Amazon SQL Interview Questions


Categories:
 Written by:
Written by:Nathan Rosidi
In this article, we will discuss how to solve one of the interesting Amazon SQL interview questions using several different approaches!
Amazon is a company that requires no introduction. Launched by Jeff Bezos in 1994 as an online bookstore, Amazon is now the largest online retailer in the world. As the company currently employs over a million people in over 200 teams across nearly 30 branches and products, 1 out of every 153 American workers can call themselves an Amazon employee. With its continuous growth and the aspiration to innovate and automate, Amazon is always looking for talented data scientists to join its team.
The Data Science Role at Amazon
The exact tasks of a data scientist at Amazon highly depend on the specific team a person works in. For instance, a data scientist position at a retail department might concern recommender systems while the same position in the logistics team may deal more with optimization techniques.
However, we can expect that most of Amazon's data scientists will share tasks such as making predictions and providing forecasting insights using models and machine learning or deep learning solutions. Aside from data scientists, Amazon also employs data analysts whose role is to interpret data, build and maintain dashboard, and design data pipelines.
Check our Amazon Data Scientist Interview Guide to get insight into the interview process, tips and tricks to ace the interview, and most importantly, the kind of questions asked in the interviews at Amazon.
Technical Concepts Tested in Amazon SQL Interview Questions
As the knowledge and understanding of SQL are the key requirements for both data scientists and data analysts at Amazon, many interview questions require writing solutions using this language. In fact, Amazon asks much less questions about theoretical concepts and their products when compared to other tech companies. This is why it’s crucial to practice solving SQL interview questions before an Amazon interview.
The Amazon SQL interview questions test a wide range of SQL concepts but some notions appear in them more often. Nearly 70% of Amazon SQL interview questions concern data stores in multiple tables and ask for merging the data using JOIN clauses, Common Table Expressions or subqueries. Another highly prevailing concept is data aggregation using SQL functions such as COUNT of SUM in combination with the GROUP BY clause or using the more complicated window functions. Many questions also require data filtering and sorting using the WHERE and ORDER BY clauses.
Amazon SQL Interview Question for Data Scientist Position
Revenue Over Time
The SQL interview question that we are going to examine in detail in this article has been asked during an interview at Amazon. With the title “Revenue Over Time”, it challenges the candidate to calculate the rolling average of total revenue from Amazon purchases using SQL and based on the rolling average definition provided in the question.


Link: https://platform.stratascratch.com/coding/10314-revenue-over-time
We’re being asked to find the 3-month rolling average of total revenue from purchases given a table with users, their purchase amount, and date purchased. What’s more, we shouldn’t include returns which are represented by negative purchase values and we need to output the month and 3-month rolling average of revenue, sorted from earliest month to latest month.
Furthermore, this Amazon SQL interview question specifies that a 3-month rolling average is defined by calculating the average total revenue from all user purchases for the current month and previous two months. The first two months will not be a true 3-month rolling average since we are not given data from last year.
This is one of the hard Amazon SQL interview questions because it deals with a difficult concept of a rolling average and it has many additional requirements and restrictions that we need to account for. But it’s also one of the important Amazon SQL interview questions because calculating a rolling average is a common data science problem. There are also multiple ways in which this can be solved using SQL and that’s why we will cover several different approaches.
Framework to Solve this Amazon SQL Interview Question
Let's make the process of solving our interview question easier. We'll follow an easy framework that can be applied to any data science interview problem. This framework has only three easy steps but it creates a logical pipeline for approaching any data science problems concerning writing code for manipulating data. The three steps are following:
- Understand your data:
- First, you have to list your assumptions about the data columns so that you know which columns you need to use
- If you still don’t feel confident you understand your data enough, view the first couple of rows of your data (single or multiple tables). Or if in an interview, ask your interviewer for some example values to understand the actual data, not just the columns. It’ll help you identify edge cases and limit your solution to the bounds of your assumption.
- Formulate your approach:
- Write down the logical steps you are supposed to program/code.
- Now, identify the main functions you are going to use/implement to perform the logic.
- Interviewers will be watching you; they will intervene when needed, make sure you ask them to clarify any ambiguity, they can also specify if you'll use ready-made functions, or you should write code from scratch.
- Code Execution:
- Build up your code but don't oversimplify or overcomplicate.
- I like to build it in steps based on the steps I’ve outlined with the interviewer. That means that the code is probably won't be efficient. That’s fine. Here you will be talking about optimization at the end with the interviewer.
- The most important point here is not to overcomplicate your code with multiple logical statements and rules in your each code block. A block of code can be defined as a CTE
or a subquery because it’s self-contained and separate from the rest of the code. - You need to speak up! Talk as you’re laying down code. Remember that your interviewer will be evaluating your problem-solving skills.
Understand your data
The first step, according to the framework, is to understand the data. In this case, there is only one, rather simple table called amazon_purchases. It has three columns: user_id, created_at and purchase_amt.
At an actual interview, we’re not usually given any specific data but we can expect that each row in this table represents a single purchase where for each purchase we have the ID of the user who made it, the date when it happened and the amount paid for it. This Amazon SQL interview question also informs us that it is possible for a value in the purchase_amt to be negative which means that a user purchased a product but then returned it.
amazon_purchases
| user_id | int |
| created_at | datetime |
| purchase_amt | int |
In many cases, we can solve an interview question without using the entirety of the table. We can go back to the task description and try to predict which columns will be used in our code. Here, we’re interested in the rolling average of total revenue from purchases and thus, we’ll need the dates and prices of the transactions. This means that we’ll only focus on columns created_at and purchase_amt while the column user_id won’t be particularly useful for us.
