Self-Supervised Learning Guide: Super simple way to understand AI


 Written by:
Written by:Nathan Rosidi
Unlock the power of AI without extensive labeled data through our comprehensive guide to Self-Supervised Learning, where algorithms teach themselves.
Did you know that over 90% of the data in the world today was generated in the last two years alone?
This fact comes from the latest study by Statista and insights from Bernard Marr & Co., which shows the importance of self-supervised learning, where algorithms learn to understand and take advantage of data without explicit human intervention.
In this guide, we'll explore the techniques of self-supervised learning by doing several projects. These can be extended into real-life portfolio projects, where you can showcase your skills to land your desired job! Let’s start with the fundamentals first!
What is Self-Supervised Learning?
Self-supervised learning is a type of machine learning halfway between supervised and unsupervised learning. It is like supervised learning in that it generates labels rather than requiring labeled examples.
It still needs many unlabeled examples. However, since an individual’s labeling efforts don’t generally serve as very high-quality labels, this technique relies more on the vast amount of unlabeled data than human data labeling.
The concept of this kind of machine learning is that the ideal scenarios for the learning process require the model to predict parts of its input. This “missing” part may be a subsequent word in a piece or image.
Exploring Learning Paradigms: Self-Supervised, Supervised, and Unsupervised Learning

But before knowing what self-supervised learning is, you need to know more about other learning types, like supervised or unsupervised learning. In the meantime, we’ll see one data project example from our platform to solidify what you have learned. Let’s start!
Supervised Learning
This is where a model is trained using labeled data. Each example in the training set has an input with the correct output. This label is the learning goal for the model.
Once it has learned to map inputs to outputs from the labeled data, it can be used to map new examples. This is the most used learning type in machine learning, so let’s examine one example from our platform.
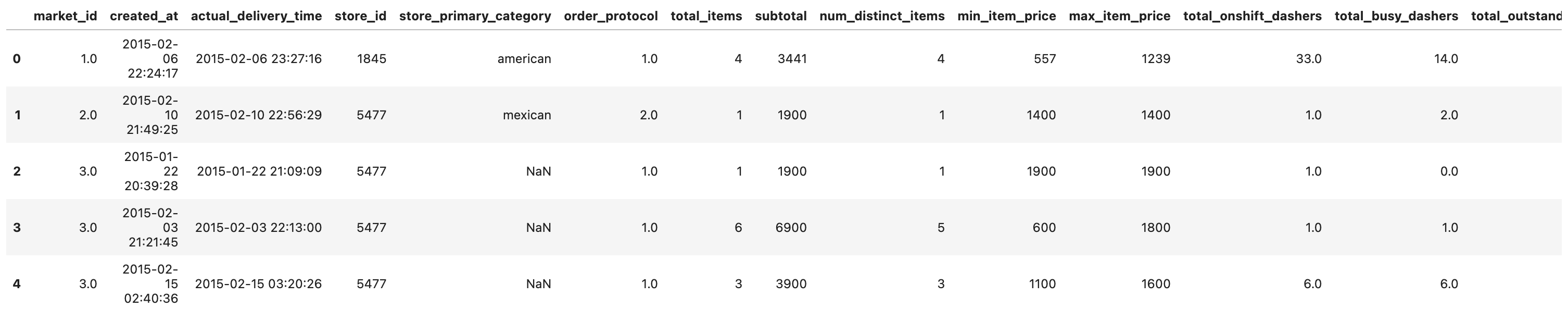
This data project aims to predict the delivery duration of Doordash's food orders. Here is our dataset.
# read data
historical_data = pd.read_csv("historical_data.csv")
historical_data.head()Here is the output.

