Amazon Data Engineer Interview Questions


Categories:
 Written by:
Written by:Vivek Sankaran
Amazon Data Engineer interview questions that will specifically focus on the SQL coding skills relevant from a data engineering point of view.
Data Engineering is one of the most rapidly evolving and highly paid areas in Data Science. Data Engineers take the research and curiosity of a data scientist and meld it with the teamwork, discipline, and test-driven approach of traditional software engineering. Data Engineering brings all the cutting-edge models to life and provides the input data and features to monitor and evolve the existing ones. It is reported to be one of the highest-paid areas in Data Science, with a median pay of around USD 90,000 per year.
What does a Data Engineer do?
A data engineer needs to wear multiple hats. She is expected to be resourceful to be able to deal with multiple technologies and platforms as the needs of the business change. We have an exhaustive article on Data Engineer Interview Questions here. A high-level overview of the tasks that a Data Engineer might need to perform is -
- Acquire data from multiple sources to fulfill business requirements.
- Build ETL pipelines to transform the data into information that can be used by Analysts and Data Scientists.
- Test, monitor, and evolve these data pipelines as the business needs evolve.
- Validate data integrity and shortlist data analysis tools to suit business size.
- Be the gatekeeper of data and ensure compliance with data governance and security policies.
- Capacity, Technology, and Resource Planning for future business needs.
In terms of technologies required, most data engineers are required to be proficient in SQL, Python, Bash Scripting, ETL tools like Airflow and Kafka, Git, Docker, and associated containerization tools and one or more of the top cloud platforms - GCP, AWS, Azure. In this article we will look at problems that appeared in Amazon Data Engineer Interviews. We will specifically focus on the SQL coding skills that are relevant from a data engineering point of view. We also have an article on Amazon SQL Interview Questions covering multiple areas. The topics that we will cover in this article are
- EDA and Validation
- Aggregation and Metrics
- JOINS
- Text and Datetime Manipulation
We will finish the article off with a case study that applies one or more of the aforementioned skills. Let's begin.
Amazon Data Engineer Interview Questions
EDA and Validation

One of the key responsibilities of a Data Engineer is to monitor and validate data integrity. The Data Engineer is responsible for the data quality and hence has to ensure that the data conforms to the agreed standards. Let us take an example of this with a simple problem from a past Amazon Data Engineer interview.
Amazon Data Engineer Interview Question #1: Primary Key Violation
Given a dim_customer table with a key (cust_id) identifying each customer, return all the customer IDs (cust_id) that are violating the primary key constraints. Output all the customer IDs that are present more than once in the table. Output the IDs and the number of times the key is present.

Link to the question: https://platform.stratascratch.com/coding/2107-primary-key-violation
The problem uses the dim_customer table with the following fields.
| cust_id: | varchar |
| cust_name: | varchar |
| cust_city: | varchar |
| cust_dob: | datetime |
| cust_pin_code: | int |
The data is presented thus.
Solution
The solution is pretty straightforward. To find the number of occurrences, we start by counting the number of occurrences for each cust_id using the GROUP BY clause.
SELECT
cust_id
, count(*)
FROM dim_customer
GROUP BY 1
;
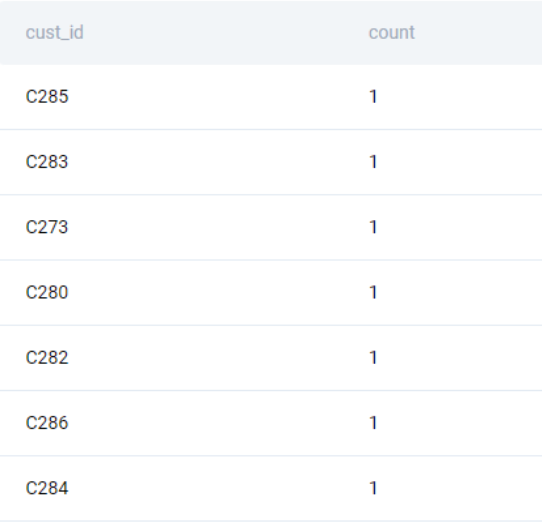
We keep only those cust_id that are present more than once. To do this, we use the HAVING clause, not the WHERE clause, since we need to work on the aggregated data, not the underlying table.
SELECT
cust_id
, count(*)
FROM dim_customer
GROUP BY 1
HAVING count(*) > 1
;Let us take this problem a notch further. We will use the same table.
Amazon Data Engineer Interview Question #2: Find the five highest salaries

Link to the question: https://platform.stratascratch.com/coding/9868-find-the-five-highest-salaries
The problem uses the worker table with the following fields.
| worker_id: | int |
| first_name: | varchar |
| last_name: | varchar |
| salary: | int |
| joining_date: | datetime |
| department: | varchar |
The data is presented in the following manner -
Solution
This problem can be solved in multiple ways. To get an idea of how to solve this, let us explore the salary field a bit more.
SELECT
salary
FROM worker
ORDER BY salary DESC
;This gives us the following output.

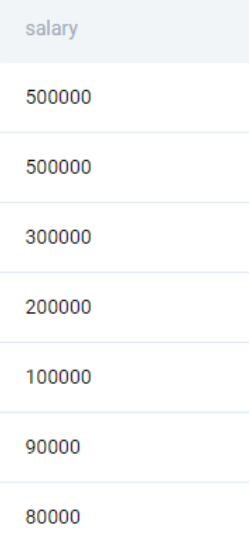
If we use the LIMIT clause, we will get the first five rows from the output
SELECT
salary
FROM worker
ORDER BY salary DESC
LIMIT 5
;However, this would be incorrect as the salary values are repeated.