Solution 1: Common Table Expressions and INTERVAL function
Formulate Approach
Let’s jump right into the first approach to solving this Amazon SQL interview question! In this solution, we will use the concept of Common Table Expressions, or CTEs for short and an SQL function INTERVAL that will come very handy to calculate the rolling average in a simple way. But before we start writing any code, let’s formulate our approach and write down a few general steps that we’ll follow in the solution.
- Starting with what we have now, just separate rows for all purchases, let’s start by aggregating the data. And since before we can calculate the rolling average we need to know the average revenue for each month, the first step will be to create a new table with only two columns: the month and the average revenue for this respective month.
And what’s more, let’s store this table in the form of a CTE so this Common Table Expression. The CTE is basically a special syntax that allows to define a query, give it an alias and then reuse it multiple times. It’s somewhat similar to a subquery but it can easily be used more than once and for many people, the CTE syntax is much clearer and easier to read. You’ll see exactly how it looks once we start writing the code, for now let’s just say that as the first step, we want to define a CTE with total revenue per month. - When aggregating by month, we need to remember about something that may not seem obvious at first, namely, date formatting. We can assume that the values in the created_at column include the year, month and day. In reality, however, the dates may be stored in other formats or may not be consistent and we should account for all of it. For now, let’s just write down that we need to ensure the correct encoding of dates and once we get to writing the code, we can figure out how to solve it.
- Remember that this Amazon SQL interview question asks us to disregard the negative purchase values so we can filter them out in the CTE from step one. The third step will therefore be to edit the query in the CTE in such a way that it won’t output the negative amounts.
- Now, we have a table with monthly revenues that we can simply reuse using the CTE. How to get from it to a rolling average? We will need to know, for each month, not only the revenue of this month but also of the 2 previous months. To achieve this, we can use our CTE query and merge it with itself. You can think of it as taking the two columns that we already have: month and revenue, and we’ll add to it the revenue column but we’ll shift all the values by one row. Then let’s repeat it one more time and in each row we’ll have 3 different revenues from the past 3 months.
- Having this, we can simply add a SELECT clause to turn these three separate columns with revenues into a single column with their average.
- The very final step will again be about adjusting the format to what is required by the interview question. It says the output should be sorted from earliest month to latest month, so that’s what we need to do in the end.
Code Execution
Once we have written down the general steps for solving this task, we can get to coding. The first thing is to write a query returning total revenue per month. We can start by selecting the column created_at and the sum of the column purchase_amt, both from the table amazon_purchases. Since we use the aggregation function SUM(), we need to add a GROUP BY statement. Here, we aggregate by date so we say GROUP BY created_at.
SELECT created_at,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
GROUP BY created_at
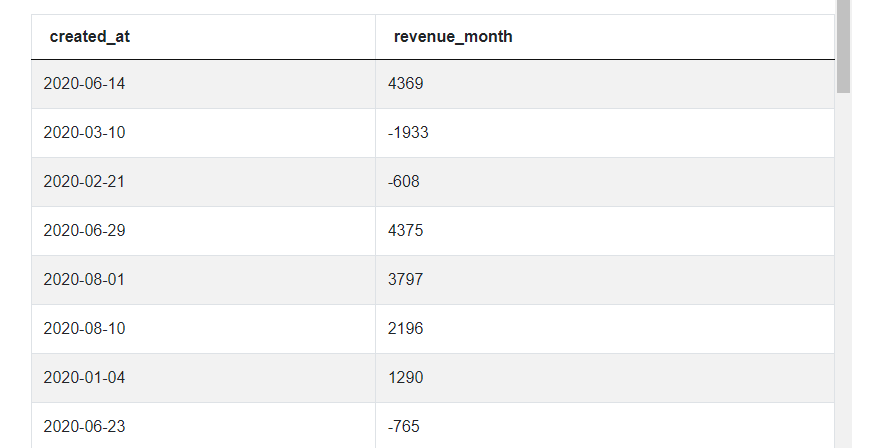
If we run it, you can see that not much has changed. That’s because we’re not really aggregating by month but by day - it has to do with how the date is stored. And this is why we have this second step, ensuring the proper encoding of date. So let’s change the format of the date to year and month only. We can start by casting the column created_at to a date format using the two colons (::). In this very case if we don’t do it, the solution will still work because all values in this column happen to be correctly formatted as dates, but we need to anticipate possible errors in data. Once we have it, we can use the to_char() function to convert the date into the format we want, in this case YYYY-MM which means year followed by month. Let’s give this column an alias ‘month_year’ and remember to update this alias in the GROUP BY clause.
SELECT to_char(created_at::date, 'YYYY-MM') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
GROUP BY month_year
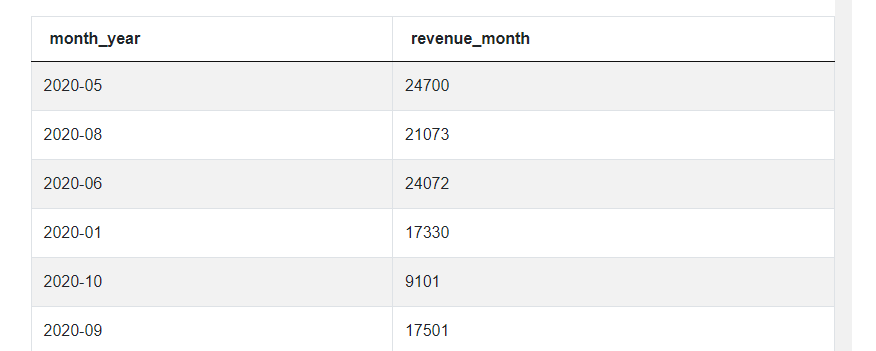
The results look much better now, we have each month only once and the total monthly revenue is calculated. But before moving on, let’s change one more thing. Later on, we will use the INTERVAL function and for this function, we need to have the date together with a day. So we can change this year-month construction that we have now, to year-month-01, as in the first day of each month. This won’t change the data, just a format in which the date is stored. We can do it with a to_date() function and specifying the desired format.