After doing a lot of transformation, let’s go to the end of our projects and let’s see this high-level code, where we applied a lot of different models at once like;
- Ridge
- Decision Tree
- Random Forest
- XGBoost
- LGBM
- MLP
Here is the code:
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.neural_network import MLPRegressor
from sklearn import tree
from sklearn import svm
from sklearn import neighbors
from sklearn import linear_model
pred_dict = {
"regression_model": [],
"feature_set": [],
"scaler_name": [],
"RMSE": [],
}
regression_models = {
"Ridge" : linear_model.Ridge(),
"DecisionTree" : tree.DecisionTreeRegressor(max_depth=6),
"RandomForest" : RandomForestRegressor(),
"XGBoost": XGBRegressor(),
"LGBM": LGBMRegressor(),
"MLP": MLPRegressor(),
}
feature_sets = {
"full dataset": X.columns.to_list(),
"selected_features_40": importances.sort_values(by='Gini-importance')[-40:].index.tolist(),
"selected_features_20": importances.sort_values(by='Gini-importance')[-20:].index.tolist(),
"selected_features_10": importances.sort_values(by='Gini-importance')[-10:].index.tolist(),
}
scalers = {
"Standard scaler": StandardScaler(),
"MinMax scaler": MinMaxScaler(),
"NotScale": None,
}
# examine the error for each combination
for feature_set_name in feature_sets.keys():
feature_set = feature_sets[feature_set_name]
for scaler_name in scalers.keys():
print(f"-----scaled with {scaler_name}-------- included columns are {feature_set_name}")
print("")
for model_name in regression_models.keys():
if scaler_name == "NotScale":
X = train_df[feature_set]
y = train_df["actual_total_delivery_duration"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
make_regression(X_train, y_train, X_test, y_test, regression_models[model_name], model_name, verbose=True)
else:
X_scaled, y_scaled, X_scaler, y_scaler = scale(scalers[scaler_name], X[feature_set], y)
X_train_scaled, X_test_scaled, y_train_scaled, y_test_scaled = train_test_split(
X_scaled, y_scaled, test_size=0.2, random_state=42)
_, y_predict_scaled, _, _ = make_regression(X_train_scaled, y_train_scaled[:,0], X_test_scaled, y_test_scaled[:,0], regression_models[model_name], model_name, verbose=False)
rmse_error, y_predict = rmse_with_inv_transform(y_scaler, y_test, y_predict_scaled, model_name)
pred_dict["regression_model"].append(model_name)
pred_dict["feature_set"].append(feature_set_name)
pred_dict["scaler_name"].append(scaler_name)
pred_dict["RMSE"].append(rmse_error)
Here is the part of our output:

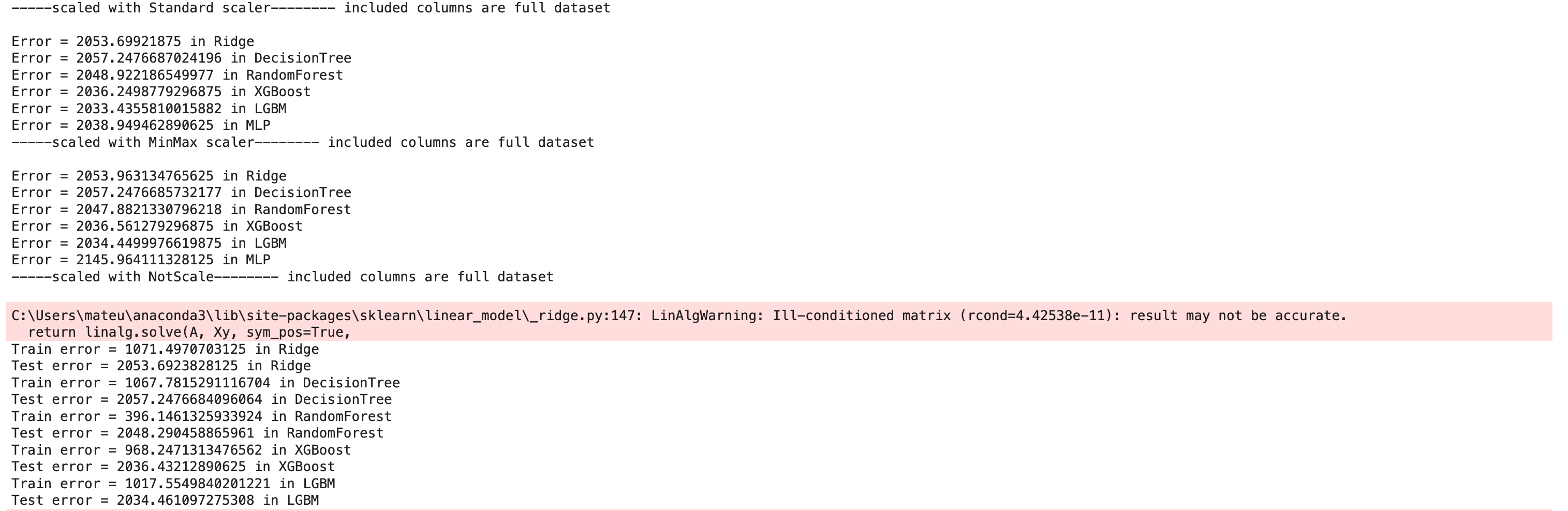
Here, these regression models have been used to predict delivery_duration. This feature is generated by doing mathematical calculations(created_at - actual_delivery_time),
So this delivary_duration became our label for this example, and this makes our problem supervised learning.
If you want to know the differences between Supervised and Unsupervised learning, check this one before - “Supervised vs Unsupervised Learning”.
Unsupervised Learning
In a model using unsupervised learning, the data is unlabeled. The objective is to learn the underlying structure of the data or different patterns, such as data clustering or data associations.
There are too many things to discover, but we did focus on self-supervised learning for this one, so if you want to know unsupervised learning, check this one - “Unsupervised learning algorithms”.
Self-Supervised Learning
Self-supervised learning is a type of learning that can happen both with and without supervision. It uses the data to create the justification from which a model learns.
Sometimes, the model must predict the next word in the text. Almost all modern NLP models, including text-2-image systems, have used language models.
Applications of Self-Supervised Learning

