10 Interesting AI Projects For Beginner Coders in 2023


 Written by:
Written by:Nathan Rosidi
You should start somewhere, and the 10 AI projects are a good start. They are ideal for beginners. Along the way, you’ll also learn AI theory.
Artificial intelligence (AI) has become a buzzword in the world of technology, with its potential to transform the way we live and work. The term “AI” was first offered by John McCarthy in 1956, when he defined it as “the science and engineering of making intelligent machines.”
AI refers to the simulation of human intelligence in machines, enabling them to perform tasks that typically require human cognition, such as learning, reasoning, problem-solving, and perception.
Machine learning (ML) is a subset of AI, and deep learning (DL) is a subset of machine learning.
So, AI is a larger field that includes both ML and DL, as well as other techniques and methodologies used to create intelligent systems.

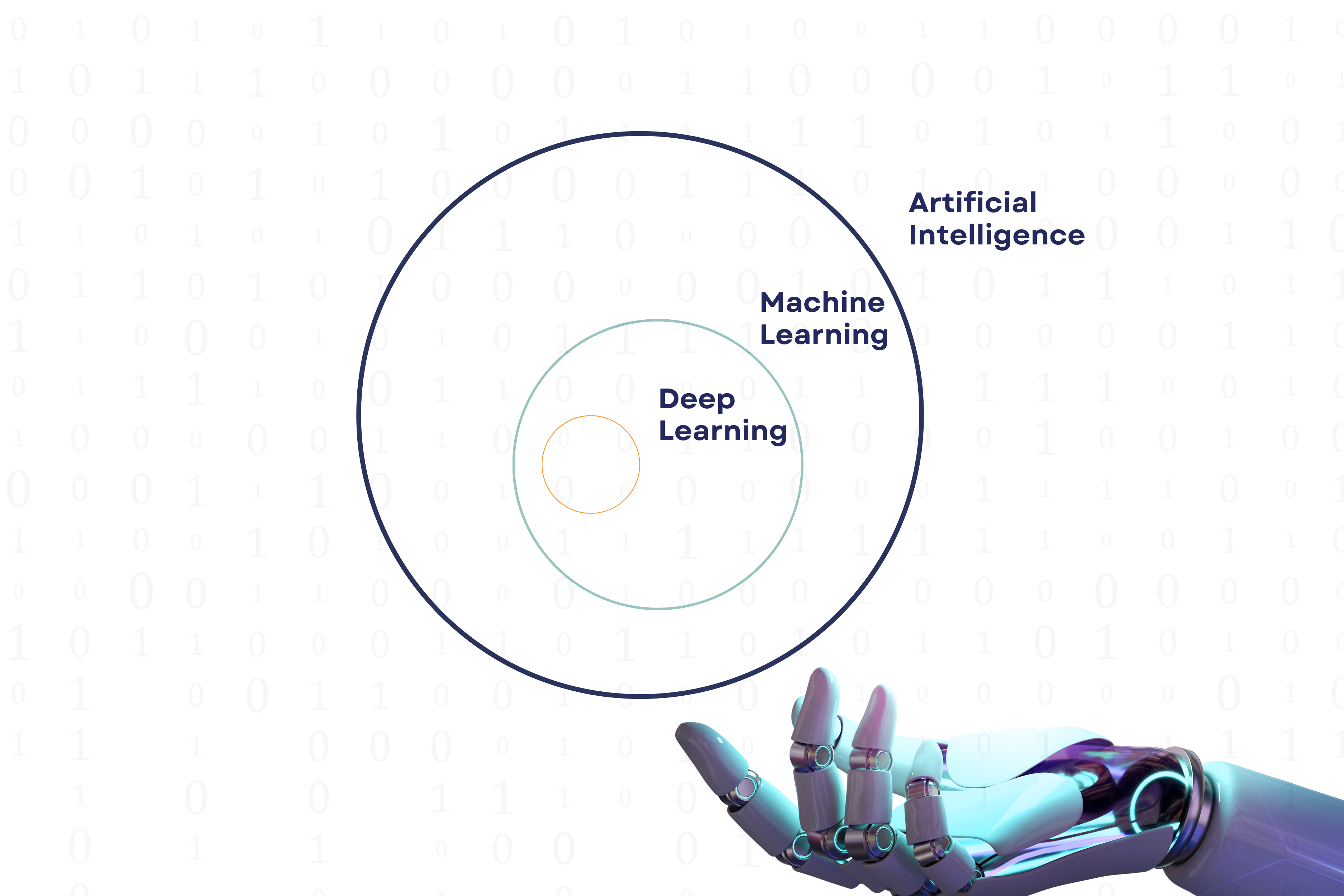
The process of machine learning entails instructing computers to acquire knowledge from data without programming, while deep learning involves training artificial neural networks to perform complex tasks.
In this article, we split deep learning into natural language processing (NLP) and computer vision (CV) to be more understandable.
NLP involves processing and analyzing human language, while computer vision enables machines to interpret and understand visual data.
For beginner coders, learning AI can seem daunting at first, but it is a rewarding and exciting field to explore and really easy when it is organized.
In this article, we’ll explore why you should consider working on AI projects, the skills you need to succeed in AI, and some top AI project ideas for beginners to practice.
Why Do You Need AI Projects?


