A Comprehensive Overview of 3 Popular Machine Learning Models

 Written by:
Written by:Nathan Rosidi
Where to start with machine learning and all its algorithms? Here’s a comprehensive overview of ML approaches and the most popular algorithms you can begin with.
To understand machine learning algorithms, you must first understand what machine learning is and its three main categories.
Machine learning (ML) is a subset of artificial intelligence (AI) that focuses on developing algorithms and statistical models that enable computers to perform tasks without being explicitly programmed for those tasks. Instead, these algorithms use patterns and inference to learn from data.
In other words, machine learning allows computers to learn from data and make decisions and predictions based on that data. For example, predicting stock market trends, recommending products or movies to users based on their past preferences, recognizing images or speech, detecting fraudulent transactions, or driving autonomous vehicles.
Categories of Machine Learning
When we talk about ML, we often categorize it into three major classes.
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
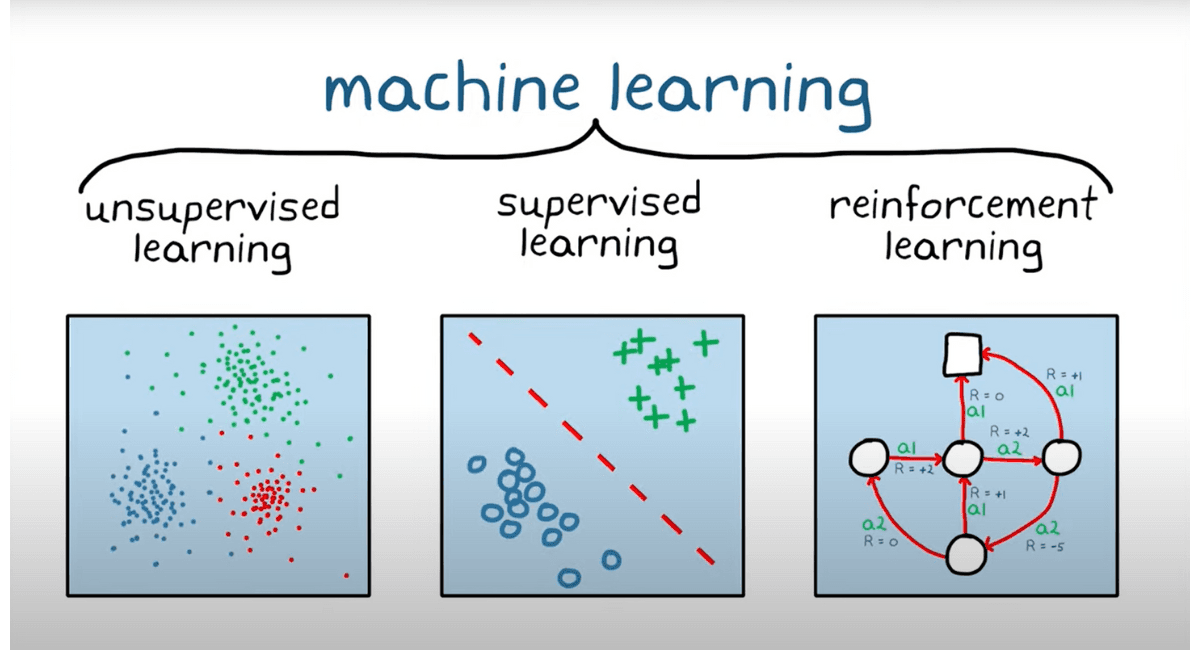
In simple terms, Supervised Learning is when the label you want to predict is in the dataset.
Unsupervised Learning makes predictions without labels in the data.
To dig deeper into the differences between these two approaches, go to our Supervised vs Unsupervised Learning article.
Reinforcement Learning is when the algorithm learns by making mistakes and eventually gets more and more accurate as it learns from the data.
But there’s another way to categorize machine learning.