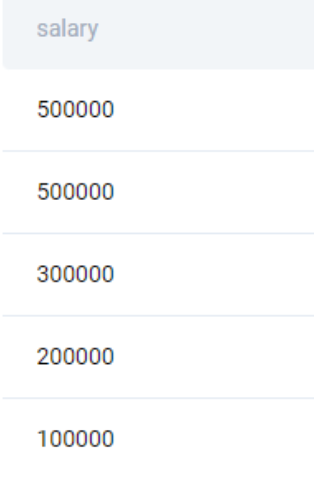
To get unique salary values, we use the DISTINCT clause.
SELECT
DISTINCT salary
FROM worker
ORDER BY salary DESC
LIMIT 5
;We will also get the same output if we use the GROUP BY and LIMIT clauses together. It will simply group the identical salaries together and limit the top five values only.
SELECT
salary
FROM worker
GROUP BY salary
ORDER BY salary DESC
LIMIT 5
;Using GROUP BY in this case results in an identical solution with almost identical performance times as discussed here.
Given the exploratory nature of work, sometimes Data Engineers might not have access to all the libraries and functionalities in the test environment. This is specifically the case while working with scripting languages like Python. The skill of the Data Engineer here is to use the barebones standard libraries and develop workarounds to help solve the problem. Let us try that in our next problem.
Amazon Data Engineer Interview Question #3: Find the second highest salary without using ORDER BY

Link to the question: https://platform.stratascratch.com/coding/9857-find-the-second-highest-salary-without-using-order-by
The problem uses the same worker table that we used in the previous problem.
Solution
The problem is relatively straightforward. However, we are prohibited from using the ORDER BY clause. So let us break this problem down into two parts.
- We start off by taking out the maximum salary
- Then, query the table again and take the maximum salary after excluding the maximum salary.
SELECT
MAX(salary)
FROM worker
;We get the following output.

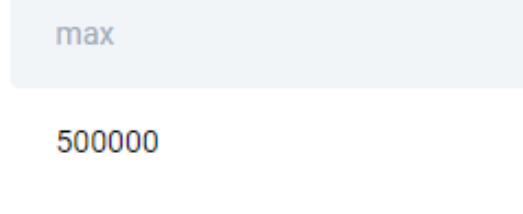
Now we get the maximum salary after excluding this salary.
SELECT
MAX(salary)
FROM worker
WHERE salary NOT IN
(
SELECT
MAX(salary)
FROM worker
)
;Aggregations
Data Engineers are also required to constantly monitor and report metrics. They need to be on top of changing values, drift in the input, etc. To accomplish this, they need to be able to work with aggregate functions. Let us look at one such example.
Amazon Data Engineer Interview Question #4: Manager of the largest department
Find the name of the manager from the largest department. Output their first and last names.

Link to the question: https://platform.stratascratch.com/coding/2060-manager-of-the-largest-department
The problem uses the az_employees table with the following fields.
| id: | int |
| first_name: | varchar |
| last_name: | varchar |
| department_id: | int |
| department_name: | varchar |
| position: | varchar |
Solution
To solve this problem, we need to do the following -
- Find the number of employees in each department
- Output the manager from the department(s) with the maximum number of employees
We start by adding a column with the number of employees in that department. We use a window function over a GROUP BY aggregation as it saves us the aggregation-merge trip.
SELECT
*
, COUNT(*) OVER (PARTITION BY department_id) as num_employees
FROM az_employees
;We get the following output.

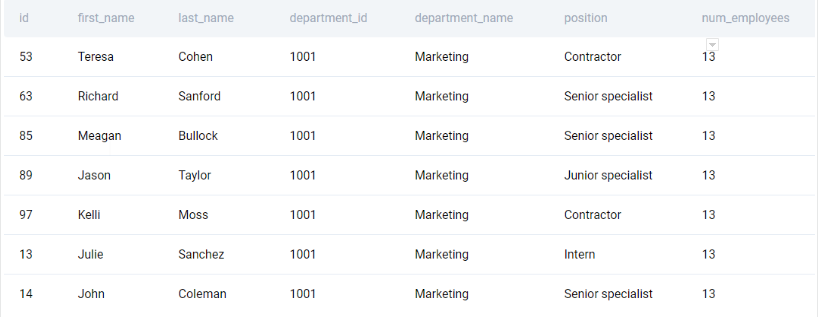
Now we can easily subset the department based on the maximum number of employees. To do this, we use the ILIKE function to identify the managers.
WITH dept_emp AS (
SELECT
*
, COUNT(*) OVER (PARTITION BY department_id) as num_employees
FROM az_employees
)
SELECT
first_name
, last_name
FROM dept_emp
WHERE num_employees = (SELECT MAX(num_employees) FROM dept_emp)
AND position ILIKE '%manager%'
;If the ILIKE function is not available like in MySQL, we can convert the ‘position’ column to lower or upper case and use the LIKE operator.
WITH dept_emp AS (
SELECT
*
, COUNT(*) OVER (PARTITION BY department_id) as num_employees
FROM az_employees
)
SELECT
first_name
, last_name
FROM dept_emp
WHERE num_employees = (SELECT MAX(num_employees) FROM dept_emp)
AND UPPER(position) LIKE '%MANAGER%'
;
Both of them will give us the same result. You can know more about aggregation functions here. And about window functions in SQL here.
Joining Tables

Till now we have worked with only a single table. In real life however, databases are highly normalized and require merging multiple tables to get the required output. Let us look at a few problems. We start with a relatively easy one.
Amazon Data Engineer Interview Question #5: Customer Order and Details
List the number of orders, customers, and the total order cost for each city. Include only those cities where at least five orders have been placed but count all the customers in these cities even if they did not place any orders.

