NumPy for Data Science Interviews


Categories:
 Written by:
Written by:Vivek Sankaran
An introduction to NumPy for Data Science
An introduction to NumPy for Data Science
NumPy is the fundamental library in the Python Data Science ecosystem for scientific computing. Some of the key features of NumPy include
- Speed: NumPy arrays are up to 50x faster than standard Python lists
- Performance: NumPy melds the ease of use of Python with the speed of C
- Indexing and Broadcasting: The features so widely used in Pandas are inherited from NumPy.
- Computing Tools: NumPy has a comprehensive range of Mathematical Functions and computational tools for virtually all needs. You can perform operations like curve-fitting, optimization, linear algebra, transformations, etc., with ease.
- NumPy is the foundation on which numerous other scientific computing libraries are built. Some of the well-known libraries using NumPy are
- Stats and ML Libraries: SciPy, Statsmodels, Scikit-Learn, SpaCy
- Visualization: Matplotlib, Seaborn, Plotly, Bokeh, Altair
- Array Manipulation: PyTorch, Dask, TensorFlow
- ETL: Pandas
If you are an aspiring Data Scientist, proficiency in NumPy is expected. Fortunately, NumPy is straightforward to learn. In this two-part series, we will start from the basics of NumPy and move to advanced usage of NumPy.
Need for NumPy
Let us take a simple example. Suppose you want to go from point A to point B there are multiple ways of traveling. You can probably use a bike to try to walk, or you might want to take a car. There are numerous choices you can take a sports car or an SUV, even among vehicles. If you do not know the type of terrain that you will drive on, you will arguably be better off using an SUV because that's what they are designed for - an all-purpose vehicle. However, if you aim to complete the journey in the shortest possible time, and you know that the roads are well-paved and there is no unexpected traffic from the other direction, you will opt for a sports car because you can zip through the distance. In short, that is the difference between a standard Python list and a NumPy array. A Python list is your all-terrain vehicle, whereas a NumPy array is a sports car. A Python list is designed to handle all kinds of data you can insert into a list. However, suppose. You know that the data is homogeneous and numeric type data (integer, floating-point, Boolean, datetime, etc.) and involves a lot of computation. In that case, you are better off using NumPy.
Let us take a simple use case. Say we have a simple list of five elements. And we want to create another list that contains the result of dividing each of these elements by five. We will have to loop through the list and perform the operation elementwise because performing the division operation on the entire list will result in an error.

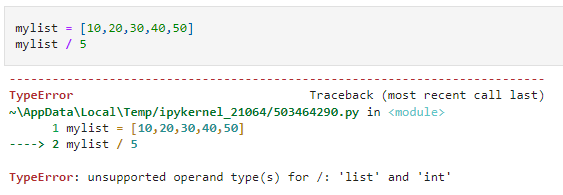
Even though each of these five elements is numeric, Python lists will not allow you to perform this division operation because the Python operations are designed to work with all possible cases. Since a list need not contain only numeric data types, Python will not allow this.
Enter NumPy. With the NumPy array, we can simply divide the entire array by five. Just as you will do with a Pandas Series (In fact, the Pandas Series derives these powers from NumPy).


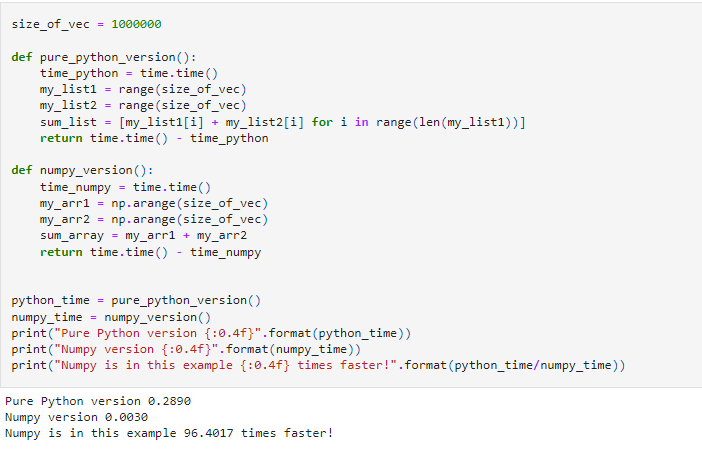
Another reason for using NumPy is speed. NumPy arrays are significantly faster than Python standard lists. Here is a quick example. We will add two Python lists elementwise, each containing a million elements. Comparing list operations and the equivalent NumPy operation, we find that NumPy is about 20 times faster than standard lists. (Note: The speeds may vary)

Comparison of NumPy with Python and Pandas Data Types
What about Pandas? Well, Pandas Data Frame provides an easy way of manipulating tabular data. Each Pandas Series is built on NumPy arrays. Pandas provide the advantage of having labeled elements using row and column labels.