AI is rapidly transforming various industries, such as finance, healthcare, entertainment, and education. As a beginner coder, working on AI projects can provide you with valuable skills and experiences that can help you excel in the rapidly evolving technology landscape.
The need for individuals with expertise in AI is rapidly increasing. The job vacancies in the field rose by more than 50% in 2017.
This information is derived from the McKinsey report. This report also predicts that AI could add up to $13 trillion to the global economy by 2030.
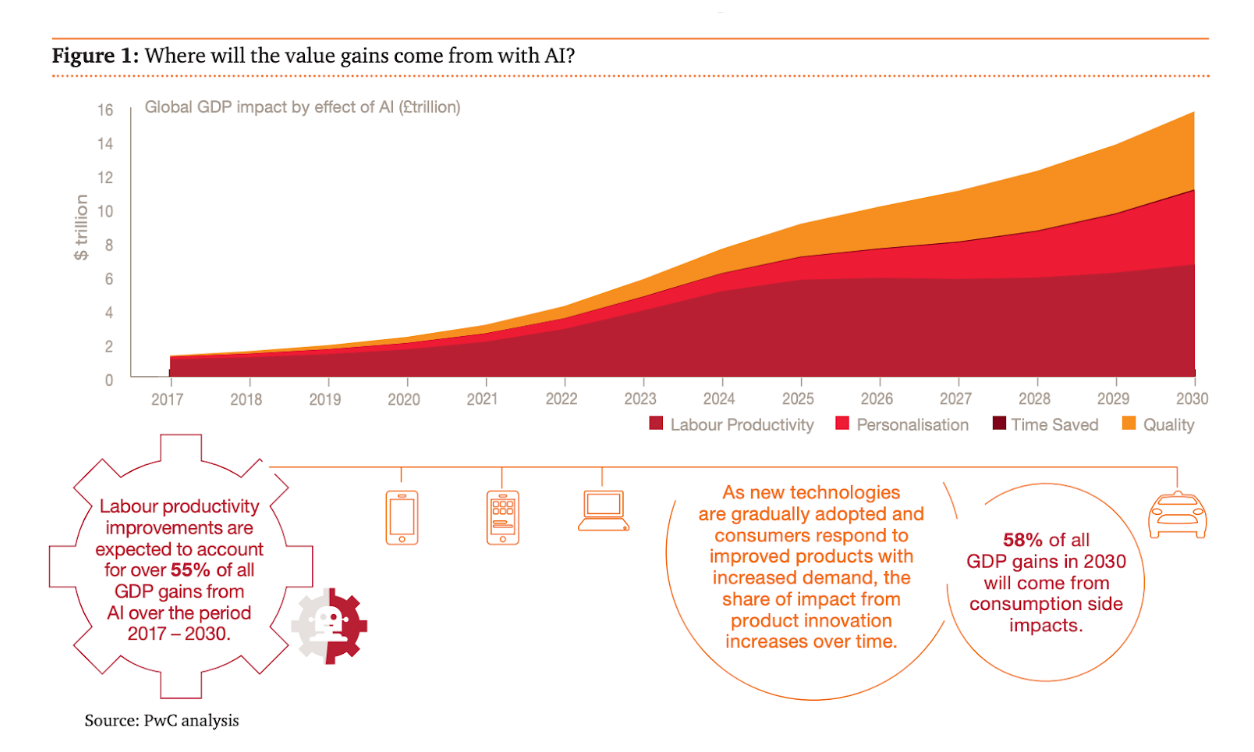
In the below graph, you can see here how the economic impact of AI has and will change over the years.


Another report, PWC’s Global Artificial Intelligence Study, found that 72% of business leaders believe that AI will be a “business advantage” in the near future, and 63% of them are planning to invest in AI in the next few years. These reports highlight the growing demand for AI talent and the significant impact that AI can have on the economy and various industries.
The below figure shows where will the value gains come from with AI.

To use these prospects, you need to develop skills and experiences that can help you excel in the job market and contribute to the growth of the AI industry.
What are these skills?
What Skills Can Assist You When Working On AI Projects?

When working on AI projects, having a strong foundation in several key skills is essential.
These skills include knowledge of algorithms and statistical methods, proficiency in linear algebra, and experience with programming languages such as Python.
Additionally, familiarity with machine learning libraries such as NumPy, pandas, scikit-learn, TensorFlow, Matplotlib, and seaborn can greatly assist in developing AI projects.
With a solid background in these areas, you can build effective AI models and algorithms capable of performing complex tasks.
Let’s explore each of these skills in detail. We will also give you links to the free resources where you can learn a particular skill.
Linear Algebra
Linear algebra is the branch of mathematics that deals with vector spaces and linear relationships between them. It is a fundamental skill in machine learning and deep learning, as it is used to represent and manipulate data and models.
Linear algebra concepts like vectors and matrices are widely used in machine learning. The same is with the operations such as matrix multiplication, transpose, and inversion.
These concepts are especially important when working with large datasets and high-dimensional data, as they help reduce computational complexity and improve the efficiency of algorithms.
Linear Algebra Courses
To learn linear algebra for free, you can refer to resources like:
Understanding linear algebra is crucial in machine learning, deep learning, and AI because it helps optimize algorithms, improves computational efficiency, and provides a solid foundation for understanding complex concepts and techniques.
Statistics

Statistics play a vital role in machine learning and understanding algorithms.
It helps you analyze and interpret data, measure uncertainties, and make informed decisions.
Machine learning algorithms often involve concepts like probability distributions, hypothesis testing, and confidence intervals. All this requires a strong foundation in statistics.
Statistics Courses
To learn statistics for free, you can refer to resources like:
One other way to learn statistics is by reading about it. It is free and valuable. As you read articles from the blogs like ours, you gain practical insights from the industry, e.g., the interview questions and statistics concepts you need for an interview. Help yourself with the statistics section of our blog articles.
Algorithms

Algorithms in AI can be broadly categorized into machine learning and deep learning. Machine learning includes techniques like regression, classification, and clustering.
Deep learning covers natural language processing and computer vision.


Algorithms are important in AI because they provide a systematic way of solving problems and help build intelligent systems.
Using pre-built algorithms in libraries like scikit-learn(e.g., decision trees or SVM) is advantageous as they are optimized and well-tested algorithms. They also save development time compared to creating algorithms from scratch.
Our post “Machine Learning algorithms” explains the AI algorithms one by one and splits them into subsections.
Programming

To develop and implement AI algorithms, you need to choose a programming language.
Python is the most popular language in data science due to its simplicity and extensive library support.
Let’s support this idea with research.
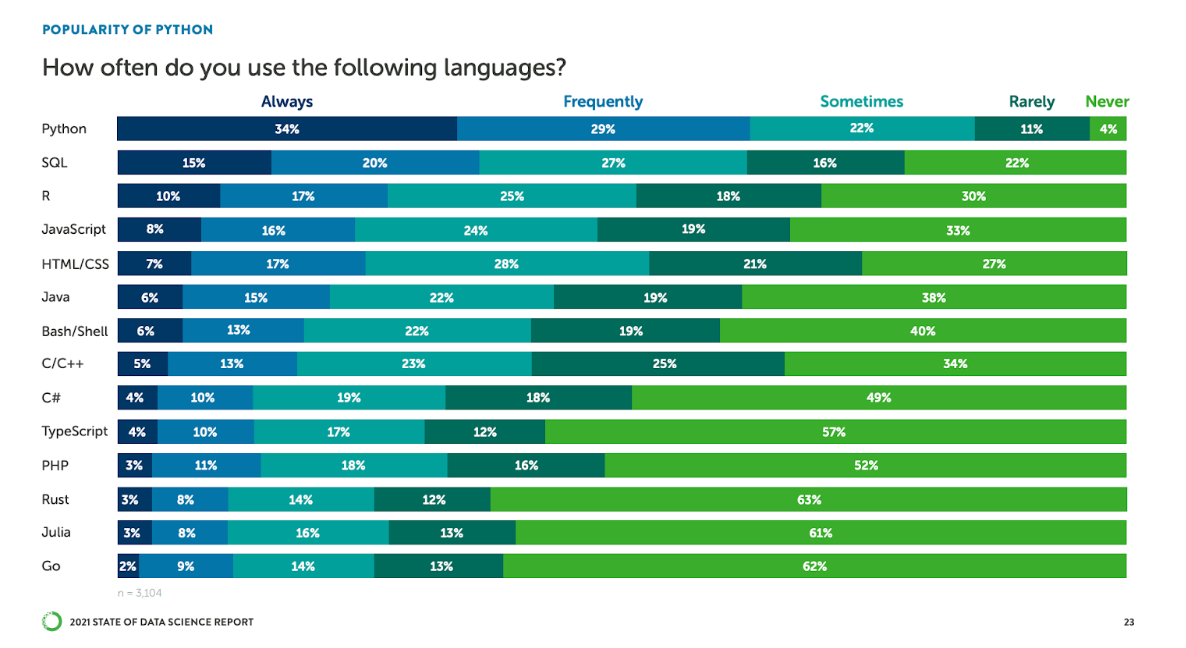
In Anaconda's 2021 State of Data Science survey, Python is set to maintain its position as the dominant programming language in data science. In the latest survey, 63% of respondents indicated that they use Python frequently or always, which makes it the most widely used language. Moreover, the survey shows that 71% of educators are teaching Python, and 88% of students are learning Python to prepare for entering the data science and machine learning field.