SELECT to_date(to_char(created_at::date, 'YYYY-MM'),'YYYY-MM-01')
AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
GROUP BY month_year
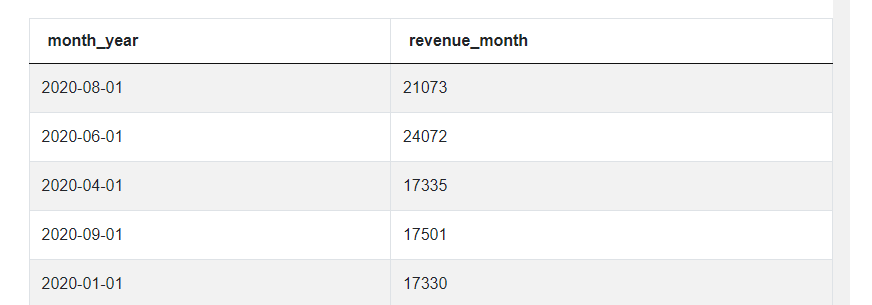
Moving on to the next step, the goal is to filter out negative purchase amounts. So we can simply add a WHERE clause to our query in which we say that purchase_amt should be greater than or equal to 0.
SELECT to_date(to_char(created_at::date, 'YYYY-MM'),'YYYY-MM-01')
AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year
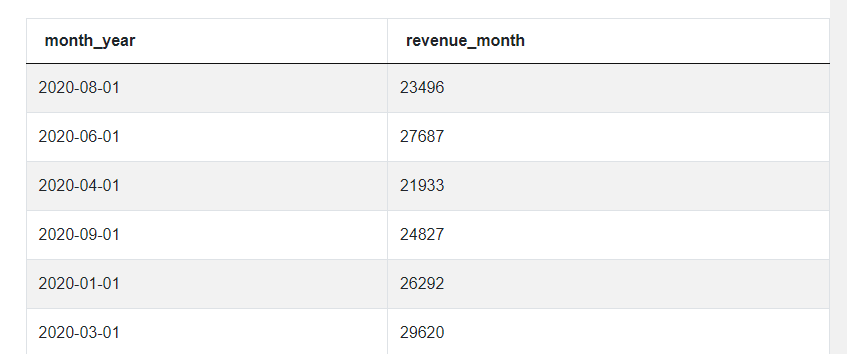
Now, this is the query that we’ll want to reuse later and for this, it needs to be declared using a CTE, the Common Table Expression. Its syntax is simple, we start with the keyword WITH followed by an alias, we can call our query ‘revenues’. After the alias we add a keyword AS and the query itself in parentheses.
WITH revenues AS
(SELECT to_date(to_char(created_at::date, 'YYYY-MM'),'YYYY-MM-01')
AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year)From now on, whenever we need to reuse this query, we’ll just write the alias ‘revenues’ and it’ll do. For example, we can write a main query like this which will return the CTE revenues:
WITH revenues AS
(SELECT to_date(to_char(created_at::date, 'YYYY-MM'),'YYYY-MM-01')
AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year)
SELECT *
FROM revenues
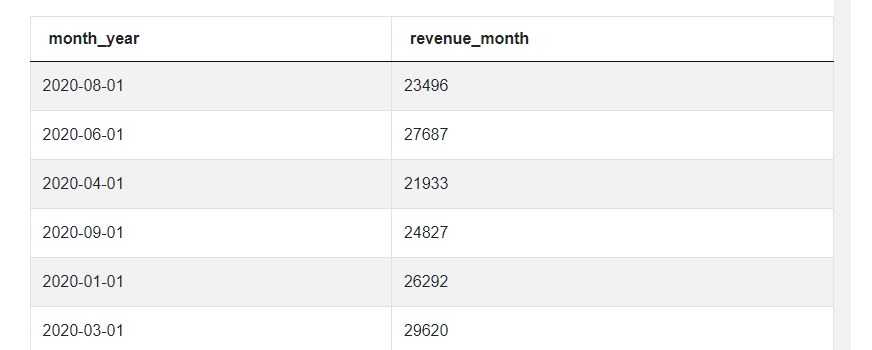
The next step is to merge the CTE ‘revenues’ with itself twice while ensuring the shift in months. Let’s start by merging it only once to see what’s going on. For this, we'll add a JOIN statement to the main query, basically joining revenues with revenues, with itself. The JOIN statement requires us to add aliases for the tables even when it’s the same table, so let’s call the first one ‘m1’ for month 1 and the other one ‘m2’. We can select the month_year and revenue_month columns from m1 and expand it by adding a revenue_month column from m2.
