SQL ROW_NUMBER() Function: Syntax and Applications


Categories:
 Written by:
Written by:Nathan Rosidi
How to add SQL ROW_NUMBER() to your data handling and analysis tools? We’ll help you by explaining its workings, its syntax, and how to use it in examples.
Truth be told, relational databases are an organized form of data. However, as databases increase with the collected data, their size again moves them towards being unreadable and seem disorganized to your average user.
But you’re a very non-average user. You’re a data scientist! You thrive swimming in data. But what if I told you there’s a way to make this easier for you?
The SQL ROW_NUMBER() function is the backbone of organized data retrieval and manipulation. As a data scientist, you can use it to turn rows of data into more manageable data sets. Along the way, you’ll help the average data users by providing them with neatly ordered and easily navigable data.
In this guide, I’ll lead you through the concepts necessary for understanding SQL ROW_NUMBER(), its syntax, and its usage. I’ll show you some basic but also advanced applications of ROW_NUMBER(), best practices, and differences between SQL databases.
Understanding the Concept of SQL ROW_NUMBER()
ROW_NUMBER() is a window function in SQL that assigns a unique number to each row in a result set. It’s a function used in tasks such as ranking and pagination. The numbering is based on an ordered partition of data.
How Do Window Functions Work?
The ROW_NUMBER() definition calls for some additional explanations. First of all, what