Python Courses
To get started with Python, you can learn the basics through resources such as:
Python, like any other programming language, is best learned through a lot of practice. In other words, coding as much as possible. One of the best ways to practice is by solving the actual coding interview questions. Complement that with engaging with the community and reading about Python, and you’re on a good course to getting skills for AI.
AI Libraries in Python

Leveraging ML & DL libraries can significantly simplify the development process and save time. But which one to choose?
We’ll talk about them in a bit. But before using ML & DL libraries, some Python libraries are pre-requisite. They create building blocks for ML libraries, their data structures, and even the calculations used in machine learning.
These libraries are NumPy SciPy, pandas, and Matplotlib.
NumPy: Here is the official documentation of the Numpy library. Also, if you have limited knowledge about NumPy, this NumPy introduction for data science should get you started.
SciPy:Here is the official documentation.
pandas: Here is the official documentation and the pandas cheat sheet. The cheat sheet includes the most important pandas functions and their applications.
Matplotlib: It is one of the most famous data visualization libraries in Python, useful for detecting patterns in data. This is valuable for building ML models. Here is the official documentation of Matplotlib.
You should be familiar with these libraries before you even think about machine learning.
Before giving examples of Machine learning and Deep Learning libraries, let’s look at the Kaggle research.
It shows the ML framework popularity. As you can see, scikit-learn and Tensorflow are at the top of the list.

