Uber SQL Interview Questions

Categories:
 Written by:
Written by:Irakli Tchigladze
Breaking down the solution to one of the interesting Uber SQL interview questions
Uber is a company that changed inner city travel and made the lives of millions of users much easier. Their main product is a smartphone app that lets users find a ride for a reasonable price. Uber is involved in a number of other businesses, such as food delivery, shipments, and more.
All of these operations have one thing in common: they rely on stable and efficient logistics to successfully complete the trip. To reach that goal, Uber collects massive amounts of data every day. The company maintains a team of talented data scientists to gain actionable insights from the available information.
In this article, we will explore one of the SQL interview questions asked during an interview at Uber.
Basic to Intermediate Concepts Tested in Uber SQL Interview
Aggregate Functions
Before going into an interview, read this “Ultimate Guide to SQL Aggregate Functions” to refresh your knowledge of aggregate functions. You will need to know aggregate functions to solve most SQL questions asked during interviews, and more importantly, write SQL queries on your day to day job.
You need to have a basic knowledge of aggregate functions, such as the syntax, arguments and how to summarize the results using the GROUP BY statement.
If you want to really stand out from the competition, it’s a good idea to dig a little deeper. For instance, learn how to use aggregate functions in combination with other SQL features, such as the DISTINCT statement.
SUM() is one of the most commonly used aggregate functions. It is necessary to solve questions where you have to add up numerical values in a certain column. In the question below, we will use it to calculate total miles.
You should know that SUM() can only be used for counting the total of numbers, not with text, date or other types of values. Knowing little details, like how this function handles NULL values, can go a long way.
WHERE
The WHERE statement is one of the basic features of SQL. Despite its simplicity, it is essential for filtering data in SQL. You should know how to use it with SELECT/FROM statements to filter out rows that don’t meet the criteria.
To filter the tables in SQL, you should know how to set a condition for the WHERE statement. There is no limitation on what the condition can be. You might have to check if the number value in one column is higher than another. You should be prepared for how to use comparison operators to compare other values, such as strings, dates and floats.
There are syntax rules for writing conditions. For instance, whether it’s necessary to use quotes when comparing number, string, date and other types of values.
It’s important to know how comparison operators work on non-numerical data. For instance, if you’re working with sales data, you might want to limit the output to one specific month. You can use comparison operators to get the records from one specific month, or determine which of the two dates came first.
ORDER BY
Interviewers often ask you to return X number of highest values in a column. To do that, you need to arrange the data from the highest to lowest, and output the specified number of values in the order.
We use the ORDER BY statement to sort rows in SQL. It allows you to specify a column, and SQL will order the records based on values in that column. To solve some of the more difficult questions, you might have to specify more than one column. It’s useful to know how to specify the column by name or by its index in the table.
A good candidate should know how to specify between ascending and descending order for sorting values, and how the ordering works on date and string values.
Also, the knowledge of details, such as what happens when the order is not specified, can go a long way.
Ranking Window Functions
As previously mentioned, to solve some questions, candidates have to output a specific number of highest values in a column. There are multiple ways to approach these questions.
In some cases, like for the question below, it can be argued that a simple LIMIT statement is enough to output a specific number of values off the top.
On the other hand, ranking window functions are always the most accurate and foolproof method to output a certain number of highest values.
Study SQL window functions and SQL Rank Functions to prepare for any SQL question that requires you to output X number of highest values.
Functions like RANK() and DENSE_RANK() allow you to assign ranking to rows based on the value in one of the columns. It’s important to understand the difference between these two functions.
Uber SQL Interview Question Walkthrough
Highest Total Miles
In this question, we have a table of data that describes every individual trip booked through the Uber application. Candidates are asked to find three most common purposes that motivate business accounts to use Uber for travel.
It is marked as ‘Medium’ difficulty on the StrataScratch platform, so as long as you pay attention, you should be able to find a solution. There are multiple ways to approach this Uber SQL interview question.
Highest Total Miles
Last Updated: July 2020
You’re given a table of Uber rides that contains the mileage and the purpose for the business expense. You’re asked to find business purposes that generate the most miles driven for passengers that use Uber for their business transportation. Find the top 3 business purpose categories by total mileage.
Question formulation can be a bit confusing, so you may have to look at the available data to make sense of the question.