Link to the question: https://platform.stratascratch.com/coding/9908-customer-orders-and-details
This problem uses the customers and orders tables. The fields in the customers table are
| id: | int |
| first_name: | varchar |
| last_name: | varchar |
| city: | varchar |
| address: | varchar |
| phone_number: | varchar |
The data therein looks like this.
The following are the fields in the orders table.
| id: | int |
| cust_id: | int |
| order_date: | datetime |
| order_details: | varchar |
| total_order_cost: | int |
The data in the orders table is presented thus.
Solution
The problem is not too difficult. However, one needs to be careful about following the instructions provided in the question properly. Here is the outline to solve this problem
- Merge the two tables
- Aggregate the number of orders, total order value, and the number of customers for each city.
- Subset only those cities that have five or more orders.
We start off by merging the two tables. We need a LEFT JOIN because we need to count even those customers who have not placed any orders.
SELECT
customers.city
, customers.id
, orders.cust_id
, orders.id
, orders.total_order_cost
FROM
customers
LEFT JOIN orders
ON customers.id = orders.cust_id
ORDER BY 1
;We get the following output.

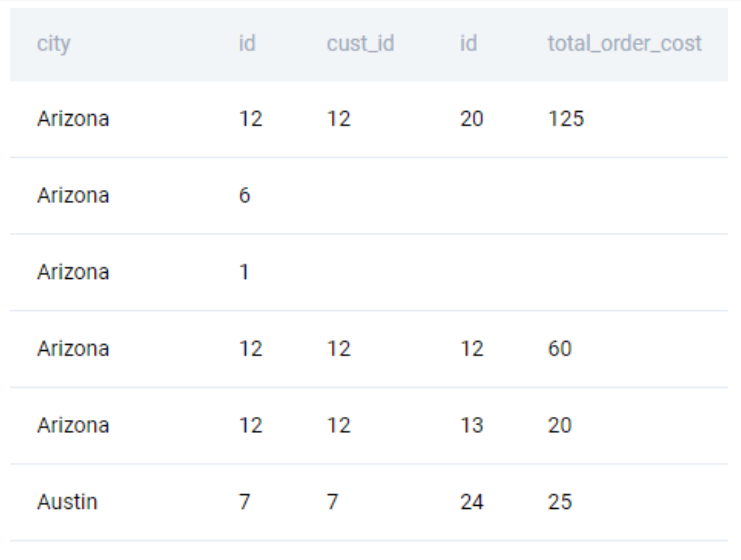
Note: We do not need the cust_id field from the orders table. We used that to illustrate how the merge results will look.
Now that we have all the fields, we can aggregate our metrics.
- To find the number of orders and the value of the orders, we use the fields from the orders table.
- To find the overall number of customers in a city, we use the cust_id field from the customers table.
Further, we need to be careful not to count duplicates while counting the number of customers. The actual query is not too complicated.
SELECT
customers.city
, COUNT(orders.id) AS orders_per_city
, COUNT(DISTINCT customers.id) AS customers_per_city
, SUM(orders.total_order_cost) AS orders_cost_per_city
FROM
customers
LEFT JOIN orders
ON customers.id = orders.cust_id
GROUP BY 1
;We get the following output.

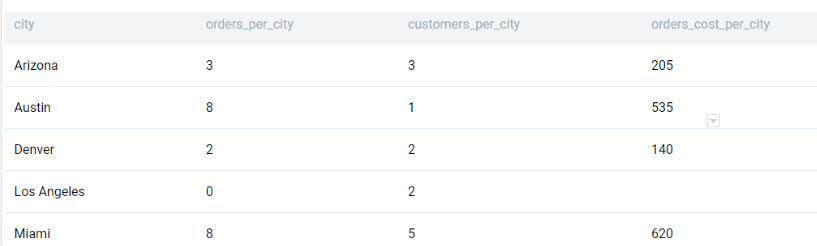
We can now subset the relevant cities by using the HAVING clause.
SELECT
customers.city
, COUNT(orders.id) AS orders_per_city
, COUNT(DISTINCT customers.id) AS customers_per_city
, SUM(orders.total_order_cost) AS orders_cost_per_city
FROM
customers
LEFT JOIN orders
ON customers.id = orders.cust_id
GROUP BY 1
HAVING COUNT(orders.id) >=5
;Let us dial up the difficulty a bit with the next one. This uses information from three tables.
Amazon Data Engineer Interview Question #6: Exclusive Amazon Products
Find the products that are exclusive only to Amazon and not available at TopShop or Macy’s. A product is exclusive if the combination of product name and maximum retail price is not available in the other stores. Output the product name, brand name, price, and rating for all exclusive products.

Link to the question: https://platform.stratascratch.com/coding/9608-exclusive-amazon-products
The problem uses three tables: innerwear_macys_com, innerwear_topshop_com, innerwear_amazon_com. Each of the three tables has the same fields.
| product_name: | varchar |
| mrp: | varchar |
| price: | varchar |
| pdp_url: | varchar |
| brand_name: | varchar |
| product_category: | varchar |
| retailer: | varchar |
| description: | varchar |
| rating: | float |
| review_count: | float |
| style_attributes: | varchar |
| total_sizes: | varchar |
| available_size: | varchar |
| color: | varchar |
The fields of interest are product_name, mrp, brand_name, price, and rating. The retailer field is constant across the table. Therefore, the innerwear_macys_com table will have all retailer column values as Macys US, the innerwear_topshop_com will have the field as US Topshop and so on. Here is an outline of the relevant fields available in the innerwear_topshop_com table.
Solution
There are multiple ways of solving this problem. One way is to JOIN the tables on product_name and mrp fields and find only those products which are present exclusively on Amazon. Let’s see how this works by joining the Amazon and TopShop tables.
SELECT
a.product_name
, t.product_name AS t_prod
, m.product_name AS m_prod
, a.mrp
, t.mrp AS t_mrp
, m.mrp AS m_mrp
, a.brand_name
, a.price
, a.rating
FROM innerwear_amazon_com AS a
LEFT JOIN innerwear_topshop_com AS t
ON a.product_name = t.product_name
AND a.mrp = t.mrp
;
We get the following output.

