What Makes a Good Data Project?


 Written by:
Written by:Nathan Rosidi
What is that differs a good data project from the adequate one? There are five crucial elements we will talk about that will make your project stand out.
Data science projects are the real deal when considering the technologies that have been coming to the surface daily. They allow organizations and individuals to collect and analyze large amounts of data that have been collected.
This article will discuss the vital steps and factors that make a data science project good, from using quality data to gathering feedback. In between, we’ll go through cloud systems (You have to store the data somewhere, right?), data visualization, and model building. In model building, we’ll also mention data exploration, different algorithms and techniques to increase the performance of the algorithms, and more.
Below is an overview of all the elements every good data project must have.
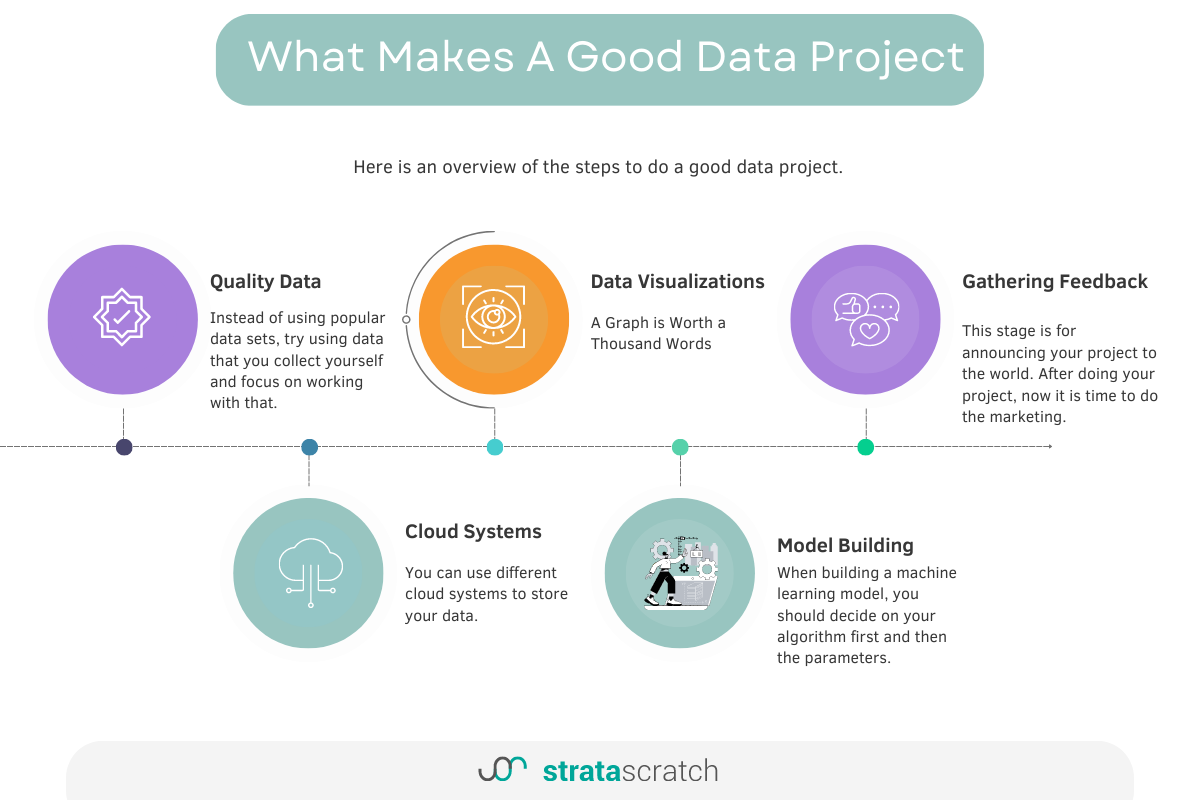