Self-supervised learning has shown remarkable success across various domains. Here are some applications:
Natural Language Processing (NLP)
The models are trained through language modeling tasks, such as BERT(Bidirectional Encoder Representations from Transformers), used in NLP.
Random words are masked in a sentence during this task, and the model should predict them. This has shown perfect performance improvement in language understanding tasks.
Decoding Emotions: Sentiment Analysis Using BERT
In our exploration of self-supervised learning, we'll show how BERT (Bidirectional Encoder Representations from Transformers), trained initially through self-supervised learning, can be effectively applied to sentiment analysis.
This example involves encoding a movie review, using BERT to derive sentence embeddings, and applying a simple rule-based classifier to determine the sentiment. Here is the code.
# Example text for sentiment analysis
text = "I love the new Spider-Man movie! It's fantastic with great special effects."
# Assuming tokenizer and model are already loaded as per previous code
# Encode the text
encoded_input = tokenizer(text, return_tensors='pt')
# Forward pass to get hidden states
output = model(**encoded_input)
# Use the [CLS] token as a sentence representation for classification
sentence_embedding = output.last_hidden_state[:, 0, :]
# Simulate a sentiment classifier (in practice, this would be a trained classifier)
def dummy_sentiment_classifier(embedding):
# Here we just use a rule-based mock-up for demonstration purposes
return "positive" if embedding[0, 0].item() > 0 else "negative"
# Get the sentiment prediction
sentiment_prediction = dummy_sentiment_classifier(sentence_embedding)
print(f"The predicted sentiment is: {sentiment_prediction}")
Here is the output.


The ability of BERT in the above output to predict the sentiment of the textual content demonstrates how well it can comprehend and process a text's meaning. Therefore, this example shows the usefulness of self-supervised learning models such as BERT in applying sentiment analysis.
Of course, you can use this sentiment analysis to do further sentiment analysis, like a sentiment analysis of the previous tweets, to predict the presidential election.
Computer Vision
In computer vision, the self-supervised learning process usually means predicting the parts of an image that are masked or returning the order of an image stride. It allows models to see many different levels of features for object detection and image segmentation.
A Self-Supervised Approach to Computer Vision
This code example is a simple demonstration of the beginning stages of a self-supervised computer vision task: our neural network, a single convolutional layer, processes batches of example images from the CIFAR-10 dataset.
The purpose is to train this model to predict or reconstruct parts of the input image, helping it generalize from patterns seen during this training. Let’s see the code.
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
# Load dataset
dataset = CIFAR10(root='./data', train=True, download=True, transform=transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
# Define a simple convolutional neural network
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.layer1 = nn.Conv2d(3, 16, 3, padding=1) # Input channels, output channels, kernel size
def forward(self, x):
x = self.layer1(x)
return x
# Initialize model
model = ConvNet()
# Example training loop (simplified)
for images, _ in dataloader:
outputs = model(images) # Forward pass
# Normally you would include a loss function and optimizer step here
Here is the output.