Link to the question: https://platform.stratascratch.com/coding/10169-highest-total-miles
Available Dataset
my_uber_drives
| start_date | datetime |
| end_date | datetime |
| category | varchar |
| start | varchar |
| stop | varchar |
| miles | float |
| purpose | varchar |
Data Assumptions
This is a convoluted question, so you should read it multiple times to understand what you have to do.
For data science interview questions like this one, it’s useful to preview the final table or ask the interviewer to describe the expected output. You can use this opportunity to work backwards from the final result to understand the question.
While you’re reading the question, you should also look at actual values in the table, whenever it’s possible. This can help you get a better grasp of available data.
Let’s look at columns in this table:
start_date - The question does not ask us to calculate the duration of each trip, so we won’t need the exact date and time of when the trip started.
end_date - Similarly to the start_date column, we won’t need values from this column either.
category - We will check the values in this column to keep only the records of business expenses.
start - The pickup spot is not relevant for this question.
stop - The final destination is not relevant for this Uber SQL interview question.
miles - We need to calculate total miles for each purpose. So we are going to add up values in this column.
purpose - Our final output will include summarized total miles for each purpose. So we definitely need values in this column.
While looking at the table, pay attention to types of values in each column to understand what they represent. For instance, knowing that the ‘miles’ column contains float values can help you decide how to rank purposes by miles.
Candidates should carefully examine the purpose column and all the values in it. If you look closely, you’ll notice one important detail - some drive records contain a NULL value in this column. This is an edge case which will need to be handled.
You should take a look at the range of values in each column. Most of the values in the ‘category’ column are ‘Business’, which means that the drive was a business expense. However, if you look carefully, you’ll notice that there are some personal expenses mixed in.
Once you’ve read the question multiple times, you can start formulating your approach.
Solution Logic
This Uber SQL interview question can be hard to follow, so you should read it multiple times. One condition is to calculate total miles for business expenses only. In other words, the value in the ‘category’ column must be ‘Business’.
Break down the solution into a few manageable steps. Writing down your approach can help you stay on track. The solution to this question consists of four broad steps:
- Filtering the records
- Calculating total miles
- Ordering records
- Outputting top 3 business purposes
Filter out the records that aren’t business expenses
For the first step, we will use a simple WHERE statement to filter out the records that weren’t a business expense.
If you look at the available data, you’ll notice that some records have an empty ‘purpose’ column. In other words, the value in this column is NULL.
We will have to alter our WHERE statement to filter out non-business expenses as well as the records that have an empty ‘purpose’ column. For that, we are going to use the AND logical operator. This condition will only keep rows that meet both conditions: the value in the ‘category’ column is ‘Business’ and have some value in the ‘purpose’ column.
The first condition could be a simple equality operator to make sure the value in the ‘category’ column is equal to ‘Business’. For the second condition, we can simply write purpose IS NOT NULL and it will filter out all the empty values.
Calculate total miles for each purpose
Once we have the filtered table, we can get total miles for each purpose. For that, we are going to use the SUM() aggregate function and GROUP BY statement to summarize the results.
We will use the ORDER BY statement to arrange rows in a descending order based on the aggregate sum of miles for each purpose.
As you can see in the final table, we will have only two columns: the purpose column, which will contain unique values to represent each group, and another column, which will contain aggregate values for each purpose. Finally, we will output three highest values.
Order records in descending order based on total miles value
We can simply write ORDER BY 2 to indicate that the rows should be sorted based on the value in the second column, which contains total miles.
Output three purposes with highest total miles
The last step is to output three purposes with the highest total miles. This step could be handled in two different ways: one is using the LIMIT statement. In this case, the solution is very simple and likely to work 99.99% of the time.
The other solution is to use window ranking functions, which tend to produce more accurate results. In the sections below, we will go over both approaches to the problem.
The obvious advantage of the LIMIT statement is that it’s simple and easily readable.
The problem with using LIMIT is that data is unpredictable. There could be a tie between purposes with third and fourth highest total miles. In this case, using the LIMIT statement would ignore the fact, and still output the first three values in the table.
Ranking window functions give you more control over these edge cases. They allow you to output three highest values, including ties for the first, second or third places. If there’s a high chance of ties, ranking window functions are a more suitable option.
