An Introduction to the SQL Rank Functions

Categories:
 Written by:
Written by:Nathan Rosidi
This introduction covers two of the most common SQL Rank Functions, their differences, and how to use them.
In the data world, SQL serves as the universal language, and companies consider it the most important skill for their data science teams.
These companies value SQL so much because it is the main technology to use during the data wrangling phase where much of the data exploration, data manipulation, pipeline development, and dashboard building happens.
What separates high performing data scientists from their colleagues is the ability to wrangle data to the full extent to which SQL allows them. More specifically, they use and experiment with a variety of SQL capabilities such as window functions to best handle the data. While this article doesn’t go into detail regarding windows functions in general, you can find more information in StrataScratch’s Ultimate Guide to SQL Window Functions.
What this article will cover more specifically is a subtype of these functions they call ranking window functions which assign ranks to rows of ordered data based on a specific column of the data. There’s no obvious equivalent which doesn’t use windows and avoiding these ranking window functions typically results in too many nested queries and an inefficient solution. As a result, they’re the most common window functions.
Two ranking windows functions RANK() and DENSE_RANK() both assign a rank to rows of ordered data, but they have a critical difference which you must understand to avoid incorrect outputs and inconsistencies. We’ll begin by explaining the two, then cover their differences, and finally explain how to use them.
What is the RANK() Function in SQL
The RANK() function gives each row a rank according to a specific ordering. One notable feature of this SQL rank function is it will apply the same rank to values which match, so it’s possible to receive two rank 1’s for example. It will then add the tied rows to produce the next rank, so if you have two rank 1’s then your next rank will be 3 with a gap in the rankings where rank 2 would otherwise be. Therefore, when the rank increments, it always matches the number of rows corresponding to that rank.
Here’s a result of using the RANK() function from our article on a common Facebook SQL Interview Question about finding the highest energy consumption among data centers across a variety of dates:
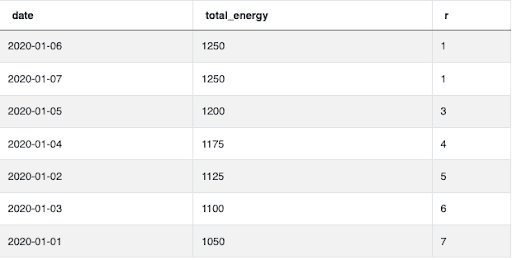
Since there is a tie for the two date’s with the most energy consumption, both corresponding rows have a rank of 1. However, the next highest energy consumption has a rank of 3 instead of 2. Therefore, rank 3 corresponds to 3 rows of data BUT NOT the three highest discrete values.
As far as syntax goes, the rank function typically looks like this:
RANK() OVER ([PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...)Where PARTITION BY divides the rows by a particular row serving as a partition and ORDER BY specifies the logical sort order. We’ll cover specific code blocks with the RANK() function later in this article.
When it comes to output, the RANK() function is useful for reports where your goal is to find the top-n or bottom-n results.
What is the DENSE_RANK() Function in SQL
The SQL DENSE RANK function also gives each row a rank according to a specific ordering. However, the defining outcome of the DENSE_RANK() function is it will apply the same rank to values which match, but it will not permit gaps in the ranking. So if you have two matching values which receive rank 1, the next ranked value will receive rank 2 even if it’s the third row. Therefore when the rank increments, you can not know for sure if the ranking and number of rows are equal.
Using the same data from the Facebook Interview Question in the previous section, we instead apply DENSE_RANK():
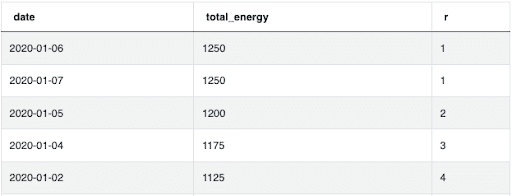
Here we see the tie for the top two rows still results in rank 1, but the 3rd row is instead assigned a rank of 2 instead of 3. Therefore, rank 2 DOES NOT correspond to 2 rows of data but rather to the 2nd highest discrete value.
The syntax of the DENSE_RANK() function looks almost identical to RANK():
DENSE_RANK() OVER ([PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...)Where PARTITION BY similarly divides the rows by a particular row as a partition and ORDER BY again specifies the logical sort order. We’ll cover a real example of DENSE_RANK() later in this article.
Dense rank is sometimes insufficient for finding top-n results but is instead useful for returning top-n or bottom-n discrete values.
RANK vs DENSE_RANK