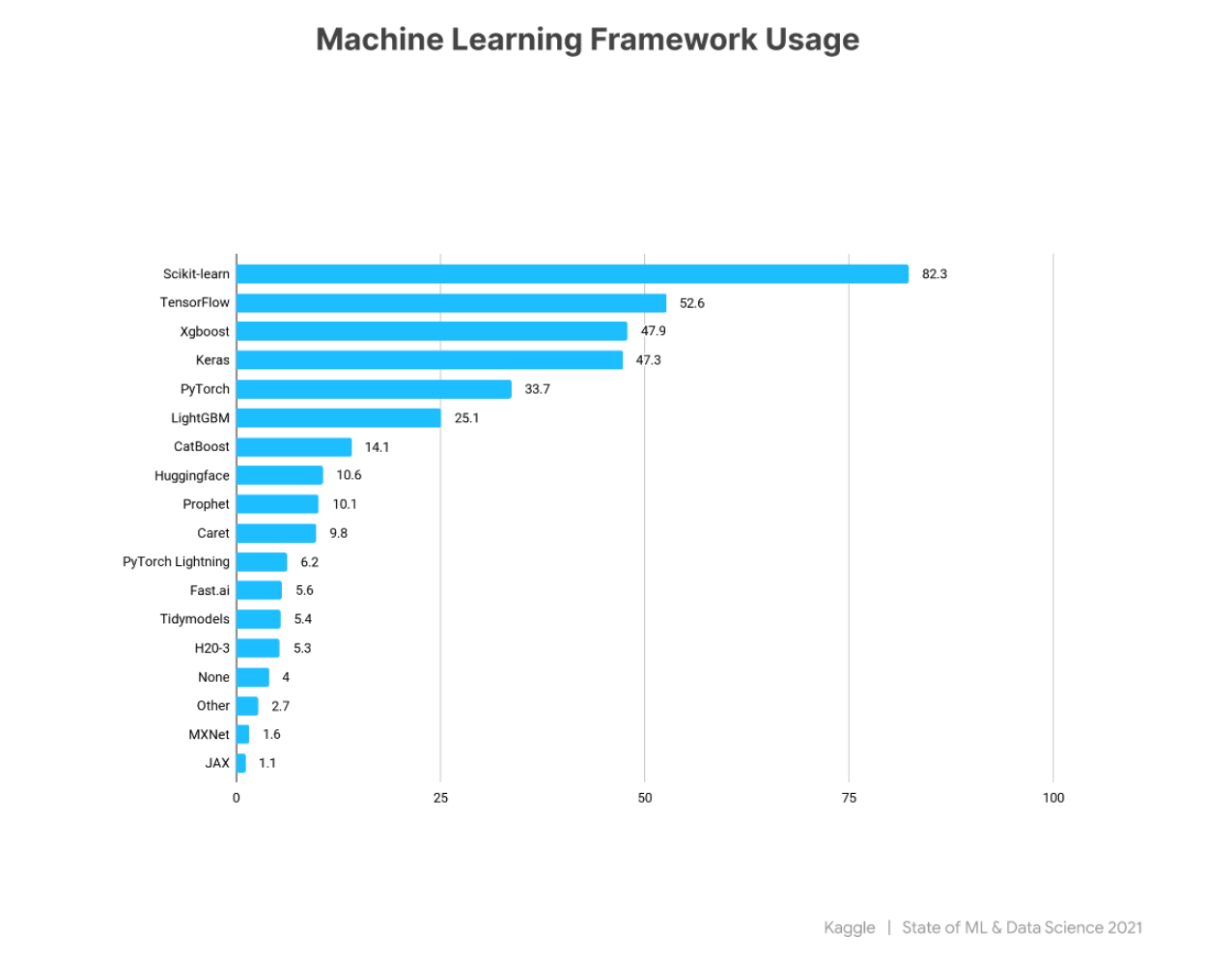
Machine Learning and Deep Learning Libraries
scikit-learn: Here is the official documentation.
TensorFlow: Here is the official documentation.
PyTorch: Here is the official documentation.
Keras:Here is the official documentation.
These libraries allow you to focus on solving AI problems without developing code from scratch.
Top AI Project Ideas for Beginners to Practice
Machine learning can be explained through three main concepts: regression, classification, and clustering.
As for deep learning, there are two parts: NLP and CV, as we mentioned before.
Let’s explain these concepts and suggest suitable AI projects for each. Below you can see the overview of all the projects we’ll discuss.
Regression
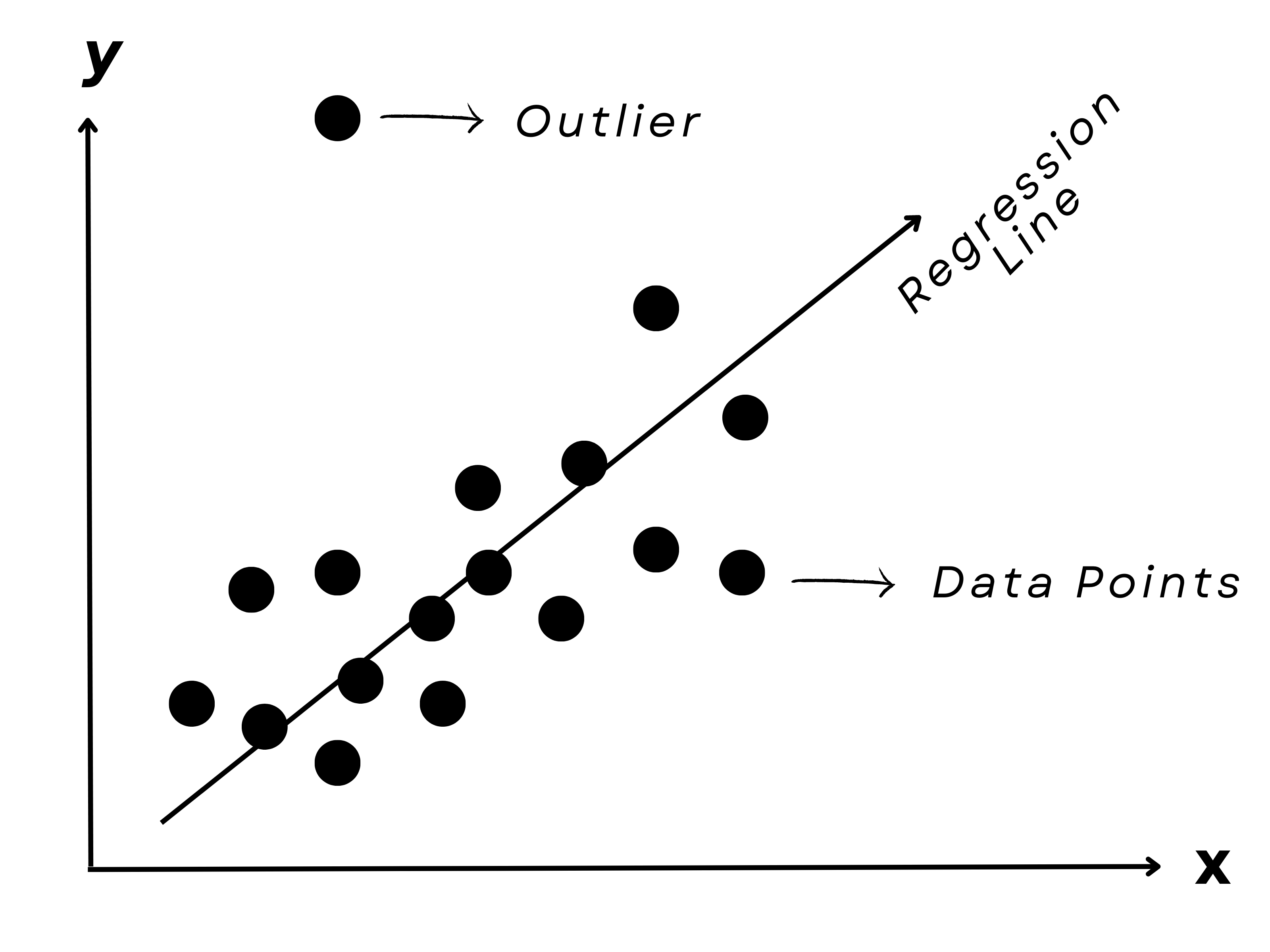
Regression is a supervised learning algorithm in ML that involves predicting a continuous output variable based on one or more input variables.
Regression aims to establish a mathematical relationship between the input and output variables, so we can use this relationship to make predictions on new, unseen data.
We use a regression line to represent the relationship between the input and output variables. The regression line is a line of best fit that minimizes the distance between the actual data points and the predicted values. This is shown in the graph above.
The distance between the actual data points and the regression line is called the residual, and the goal of regression is to minimize the sum of the squared residuals.
There are many regression algorithms that can be used for different types of problems.
Some common are linear regression, logistic regression, polynomial regression, ridge regression, and lasso regression.
You can learn more about them in our regression overview.
A real-life example of regression is earthquake prediction. We can use regression algorithms to predict the time until the next earthquake based on past seismic activity and other relevant features.
Another example is predicting electricity consumption, where we can use regression algorithms to predict the electricity demand based on historical energy usage data, weather data, and other relevant factors.
When it comes to coding these algorithms, scikit-learn is one of the famous tools. Here's a link to the scikit-learn documentation for regression algorithms.


Now, let’s get started with the electricity consumption project.
AI Project #1: Predicting Electricity Consumption
This project uses historical energy usage data, weather data, and other relevant factors to predict electricity consumption. This can help energy companies forecast future energy demand and ensure a consistent electricity supply to their clients. Additionally, this project can contribute to the mitigation of energy consumption and aid in reducing the impact of global warming.
Data
The Global Energy Forecasting Competition (GEFCom) datasets are publicly available datasets created for forecasting electricity load, price, and wind power generation.
The datasets contain hourly measurements of electricity load, temperature, and other relevant variables for different regions worldwide, along with information on holidays, weather events, and other factors affecting electricity demand.
This competition was published in Kaggle, so by visiting the platform, you can also see the code of others.
Solution Suggestion
Gradient boosting regression is one regression algorithm that could be used in the Global Energy Forecasting competition.
This algorithm is a powerful ensemble method that builds multiple decision trees sequentially and corrects the errors of the previous trees.
The gradient boosting regression can handle non-linear relationships between the input features and the output variable, which might suit this problem.
It is also a good choice for predicting the electricity load based on historical and weather data.
Solution Spoiler Alert
If you decide to do this project, please stop reading now!
The Global Energy Forecasting Competition is now finished, so we can analyze the solution.
Eight teams won the Global Energy Forecasting Competition 2012 - Load Forecasting competition. One of them used a combination of several regression algorithms, including gradient boosting regression, support vector regression, and neural networks.
They also used feature engineering techniques to create additional features from the raw data.
Their winning solution was based on a weighted average of the predictions from the different regression models, with the weights determined by the performance of each model on the validation set.
This approach allowed them to combine the strengths of multiple regression algorithms and improve the overall accuracy of the prediction.
AI Project #2: Earthquake Prediction

