The Ultimate Guide to SQL Aggregate Functions


Categories:
 Written by:
Written by:Nathan Rosidi
Aggregate Functions in SQL is the main tool for data aggregation and one of the most common topics when working with data.
Data aggregation is a process of retrieving data and presenting it in a summarized (aggregated) form suitable for data and statistical analysis.
SQL’s primary purpose is working with data, so it comes as no surprise that you can do data aggregation very easily. The functions you’ll be interested in are called, again not surprisingly, the SQL aggregate functions.
SQL Aggregate Functions
The important thing to know is that SQL aggregate functions return a single row containing the aggregated value when applied across one or several groups of values.

While every SQL dialect offers you a different number of different aggregate functions, there are five most often used ones:
- COUNT()
- SUM()
- AVG()
- MAX()
- MIN()
COUNT()
This function is used to count the number of rows within the group value. In less technical terms, it simply counts the number of rows in a column or a whole table. It’s a function that works both on numerical and non-numerical data types.
Regarding the NULL values, they are ignored and not included in the total number of rows.
SUM()
The SUM() function in SQL returns the sum of values within a specified column. It works with the numerical data types only and ignores the NULL values.
AVG()
This is again a function that works only with the numeric columns and ignores the NULL values. When used, it will return the average value of a specified column.
MAX() & MIN()
While those are the two different functions, they can be explained together since they are opposite to each other. The MAX() function returns the maximum (the highest) value, while the MIN() function returns the minimum (the lowest) value of a column.
They both ignore the NULL values and work with numerical and non-numerical values. For the numerical values, it’s intuitive what the MAX() and MIN() functions will return: the highest and the lowest number.
What happens when applied to the non-numerical values? For strings, MAX() will return the latest value in alphabetical order. It’s the same as ordering text data in descending order and displaying only the first row. With the MIN() function, it’s the other way round: returns the first value in the alphabetical order or as if you ordered data in ascending order and show the first row.
How to Use the Aggregate Functions in an SQL Code