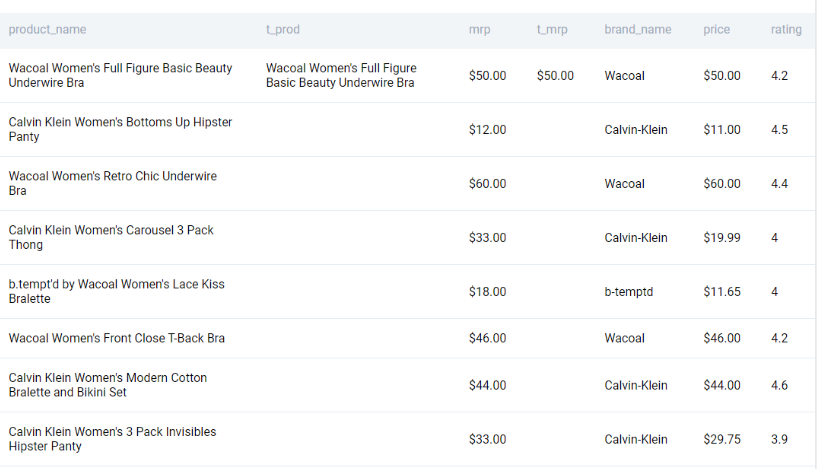
Where the TopShop fields are NULL, then that product is not available on TopShop. We repeat the same process with the Macys table.
SELECT
a.product_name
, t.product_name AS t_prod
, m.product_name AS m_prod
, a.mrp
, t.mrp AS t_mrp
, m.mrp AS m_mrp
, a.brand_name
, a.price
, a.rating
FROM innerwear_amazon_com AS a
LEFT JOIN innerwear_topshop_com AS t
ON a.product_name = t.product_name
AND a.mrp = t.mrp
LEFT JOIN innerwear_macys_com AS m
ON a.product_name = m.product_name
AND a.mrp = m.mrp
;
We get the following output.

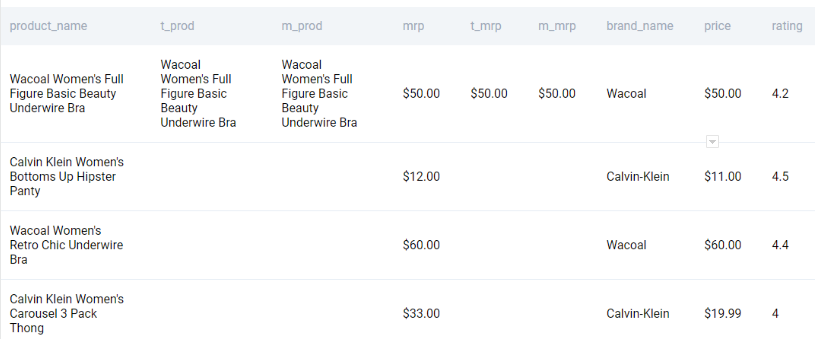
Now we can simply subset the products that are available exclusively on Amazon and keep only the relevant fields.
SELECT
a.product_name
, a.brand_name
, a.price
, a.rating
FROM innerwear_amazon_com AS a
LEFT JOIN innerwear_topshop_com AS t
ON a.product_name = t.product_name
AND a.mrp = t.mrp
LEFT JOIN innerwear_macys_com AS m
ON a.product_name = m.product_name
AND a.mrp = m.mrp
WHERE
t.mrp IS NULL
AND t.product_name IS NULL
AND m.mrp IS NULL
AND m.product_name IS NULL
;
Alternatively, we can solve this using UNION. UNION will provide us with non-repeating values of the combination of product_name and price.
SELECT DISTINCT product_name, mrp FROM innerwear_macys_com
UNION
SELECT DISTINCT product_name, mrp FROM innerwear_topshop_com
;
This gives the following output.