If we take a look at the miles column, we can see that it contains float values. Total miles will be an aggregate of values in this column. For this reason, it’s unlikely that we are going to have a tie.
In this case, it could be argued that the simplicity of the LIMIT statement outweighs the risks of getting an inaccurate result because of a tie. Still, if you want to ensure the accuracy of results, you should use one of the RANK() or DENSE_RANK() functions instead.
Some employers might prefer a more robust approach over the simplicity and readability of LIMIT, so the best thing you can do is ask. Show that you can approach the problem both ways, to display your analytical thinking and overall knowledge of SQL.
This can help you show off your ability to read the data and pay attention to nuance and details, like the fact that float values are unlikely to be tied.
If interviewers ask you to use window ranking functions, be prepared to use them. The most important thing is to show that you understand the pros and cons of both solutions.
Finally, we will have to use the AS command to name the column that stores total miles of each purpose. It should be something descriptive, such as miles_sum.
Solution Approach
Step 1: Filter the table to keep business expenses only
We can start with getting all records of business expenses.
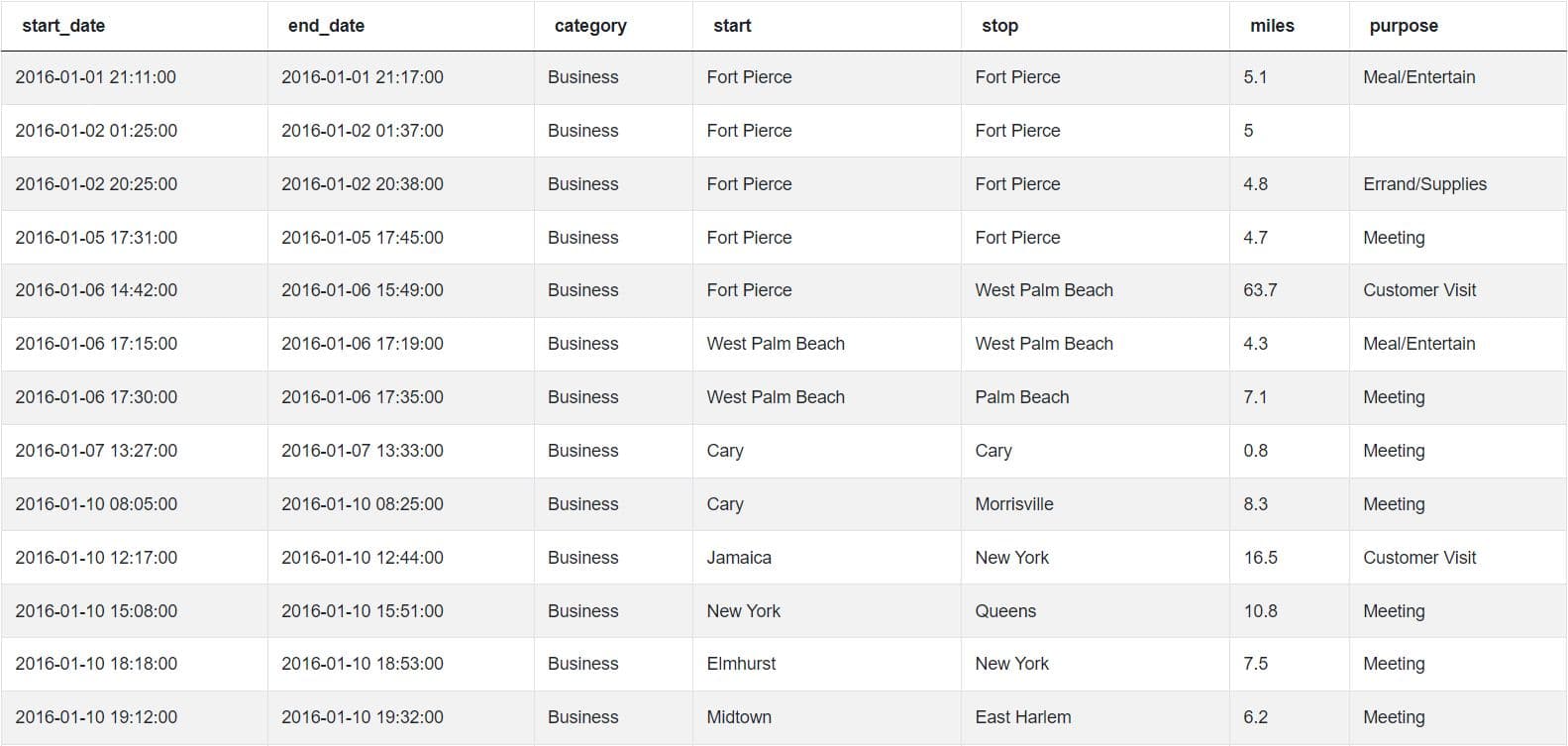
SELECT *
FROM my_uber_drives
WHERE category = 'Business'If we run this code, the output will consist of business expenses. It will look something like this:
Step 2: Get sum total of mileage for each purpose
Instead of getting an entire row, we can limit the output to two necessary columns. One is the purpose column, and the other will be generated using the SUM() aggregate function. We will use the AS command to give the column a descriptive name.