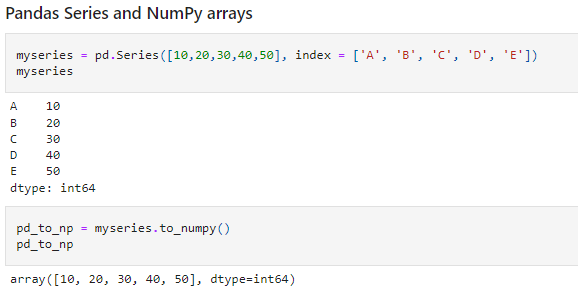
However, as the size of data grows, mathematical operations become slower and slower. One can use Pandas to manipulate data and then shift to NumPy to perform the operations faster.
NumPy Basics
Initialization
There are multiple ways of initializing a NumPy array. The easiest is to pass a list (or any other array-like object) to the array method in NumPy.


The following will, however, produce an error.

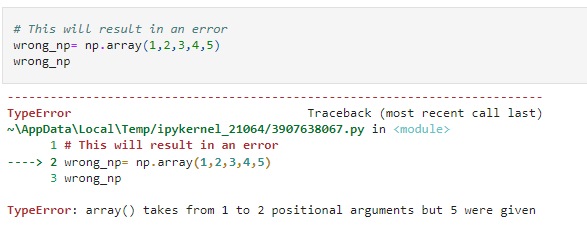
This is one of the most common errors while starting off with NumPy. We need to pass the array elements as an array-like object viz list, tuple, Pandas Series, etc.
Dimensions
The NumPy array is an n-dimensional container of homogeneous items. NumPy can handle multi-dimensional data and is therefore aptly suited for scientific calculations. We can create a multi-dimensional array just as we created a single-dimensional array earlier.


A point to remember is that the lengths of the sub-lists here should be identical otherwise, NumPy will create what is called a ragged array (an array of list type) data which basically defeats the purpose of NumPy.

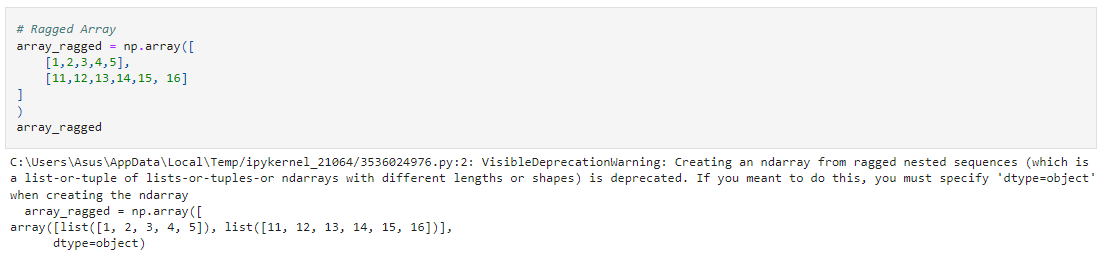
Think of it as driving a sports car into a desert. It will move (for some time at least), but that is not what it was designed for!
We can easily change a single-dimensional data into multiple-dimensional data and vice versa. We will look at these later.
Descriptive Attributes
As with Pandas, we can find out the various attributes of a NumPy array. The most used attributes are.
ndim: The number of dimensions (axes) of data.


shape: It returns the number of elements along each dimension as a tuple


size: Returns the number of elements in the array.


dtype: this provides us with the data type of the array elements.


While the most common data types are integer (int) and floating-point (float), NumPy also allows you to create datetime, boolean, and character type arrays as well.
Special Arrays
NumPy allows us to quickly initialize large arrays very easily, especially those associated with scientific computing.
ones – an array of 1s.


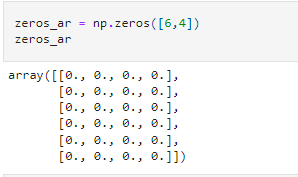
zeros – an array of 0s

eye – an array with 1s on the specified diagonal and 0s elsewhere.