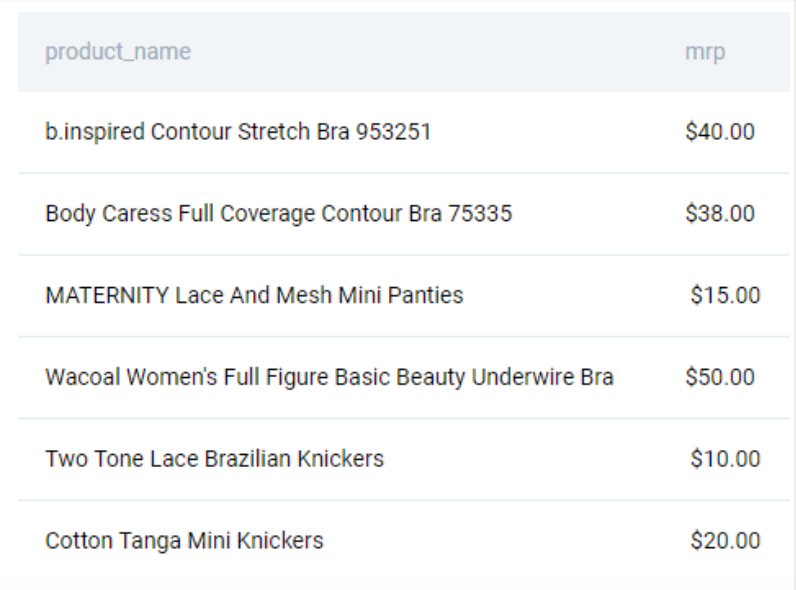
We can now remove this combination from the Amazon listings by using a simple subquery.
SELECT
product_name
, brand_name
, price
, rating
FROM innerwear_amazon_com AS a
WHERE (product_name, mrp) NOT IN (
SELECT product_name, mrp FROM
(
SELECT DISTINCT product_name, mrp FROM innerwear_macys_com
UNION
SELECT DISTINCT product_name, mrp FROM innerwear_topshop_com
) q
)
;
You can check the combination of two or more fields as a tuple against a subquery just as you would do with a single column. This can help reduce multiple joins and gives a simple and neat-looking result. You can know more about different types of SQL JOINS and UNION here.
Text and Datetime Manipulation
Text and Datetime fields are ubiquitous. We have detailed articles on these two concepts - “String and Array Functions in SQL” for Text functions and “SQL Scenario Based Interview Questions” for Datetime functions. Let us start with text manipulation.
Amazon Data Engineer Interview Question #7: Most expensive product in each category
Find the most expensive product in each category. Report the category, product name, and the price (as a number).

Link to the question: https://platform.stratascratch.com/coding/9607-the-most-expensive-products-per-category
The problem uses the innerwear_amazon_com dataset that we saw in the previous problem with the following fields.
| product_name: | varchar |
| mrp: | varchar |
| price: | varchar |
| pdp_url: | varchar |
| brand_name: | varchar |
| product_category: | varchar |
| retailer: | varchar |
| description: | varchar |
| rating: | float |
| review_count: | int |
| style_attributes: | varchar |
| total_sizes: | varchar |
| available_size: | varchar |
| color: | varchar |
If you observe carefully, the price field is represented as a text field. Let us see how the relevant fields look.
Solution
The biggest challenge in this problem is to convert the price to a number. We cannot typecast the field directly to a number since the field has non-numeric characters. Therefore, we proceed in the following manner.
- Extract the numeric value from the price field.
- Find the highest-priced product from each category and output the relevant fields.
Let us try cleaning up the price field. There are numerous ways of accomplishing this. Let us look at a few.
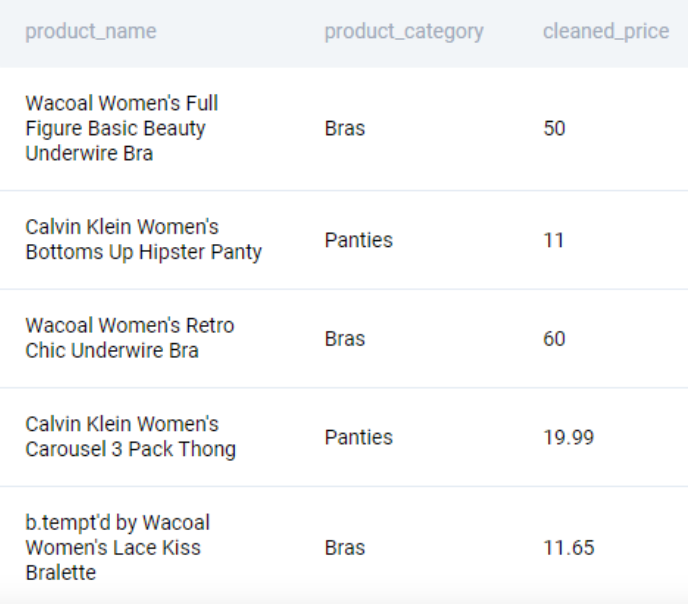
One way is to use the REPLACE() function to replace the $ sign and then typecase the output to a number.
SELECT
product_name
, product_category
, REPLACE(price, '$', '')::NUMERIC AS cleaned_price
FROM innerwear_amazon_com
;This gives us the following output.

We can also try a more complex regular expression match using REGEX_REPLACE(). We can do this by trying to find all instances of characters that are not digits or the decimal symbol (.)
SELECT
product_name
, product_category
, REGEXP_REPLACE(price, '[^0-9.]+', '', 'g' ) AS cleaned_price
FROM innerwear_amazon_com
;This gives the same result as earlier. Now we need to find the costliest item in each category. To do this we use the window function RANK(), partitioning over the product category.
SELECT
product_name
, product_category
, REGEXP_REPLACE(price, '[^0-9.]+', '', 'g' )::NUMERIC AS price
, RANK() OVER (PARTITION BY product_category
ORDER BY REGEXP_REPLACE(price, '[^0-9.]+', '', 'g' )::NUMERIC DESC) AS rnk
FROM innerwear_amazon_com
;Resulting in the following output.