The goal of this project is to predict the time until the next earthquake based on seismic data and other relevant factors. This can help improve earthquake forecasting and enable early warning systems to be put in place, potentially saving lives and reducing property damage.
Data
One example of a competition on Kaggle related to earthquake prediction is the LANL Earthquake Prediction competition.
In this competition, participants were challenged to build a regression model that could predict the time remaining before the next earthquake based on seismic data from the Los Alamos National Laboratory (LANL) earthquake dataset.
The dataset contained recordings of seismic activity from a single earthquake sensor, along with information on the time to failure (TTF) for each recording. The goal was to create a regression model that could accurately predict the TTF for each recording, given the seismic data and other available information.
The competition offered a total prize pool of $50,000, with the top-performing teams earning cash prizes and the opportunity to collaborate with LANL's data science team.
Solution Suggestion
There are several regression algorithms that could be used for earthquake prediction. These include linear regression, ridge regression, lasso regression, and random forest regression. Each of these algorithms has its own strengths and weaknesses, so the choice of algorithm will depend on the project's specific requirements.
However, given the complexity and non-linearity of earthquake data, a random forest regression model is a good choice for this project.
It’s an algorithm that can handle non-linear relationships between the input features and the output variable. It can also handle missing values and noisy data, which may be present in the earthquake prediction dataset.
Additionally, it can handle a large number of input features, which is essential for this project, as there may be many variables that are relevant to predicting earthquake activity.
It can also provide a measure of feature importance, which can help identify the most important variables for predicting earthquakes.
Solution Spoiler Alert
By now, you know the drill! Please stay away and do not read the following if you consider doing this project.
The winners of the earthquake prediction competition on Kaggle used some clever tricks to get ahead.
They manipulated the sound data and focused on finding peaks and volatility in the signal.
They only used four features in their best model and made sure to sample the training data to match the testing data. They also did simple cross-validation and used a combination of three different models.
Their final submission was a blend of three types of models: LGB, support vector regression, and neural network. They then used multi-task learning by specifying additional losses next to the time to failure loss that they weighted higher than the others.
If you want to learn more about this project, here is the article that a winning team member wrote. Also, you can find this solution on Kaggle.
Classification
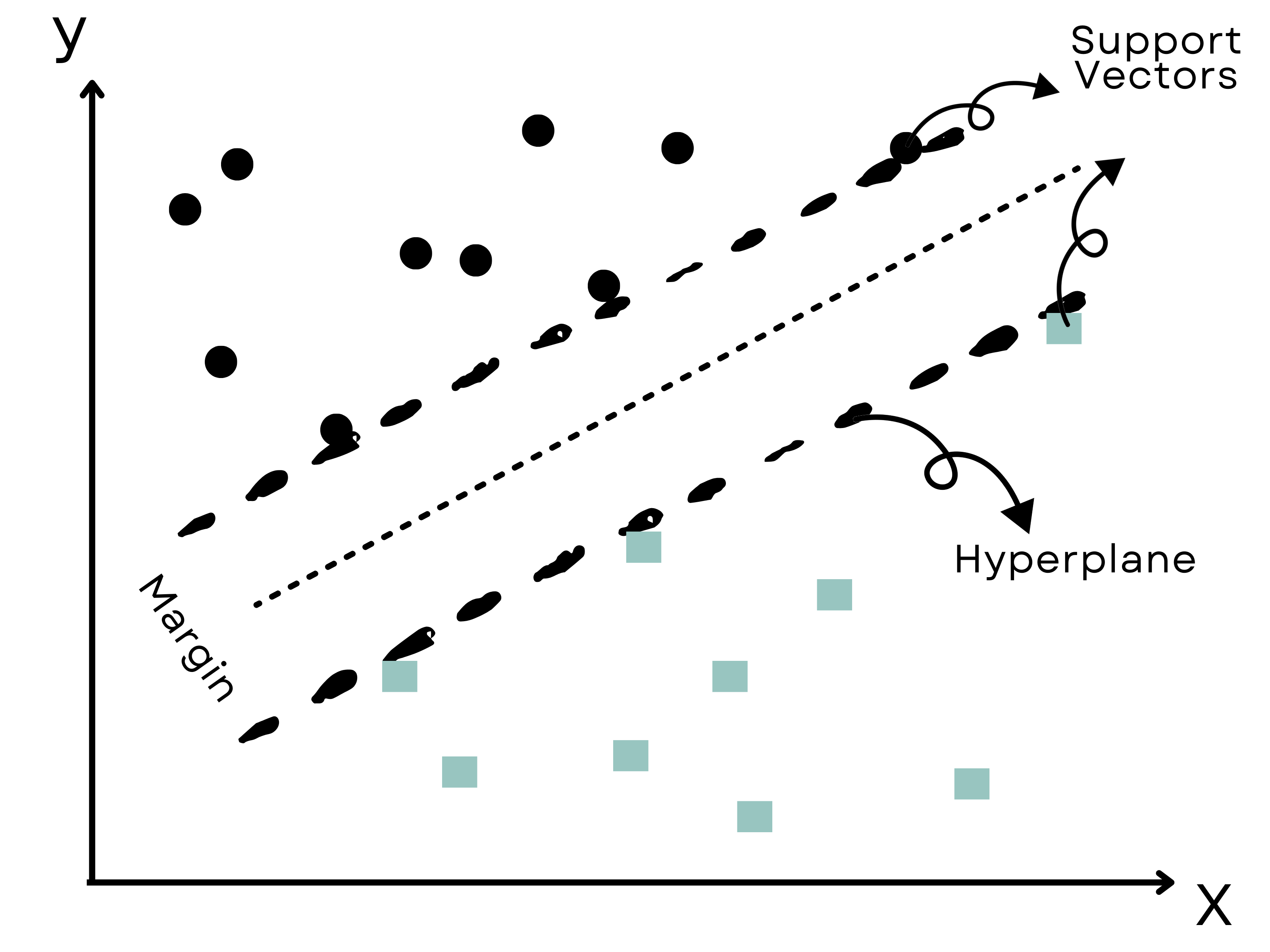
Classification is a machine learning algorithm that categorizes input data into pre-defined classes or categories.
For instance, support vector machines (SVM) is a popular classification algorithm that works by finding the hyperplane that best separates the data into different classes.
The hyperplane is selected so that it maximizes the margin, which is the distance between the hyperplane and the closest data points from each class.
The data points that are closest to the hyperplane are called support vectors.
To learn more about classification and the various algorithms, check the scikit-learn documentation and the classification overview.