All theory and no code makes Jack a dull boy. Jack will be happy to see how the SQL aggregate functions work in practice within three scenarios:
- SQL Aggregate functions alone
- SQL Aggregate functions with GROUP BY
- SQL Aggregate functions as window functions
SQL Aggregate Functions Alone
The most basic way of using an aggregate function is to use them alone, without any additional data grouping. This means the aggregate function is the only column in the SELECT statement.
When Would You Use It?
Doing aggregation this way returns only the result in one row. There’s no further information about the aggregated value. That’s why using the aggregate functions alone doesn’t have much analytical value. But it’s perfect when you need to quickly provide an informational value, which other uses generally don’t allow.
Sometimes you don’t need a sophisticated breakdown of data. You simply want to know how many customers there are, total sales, the average salary, or the lowest and highest number of products sold.
Example Use
One example of such aggregation is a question by Spotify:
Find the average number of streams across all songs.
Link to the question: https://platform.stratascratch.com/coding/9996-find-the-average-number-of-streams-across-all-songs
The solution to this question is:
SELECT AVG(streams)
FROM spotify_worldwide_daily_song_ranking
This simple query shows how the SQL aggregate functions work. Within the parentheses of the desired function, you need to specify the column for which you want to perform the calculation.
In this example, the code returns the average number of streams. Its output will be:
You can do the same thing with other aggregate functions.
By running the following code:
SELECT SUM(streams)
FROM spotify_worldwide_daily_song_ranking
You’ll get the total number of streams from the provided table. The output will be similar to the previous one:
Similarly, you can find the maximum and the minimum number of streams.
SELECT MAX(streams),
MIN(streams)
FROM spotify_worldwide_daily_song_ranking
The output will give you the highest and lowest number of streams without any further info.
As mentioned, we can apply these two functions to the non-numerical data, too. Let’s see how it looks:
SELECT MAX(artist) AS last_alphabetical,
MIN(artist) AS first_alphabetical,
MAX(date) AS latest_date,
MIN(date) AS earliest_date
FROM spotify_worldwide_daily_song_ranking
Here’s the output:
What this data tells us is that Zara Larsson is the last artist in the alphabetical order in the table, while Adele is the first. From the output dates, we can conclude that it’s a worldwide ranking table for the period between 1 January 2017 and 28 December 2017. In short, there’s only 2017 data.
The only function that is slightly different is the COUNT() function. Unlike the aggregate functions we’ve seen here, it’s possible to use COUNT() without specifying the particular column. You can do it, but you don’t have to. Whether you use the asterisk (*) or the table column, the result will be the same.
SELECT COUNT(*),
COUNT(streams)
FROM spotify_worldwide_daily_song_ranking
The COUNT(*) will count the number of rows in the whole table. The COUNT(streams) will count the number of rows within the column streams.
Be aware that the result will be the same only if there are no NULL values. If there are, these two versions of the COUNT() function will behave differently.
The COUNT(*), as we mentioned earlier, counts the number of rows in the whole table. Therefore, it will include the rows with the NULL values too.
The COUNT(streams) will return only the number of rows that are not NULL.
Now it’s your turn to play with a code. Use the widget below:
SQL Aggregate Functions With GROUP BY
Using the aggregate functions with the GROUP BY clause is more common. The GROUP BY extends the possibilities of the aggregation. Its purpose is to put one or multiple columns’ rows into groups with the same value.
By specifying multiple columns in the GROUP BY, you’re increasing the number of groups data will be grouped into.
Use it with the aggregate functions, and you won’t be limited to only returning the aggregate value. No, you’ll also be able to get other data from the table that will add more meaning to the aggregate values.
When Would You Use It?
The GROUP BY adds an analytical dimension to data aggregation, with the output looking more like data analysis.
Instead of aggregating all available data, for instance, showing the total sum, when using the GROUP BY, you can also aggregate on data subset levels. For instance, find the total sales by product, branch, or salesperson. Or do the same with the average sales or salary by the department. You can use MAX() & MIN() functions to find the latest order by the customer, latest login, stream, or activity by user. Or you can count users, customers, employees according to date periods, locations, or any other different category.
Example Use
Our showcase example here will be a question by the City of San Francisco.
Find the total renewals per library. Output the home_library_definition and its corresponding total number of renewals and order the results by total renewals in descending order.
Link to the question: https://platform.stratascratch.com/coding/9930-find-libraries-with-the-highest-number-of-total-renewals
To solve the question, you need this code:
SELECT home_library_definition,
SUM(total_renewals) AS total_lib_renewals
FROM library_usage
GROUP BY home_library_definition
ORDER BY total_lib_renewals DESC
Same as in the previous example, we’re using the aggregate function on a table column. In this case, it’s a SUM() function applied to the column total_renewals, with the result being shown in the new column total_lib_renewals.
If we selected only this column, we would get only the total number of renewals. However, we also selected the column home_library_definition, which indicates that we want to see the number of renewals by the library. They need to be summed because one library appears several times with a different number of renewals, depending on some other criteria such as age range, patron type definition, etc., as you can see below on an example data.
Any other columns appearing in the SELECT statement have to be listed in the GROUP BY clause when using aggregate functions. This is what is done in the code above. That will result in an output that shows the total number of renewals per library.
The result is also ordered by the number of renewals in descending order, just as the question asks.
Now we can use the same code to add all other aggregate functions.
SELECT home_library_definition,
SUM(total_renewals) AS total_lib_renewals,
AVG(total_renewals) AS average_lib_renewals,
MAX(total_renewals) AS maximum_lib_renewals,
MIN(total_renewals) AS minimum_lib_renewals,
COUNT(*)
FROM library_usage
GROUP BY home_library_definition
ORDER BY total_lib_renewals DESC
The principle is the same as with the SUM() function. The AVG() will give you the average number of renewals per library.
The MAX() and MIN() functions will return the highest and lowest number of renewals per library.
We also added the COUNT() function to see how many times each library appears in the table. That will allow us to see how the calculation of the average works.
Why average? Because the number of renewals appears several times, depending on the patron type definition, age range, and time period. To get the average, you’ll need to divide the total number of renewals per library by the number of instances, rows, or categories the particular library has in the table.
Take Ortega library, for example. There are 2,421 total renewals in that library. The column count shows 7. You calculate the average this way: 2,421/7 = 345.857. This is precisely the number that appears in the column average_lib_renewals.
Other columns show that Ortega library’s highest number of renewals per category is 2,355, while the lowest number is 0.
To understand how the aggregate functions work with the GROUP BY clause, try using the widget below:
SQL Aggregate Functions as Window Functions
The most complex way of data aggregation we will show you here is the window functions.
The SQL window functions and aggregate functions are similar but are not the same. The aggregate functions return one aggregated value and lose the corresponding individual rows. The window functions allow you to aggregate data and maintain the individual rows.
There are four types of window functions:
- Aggregate window functions
- Ranking window functions
- Distribution window functions
- Analytic window functions
If you need examples of other window functions, there’s an article for you. Here, we’ll only talk about the aggregate window functions. They are the same five aggregate functions we mentioned earlier. The key to transforming them from ‘plain vanilla’ aggregate functions to the window aggregate functions is the OVER() clause.
When Would You Use It?
The aggregate window functions are like the ordinary aggregate functions on steroids, which provides a whole new level of data analysis. The main point of the window functions is to show the individual rows and aggregated values simultaneously. Using the aggregate functions with the GROUP BY clause doesn’t allow that because it will group the same values.
For instance, you can use it to show the average or total sales per location and product while at the same time displaying all locations and every product individually at every location. Or you can count the number of orders by user and time period, keeping all the user and time period info too. Finding the maximum and minimum values or counting them works the same way.
Here’s a Credit Karma example of how you do that:
Last Updated: February 2021
Write a query to return the total loan balance for each user based on their most recent "Refinance" submission. The submissions table joins to the loans table using loan_id from submissions and id from loans.
Link to the question: https://platform.stratascratch.com/coding/2003-recent-refinance-submissions
You’ll need the MAX() window function to solve this problem.
SELECT l.user_id,
SUM (balance)
FROM
(SELECT DISTINCT id,
user_id,
created_at,
MAX(created_at) OVER (PARTITION BY user_id, type) AS most_recent
FROM loans
WHERE type = 'Refinance') AS l
LEFT JOIN submissions s ON l.id = s.loan_id
WHERE most_recent = created_at
GROUP BY l.user_id
The query first selects the column user_id from the subquery and calculates the total balance per user using the SUM(). It’s a plain aggregate function, not the window aggregate function.
The subquery outputs the loan ID, user ID, and the date the record is created.
The last column is the most interesting one. It’s named most_recent and contains the date of the most recent submission. This is achieved by using the MAX() function over the column created_at. Then by writing the OVER() clause, we can make it an aggregate window function. In the OVER clause, you can specify columns you want to use for aggregation. You do that in the PARTITION BY clause. You can look at it as a kind of GROUP BY for window functions. That way, we can get the most recent submission date according to the user and loan type.
Since we’re only interested in the refinance, we specified that in the WHERE clause.
Remember the window functions do not lose individual columns when doing aggregation. That’s why this subquery alone can output all the users, all their refinance submissions and also show a date of the most recent refinance submission.
Here’s what the mentioned subquery will output if run on data:


Take a user 100, for example, that appears in the first, second, and last row. This user’s refinance applications have the IDs 1, 2 & 11, created on 2017-04-21, 2017-04-27, and 2015-04-21. The most_recent column shows the date of the latest refinance application, which is 2017-04-21.
This output is then joined with the table submissions and grouped the user ID.


You can also find the total loan balance of the user’s oldest refinance submission by simply using the MIN() instead of the MAX() window function in the subquery. Once you do that, the subquery’s output will be:

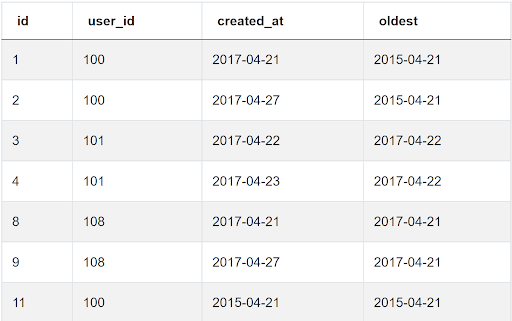
The output looks the same as with the previous subquery. The only difference is the last column shows the oldest refinance submission. For user 100, that’s a 2015-04-21 submission.
The output of the whole code will be:


Using other aggregate window functions can get the average and total balance per loan type and rate type.
SELECT DISTINCT type,
rate_type,
AVG(balance) OVER (PARTITION BY type, rate_type) AS average_balance,
SUM(balance) OVER (PARTITION BY type, rate_type) AS sum_balance
FROM loans l
JOIN submissions s ON l.id = s.loan_id
The code will return the output shown below.
If you want to show loan status and type, along with the number of loans per type, you should write the code below.
SELECT DISTINCT status,
type,
COUNT(*) OVER (PARTITION BY type) AS loans_per_type
FROM loans
ORDER BY type
And the output looks like we expected.
What does this output tell us? At first sight, it looks like there are seven refinance loans with the prequal_completd_offer status, then seven refinance loans with the prequal_completd_no_offer, etc. This is not the case! The column loans_per_type shows the total number of refinance loans, seven. It also shows there are two InSchool loans and two Personal loans. Since we also wanted to see loans’ different statuses, the total number of loans per type is simply repeated in the column loans_per_type.
How about you show what you learned and solve one question by yourself now? Have a look at the question by Spotify and try to solve it.
Find the number of days a US track has stayed in the 1st position for both the US and worldwide rankings on the same day. Output the track name and the number of days in the 1st position. Order your output alphabetically by track name.
If the region 'US' appears in dataset, it should be included in the worldwide ranking.
Do you need a hint? The aggregate window function you should use here is SUM().
Use the widget below to write an answer. You could also use the question’s dataset to think of examples of how you could use other aggregate window functions and write them in the widget too.
Conclusion
The main tool for data aggregation in SQL is the aggregate functions. The most popular ones allow you to calculate sums, averages, minimum and maximum values, or count the number of rows.
Their use can be the most basic one when they are used alone. The more complex types of aggregations happen when you use the aggregate functions with the GROUP BY clause or as window functions.
Several examples we’ve shown you should be just a starting point for mastering the aggregation in SQL. You can find much more examples and opportunities to practice here → SQL Interview Questions.
Share