Types of Machine Learning Models
We can also categorize ML models by focusing on how the model works. That way, we get these three ML types:
- Classification
- Regression
- Clustering
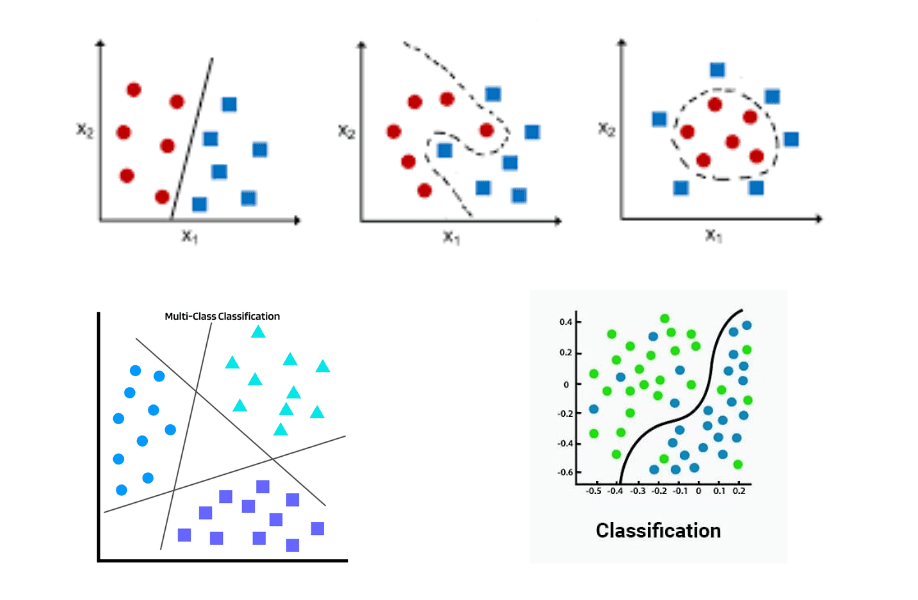
Classification focuses on grouping or labeling items.
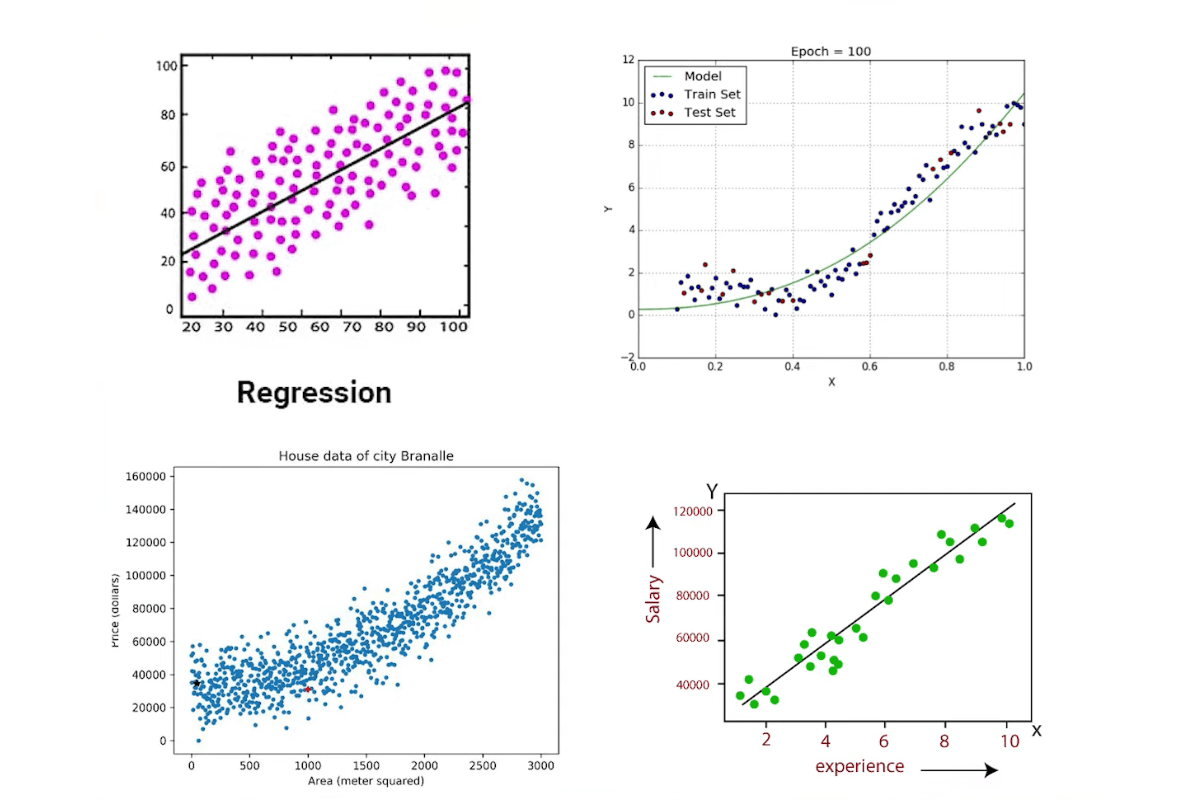
Regression attempts to understand a trend and predict numerical variables.