Let’s now go deeper into the classification by examining real-life examples.
AI Project #3: Hearth Failure Prediction

Predicting heart disease is a common ML project that involves building a model to predict the likelihood of a person developing heart disease. The prediction is based on various factors such as age, gender, blood pressure, cholesterol levels, family history, smoking habits, and others.
The goal of the project is to develop a reliable model that can accurately predict the likelihood of a person developing heart disease, which can help medical professionals diagnose and treat patients and implement preventive measures.
Data from patients diagnosed with or at risk of heart disease is collected and analyzed to build such a model.
Data
Here are examples of multiple datasets you can use.
Heart Failure Prediction Dataset on Kaggle: This dataset contains the clinical features of 299 patients with heart failure and their survival status. You can use it to predict the likelihood of death from heart failure.
Cardiac Arrhythmia Dataset on the UCI Machine Learning Repository: This dataset contains information about 279 patients with arrhythmia and their 16 features. You can use it to predict whether a patient has arrhythmia or not.
Coronary Artery Disease (CAD) Dataset on the UCI Machine Learning Repository: This dataset contains information about 303 patients with CAD and their 14 features. You can use it to predict whether a patient has CAD or not.
Solution Suggestion
For the Heart Failure Prediction Dataset, we suggest using the random forest algorithm for classification.
Random forest is a popular ensemble learning method that combines multiple decision trees to make a final prediction. It works well with datasets that have a mix of categorical and continuous variables, as is the case with the Heart Failure Prediction Dataset.
Random forest also has the advantage of being able to handle missing data and outliers well. Additionally, it can provide important features which can help identify the most important clinical features for predicting heart failure.
Overall, random forest is a reliable and robust classification algorithm that can perform well on the Heart Failure Prediction dataset.
AI Project #4: Parkinson Prediction

Here, we will try to detect freezing of gait (FOG), a symptom affecting many individuals with Parkinson's disease.
FOG can cause significant difficulties for individuals. This competition is designed to develop a machine learning model that can identify when FOG episodes occur by analyzing data collected from a wearable 3D lower back sensor.
The ultimate goal is to improve medical professionals' ability to assess, monitor, and prevent FOG events.
Data
Here is the link to this competition.
The dataset contains lower-back 3D accelerometer data from patients exhibiting FOG episodes.
The objective is to detect the start and stop of each FOG episode, as well as the occurrence of three types of FOG events: Start Hesitation, Turn, and Walking.
The dataset includes three subsets of data, each collected under different circumstances.
The tDCS FOG dataset comprises data collected in a lab, while the DeFOG dataset comprises data collected in the subject's home.
The Daily Living dataset contains continuous 24/7 recordings from 65 subjects, including 45 subjects with FOG symptoms.
Solution Suggestion
To detect Freezing of Gait (FOG), we suggest using a supervised machine learning classification algorithm such as Support Vector Machine (SVM), random forest, or gradient boosting. These algorithms are suitable for processing complex, high-dimensional data like 3D accelerometer data.
SVM is a well-known algorithm for classification that can handle nonlinear data and has excellent generalization performance.
Random forest is also a powerful algorithm for classification that can manage high-dimensional data and provide insights into feature importance.
Gradient boosting is a popular algorithm that can address complex relationships between features and target variables.
Also, there is a prize for this ongoing competition, which might motivate you.


Clustering
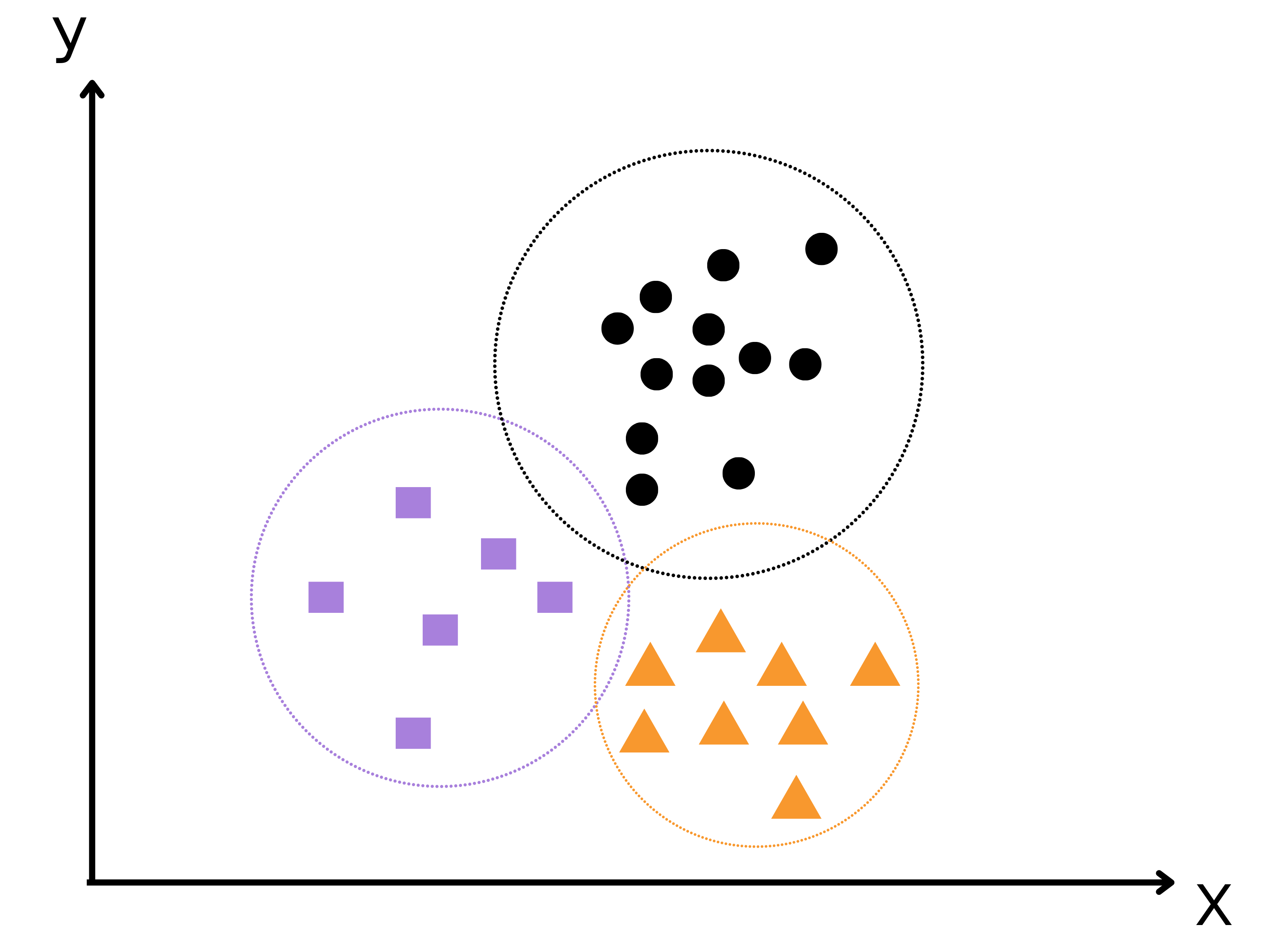
Clustering is a type of unsupervised learning technique in machine learning, where the aim is to group similar data points in clusters based on some similarity or distance measure. The goal is to maximize the similarity within the same cluster and maximize the dissimilarity between different clusters.
There are several clustering algorithms, including k-means clustering, hierarchical clustering, DBSCAN, mean-shift clustering, and Gaussian mixture models.
For more information, go to our article about clustering algorithms or the scikit-learn documentation.