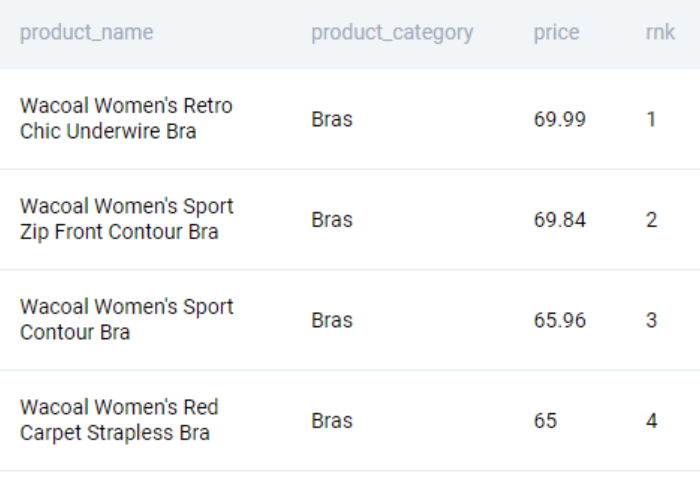
We now take the first-ranked products along with their prices in each category.
WITH ranked_products AS (
SELECT
product_name
, product_category
, REGEXP_REPLACE(price, '[^0-9.]+', '', 'g' )::NUMERIC AS price
, RANK() OVER (PARTITION BY product_category
ORDER BY REGEXP_REPLACE(price, '[^0-9.]+', '', 'g' )::NUMERIC DESC) AS rnk
FROM innerwear_amazon_com
)
SELECT
product_category
, product_name
, price
FROM ranked_products
WHERE rnk = 1
; Let us solve a problem involving Datetime manipulation.
Amazon Data Engineer Interview Question #8: First Day Retention
A first day retention happens when a player logs in on the next day of his or her first ever log-in. Calculate the first day retention rate for the given set of video-game players and output the proportion of players who meet this definition as a ratio of the total number of players.

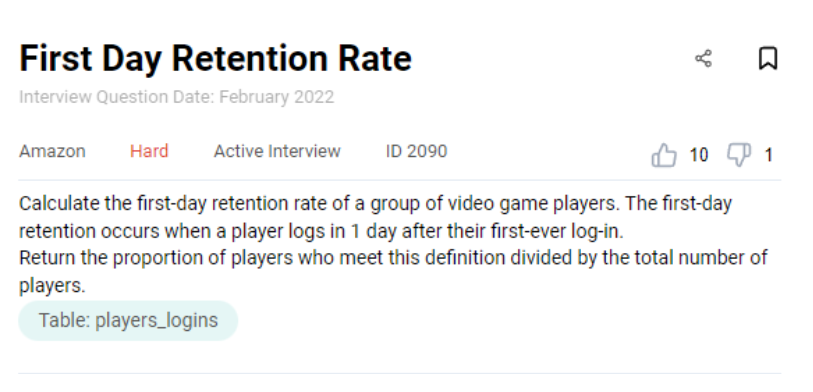
Link to the question: https://platform.stratascratch.com/coding/2090-first-day-retention-rate
The problem uses the players_logins table with the following fields.
| player_id: | int |
| login_date: | datetime |
The data is presented in the following manner
Solution
There are numerous ways of solving this Amazon data engineer interview question. Let us look at one way of solving this.
- Find the earliest login date for each player
- Check if the player logged in one day after the earliest login date.
- Calculate the proportion of players who satisfy the first-day retention criteria as a fraction of all the players
We start by adding a column with the earliest login date by applying a window function.
SELECT
*
, MIN(login_date) OVER (PARTITION BY player_id) AS min
FROM players_logins
;We get the following output.

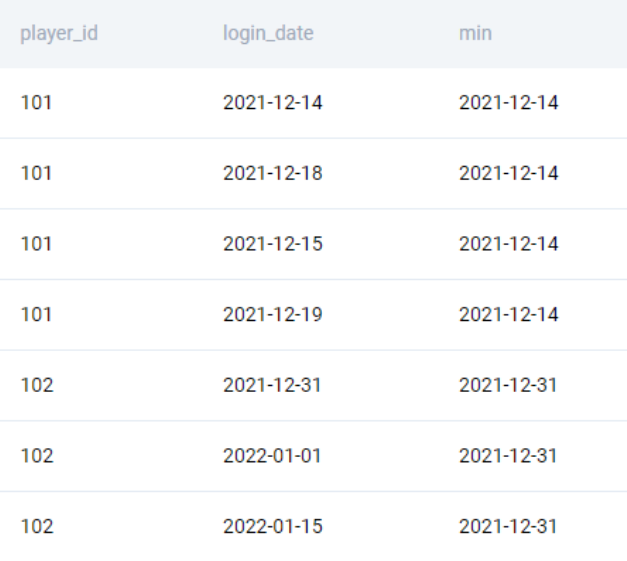
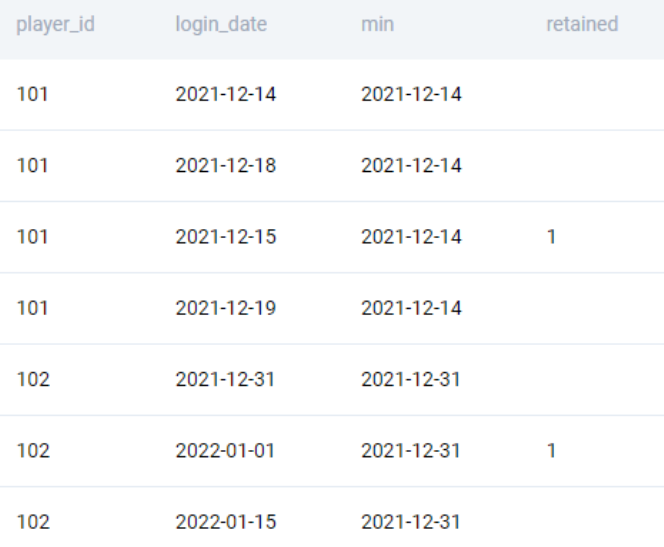
We used the window function instead of a GROUP BY and JOIN to avoid multiple passes. Now we can tag the logins that happened the very next day of the first login. To do this, we simply add one day to the earliest login date and tag the logins.
SELECT
*
, MIN(login_date) OVER (PARTITION BY player_id) as min
, CASE WHEN DATE(login_date) = MIN(login_date) OVER (PARTITION BY player_id) + INTERVAL '1 DAY' THEN 1 END AS retained
FROM players_logins
;This gives us the following output.