We can add GROUP BY clause to summarize total miles for each purpose.
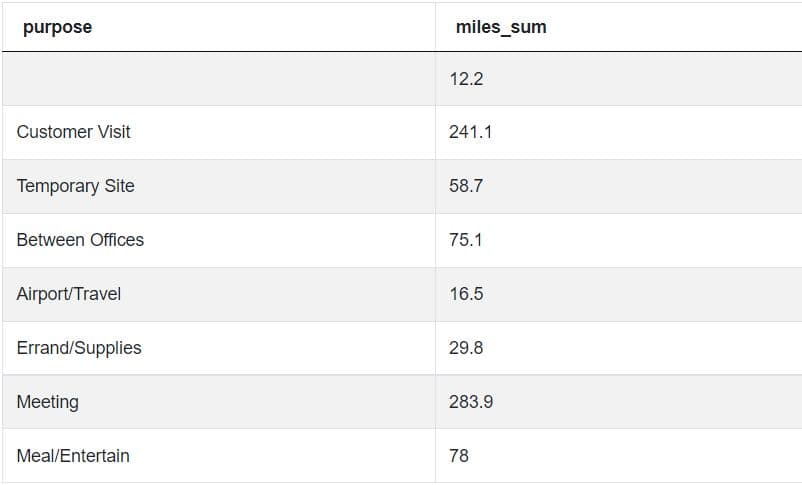
SELECT purpose,
SUM(miles) AS miles_sum
FROM my_uber_drives
WHERE category = 'Business'
GROUP BY purposeIf we run this query, we’ll get a result that’s a little bit closer to final result:
Step 3: Handle NULL purpose
The previous query returns a table that contains an empty column, representing the total miles of the records with a NULL(empty) purpose.
Currently we filter the table with one condition: to check the value in the category column and keep only business expenses.
We can use the AND logical operator to add another condition to our filter. Now, SQL will also check and keep only the values that are business expenses, and the value in the purpose column is not null.
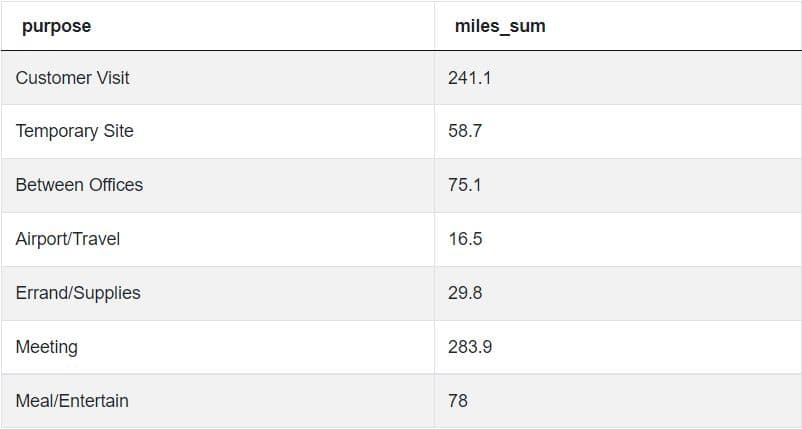
SELECT purpose,
SUM(miles) AS miles_sum
FROM my_uber_drives
WHERE category = 'Business'
AND purpose IS NOT NULL
GROUP BY purposeIf we run the code, we’ll see that the output no longer includes an empty cell.