WITH revenues AS
(SELECT to_date(to_char(created_at::date, 'YYYY-MM'),'YYYY-MM-01')
AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year)
SELECT m1.month_year,
m1.revenue_month AS m1_revenue_month,
m2.revenue_month AS m2_revenue_month
FROM revenues m1
JOIN revenues m2 ON m2.month_year=m1.month_year
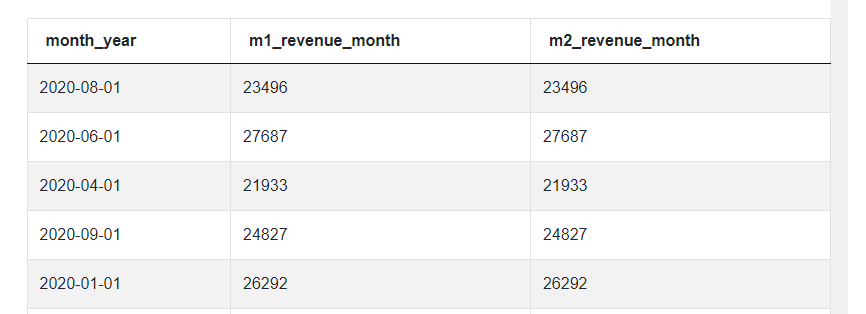
As you can see, both the revenue_month columns are exactly the same because we didn’t include the month shift. Instead, we said in the JOIN statement that, in each row, the month from m1 must equal the month from m2. So let’s add this shift. This is where all the magic happens in this solution and where we get to use the INTERVAL function. We simply say that when merging the two tables, the months from ‘m2’ should be assigned to a “the same month minus one month” from m1. And to make this happen, we simply add ‘-INTERVAL '1 Months'.
WITH revenues AS
(SELECT to_date(to_char(created_at::date, 'YYYY-MM'),'YYYY-MM-01')
AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year)
SELECT m1.month_year,
m1.revenue_month AS m1_revenue_month,
m2.revenue_month AS m2_revenue_month
FROM revenues m1
JOIN revenues m2 ON m2.month_year=m1.month_year-INTERVAL '1 Months'
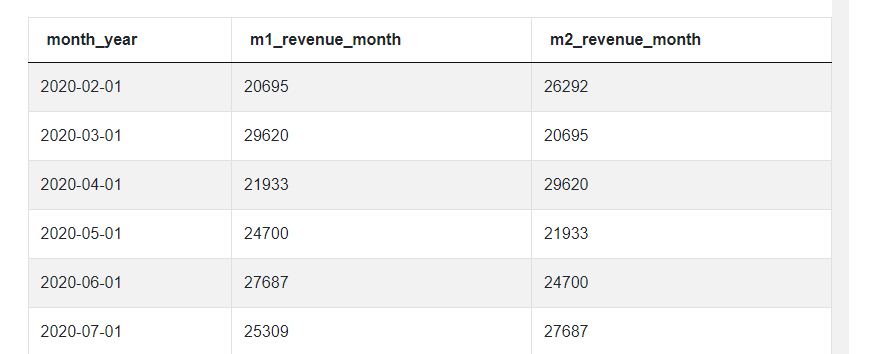
Can you see how these two revenue_month columns are shifted by exactly one month? Let’s do it again because, remember, we need to merge the CTE with itself twice. Let’s add another JOIN statement and the only difference this time is that INTERVAL will be ‘2 Months’.
WITH revenues AS
(SELECT to_date(to_char(created_at::date, 'YYYY-MM'),'YYYY-MM-01')
AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year)
SELECT m1.month_year,
m1.revenue_month AS m1_revenue_month,
m2.revenue_month AS m2_revenue_month,
m3.revenue_month AS m3_revenue_month
FROM revenues m1
JOIN revenues m2 ON m2.month_year=m1.month_year-INTERVAL '1 Months'
JOIN revenues m3 ON m3.month_year=m1.month_year- INTERVAL '2 months'
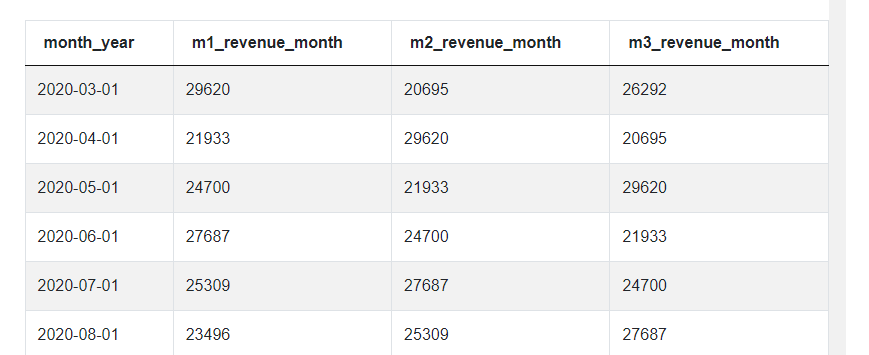
When we run this code, you can see that in each row we have a month, then the total revenue in this month, then in the next column the revenue from the previous month and finally the revenue from 2 months ago. From this, we can calculate the average by summing all three revenues in each row and dividing the total by 3.
WITH revenues AS
(SELECT to_date(to_char(created_at::date, 'YYYY-MM'),'YYYY-MM-01')
AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year)
SELECT m1.month_year,
(m1.revenue_month+m2.revenue_month+m3.revenue_month)/3
AS rolling_avg
FROM revenues m1
JOIN revenues m2 ON m2.month_year=m1.month_year-INTERVAL '1 Months'
JOIN revenues m3 ON m3.month_year=m1.month_year- INTERVAL '2 months'

The last step we defined was to sort the results by month. But actually, there’s no need to do it. As you can see, the results are nicely ordered already. How did it happen? That’s because of using the INTERVAL function, it’s side-effect is that it sorts the results and for us it happens to be the right ordering. The one last thing we may want to do, is to replace this date format of year-month-01 to just year and month. We can do it using the to_char() function like before. And we can consider it our final solution.