We can now finish the problem by aggregating those players who were retained and the overall number of players.
WITH ret_tags AS (
SELECT
*
, MIN(login_date) OVER (PARTITION BY player_id) as min
, CASE WHEN DATE(login_date) = MIN(login_date) OVER (PARTITION BY player_id) + INTERVAL '1 DAY' THEN 1 END AS retained
FROM players_logins
)
SELECT
count(DISTINCT CASE WHEN retained = 1 THEN player_id END) * 1.0
/ count(DISTINCT player_id)
FROM ret_tags
;Case Study

Let us put all these concepts together in the form of a case study. This is rated as a hard question by the users.
Amazon Data Engineer Interview Question #9: Product Market Share
The market share of a product is defined as the number of products sold as a percentage of the total number of products sold in the market. List the Market Share of each product brand for each territory. Output the Territory ID, name of the Product Brand, and the corresponding Market Share in percentages.

Link to the question: https://platform.stratascratch.com/coding/2112-product-market-share
The product uses three tables
fct_customer_sales that has the following fields.
| cust_id: | varchar |
| prod_sku_id: | varchar |
| order_date: | datetime |
| order_value: | int |
| order_id: | varchar |
The data in fct_customer_sales is presented thus.
The map_customer_territory table contains the following fields
| cust_id: | varchar |
| territory_id: | varchar |
The data therein looks thus
And the dim_product table with the following fields.
| prod_sku_id: | varchar |
| prod_sku_name: | varchar |
| prod_brand: | varchar |
| market_name: | varchar |
The data in the dim_product table is organized in the following manner.
Solution
This Amazon data engineer interview question uses most of the concepts that we have covered in this article. Let us plot our path to the solution.
- We get the relevant fields from the three datasets by merging them.
- Then, we aggregate the sales for each brand in each territory for the time period.
- We finally find the market share of each brand in each territory.
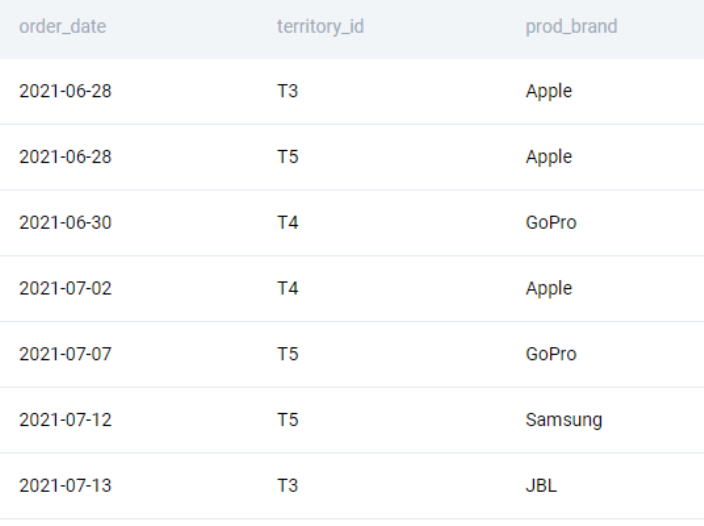
Let us start off by selecting the relevant fields from each of the tables. From the fct_customer_sales table, we need the order_date field. Onto this, we overlay the territory_id from the map_customer_territory table. And from the dim_product table, we add the prod_brand fields. This can be done using a single query.
SELECT
f.order_date
, mc.territory_id
, dc.prod_brand
FROM fct_customer_sales AS f
LEFT JOIN map_customer_territory AS mc
ON f.cust_id = mc.cust_id
LEFT JOIN dim_product AS dc
ON f.prod_sku_id = dc.prod_sku_id
;We get the following output.

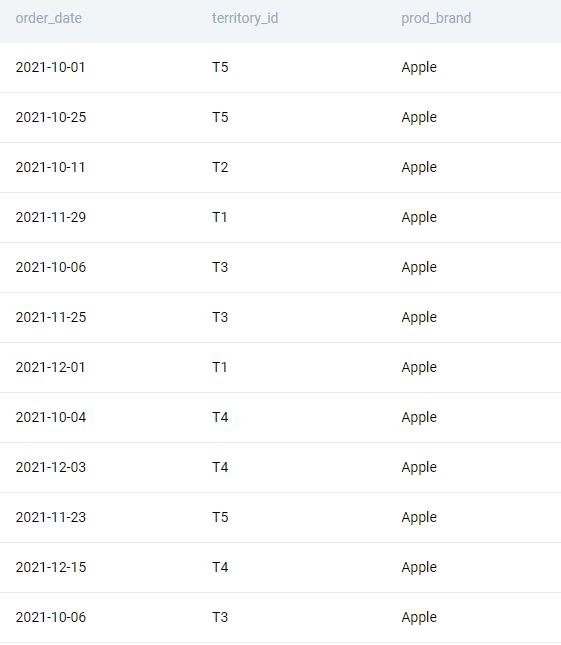
Now we subset the relevant dates. Since we need only the transactions from the fourth quarter of 2021, we use the EXTRACT function to get the relevant year and quarter.
SELECT
f.order_date
, mc.territory_id
, dc.prod_brand
FROM fct_customer_sales AS f
LEFT JOIN map_customer_territory AS mc
ON f.cust_id = mc.cust_id
LEFT JOIN dim_product AS dc
ON f.prod_sku_id = dc.prod_sku_id
WHERE EXTRACT(QUARTER FROM f.order_date) = 4
AND EXTRACT(YEAR FROM f.order_date) = 2021
;Alternatively, we can use the BETWEEN operator to find subset of the relevant dates like this.
SELECT
f.order_date
, mc.territory_id
, dc.prod_brand
FROM fct_customer_sales AS f
LEFT JOIN map_customer_territory AS mc
ON f.cust_id = mc.cust_id
LEFT JOIN dim_product AS dc
ON f.prod_sku_id = dc.prod_sku_id
WHERE f.order_date::DATE BETWEEN '2021-10-01' AND '2021-12-31'
;In either case, we get the following output.