A real-life example of clustering is crime analysis. Law enforcement agencies can use clustering algorithms to group similar crimes together based on various features such as the type of crime, location, time of day, etc. This can help identify patterns and trends in criminal activity and predict where future crimes may occur.
One more example is image segmentation in computer vision. Clustering algorithms can group pixels in an image based on their color or texture similarity, which can be helpful for object recognition and image analysis.
AI Project #5: Crime Analysis

A crime analysis project typically involves using data related to crimes committed in a particular area to identify patterns, trends, and other insights to help law enforcement agencies prevent future crimes or solve past ones.
In the case of the Chicago Crime dataset on Kaggle, it contains information on reported crimes in the city of Chicago from 2001 to the present, with data points such as the type of crime committed, the location and time of the crime, and the arrest status of the offender.
Data
The dataset here is maintained by the Chicago Police Department and is updated weekly. It includes various details such as the type of crime, location, date and time of occurrence, description of the incident, and whether an arrest was made or not. The dataset has over 7 million rows and 22 columns, providing a rich source of data for analysis and modeling. This dataset can be used for a variety of machine-learning projects, including clustering, classification, and prediction.
Solution Suggestion
A possible solution for the Chicago Crime dataset would be to use clustering to identify patterns and hotspots of criminal activity in the city.
One approach could be using k-means clustering to group similar crimes based on location, time, and type.
To implement this, we can first preprocess the data by cleaning and filtering out any irrelevant information.
We can then use the latitude and longitude values to create spatial clusters using k-means. Additionally, we can use the date and time of each crime to group them into temporal clusters.
Once we have identified the clusters, we can use various visualization techniques to analyze and interpret the results. For example, we can create heat maps to visualize the density of crimes in different areas of the city, or we can create line graphs to show the trends and patterns of crime over time.
Another possible clustering algorithm for this project could be DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
This algorithm can identify clusters of arbitrary shape and is particularly useful when dealing with spatial data that has noise or outliers.
So choose your side, and go with it.
AI Project #6: Image Segmentation using Clustering Algorithms
The Data Science Bowl 2018 dataset is a collection of 2D microscopy images of human cells.
The competition aimed to identify individual nuclei within these images and segment them accurately. The dataset consists of 670 images in the training set and 65 in the test set.
Data
The data consists of two folders - one for training images and the other for testing images.
The training images folder contains 670 subfolders, each containing a single image in PNG format and a corresponding mask image indicating the location of the nuclei in that image.
The testing images folder contains 65 subfolders, each containing a single image in PNG format.
This competition aimed to develop an algorithm that could accurately identify the nuclei in the testing images.
The Allen Institute provided the dataset for Cell Science, and Kaggle hosted the competition in partnership with Booz Allen Hamilton.
Solution Suggestion
One popular clustering algorithm for image segmentation tasks like the one in the Data Science Bowl 2018 competition is k-means clustering.
K-means is an unsupervised learning algorithm that partitions a given dataset into the k-number of clusters based on their similarity.
It works by randomly initializing k-centroids, assigning each data point to the nearest centroid, moving the centroids to the mean of the assigned data points, and repeating this process until convergence.
In image segmentation, k-means can be used to group pixels with similar colors or textures, which can help identify regions of interest in an image.
In the Data Science Bowl 2018 competition, k-means clustering was used to segment lung nodules from CT scans.
Here's a link to the scikit-learn implementation of k-means clustering.
Solution Spoiler Alert
The winning solution for the Data Science Bowl 2018 used a combination of clustering and convolutional neural networks (CNN) to identify and segment individual nuclei in microscope images of cells.
The solution consisted of three main steps.
First, they used a clustering algorithm called DBSCAN to identify the nuclei in the images. DBSCAN is a density-based clustering algorithm that groups data points close together in a high-density region while ignoring points far away or in low-density regions.
Next, they used a CNN to refine the nuclei segmentation further, using the clusters identified by DBSCAN as input. The CNN was trained to distinguish between nuclei and background pixels based on the features extracted from the input images.
Finally, they used post-processing techniques to clean up the segmentation masks and remove any artifacts or false positives. This involved applying morphological operations to the masks to remove small objects and fill in holes in the masks.
The winning solution used a combination of DBSCAN clustering and a custom CNN architecture for segmentation.
The code for the solution is not publicly available. Still, there are many resources available online for learning how to implement clustering and CNNs for image segmentation, such as the scikit-learn documentation and the Keras library.
Natural Language Processing

Here we have the following two AI projects:
- Classification For News Articles
- Resume Parser