WITH revenues AS
(SELECT to_date(to_char(created_at::date, 'YYYY-MM'),'YYYY-MM-01')
AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year)
SELECT to_char(m1.month_year, 'YYYY-MM') AS month,
(m1.revenue_month+m2.revenue_month+m3.revenue_month)/3
AS rolling_avg
FROM revenues m1
JOIN revenues m2 ON m2.month_year=m1.month_year-INTERVAL '1 Months'
JOIN revenues m3 ON m3.month_year=m1.month_year-INTERVAL '2 months'The output should be:

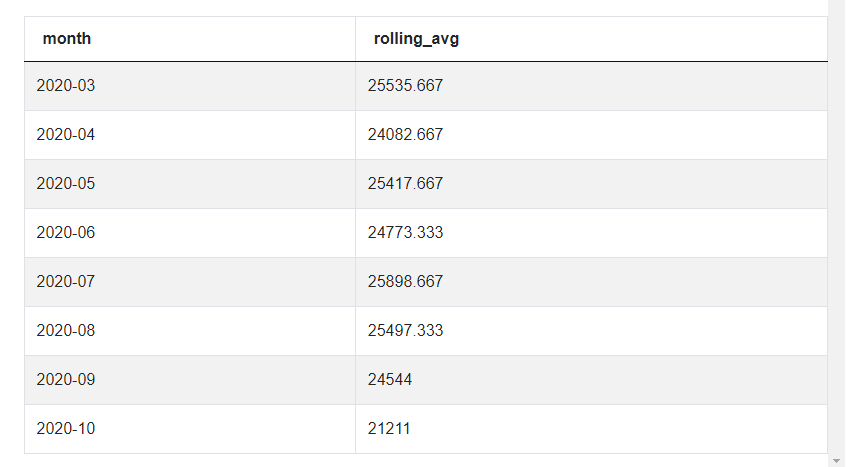
This solution will not be accepted as an official solution by a StrataScratch platform. It is because it omits the first two months: 01/2020 and 02/2020. In the real world, it isn't a mistake. Especially if it isn't specified how you deal with the first two months when calculating the rolling average: do you omit them completely, or do you calculate the rolling average with incomplete data?
Solution 2: Inner Query / Window Function
There is also another approach to solving this Amazon SQL interview question. Instead of using the INTERVAL function which requires specific formatting of the dates, we can use another method called a window function. In SQL, window functions are used to aggregate results but are more powerful than, for example, using a GROUP BY clause. The window functions are also the most common technique used when calculating rolling averages.
Formulate Approach
But as always, before writing any code, let’s define some high-level steps that the solution will follow:
- Similarly, as in the previous approach, the first step will be to write a query for total revenue in each month. Last time we used the Common Table Expressions to define it but since this time there won’t be a need to reuse this query, so we can use a standard inner and outer query approach.
- And right away, we need to remember to solve the date formatting issue that we observed in the previous solution, so let’s convert all the dates to year-month format. This time we’re not using the INTERVAL function so it won’t be necessary to switch formats all the time and only this one conversion will do.
- The third step in the previous solution was to filter out negative purchase amounts and it stays the same. Again, we should do it already in the inner query.
- Now, this is the main change, compared to the previous approach because we won’t be merging the subquery with itself and using the INTERVAL function, instead, we will write a special window function that will return the rolling average.
- And the final step is again pretty much the same because in the end we need to ensure the proper ordering of the results.
Code Execution
After defining the steps, we can get straight to writing the code and the beginning will be pretty much the same as the last one because we’re writing a query returning the monthly revenue.
SELECT created_at,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
GROUP BY created_at
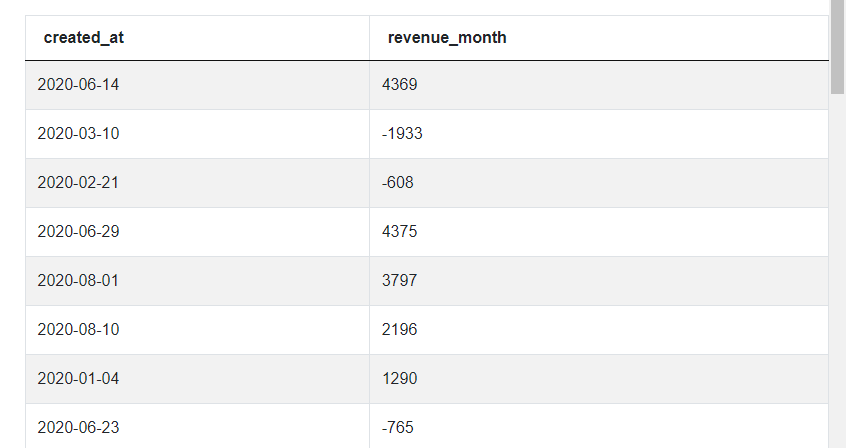
And the second step will also be nearly identical, we want to convert the dates in the created_at column to the year-month format. In this case, only one to_char() function will do the trick because we don’t need this strange ‘year-month-01’ format that was necessary for the INTERVAL function.
SELECT to_char(created_at::date, 'YYYY-MM') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
GROUP BY month_year
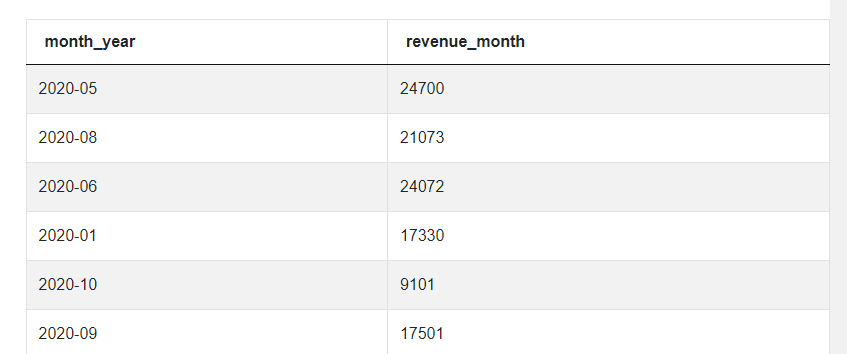
The third step is also something we already covered, let’s add a WHERE clause to filter out the negative purchase amounts.