The code shows how the computer views an image. Each photo has 16 variations. The computer attempts to solve a puzzle by examining the image multiple times.
This is considered a self-supervised method, where you teach the computer to start guessing what it sees in the pictures or what it expects to happen next in the video (without labeled data).
It is like putting glass on the computer, which allows it to understand and anticipate visuals without needing anyone to guide it.
Tools, Libraries, and Frameworks

TensorFlow and PyTorch are among the most popular frameworks for deploying models in machine learning. If you want to know more about AI libraries, check out this one.
As discussed in the earliest section, these programming frameworks could develop and train self-supervised learning models using dynamic computation graphs and hardware acceleration (such as GPUs).
Below, we provide an overview of how different self-supervised learning tasks can be formulated using Tensorflow.
Tensorflow: Self-Supervised Model Architectures
The TensorFlow example below illustrates self-supervised learning in more detail through code. It is a model of self-supervised tasks with the architecture to process and reconstruct CIFAR-10 images.
Essentially, the model learns to predict the input from the modified version. In this case, the input image is noised or partially occluded. Let’s see the code.
import tensorflow as tf
# Load and preprocess the CIFAR-10 dataset
(x_train, _), (x_test, _) = tf.keras.datasets.cifar10.load_data()
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# Define a simple CNN in TensorFlow
model = tf. keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(32, 32, 3)),
tf.keras.layers.Conv2D(filters=16, kernel_size=(3, 3), padding='same', activation='relu')
])
# Define a self-supervised task - predicting pixel values of a shifted image
def self_supervised_task(image_batch):
# Shift images to the right by one pixel
shifted_images = tf.roll(image_batch, shift=1, axis=2)
return shifted_images
# Apply the self-supervised task to the training data
shifted_images = self_supervised_task(x_train)
# Compile the model, assuming we have a custom loss function for the self-supervised task
model.compile(optimizer='adam', loss='mse')
# Example training call (simplified)
model.fit(shifted_images, x_train, epochs=5, batch_size=32)
Here is the output.


The above output captures the model learning the task of reconstructing the original images better as training progresses, which is a self-supervised task.
The average loss continues to decrease over the different epochs, so the model is improving in image reconstruction.
The fact that the MSE is very low in this case means that we successfully trained this model. The success of self-supervised training is related to the fact that the model can predict from inference the right features from its structure without being taught using labeled images.
Hugging Face: Transforming Images into Text
Hugging Face offers ready models that allow you to do many things, like turning the image into the text.
These models are created using self-study algorithms. Therefore, explicit supervision of the content and the relationship between the image and the text is unnecessary. How does it work?
Now, let’s turn the image above to the text. Here is the code.
from transformers import VisionEncoderDecoderModel, ViTFeatureExtractor, GPT2Tokenizer
from PIL import Image
import requests
# Load the pre-trained VisionEncoderDecoder model
model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
# As ViTFeatureExtractor is deprecated, if available, we should use ViTImageProcessor.
# However, let's continue with ViTFeatureExtractor as an example here
feature_extractor = ViTFeatureExtractor.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
# Load the correct tokenizer that matches the pre-trained model
tokenizer = GPT2Tokenizer.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
# Load an image from the local file system
image_path = "/Users/randyasfandy/Desktop/Leonardo Photos/digital_image.jpg"
image = Image.open(image_path)
# Process the image
inputs = feature_extractor(images=image, return_tensors="pt")
pixel_values = inputs.pixel_values
# Generate text with the model
output_ids = model.generate(pixel_values)
caption = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(f"Generated caption: {caption}")
Here is the output.