Now let’s start with quality data.
Quality Data
The building block of any good data science project is to use data that fits the project's purpose and is of high quality.
There are many different open-source websites like Kaggle or UCL Machine Learning Repository to collect data. Yet, remember, your rivals and junior data scientist also looked there to build a project. To distinguish your project from other average projects most people do, you should collect your data from the web.
But is there enough data? It’s almost like asking did anyone find the end of the internet.
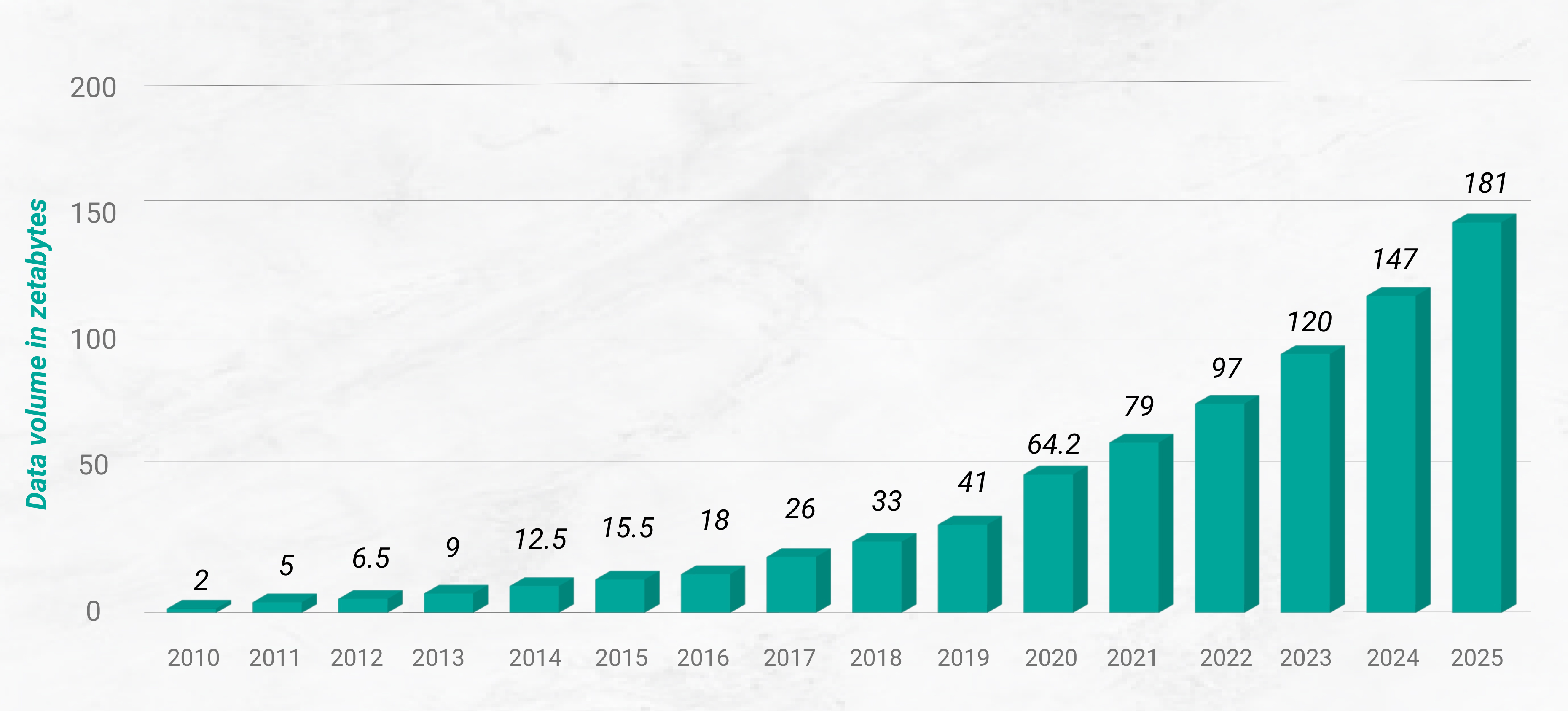
Here is the research done by International Data Group to forecast collecting data between 2010 to 2025.
The chart represents the amount of data that has been collected from a wide range of different sources. Just between 2020 and 2025, the amount of data that will have been collected is predicted to be approximately triple, from 64.2 to 181 zettabytes(1 zettabyte = 1e+12 GB)