SELECT to_char(created_at::date, 'YYYY-MM') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year
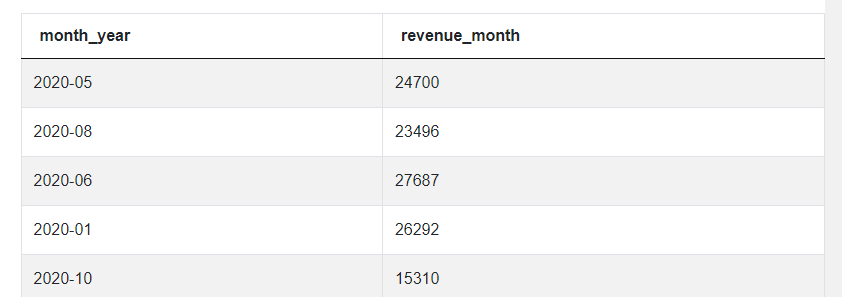
Now is where things start getting complicated again, so let’s go through it slowly. The query that we’ve just written will become the inner query or a subquery and we will use it in the FROM clause of the outer or main query. So let’s start by writing a very generic outer query. I’ll also give the inner query an alias ‘m’ for monthly revenue.
SELECT *
FROM
(SELECT to_char(created_at::date, 'YYYY-MM') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year) m

As you can see, this outer query doesn’t change the results. Because of this asterix in the SELECT clause and no filters, it simply returns the output of the inner query. But let’s change it now so that instead of the revenue_month column, it’ll return the rolling average.
SELECT m.month_year,
AVG(m.revenue_month) AS rolling_avg
FROM
(SELECT to_char(created_at::date, 'YYYY-MM') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year) mThis query won’t work yet because we have the aggregation function AVG() but there’s no GROUP BY clause or a window function following it. If we added a GROUP BY clause, for example GROUP BY month_year, it would still result in a total revenue in each month, it wouldn’t be any different from the inner query. Window function, on the other hand, is much more powerful. Its syntax starts with a keyword OVER and then in parenthesis we can put instructions, for example something like ORDER BYmonth_year.
SELECT m.month_year,
AVG(m.revenue_month) OVER(ORDER BY m.month_year)
AS rolling_avg
FROM
(SELECT to_char(created_at::date, 'YYYY-MM') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year) m
This is already a valid window function and this query will work, but that’s not really what we need. What this window function does is it sorts the rows by month and for each month calculates the average revenue from itself and all the rows that are above it. But we’re interested in the average revenue from a month and only 2 previous months instead of all of them. To correct it, we can add a command that reads ‘rows between 2 preceding and current rows’. After all, this is exactly what we want and even though this may sound like plain English and not SQL, if we put this command in the window function, it’ll work.
SELECT m.month_year,
AVG(m.revenue_month) OVER(ORDER BY m.month_year ROWS
BETWEEN 2 PRECEDING AND CURRENT ROW) AS rolling_avg
FROM
(SELECT to_char(created_at::date, 'YYYY-MM') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>=0
GROUP BY month_year) m
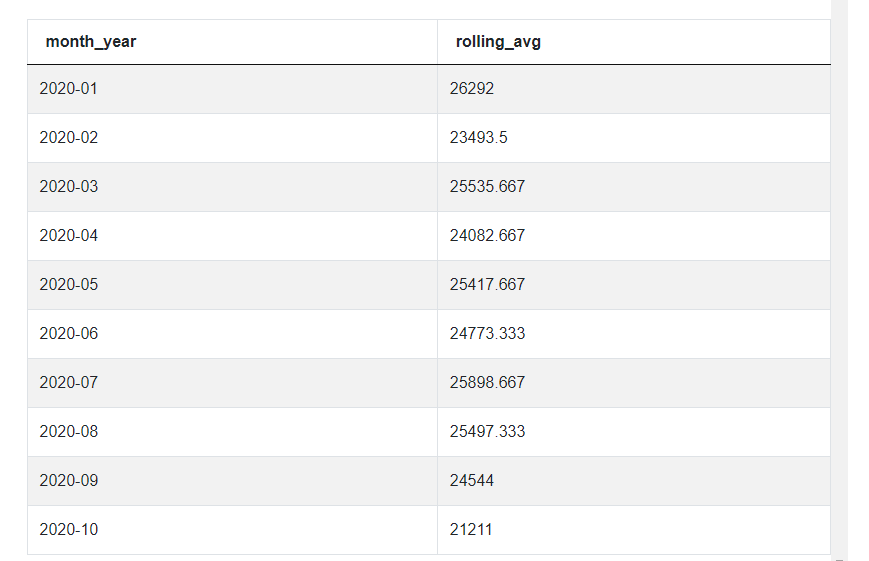
When we run this whole query, you can see that it works and it returns the same results as in the previous solution, so we have found the rolling average as requested. And even though the last step that we have defined is to sort the results, as you can see they are already in the right order. That’s because we included the ORDER BY clause in the window function and that’s exactly what this function did - it sorted the results by month and only then got to calculating the averages. And that’s why there’s no need to sort it again and this is our final solution.
Check out our article SQL window functions to find the other types of window functions and how to use them.