The critical difference between RANK() and DENSE_RANK() has to do with how they increment ranks. RANK() will skip the next rank if there is a tie in data, so if you have two rank 1’s, the next rank will be rank 3. DENSE_RANK() will not permit gaps in ranks and will always increment even if there is a tie. So if you have two rank 1’s, the next rank will always be rank 2.
As a result, for some solutions RANK and DENSE_RANK will still provide the correct answer. For instance, if your goal is to find the first rank for any given solution, both functions will typically work. Recall from our Facebook Question in the previous sections RANK() and DENSE_RANK() both return the same results for the 1st rank:
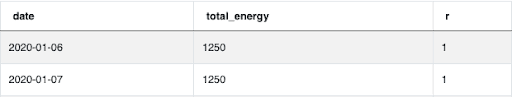
However, if you need to find the top n discrete values then you need to use a DENSE_RANK() as RANK() will skip rank n in cases of ties, and you most likely won’t know in advance how many ties there are in the data. For example, if the Facebook SQL Interview Question had asked us to find all dates with the two highest different energy consumption values, it would be more appropriate to use a DENSE_RANK() and filter by ranks lesser or equal to 2:
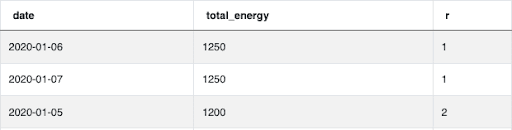
Whereas the RANK() function will skip the 2nd rank value due to a tie:

If you need to find the top n results, you use a RANK() function because you want ties in the data to increment the rank. For example, if the original question asked us to find the top 4 results, it would be more appropriate to use a RANK() function and filter where the rank is less than or equal to 4 since the ties for first place will increment the rank and prevent excessive results:
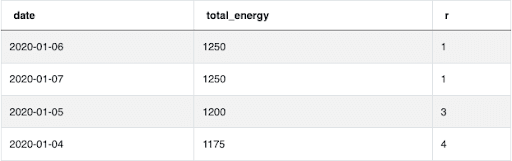
Whereas using DENSE_RANK() here would result in 4 discrete values (and too many results) instead of the top 4 ranked results:
One important caveat to keep in mind is the top-n ranked results doesn’t mean only n rows of data in the output as ties will sometimes increase the number of rows in the output beyond n. In most cases, this still provides a technically correct answer such as in the RANK() example problem later in this article.
How to Use SQL Rank Functions