Clustering is all about grouping objects based on similarities.
Classification Models for Machine Learning
Four popular classification algorithms are:
- Decision Tree
- Random Forest
- Support Vector Machine (SVM)
- K-Nearest Neighbour
Decision Tree
A decision tree is a model that makes decisions based on a series of questions or tests. It's akin to playing a game of 20 questions, starting with broad questions and getting more specific as you progress. It functions like a flowchart, asking questions and following the path based on the answers.

Random Forest
Random forest is probably one of the most popular decision tree models. It is an ensemble of decision trees. It creates different sets of decision trees from randomly selected data points and then averages their predictions. This reduces the risk of overfitting and improves overall accuracy.
Check out our article Decision Tree and Random Forest Algorithm where we deeply addressed everything related to the Decision Tree algorithm and its extension “Random Forest algorithm”.
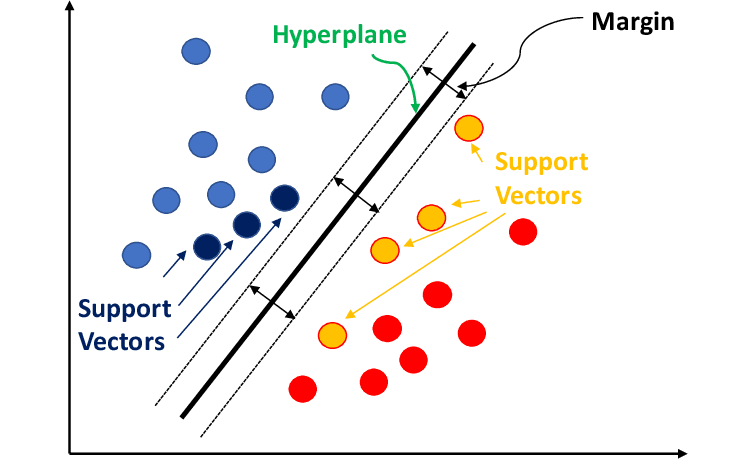
Support Vector Machine (SVM)
Support Vector Machine or SVM is used for classification. It finds the best boundary or hyperplane that separates data into different classes. The goal is to maximize the margin between the closest data points of each class. Using an analogy, if you and your friends have different types of candies, SVM is like drawing a line that sorts out all the candies into their respective groups.
K-Nearest Neighbour
Using an analogy, if you move to a new town and want to determine if your neighborhood is quiet or noisy, you might observe your nearest neighbors. If three neighbors are quiet and one is noisy, you'd likely conclude that your neighborhood is quiet.

Regression Models for Machine Learning
A popular model in the regression category is linear regression.