are window functions? The window functions are a special type of SQL functions that perform calculations over the data rows that are related to the current row. These rows are called a window or a window frame.
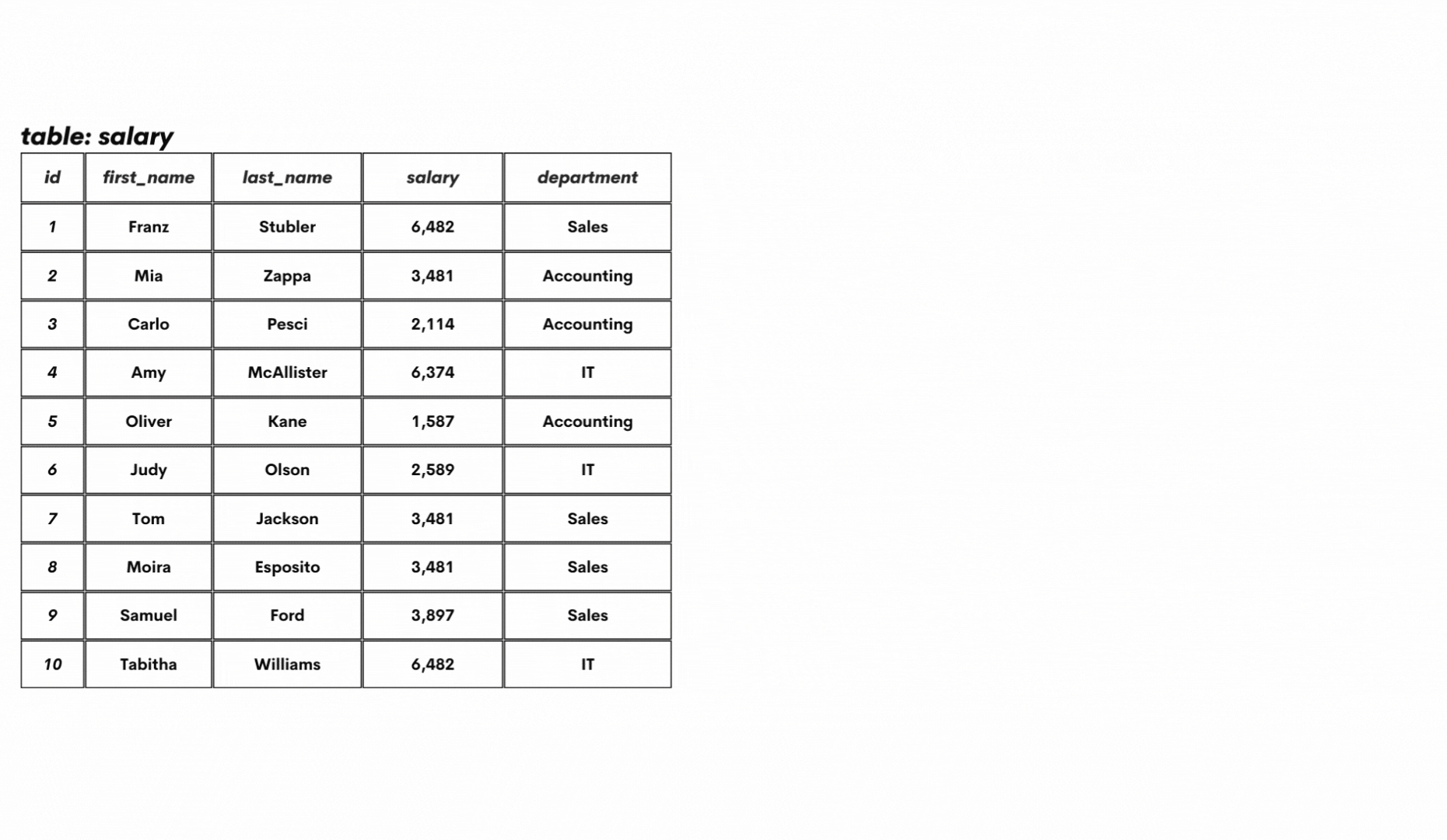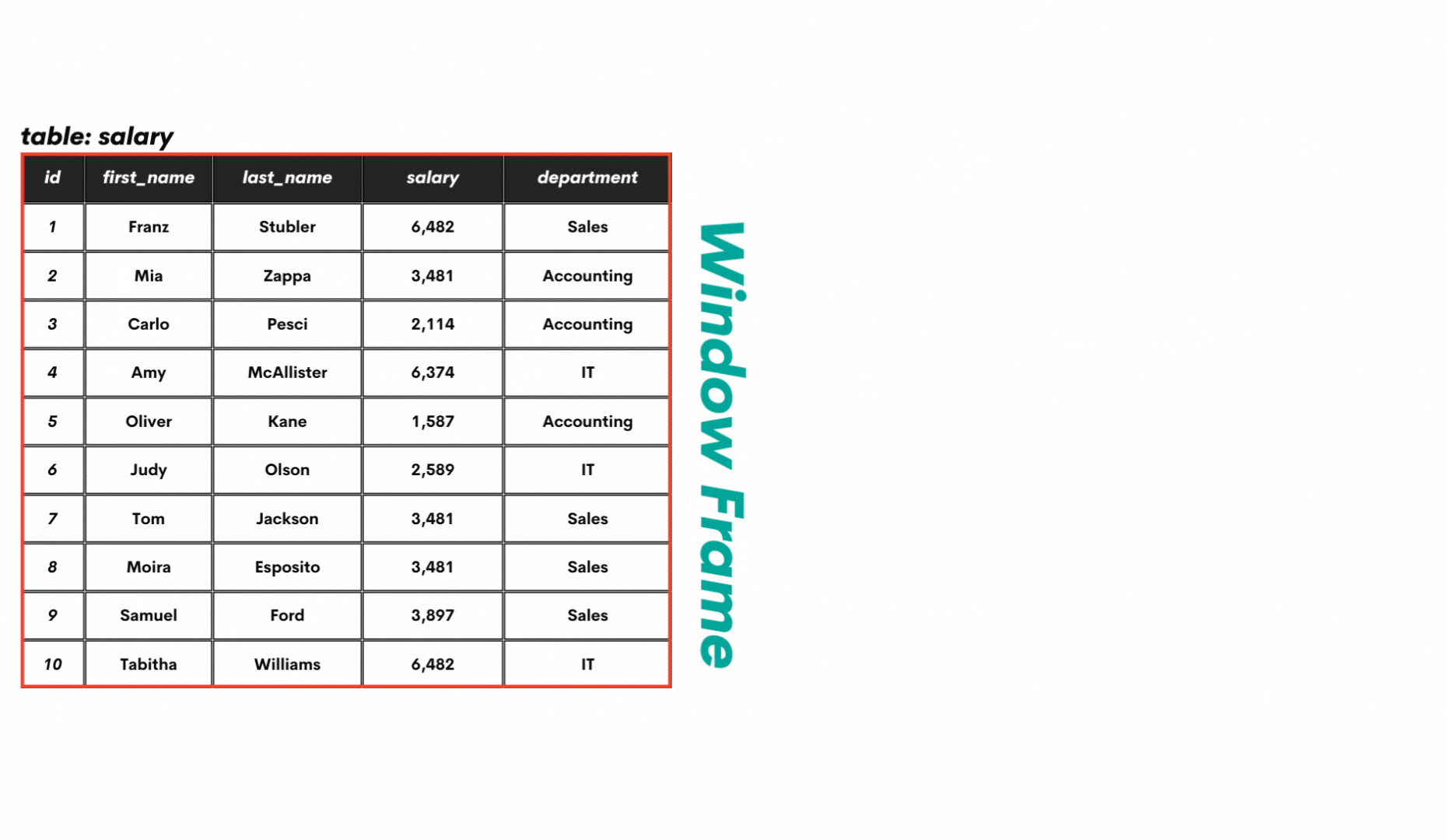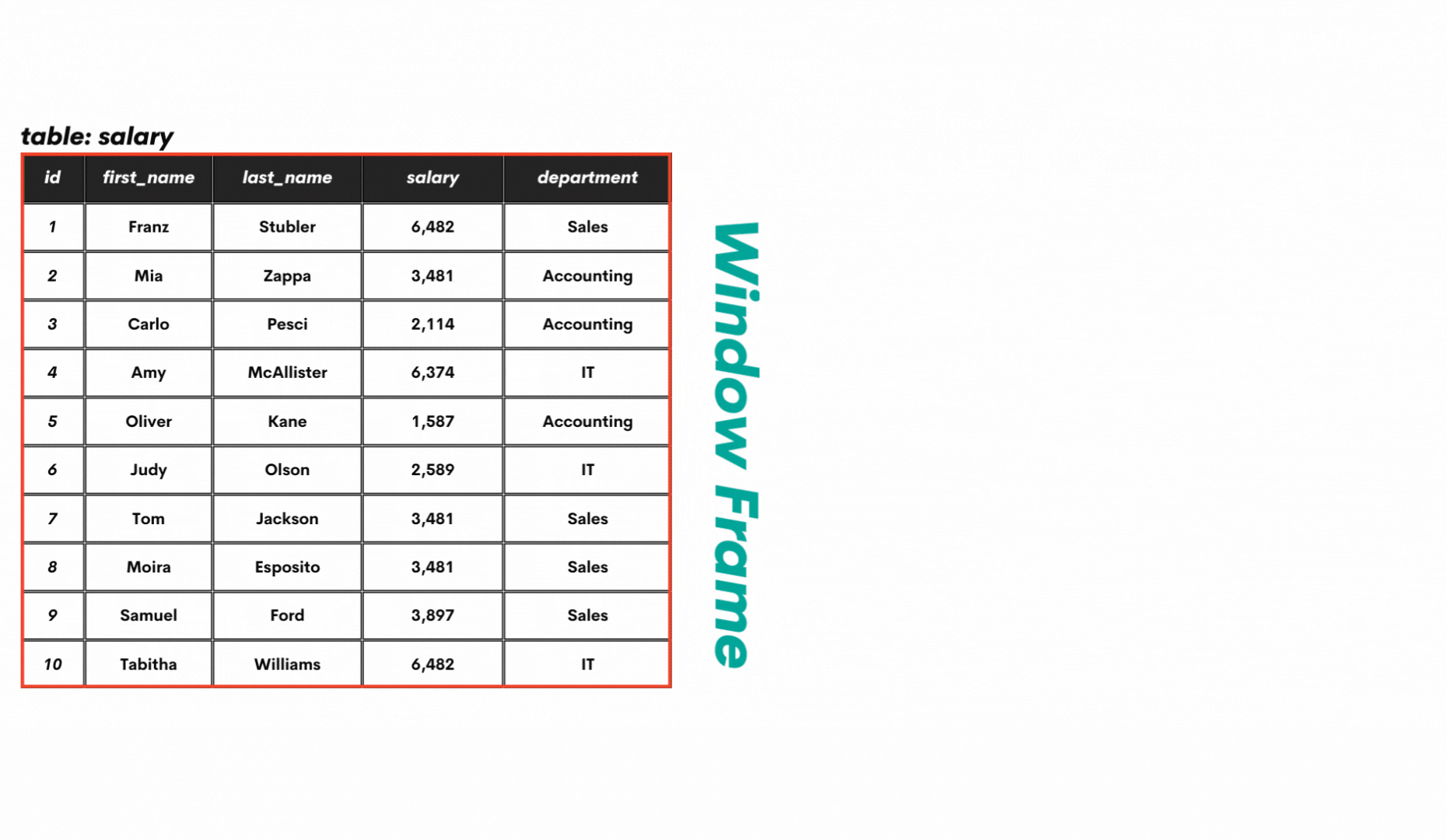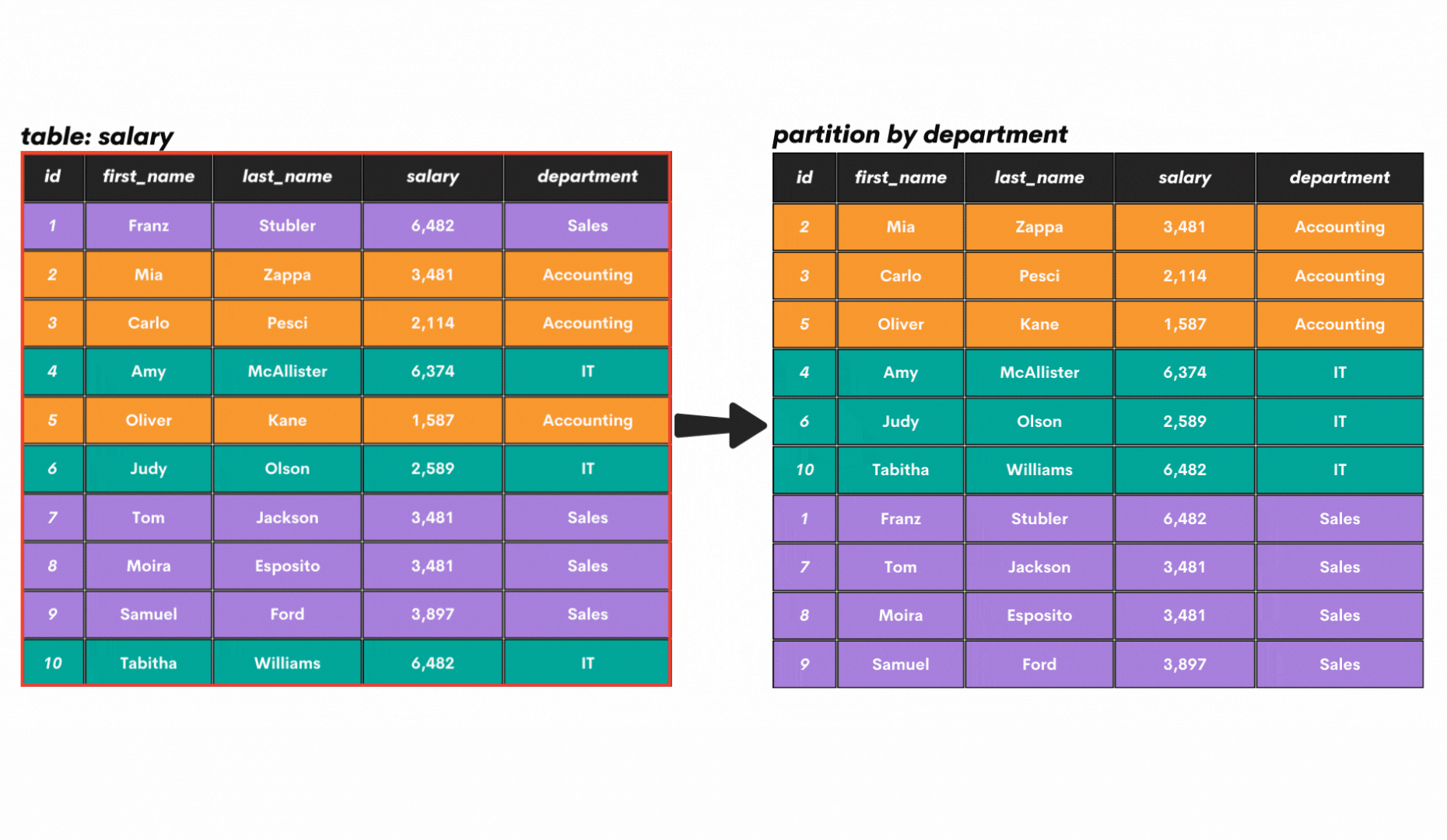
Second, what is a partition of data? Well, the window frame can be divided into smaller parts (partitions) based on certain criteria, as shown below.