Solution 3: CTEs and no analytic functions
We have seen the solutions using the INTERVAL function and the window function but what to do in case we don’t remember the exact syntax for them? Is it possible to solve this Amazon interview question in SQL but without using any analytic functions? While it’s not the most common way of solving the rolling average problems, there exists a solution in which the clever merging of tables combined with a simple aggregation and a WHERE clause can produce the required output.
Formulate Approach
Again, before writing the code, let’s formulate the approach in the form of a few general steps. The first 3 steps will be the same as before. We need to define a query returning the monthly revenue while ensuring the proper formatting of the dates and filtering out the negative purchase amounts. Since we’ll need to reuse this query, let’s again store it in the form of a Common Table Expression.
- Define CTE with total revenue per month;
- Convert dates to year-month;
- Filter out negative amounts.
- Once we have done this, we will merge the CTE with itself using a JOIN statement but in such a way that, for each month, we will have the revenue not only for this month but also from all the previous months. For example, since in the sample data there are two months before March 2020, there will be 3 rows for this month while each row will have the different monthly revenue: one will be from March 2020, one from February 2020 and the last one from January 2020 as this is the first month.
- Next, using WHERE clause, we can filter these results to only leave some of the rows. Namely, for each month, we will only leave the revenue from this month and the two previous months.
- Finally, once we have up to 3 revenues for each month, we can take the average using the SQL aggregation function AVG() and group the results by month to obtain the rolling average.
- Then the last step will again be the same as previously as we will need to ensure the correct ordering of the output.
Code Execution
Getting to the coding part, we can solve the first three steps with the same query that we have seen already. This will convert the dates to the year-month format, return the total revenue per month and disregard the negative purchase values.
SELECT to_char(created_at, 'yyyy-mm') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>0
GROUP BY month_year
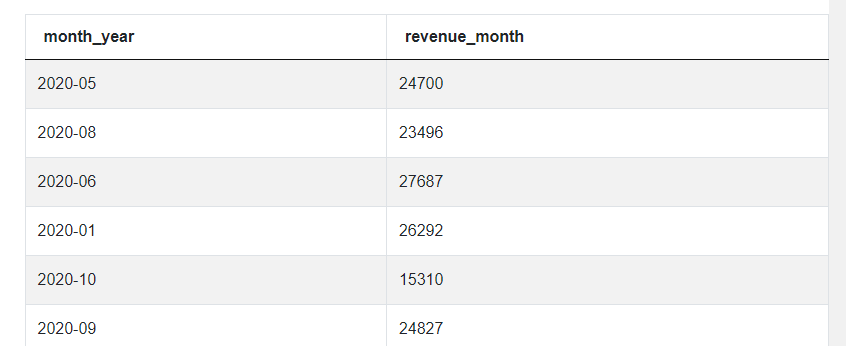
Since we want to use this query several times, let’s declare it as a CTE and give it an alias.
WITH cte AS
(SELECT to_char(created_at, 'yyyy-mm') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>0
GROUP BY month_year)
SELECT *
FROM cteThis is all something we have seen before so let’s do something new. The next step is to merge the CTE with itself such that it outputs, for each month, the revenue from this month and from all the previous months. We can merge the CTE using a JOIN statement and even though it’s the same table twice, let’s give it different aliases, ‘a’ and ‘b’. But how to return the revenue for all the previous months? For this, we’ll need to modify the condition of the JOIN so everything after the ON keyword. Instead of saying that the month in ‘a’ should be equal to the month in ‘b’ as we did before, now we want to say that the month in ‘a’ should be larger than or equal to the month in ‘b’. Let’s code it and see what happens.
WITH cte AS
(SELECT to_char(created_at, 'yyyy-mm') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>0
GROUP BY month_year)
SELECT a.month_year,
b.revenue_month
FROM cte a
JOIN cte b ON a.month_year >= b.month_year

When we select the month_year column from the CTE ‘a’ as the label of the month and the column revenue_month from CTE ‘b’, you can see we can get the revenues not only from the given month but also from all the previous months. It’s a bit hard to see now that the values are not sorted but as you can see there’s only one row for January 2020 because there are no months before it in this dataset, and there are 10 rows for October 2020 because each row has a revenue for some month between January and October.
We have all these revenue from previous months but for the rolling average, we only need the three most recent months, how to achieve that? We can add the WHERE clause in which we say that the difference between any two month numbers should be lower than 3. The problem is that in SQL we can’t compare a date with an integer so first we need to change the formatting of the date again. To change the year-month to integer, we can use the cast function like this:
cast(month_year AS integer)But this will change the entire date to integer, so we’ll have, for example, the number 202010 instead of a month number which should be 10. So instead of casting the whole date, let’s only cast the 2 rightmost characters using the right() function.