New data is constantly coming as we virtually live in a production database. That means there are a lot of opportunities for you to build a model upon this novel data.
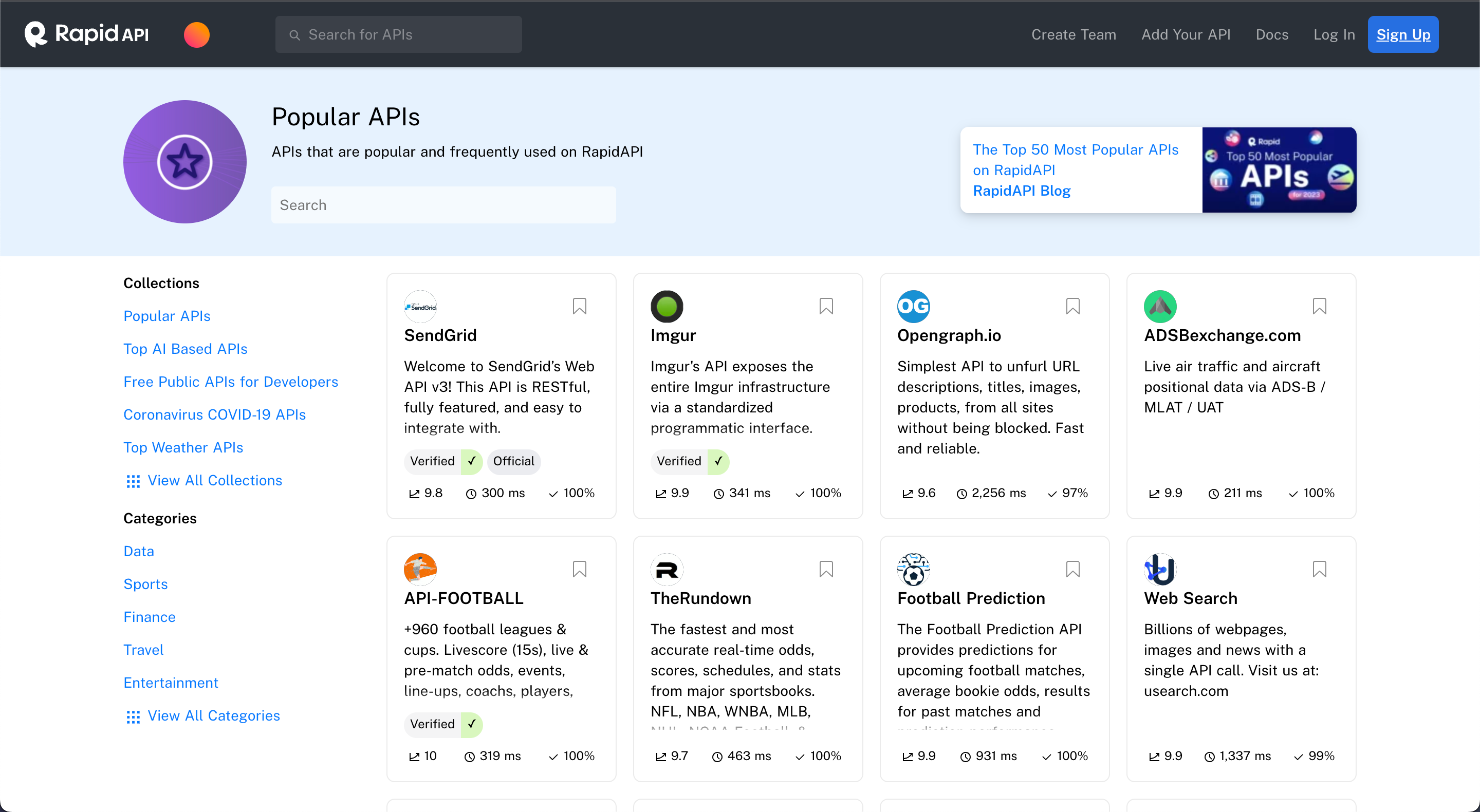
But how do you collect these data sets? The best way is to use different APIs or scrape the data from the Web with Python.
A wide range of APIs available provides you access to real-time data, such as weather data, football data, or even food recipe data. These APIs can be accessed through platforms like RapidAPI, shown below.