Step 4: Order descendingly
To find the answer, we need to order purchases by their total miles. They should be arranged in a descending order, with the highest at the top and the lowest at the bottom.
We are going to use the ORDER BY statement to do that.
SELECT purpose,
SUM(miles) AS miles_sum
FROM my_uber_drives
WHERE category = 'Business'
AND purpose IS NOT NULL
GROUP BY purpose
ORDER BY 2 DESCNote that we specify the column using the number 2. SQL will interpret it and sort the records based on values in the second column, which is miles_sum.
If you run this code, you’ll see that we almost arrived at the answer:
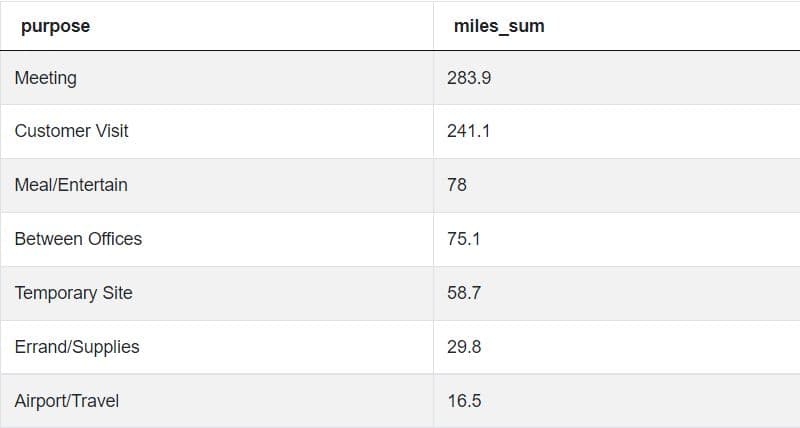
Step 5: Keep first three rows
As a final step, we need to output the first three rows. We can use a simple LIMIT statement to do so. It is a simple solution and in this case, will return a correct answer almost every time.
SELECT purpose,
SUM(miles) AS miles_sum
FROM my_uber_drives
WHERE category = 'Business'
AND purpose IS NOT NULL
GROUP BY purpose
ORDER BY 2 DESC
LIMIT 3It will give us the final, correct expected output:
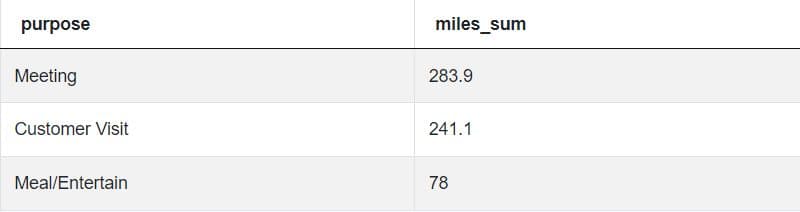
Another Right Solution
In this approach, we use a Common Table Expression (CTE in short), to filter out the records where the purpose column is empty and the category column is anything other than ‘Business’. In the CTE, we also aggregate the miles for each purpose.
We can use the SELECT statement to extract each group of purpose and their corresponding total miles from the CTE.
Then we use a RANK() window function to generate ranks for the values in a descending order. Finally, we can use another WHERE statement to only display the records where the rank value is less than or equal to three.
This approach is more robust, as it handles the edge case when the purposes might be tied by total miles.
WITH cte AS
(SELECT purpose,
sum(miles) AS miles_sum
FROM my_uber_drives
WHERE purpose IS NOT NULL
AND category ILIKE '%business%'
GROUP BY purpose)
SELECT purpose,
miles_sum
FROM
(SELECT purpose,
miles_sum,
rank() OVER (
ORDER BY miles_sum DESC) AS rnk
FROM cte) a
WHERE rnk<=3Final Words
In the last decade, Uber went from a small startup to the giant tech company it is today.
Throughout these years, data collection and analysis have remained important elements for its business model. Data scientists’ efforts allow Uber to offer a comfortable service at a reasonable price.
You can check out “Uber Data Scientist Interview Questions” to find more questions asked of data scientist candidates at Uber. Go through the practical questions at StrataScratch and refresh your knowledge of SQL to ensure that you aren’t caught off guard during the interview at Uber.
Share