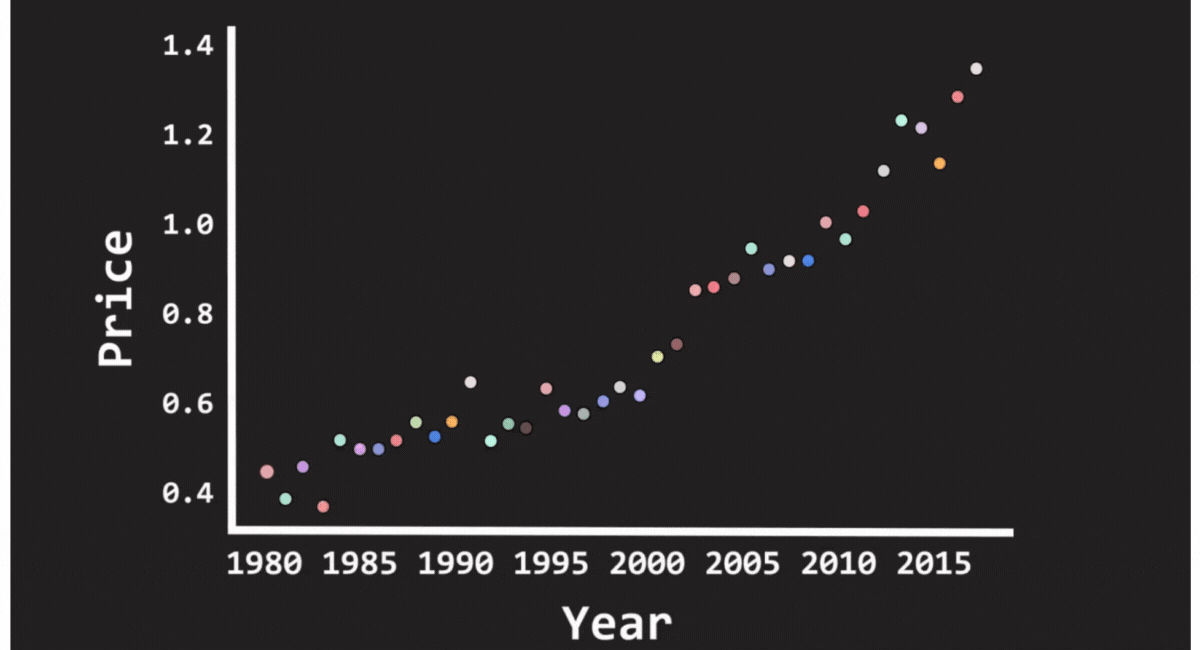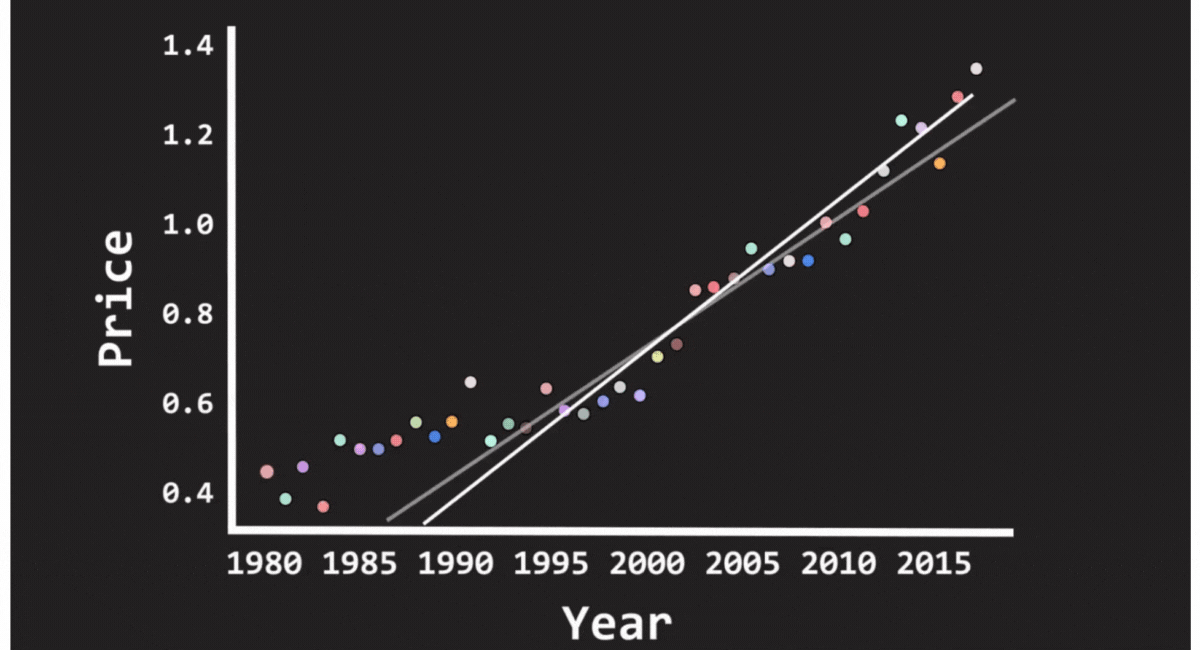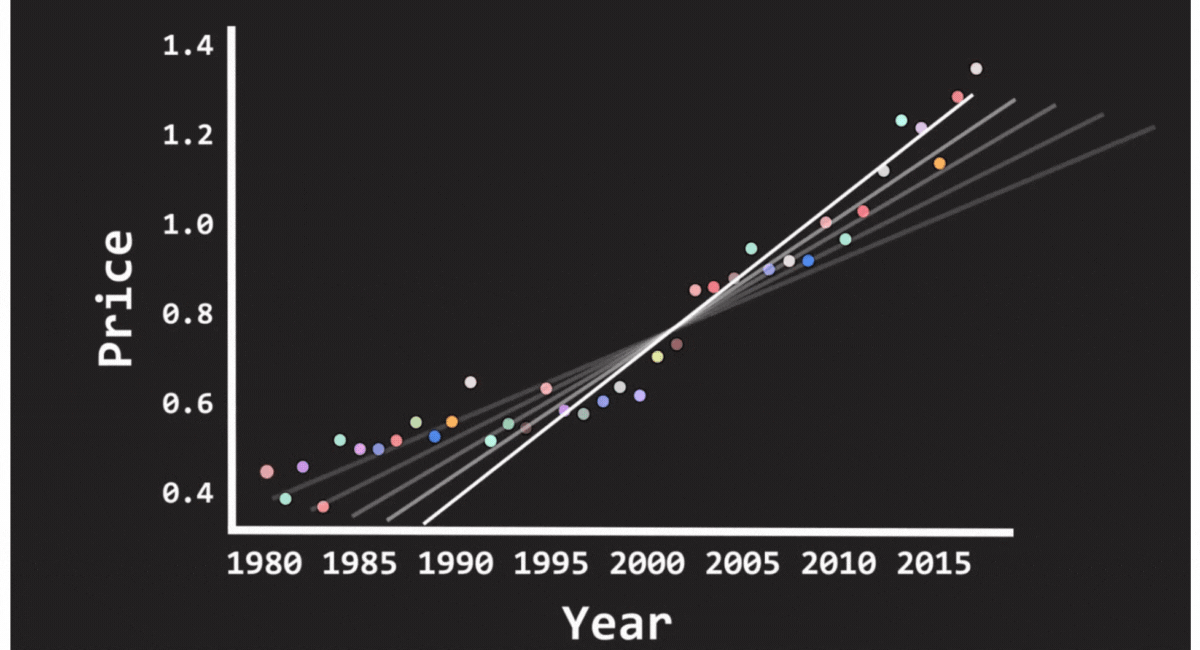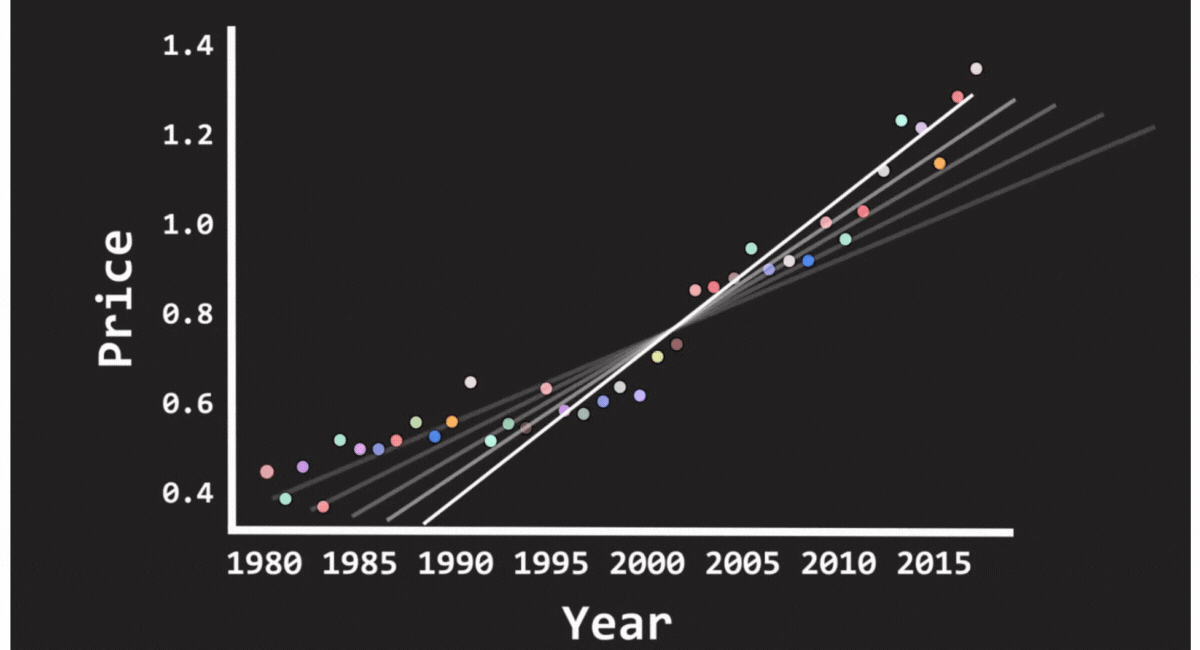
Linear Regression
Most people are introduced to this in high school. For instance, you'll notice a pattern if you're trying to predict a friend's exam results based on the number of hours they studied. More time spent studying usually correlates with better results. A linear regression model captures this correlation by representing a connection between the two variables.
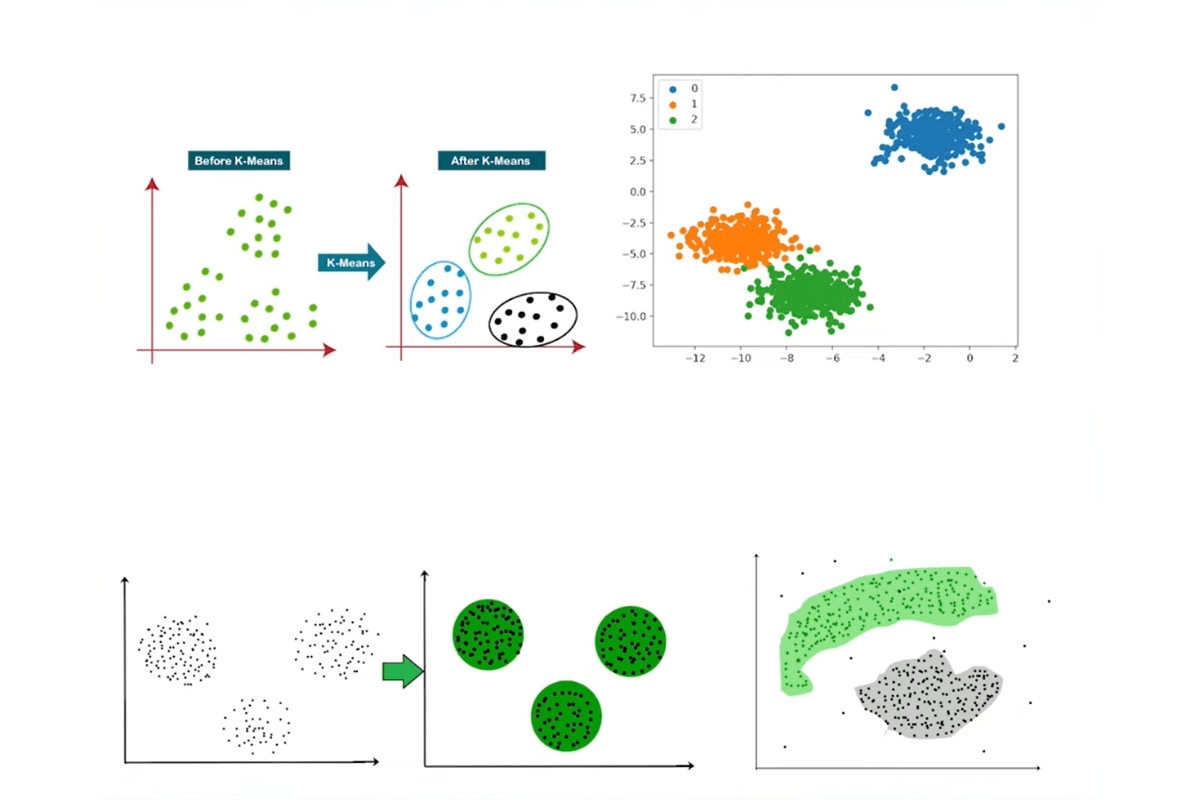
Clustering Models for Machine Learning
Clustering groups objects based on similarities. One of the most popular clustering algorithms is k-means clustering.