Web scraping is another option for obtaining real-life data. This includes using libraries like Scrapy, requests, Selenium, or Beautiful Soup to extract data from websites.


For example, you can scrape data from IMDB to find the top 250 movie list, with ratings and the year of the movie, by using Beautiful Soup and requests together.
You can learn more about it in our article about data collection libraries in Python.
Cloud Systems

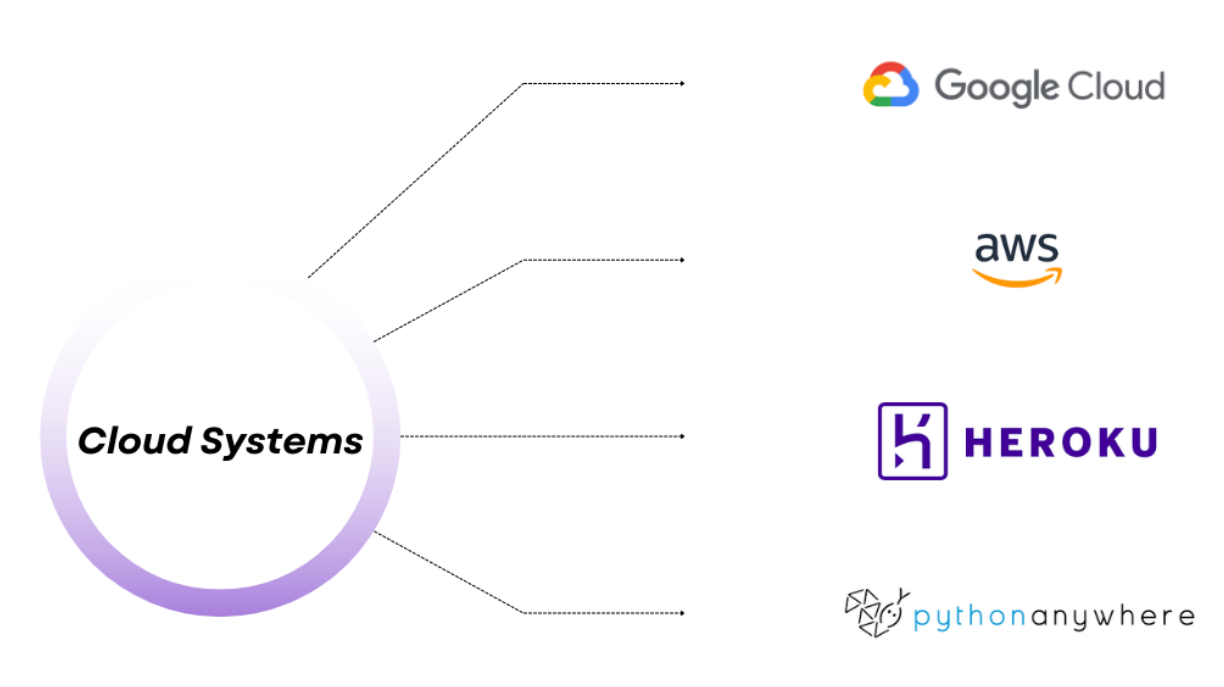
Now, you got your data. But where to store it? The best answer to that question is to find a cloud-based system to store the big data you just scraped or collected and access it when you want. AWS and Google Cloud are popular options for storing data. Yet by using pythonAnywhere and Heroku, you can achieve many tasks and also store your data.
AWS is the most popular cloud system commonly linked to other AWS technologies like SageMaker, making it so popular.
Google Cloud is also commonly preferred because of its compatibility with Google's other products.
Both AWS and Google Cloud provide server hosting, storage, database analytics, and more.
PythonAnywhere has some free options. It allows you to host your model, though, but there may be limitations on free usage, and it only supports Python.
Heroku is a platform as a service that supports various programming languages and frameworks, including Python, Flask, and Django.
Using cloud-based storage systems offers a number of advantages, including scalability, flexibility, and cost-effectiveness. By using the cloud, organizations can easily access their data and analyze it from different sources and can quickly scale up or down when needed.
Create Impressive Visuals