Besides these, we can also create equally spaced arrays. We have the range data type in standard Python. NumPy has two very common methods used for quickly creating similarly spaced values. These are:
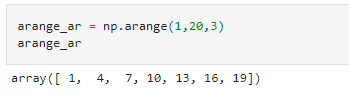
arange: This is very similar to the range datatype in standard Python. The arange method in NumPy creates an array with the same elements as the range datatype. Unlike the range datatype, this is stored as a NumPy array.

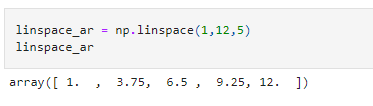
linspace: The linspace method divides the given endpoints into equally spaced intervals. In the given example, we want five equally spaced points, with 1 and 12 being the endpoints.

Reshaping NumPy Arrays
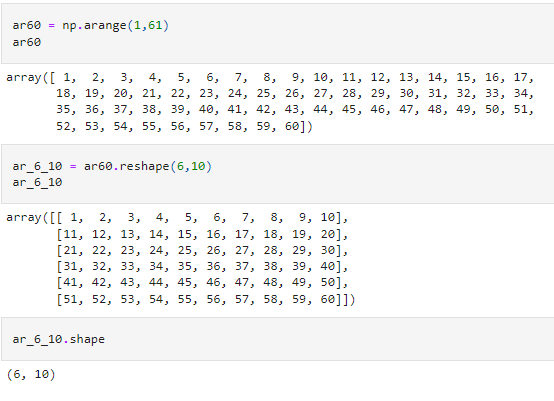
NumPy allows you to easily change the shape of the arrays to our desired dimensions. We can simply use the reshape method to change the shape of an array. A point to be noted is that you can change the shape of an array only if the size of the two arrays (the number of elements) is the same. Therefore, you can split an array of sixty elements into the following shapes
- 60x1 (or 1x60, 1x60x1…)
- 2x30
- 4x15
- 2x3x10
- 1x6x5 and so on

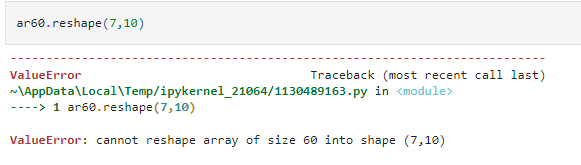
However, you cannot split a 60-element array into another array that has seven elements on one dimension

A quick hack in NumPy allows it to calculate the dimensions itself. For example, if you do not know the exact number of elements in a particular array but want six rows, we can do that by specifying -1 as the dimension to be calculated.

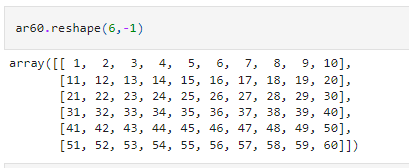
In the above case, we had 60 elements, so when we reshape it as (6,-1) NumPy automatically calculated the other dimension as 60 / 6 = 10.
Obviously, this will not work if the number of elements along an axis is not a factor of 60. So this will return an error.

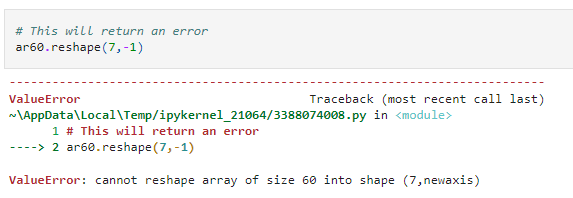
Further NumPy can calculate only one unknown dimension at a time. So this, too, will result in an error.


Indexing and Slicing Arrays
Indexing and Slicing NumPy arrays as we do with Pandas dataframes, Pandas Series, and lists. Suppose you want to find the nth indexed item in an array; you can simply use the slicer as we would do with a Python list. The other functionalities of the slicer also work as they do with a Python list or a Pandas Dataframe.