You can read more about it in the SQL Cheat Sheet, the Window Functions part.
To get more practical, here’s how the table salary can be partitioned. The whole table is one window frame, without any partitions initially. This data can be partitioned, for example, by department. All this you can see in the below GIF.

Basics of SQL ROW_NUMBER()
As SQL ROW NUMBER() is used for sorting data, it belongs to the family of ranking window functions. Each ranking function is different. First, let’s see how ROW_NUMBER() ranks data, then let’s compare it to other ranking window functions.
How SQL ROW_NUMBER() Works in Data Sorting and Retrieval
The SQL ROW_NUMBER() function sorts data by assigning a unique sequential integer to rows within a partition. If there are rows with the same value, they will get different rankings. That’s why the word ‘sequential’ is crucial when talking about ROW_NUMBER(). You’ll see why when I compare it to other ranking functions.
But first, let’s see how ROW_NUMBER() works on our table salary. If I used this function to sort data by salary in descending order, it would look like this.

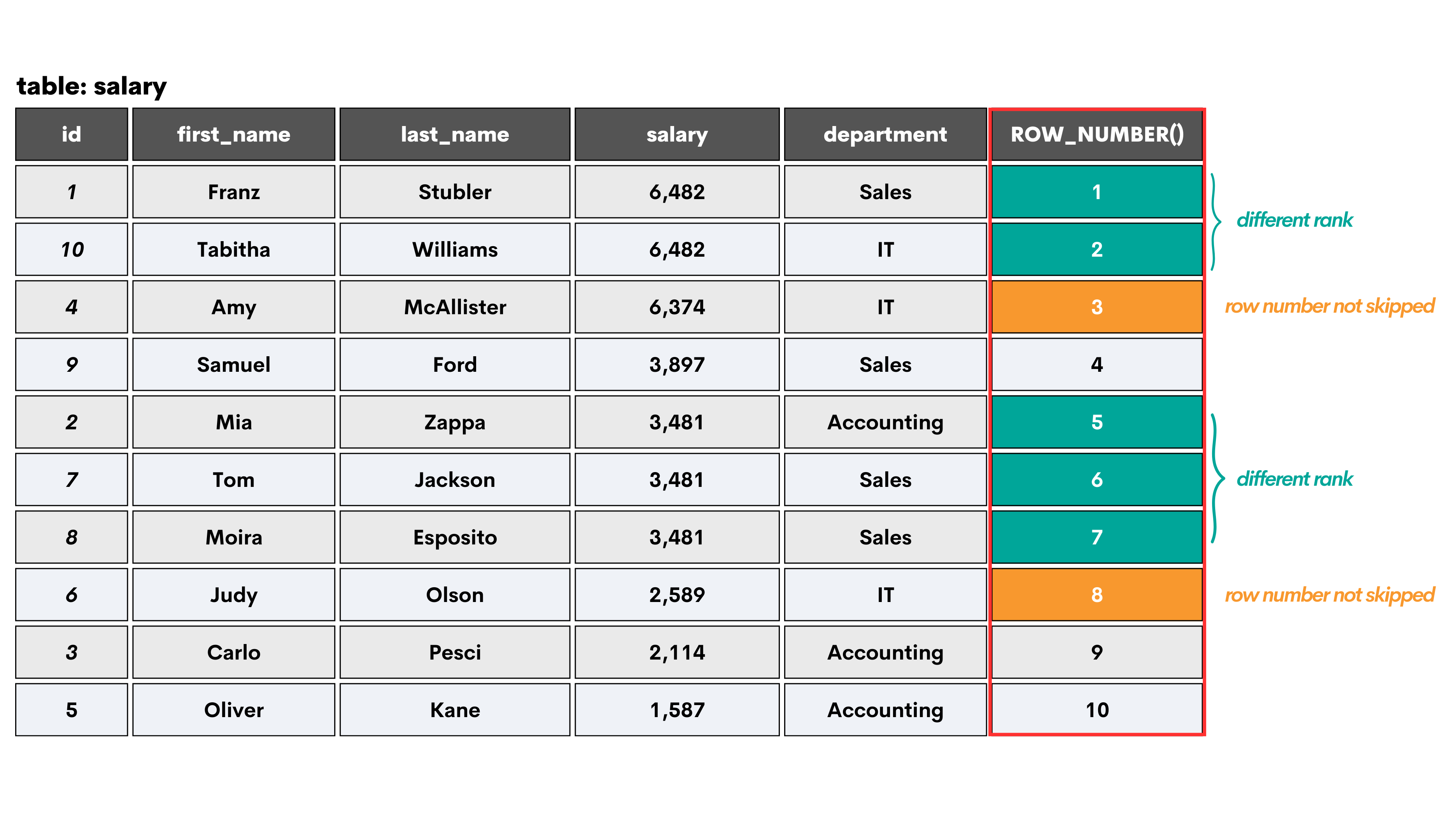
You can see that ROW_NUMBER() simply assigns the sequential ranks, no matter whether the employees have the same salary or not. It’s important to note that the duplicate values are ranked randomly. So each time, they may be ranked differently. That is unless you add another ranking level in the ORDER BY clause, which we’ll talk about later.
Comparisons With Other SQL Ranking Window Functions
Similar to ROW_NUMBER() are the RANK() and DENSE_RANK() window functions.
RANK()