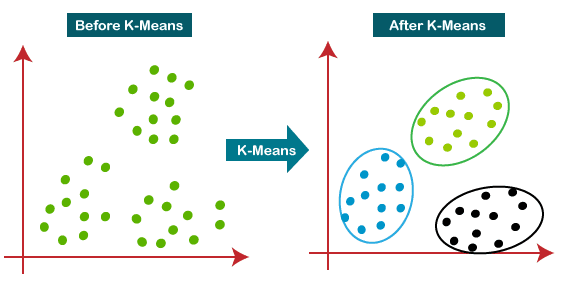
K-Means Clustering
This algorithm is used for partitioning a dataset into a set of distinct, non-overlapping groups called clusters.
Imagine you're at a large party with people from various professions, like doctors, artists, engineers, and chefs, but you don't know who belongs to which profession. Suppose you observe their conversations and group them based on similar topics they discuss. In that case, you might notice clusters forming: those talking about medical terms, those discussing art techniques, those debating engineering challenges, and those sharing cooking recipes. K-Means Clustering is like grouping these party-goers based on the similarity of their conversations, even if you initially didn't know their professions.
After learning about all these machine learning algorithms, the question naturally arises: How do you choose the right algorithm?
Choosing the Right Machine Learning Algorithm
Selecting the right machine learning algorithm isn't always straightforward. Here are three tips:
1. Understand Your Data: The type of data you have dictates the models you'll use. For instance, the presence of labels might determine if you pick a supervised or unsupervised model. Also, consider if your data is categorical or numerical.
2. Define Your Problem: Understand your goal. If you want to identify hidden patterns, you might use clustering. If you aim to forecast a trend, consider regression. For recommendations, the classification might be apt.
3. Evaluate Performance: Ensure your algorithm works effectively with your data. This can be done by evaluating the accuracy of a classification task or determining the mean squared error for a regression model. The point is to see how your model performs on the data you’ve given it.
Conclusion
You see, the algorithms are not that scary, and it’s quite easy to understand their general gist. Of course, using them in practice is much more difficult, especially when deciding which algorithm to use for your problem.
Understanding the basics of these machine learning models and their popular algorithms can provide a solid foundation for diving deeper into the machine learning algorithms you should know for data science.
Share