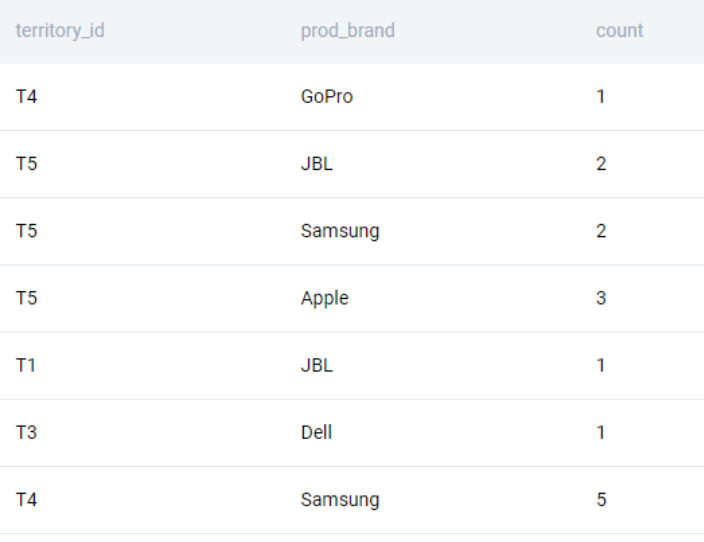
Now we aggregate the orders by territory. We can drop the date field since we do not need it anymore.
SELECT
mc.territory_id
, dc.prod_brand
, COUNT(*)
FROM fct_customer_sales AS f
LEFT JOIN map_customer_territory AS mc
ON f.cust_id = mc.cust_id
LEFT JOIN dim_product AS dc
ON f.prod_sku_id = dc.prod_sku_id
WHERE f.order_date::DATE BETWEEN '2021-10-01' AND '2021-12-31'
GROUP BY 1,2
;We get the following output.

To calculate the market share, we use a window function to aggregate the orders by territory.
SELECT
mc.territory_id
, dc.prod_brand
, COUNT(*)
, SUM(COUNT(*)) OVER (PARTITION BY mc.territory_id)
FROM fct_customer_sales AS f
LEFT JOIN map_customer_territory AS mc
ON f.cust_id = mc.cust_id
LEFT JOIN dim_product AS dc
ON f.prod_sku_id = dc.prod_sku_id
WHERE f.order_date::DATE BETWEEN '2021-10-01' AND '2021-12-31'
GROUP BY 1,2
;We get the following output.

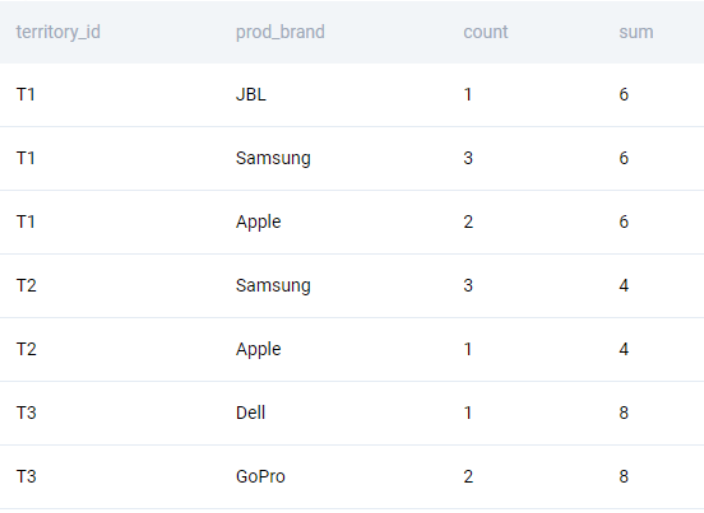
We finish off the problem by calculating the orders of the brand as a percentage of all the orders in the territory. We multiply by a decimal to ensure that it does not result in a truncated division.
SELECT
mc.territory_id
, dc.prod_brand
, COUNT(*) / SUM(COUNT(*)) OVER (PARTITION BY mc.territory_id) * 100 AS market_share
FROM fct_customer_sales AS f
LEFT JOIN map_customer_territory AS mc
ON f.cust_id = mc.cust_id
LEFT JOIN dim_product AS dc
ON f.prod_sku_id = dc.prod_sku_id
WHERE f.order_date::DATE BETWEEN '2021-10-01' AND '2021-12-31'
GROUP BY 1,2
;Conclusion
In this article, we looked at the various roles that a data engineer is required to perform. We looked at specific SQL problems from the past Amazon interviews that tested key Data Engineering skills like validation, aggregation, data transformation, text and datetime manipulation and joining tables. We finally brought it all together in a case study that required us to apply these skills. While some of these problems might appear hard at first, always remember that the first step is always the hardest. As with every other skill in life, all it takes is practice, patience, and persistence to master. Sign up today for a free account on StrataScratch and join over 20,000 other like-minded professionals aspiring to crack their next Data Engineer Interview at top companies like Amazon, Google, Apple, Meta, et al.
Share