You collected your data and started analyzing it. Now it is time to get attention. One good way to do this is by creating impressive visuals like charts, graphs, and maps.
These visuals can help you show complex data in a way that is easy to comprehend and can also be used to highlight key trends and patterns.
It is worth considering the learning style of your audience.
What is a learning style?
According to the research conducted by the University of Medicine and Pharmacy of Craiova in 2014, most people (65%) have a visual learning style. That means they understand the concepts best when the information is presented to them visually.
There are also auditory learners(30%) who prefer to learn through hearing and kinesthetic learners ( 5%) who prefer learning by physical activity. Here is the research paper if you want to read more.
On the other hand, in recent years, scholars have claimed that no scientific evidence of learning styles exists.
No matter what is true, humans can for sure be considered visual beings since “more than 50 percent of the cortex, the surface of the brain, is devoted to processing visual information.”
So dedicating time to knowing how to present your data and doing it in a visually pleasing manner is what every good project needs.
Many different Python libraries are available for creating impressive visuals, such as seaborn, plotly, matplotlib, or even pandas.


If you run out of ideas, you can visit the subreddit “dataisbeautiful” for inspiration, which features a variety of interactive visuals.
Here is one example which shows all bicycle paths in the Netherlands.


By using impressive visuals, you will increase the effectiveness of your data science project.
Model Building


Okay, now it’s time to cook the meal. You have all the ingredients for that. Now you only need to build a model that makes good predictions.
This model could be statistical, machine learning, or some other type of model designed to analyze the data and draw conclusions from it.
The goal of model building is to identify patterns and trends in the data that can be used to make predictions and make a decision that will draw a road map for your business.
But before building a model, it is crucial to clearly understand the problem you are trying to solve and the purpose of the model. This will help guide your decisions and narrow down your options.
Once you have a clear purpose, you can begin exploring the data to get a sense of its shape, whether it has any missing data, or whether the features' format should be changed.
To do that, there are several useful functions in Python.

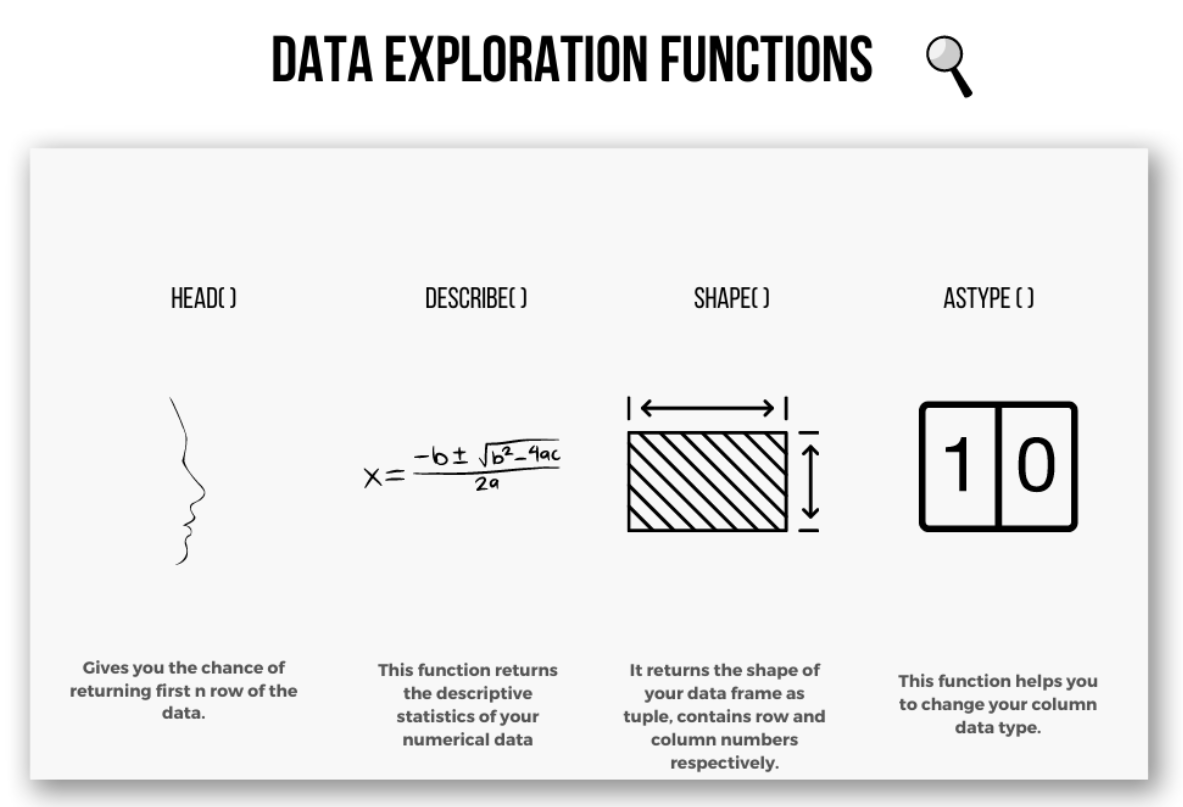
Knowing your data is important for choosing the right algorithm. For example, if your data contains a column you want to predict, you should choose one of the supervised algorithms. If not, you should choose an unsupervised algorithm.
It is also helpful to consider whether your data is numerical or not, as this will affect your choice of regression or classification algorithms.
After choosing an algorithm, optimizing your model’s performance through techniques such as scaling and random search, is vital.