While we’ve already gone over the syntax for the RANK and DENSE_RANK window functions and when to use one over the other, it’s important to understand how to use these SQL rank functions to answer realistic problems.
First, when you’re asked to find the top or bottom n of some set of data, you should immediately think about leveraging either RANK() or DENSE_RANK(). In most cases, you’ll usually have to manipulate the data to some extent before ranking, and you’ll often need to filter the rank for the top or bottom n results or discrete values.
Since you’re ranking by the data itself, you’ll always need to ORDER BY at least one column. Note the ranking doesn’t require an integer and could instead be a string, character, or other orderable data type. You can also still rank over multiple ordered columns either ascending or descending.
You’ll then usually have to filter the ranks, and this typically involves the use of a WHERE comparison. Although there are other ways to filter, this is the most common method and typically comes at the end of the query. Returning to our Facebook SQL Interview Question, the solution shows how one might use the WHERE function to filter for the first rank:
SELECT date, total_energy
FROM
(SELECT date, sum(consumption) AS total_energy,
RANK() OVER (
ORDER BY sum(consumption) DESC) AS r
FROM
(SELECT *
FROM fb_eu_energy
UNION ALL SELECT *
FROM fb_asia_energy
UNION ALL SELECT *
FROM fb_na_energy) fb_energy
GROUP BY date) fb_energy_ranked
WHERE r = 1Finally, it’s always critical to understand the difference. Use RANK() when you need top or bottom n results and gaps in the ranking don’t matter, and use DENSE_RANK() when you need top or bottom n discrete values and can’t have gaps in the ranking! Here are two examples of where the use of RANK() or DENSE_RANK() matters for a correct solution.
RANK() Function Example:
The question we’ll be looking at here is a common Yelp data science interview question.
Find the top 5 cities with the most 5 star businesses
Find all cities ranked in the top 5 by number of 5-star businesses, using standard competition ranking where ties receive the same rank and the following rank is skipped.
The output should include the city name and the total count of 5-star businesses in that city, considering both open and closed businesses.
Link to the question: https://platform.stratascratch.com/coding/10148-find-the-top-10-cities-with-the-most-5-star-businesses
The crucial information telling us to use a RANK() function here is finding the top 5 cities which more generically is finding the top-n results instead of top-n discrete values. If the question had instead asked for the top 5 number of 5-star businesses, we would use DENSE_RANK().
Ultimately, the answer ends up looking like this:
WITH cte_5_stars AS
(SELECT city,
count(*) AS count_of_5_stars,
rank() over(
ORDER BY count(*) DESC) AS rank
FROM yelp_business
WHERE stars = 5
GROUP BY 1)
SELECT city,
count_of_5_stars
FROM cte_5_stars
WHERE rank <= 5
ORDER BY count_of_5_stars DESC;Note the RANK() function doesn’t include a partition nor does it require one! To better illustrate why RANK() is necessary here, we’re going to add the rank column to our selection and remove the WHERE filter for our output data:
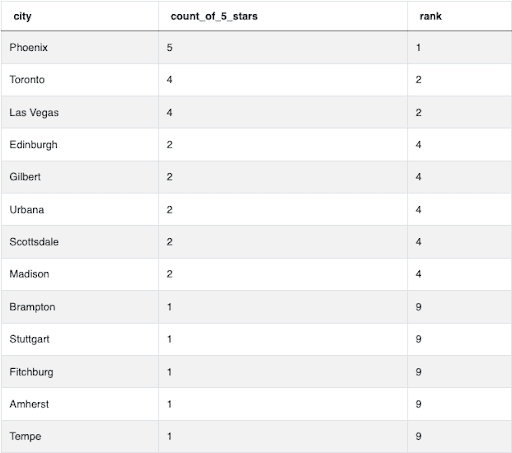
The data shows several ties for which the RANK() function will accordingly create gaps in the rankings. It’s important to point out the result is going to return more than 5 cities. However, this is still technically correct considering the multi-way tie for fourth place!
Using RANK() allows us to avoid all the cities with only a single 5-star business which would otherwise have a rank of 4 when using a DENSE_RANK(). These would end up passing the WHERE filter and yielding an incorrect answer:
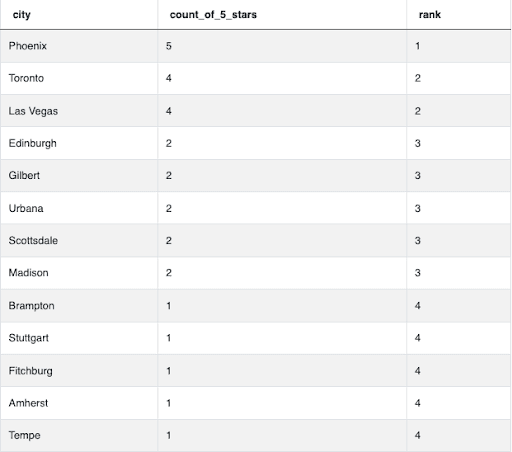
DENSE_RANK() Example:
The question we’ll be looking at here is a common Airbnb data science interview question.
Ranking Most Active Guests
Identify the most engaged guests by ranking them according to their overall messaging activity. The most active guest, meaning the one who has exchanged the most messages with hosts, should have the highest rank. If two or more guests have the same number of messages, they should have the same rank. Importantly, the ranking shouldn't skip any numbers, even if many guests share the same rank. Present your results in a clear format, showing the rank, guest identifier, and total number of messages for each guest, ordered from the most to least active.
Link to the question: https://platform.stratascratch.com/coding/10159-ranking-most-active-guests
The key detail here is the request to not skip rankings if the preceding rankings are identical. Since we’re not tasked with finding a top-n of rank or discrete values, this is the only information we have to conclude we must use DENSE_RANK() which doesn’t permit gaps in the rankings. Ultimately, the answer looks like this:
SELECT DENSE_RANK() OVER(
ORDER BY sum(n_messages) DESC) AS ranking,
id_guest,
sum(n_messages) AS sum_n_messages
FROM airbnb_contacts
GROUP BY id_guest
ORDER BY sum_n_messages DESC;While this DENSE_RANK() doesn’t rank over a partition, it does rank over an ordering of the sum of messages which is the only necessary condition to use a DENSE_RANK() window function. As a result, we can see there are no gaps in the output rankings:

If we instead use RANK() in our solution we see there are several gaps in the rankings due to ties in the data:
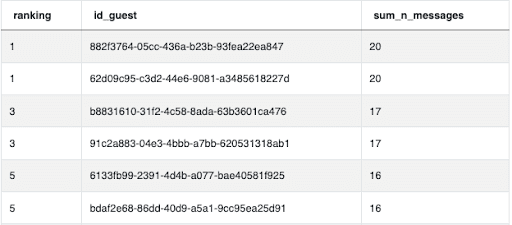
Conclusion
In this article, we covered two of the most common SQL Rank Functions in detail. We covered the uses and differences between the RANK and DENSE_RANK window functions. It’s critical to understand these SQL rank functions in depth since they are commonly used to answer data science interview questions. Even if you correctly use one over the other, it helps to know the difference since the interviewer may ask why you used it.
You can practice answering more SQL interview questions here using the SQL rank functions and other techniques. You’ll get to code solutions to them and perhaps come up with a creative or more effective approach. Then you can post your ideas to benefit from the feedback of other users while also having the opportunity to take a look at their solutions for inspiration.
Share