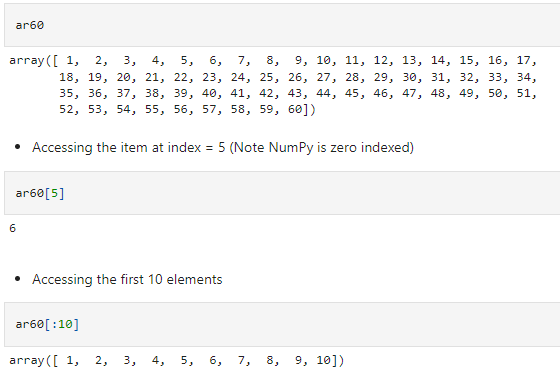
For multidimensional arrays, we can index in the same manner as we do with the Pandas iloc method. Here is an example of selecting from a two-dimensional array

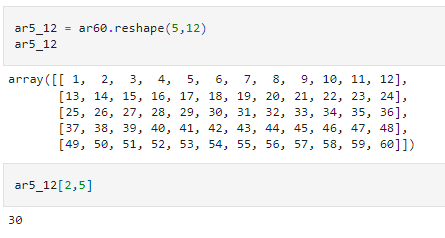
One can also subset by using multiple slicers. Here is another example of selecting multiple items from a two-dimensional array


We can also pass a range of indexes into the slicer. This is very similar to the iloc method in a Pandas Dataframe.


Boolean Mask
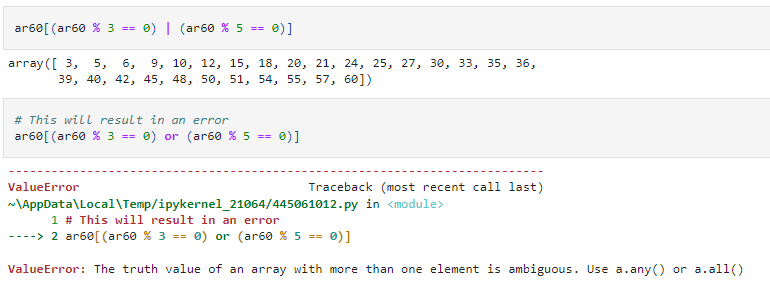
One of the most powerful concepts in NumPy is Boolean masking. As we have seen in Pandas earlier, we can subset the NumPy array based on a logical true false condition and get the output as the elements which satisfy that condition. This is quite common in Pandas.


As with Pandas, we will have to use the Python logical operators and not keywords like and, or, not while creating these Boolean masks.

Check out our post Microsoft Data Scientist Interview Questions to find a recent interview question that is testing “Boolean Masked Arrays” as one of the main Python concepts.
Functions in NumPy
NumPy comes with a variety of built-in functions. These functions perform mathematical operations and complex scientific computations very quickly.


We can also perform these operations along a particular axis instead of the whole array. So, if you want to take the sum of elements along the rows or only along the columns, that too is possible, remember the outermost dimension is axis 0, the next one 1, and so on. As with standard Python, we can use negative indexing. The innermost dimension will be axis = -1 and so on.


Besides simple aggregation functions like sum, max, min, etc., we also have built-in standard mathematical functions. You can refer to the documentation for the full list of the functions in NumPy.
Vectorized Operations
Another feature that makes NumPy so powerful is vectorized operations. These allow us to perform mathematical operations on an entire dimension or even an entire array. For example, if we want to add two arrays elementwise, you can simply do something like this.

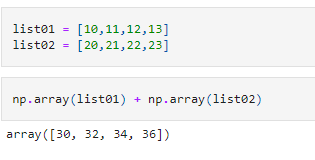
This will not be possible with a Python list that would concatenate the two lists.

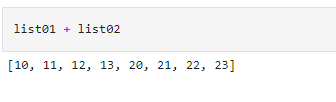
The operations are not limited just to arrays of identical dimensions. Even arrays that are not identical can be used for these vectorized operations. This process is called broadcasting, and we will look at these and more advanced features of NumPy in the next part of our series, where we will cover:
- Random Number Operations with NumPy
- Array Operations like Stacking and Splitting
- Handling Missing Values
- Broadcasting
- Matrix Operations
- Curve Fitting
- Importing Data into NumPy
Conclusion
NumPy is arguably the most critical Python library after Pandas for an aspiring Data Scientist. While NumPy might appear a little uncomfortable for those without a mathematical or technical background, if we start with Pandas, then NumPy becomes very easy to use. The range of possibilities and the power that NumPy provides is not available in other standard libraries.
As with any other skill, patience, persistence, and practice are the keys to improvement. If you would like to practice these and many more real-life problems from actual data science interviews, join StrataScratch today. You will discover a community of over 20,000 like-minded data science aspirants and learn while solving over 500 coding and non-coding problems of various difficulty levels. Sign up today and make your dream of working at top tech companies like Microsoft, Google, Amazon, or the hottest start-ups like Uber, Doordash, et al. a reality. All the code examples are available on Github here.
Share