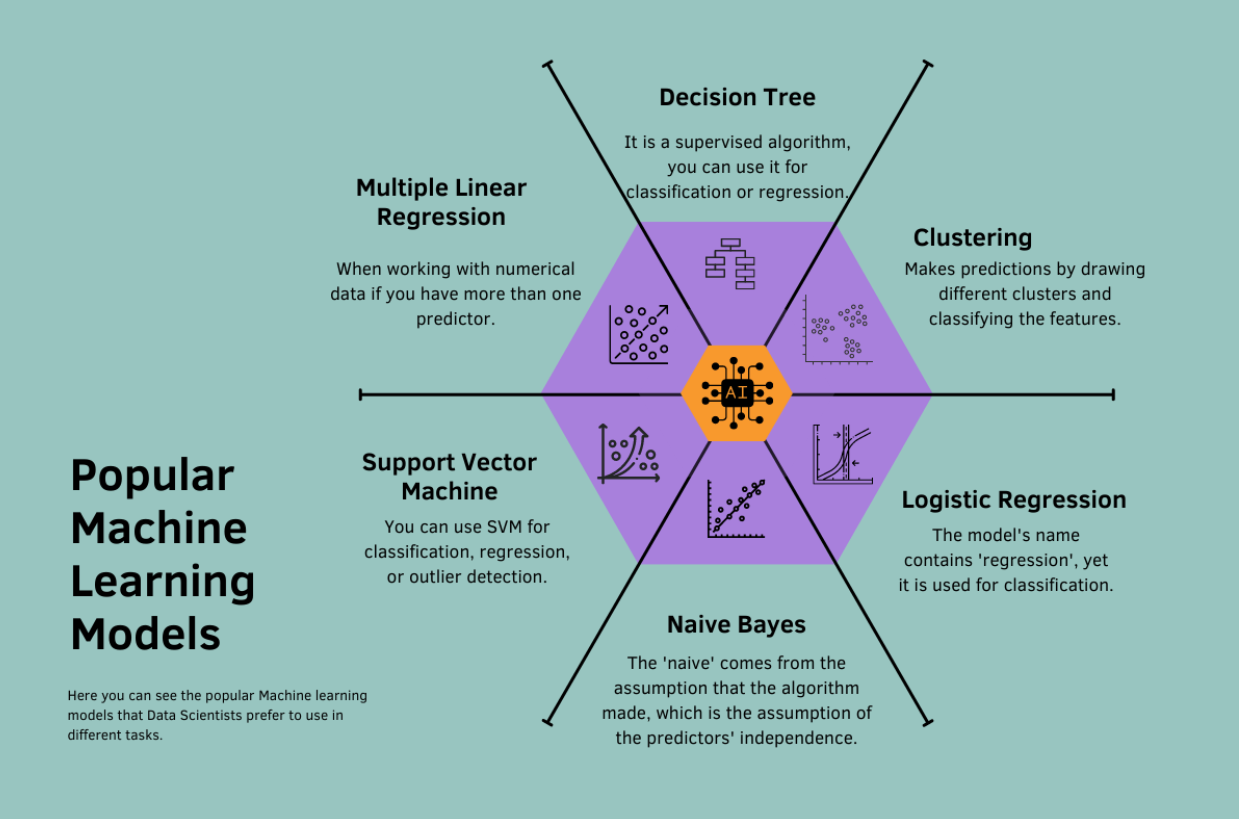
Scikit-learn is a popular open-source machine-learning library that offers a broader range of functions and techniques to improve model performance.
If you want to build complex neural networks and adjust them, TensorFlow might be the one for you. It was created by Google and offers functions for Machine learning and Deep Learning.
One other library for you to build a machine learning model is Keras, which can also work with Tensorflow and has useful built-in functions.
To make accurate predictions for a competition, try using XGBoost, which is known for its success in competition solutions.
By planning and considering these factors before building your model, you can save time and increase the effectiveness of your project.
Gathering Feedback