The SQL RANK function sorts data by assigning a rank to rows within a partition. However, if there are rows with the same data values, they will be ranked the same. The ranking is non-sequential, meaning there’s a gap between the ranking of the rows with and without the duplicate data values.
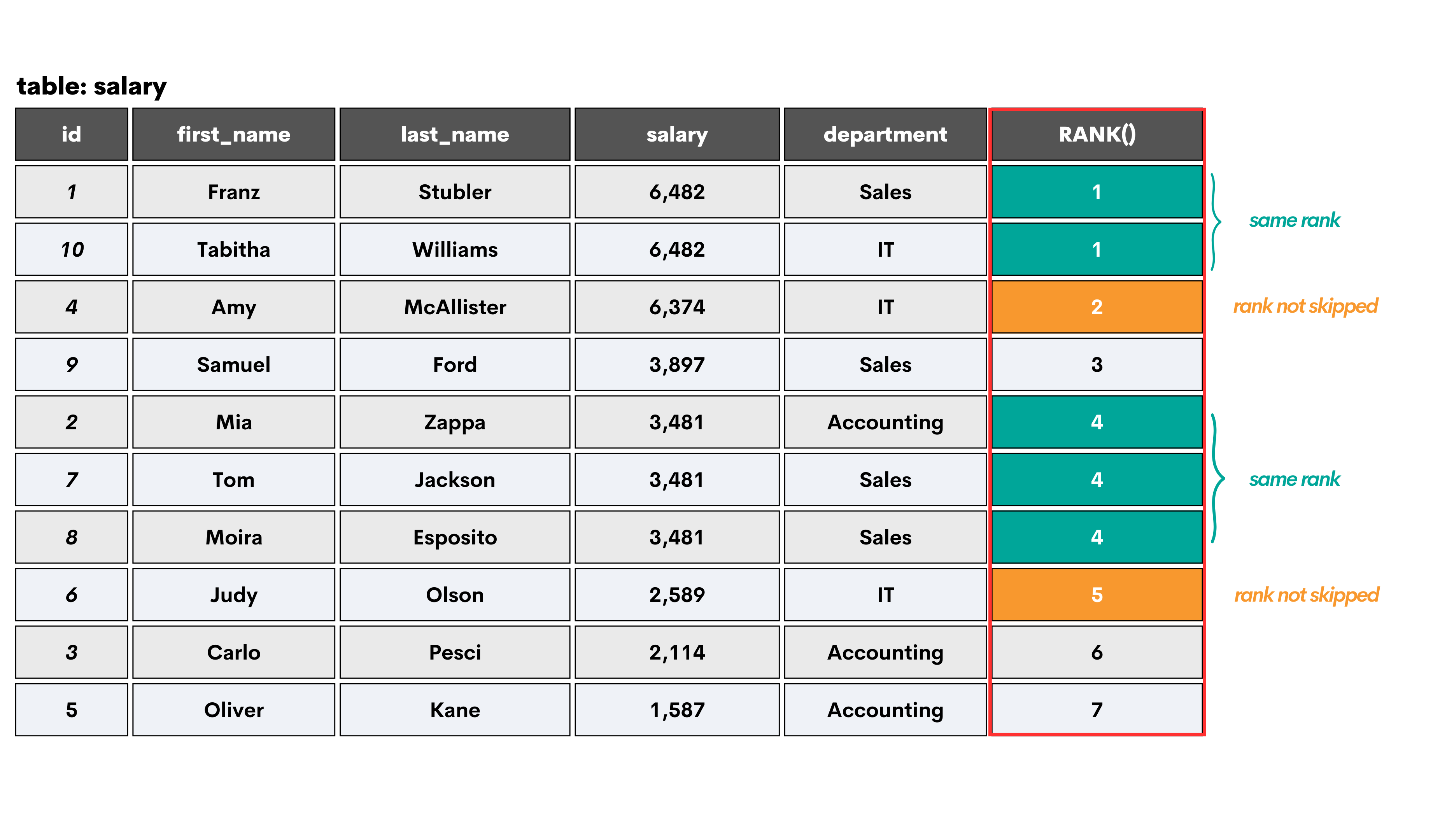
In our example, it would look like this.

The employees with the same salary have the same rank, i.e., 1 and 5. But, when the ranking reaches the next row with a unique salary value, the rank is skipped. In other words, the rank 1 is followed by the rank 3. In the same manner, the rank 5 is followed by the rank 8. The number of skipped ranks depends on the number of rows with the same value.
DENSE_RANK()
The DENSE_RANK() works the same way as RANK(), only it doesn’t leave gaps in the ranking sequences when there are ties.
Going back to our example, DENSE_RANK() would rank the salaries this way.
As you can see, the same values get the same rank. Also, there are no gaps between the ranks. In other words, as you would expect, the rank 1 is followed by the rank 2. The rank 4 is followed by the rank 5.
Syntax and Usage
The basic syntax of the SQL ROW_NUMBER() function is as follows.
ROW_NUMBER() OVER (ORDER BY column_name [ASC|DESC])The name of the function is followed by the OVER() clause. In it, you have to use the ORDER BY clause to specify the column you want to rank by. If the ranking order keyword is omitted after the column name, the default behavior is to rank data in ascending order. You can, of course, explicitly specify the order by using the keywords ASC (ascending) or DESC (descending).