AI Project #7: Classification For News Articles
In this project, the task is to build a classification model to predict the category of news articles from BBC News. The dataset consists of news articles from 2004 to 2005.
Each article is labeled with one of the following categories: business, entertainment, politics, sport, and tech.
The goal is to train a model on a portion of the labeled data and then evaluate the model's performance on a holdout set of news articles. Participants are evaluated based on the accuracy of their model's predictions on the holdout set. The project is part of the "Learn AI with the BBC" initiative aimed at helping people learn the basics of artificial intelligence and machine learning.
Participants are encouraged to experiment with different text preprocessing techniques, feature extraction methods, and machine learning algorithms to improve the accuracy of their models.
The competition provides sample code in Python and a sample submission file to help participants get started.
This project is an excellent example of text classification using supervised learning, where the model is trained on labeled data to make predictions on new, unlabeled data. It is also an example of how machine learning can be used to automate tasks such as categorizing news articles, which can be helpful in many real-world applications.
Data
The training dataset consists of over 2,000 labeled news articles, and the test dataset comprises over 700 unlabeled articles. Participants are required to submit their model predictions for the test set, and the performance of the models is evaluated based on accuracy.
The data for this project consists of BBC news articles from 2004 to 2005. The articles are in plain text format and include the title, date, and body of the article. Each article is labeled with one of the five categories mentioned above.
The dataset is split into two parts: training and test sets. The training set includes 1,700 labeled articles, and the test set contains 700 unlabeled articles. The data is available on Kaggle and can be downloaded by competition participants.
Solution Suggestion
One solution for the BBC News Kaggle dataset is to use a natural language processing (NLP) algorithm, such as a convolutional neural network (CNN) or a recurrent neural network (RNN), for text classification.
First, the dataset can be preprocessed by removing stop words, stemming or lemmatizing the text, and converting the text to numerical representations such as word embeddings. Then, the preprocessed text can be fed into the CNN or RNN model.
For CNN, the model can consist of an embedding layer, followed by several convolutional layers with max pooling, and then a fully connected layer with softmax activation for multi-class classification.
For RNN, the model can be a long short-term memory (LSTM) or a gated recurrent unit (GRU) with an embedding layer and a fully connected layer for classification.
After training the model on the dataset, it can be evaluated on a test set using metrics such as accuracy, precision, recall, and F1 score.
AI Project #8: Resume Parser

Resume parsing is also a natural language processing project that involves extracting information from resumes and converting it into a structured format.
It can involve techniques such as optical character recognition (OCR), natural language processing (NLP), and information extraction (IE).
The goal is to automate the process of parsing resumes and extracting relevant information such as name, contact information, work experience, education, and skills.
This can be useful for HR departments and recruiters who need to process a large number of resumes for job openings.
Data
About resume parsing, there are a lot of different datasets that exist from which you might choose.
Resume Parsing Dataset on Kaggle: This dataset includes 1,000 resumes in PDF format along with the corresponding data in CSV format, which includes the extracted text from each resume and the corresponding labels for various fields such as name, email, phone, etc.
Resume Screening Dataset on Kaggle: This dataset includes a collection of job postings along with the corresponding resumes received for each job. The goal is to predict whether a given resume is a good fit for a particular job based on the text of the job posting and the resume.
Solution Suggestion
One possible solution for resume parsing could be to use named entity recognition (NER) algorithms, which can identify and extract meaningful information from text, such as names, organizations, dates, and other relevant entities.
Here are some steps you can follow to build a NER model for resume parsing using the dataset you provided:
- Preprocess the data: Clean the data by removing irrelevant information and formatting the data to a suitable format for training the model.
- Split the data: Divide the dataset into training and testing sets. The training set will be used to train the NER model, while the testing set will be used to evaluate the model's performance.
- Train the NER model: Use a suitable NER algorithm such as spaCy or Stanford NER to train the model on the training data.
- Evaluate the model: Test the performance of the trained model on the testing data to evaluate its accuracy and identify any areas for improvement.
- Use the model for resume parsing: Once the model is trained and evaluated, it can be used to parse resumes and extract important information, such as contact details, work experience, education, and skills.
Computer Vision

Computer vision is a branch of AI that focuses on enabling computers to understand and interpret visual data from the world around us.
This involves using algorithms and deep learning models to analyze visual data, including images and videos, and extract information such as object recognition, segmentation, tracking, and image classification.
TensorFlow is developed by Google which is a popular open-source machine learning framework. It provides various tools and libraries for building and deploying deep learning models, including those designed for computer vision tasks.
TensorFlow includes several powerful computer vision libraries, such as TensorFlow Object Detection API, TensorFlow Hub, and TensorFlow Image Classification, which are useful for building high-performance computer vision models. To learn more about TensorFlow and its computer vision libraries, you can do so here.

AI Project #9: Hand Gesture Recognition

In this project here, you can build a model to recognize hand gestures within images or videos. This can be useful for applications such as sign language translation or gaming. Datasets such as the Hand Gesture Recognition dataset are available on Kaggle.
Data
The dataset here consists of 10 different hand gestures performed by 10 different people. There are a total of 20,000 images, with 2,000 images per gesture. The images were taken using the Leap Motion Controller, which captures hand movements in 3D space. Each image is a 640 x 240 grayscale image representing the top-down view of the hand performing the gesture.
Solution Suggestion
To recognize hand gestures within images or videos, you can use a computer vision technique called convolutional neural networks (CNNs).
CNNs are a type of deep learning algorithm that can learn to extract relevant features from images and classify them into different categories.
For this project, you can use the Hand Gesture Recognition dataset to train a CNN model to recognize the different hand gestures.
You can preprocess the images by resizing them to a standard size and converting them to grayscale. Then, you can train the CNN model using the preprocessed images and their corresponding labels (i.e., the gesture performed in each image).
Once the model is trained, you can use it to recognize hand gestures in new images or videos by passing them through the trained model and getting the predicted class label.
AI Project #10: Emotion Recognition

Emotion recognition with computer vision is a project where we use image and video processing techniques to identify and classify human emotions based on facial expressions. This project aims to build a model that can accurately detect emotions such as happiness, sadness, anger, surprise, and disgust.
Data
The FER2013 dataset contains images of varying quality and lighting conditions, which can make it challenging to detect emotions accurately.
A popular dataset used for emotion recognition in computer vision is the FER2013 dataset, which contains 35,887 grayscale images of faces labeled with one of seven emotions: anger, disgust, fear, happiness, sadness, surprise, and neutral.
Solution Approach
To overcome these challenges, a possible solution for emotion recognition with computer vision is to use deep learning models such as convolutional neural networks (CNNs) to learn and extract relevant features from the images automatically. These CNN models can be trained on the FER2013 dataset to recognize patterns in facial expressions and classify them into one of the seven emotions.
One popular deep learning library for implementing computer vision projects is TensorFlow. The TensorFlow library provides a range of tools and APIs for building and training deep learning models, including those for image classification and object detection. For example, the TensorFlow Object Detection API includes pre-trained models for emotion recognition that can be fine-tuned on custom datasets such as FER2013.
Conclusion
In summary, this article introduced the top 10 AI project ideas for beginner coders to practice, ranging from regression and classification to clustering, natural language processing, and computer vision. There are also some more machine learning projects, and not only for beginners.
We also emphasized the importance of learning essential skills such as algorithms, statistics, linear algebra, and programming to succeed in AI projects.
By working on AI projects, you can develop your skills and build a strong portfolio that showcases your abilities to potential employers.
With the help of resources like StrataScratch, you can access datasets, learn new algorithms, and practice your programming skills to tackle more complex projects.
With the right mindset and dedication, you can create futuristic projects that make a real impact in various industries.
Share