Now you have your project basically finished. But how to evaluate your project? Once you finish it, it is helpful to gather feedback in order to improve your project. There are several ways to do this, including writing blog articles about the project and sharing them on platforms like Medium.


Write Blog Articles About Your Project

By publishing articles that explain different aspects of your project, you will get feedback. Primarily if you publish your article in popular publications like Towards Data Science (651.000 followers), Towards AI, and Geek Culture in medium, you will have a chance to reach a broader audience, which will eventually lead your project to be read and evaluated more.
Don’t forget to be persistent when sharing articles and gathering feedback. Writing regularly will not only increase your project's chance of getting known by being published. Because there is an approval process at these publications, even this can provide you with positive or negative feedback about your project. By actively seeking this feedback, you will ensure that your data science projects will constantly evolve and increase.
Build Your Audience

One way to build an audience for your data science project is by writing regular articles and helping grow your community. This can be done through platforms like medium, as we already mentioned. But there is one more catch in this. Medium offers a partnership program that pays writers based on their impact, measured in reading time.
Another way to build an audience is by creating a newsletter. Now, this is an old trick many bloggers have already been doing for ages now. If you plan to do it, consider creating documents that can be attractive to your followers, like cheat sheets and source codes for your minor projects. You can say hi to your followers by creating a weekly newsletter. One fancy way to do this is using ConvertKit. With it, you can also create different landing pages which contain your source codes or cheat sheets.
And you can create e-mail automation to send it to your followers and sell products.
By building an audience and maintaining regular communication with them, you can create loyal followers and increase the chance that your project will be widely used and valued. Over time, this audience may also motivate you to create new models tailored to their needs, potentially leading to income opportunities.
Develop Your Library

Another way to share your data project with the community is by developing a Python library using PyPi and sharing it on GitHub. It is a website where developers can share their code. By sharing your library on this platform, you can also build an audience. Also, that library will include your custom functions.
One benefit of importing your libraries into a global environment is that you can also access them anywhere you want. And by doing this, you will contribute to the growing community of data scientists and developers and potentially reach a wider audience with your project.
But do not forget, the followers from there will also be developers. You should consider that when targeting this audience with a project. For them, maybe it would be more interesting if you built an API for your project. That leads us to the next section.
Develop Your API

Another way to share your data science project is by developing your own API. There are many resources available online for creating and sharing APIs, such as rapidapi.
By developing and sharing your own API, you can become a valued contributor to the data science community, but not just that. Building API can pay off by enriching your CV and potentially providing a source of side income or even a business opportunity.
Of course, this process can be challenging because it requires a range of technical skills. But here we are for you to help you hone that skills.
Conclusion
In this article, we discussed many different factors that can make your project a good one. These include using quality data, leveraging cloud systems, creating impressive visuals, building effective models, and gathering feedback.
One key to success is doing a novel project and actively sharing it with the world to validate it and reach a wider audience.
To implement all this, it is crucial that you carefully plan your project and be proactive in addressing any potential roadblocks and making decisions that need to be made.
Reading helpful articles and videos, like those available on our Youtube channel or our platform can be a great way to gain the knowledge and experience needed to succeed in data science. Possibly, land a new job if that’s your goal.
If you are interested in enhancing your programming skills through interview questions and data projects, visit our platform for more resources and guidance.
Share