cast(right(month_year, 2) AS integer)Now, we can construct the complete WHERE clause and add it to the query:
WITH cte AS
(SELECT to_char(created_at, 'yyyy-mm') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>0
GROUP BY month_year)
SELECT a.month_year,
b.revenue_month
FROM cte a
JOIN cte b ON a.month_year >= b.month_year
WHERE cast(right(a.month_year, 2) AS integer) -
cast(right(b.month_year, 2) AS integer) < 3
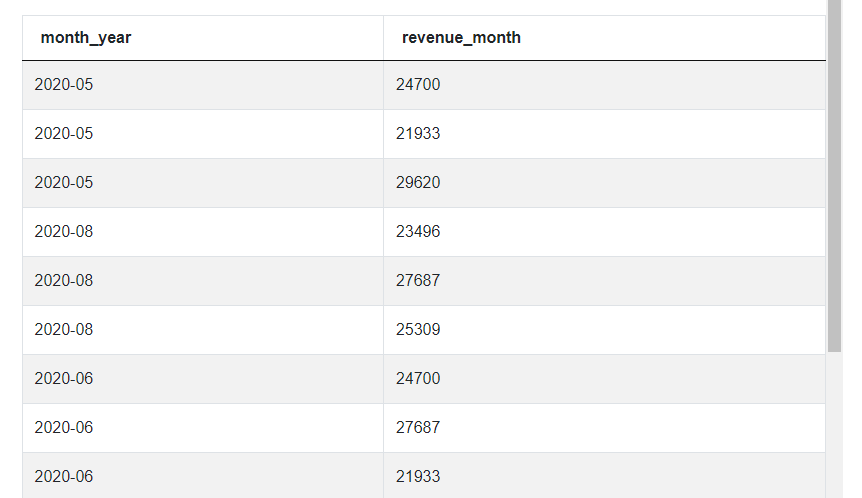
As you can see, now we’re left with only up to 3 rows for each month which represent the revenue in this month and the 2 previous months. Let’s add a simple aggregation function AVG() and the corresponding GROUP BY clause to calculate the average for each month from these 3 rows.
WITH cte AS
(SELECT to_char(created_at, 'yyyy-mm') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>0
GROUP BY month_year)
SELECT a.month_year,
avg(b.revenue_month) as rolling_avg
FROM cte a
JOIN cte b ON a.month_year >= b.month_year
WHERE cast(right(a.month_year, 2) AS integer) -
cast(right(b.month_year, 2) AS integer) < 3
GROUP BY a.month_yearAnd the last step is to sort the values by month in the ascending order. This time we didn’t use any analytic function that would order the values as a side effect so we actually need to perform this step and add an ORDER BY clause before we have the complete query.
WITH cte AS
(SELECT to_char(created_at, 'yyyy-mm') AS month_year,
sum(purchase_amt) AS revenue_month
FROM amazon_purchases
WHERE purchase_amt>0
GROUP BY month_year)
SELECT a.month_year,
avg(b.revenue_month) as avg_roll
FROM cte a
JOIN cte b ON a.month_year>=b.month_year
WHERE cast(right(a.month_year, 2) AS integer) -
cast(right(b.month_year, 2) AS integer) < 3
GROUP BY a.month_year
ORDER BY a.month_year asc

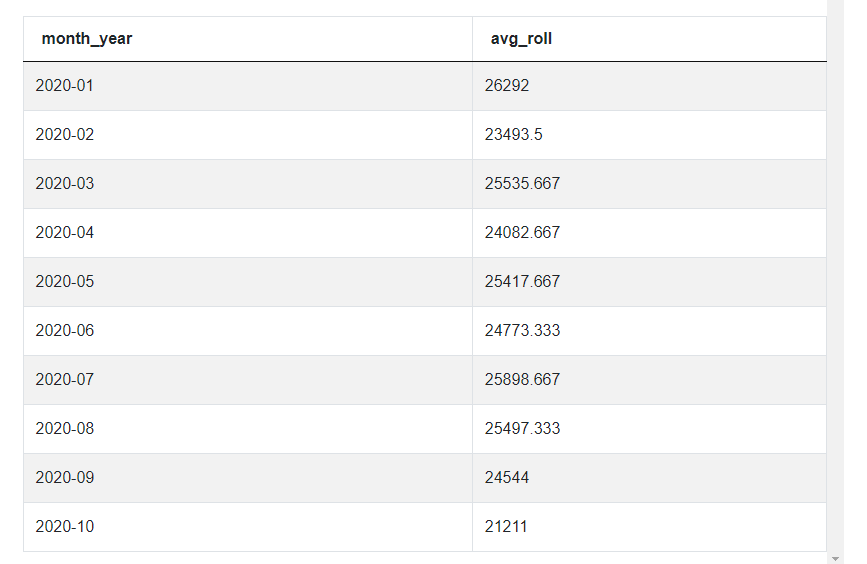
Check out our previous post Amazon Data Scientist Interview Questions to find some advanced interview questions from Amazon that will test your date manipulation and formatting skills as well as your window function knowledge.
Comparison of Approaches
In this article, we have covered 3 different approaches but are all of them equally good? Or are some of them better in some way than others? In all of the cases, we obtained the required output so all the solutions are correct but let’s talk about efficiency and performance.
When it comes to time complexity, all the solutions include two queries which then need to be merged together so the efficiency should be quite similar. But note how in the solutions that use the CTEs we merge the query with itself several times using the JOIN statement. This makes these solutions less efficient than the second approach with the subquery. On top of this, the window function from the second solution is generally a faster method of aggregation than using the GROUP BY statement so if we had a large dataset, the second approach would probably allow us to get the solution the fastest.
Additionally, the window function is the most common approach when solving the rolling average problems. It is a powerful method and it results in an elegant solution. And since it requires some more in-depth knowledge, the window function approach is probably something the interviewer expects to see when asking the rolling average question.
Conclusion
We have discovered multiple different ways of solving only one Amazon SQL interview question. Remember that the 3 methods mentioned here are not all the possibilities and there exist countless other ways, be it more or less efficient, for answering this interview question!
On our platform, you can practice answering the interview questions by constructing solutions to them but always try to think of other ways to solve them, maybe you’ll come up with a more efficient or a more elaborate approach. Make sure to post all your ideas to benefit from the feedback of other users, you can also browse all their solutions for inspiration!
And lastly, don’t forget to stick to the framework for solving any data science problems that we discussed in the beginning, it will make your interviews and your life much easier. Once again, start by examining and understanding the provided data, then formulate your approach - these are the few general steps required to solve any data science problem. Finally and based on these two, you can write your code step by step.
Share