The output of this code is the model-generated text caption for the image describing it.
The model generates the text sequence that might be considered a caption through self-supervised learning-based knowledge.
This output is a caption that explains how a more complex task, such as image captioning, could be executed by the model using self-supervised learning approaches described above, combining visual elements and linguistics into a sentence.
Resources for Datasets and Benchmarks
Datasets and benchmarks are the foundations of machine learning study and development, enabling models to be trained, assessed, and compared. Self-supervised learning mainly necessitates such a corpus to extract patterns and features from data lacking explicit labels.
Datasets for NLP and Computer Vision
- BookCorpus: A large corpus of books was used to pre-train BERT, allowing the model to better understand language structure and storytelling ability.
- Wikipedia Corpus: Wikipedia articles dump is used to pre-train different language models, including BERT, and enable the model to understand various knowledge and topics. You can check this one from here.
- CIFAR-10: In our image prediction examples, the data contains 60,000 32×32-color images in 10 classes, with 6000 images per class. It is excellent for object recognition tasks in a self-supervised learning system. You can check this one from here.
- MS COCO (Microsoft Common Objects in Context): A common dataset that includes all the images and text used to train and evaluate models on tasks such as image classification.You can check this one out here.
Benchmarks for NLP and Computer Vision
- GLUE (General Language Understanding Evaluation): A broad range of NLP tasks enables sentiment analysis, textual entailment, and similarity prediction across sentences.
- SQuAD (Stanford Question Answering Dataset): The comprehension dataset with questions on a Wikipedia set asked by the crowd.
- ImageNet Large Scale Visual Recognition Challenge (ILSVRC): The ImageNet Large Scale Challenge focuses on object detection and mainly uses image classification. It is an endpoint for models pre-trained with self-supervised tasks on the ImageNet dataset.
- COCO Captions: The addition of COCO provides the image captioning benchmarks and descriptive text for generating models.
Example of Resource Utilization
For sentiment analysis tasks with BERT, the GLUE benchmark will generally measure the model’s capability to understand language nuances for various measuring tasks. Hence, after self-supervised pre-training, the approach of evaluating BERT for SQuAD-based question-answering tasks was also implemented.
CIFAR-10 trained with self-supervised exemplary models for image colorization or inpainting in computer vision can be benchmarked for image classification using ILSVRC. Image captioning, text2image pre-training on MS COCO, and evaluating COCO Captions are options to measure a model’s ability to produce meaningful and coherent descriptions for unseen images.
Challenges and Limitations
Apart from everything we’ve already discussed, self-supervised learning also has a range of limitations and challenges.
Dependency on Data Quality and Quantity
Building a good model with insufficient and low-quality training data is practically impossible since its generalization capabilities are low. The data must reflect the nature of the problem you want the model to solve.
If you want to know what Makes a Good Data Project, read this one.
Computational Resources
The following limitation is computational resource complexity; self-supervised models are computationally expensive.
They process large volumes of data and complex neural architecture, which in many cases hampers training due to the need for permanent work of GPU or TPU, the cost of which is one of the most expensive for the duration of use.
Model Complexity and Overfitting
However, self-supervised learning models might become very complex when capturing slight patterns in the data. Given the high complexity degree, there is a risk of overfitting, which means that the model works well with the training data but fails with the new data.
That is why regularization solutions and careful model testing should be applied to overcome this issue. Do you know how regularization reduces overfitting? To see the results, visit here.
Lack of Standardized Evaluation Metrics
Unlike supervised learning, where evaluation metrics are well-defined (like accuracy or F1-score), self-supervised learning lacks standardized metrics. This makes objectively measuring performance and comparing different models challenging, especially across diverse tasks. Check this one to learn more about classification metrics.
Ethical and Bias Considerations
Like all AI models, self-supervised learning systems are at risk of inadvertently supporting or exacerbating data biases.
The ethical considerations of deploying the model must be considered to ensure the models are not enhancing harmful biases.
These challenges illustrate the continued need for research and innovation in self-supervised learning. Attempts to overcome these limitations will then facilitate maximizing the potential of self-supervised models within a wide range of applications.
Conclusion
In this one, we discovered self-supervised learning by examining its famous applications, such as NLP(Natural Language Processing) and CV(computer vision). Moreover, we found famous frameworks like Tensorflow, PyTorch, and Hugging Face.
One meaningful way to deepen your knowledge is to do a Data Project like we did for supervised learning (Delivery Duration Project- DoorDash). But we have more of them. Feel free to visit our platform to discover Data Projects and solve them using methods you’ve learned from here.
Share