You can also partition your data, which is done by adding the optional PARTITION BY clause to the basic syntax. The basic partitioning is by one column. But, you can partition data based on the several columns, and you’ll have to name them all in the PARTITION BY clause.
ROW_NUMBER() OVER (PARTITION BY column_name1 ORDER BY column_name [ASC|DESC])Simple Examples of the Basic ROW_NUMBER() Usage
I’ll use a question from our platform to demonstrate some basic uses of SQL ROW_NUMBER().
ROW_NUMBER() With ORDER BY
Here’s a question by Amazon & DoorDash.
Last Updated: July 2021
Find the job titles of the employees with the highest salary. If multiple employees have the same highest salary, include the job titles for all such employees.
Link to the question: https://platform.stratascratch.com/coding/10353-workers-with-the-highest-salaries
I won’t answer the question. Instead, I want to modify the problems’ wording to: Rank the employees from the lowest to the highest salary.
Let’s say I want to show the first and last name, salary, and joining date and then rank by the salary. For that, all the data I need is in the table worker.
This is a simple example that reflects the previous syntax explanation. Apart from selecting the required columns, I use ROW_NUMBER() to rank the data. After that, I use the mandatory OVER() clause and then ORDER BY to rank by salary in ascending order.
Simple, isn’t it?
SELECT first_name,
last_name,
salary,
joining_date,
ROW_NUMBER() OVER(ORDER BY salary ASC) AS worker_rank
FROM worker;
The code ranks the workers in the following way. You can see some of them have the same salary. As the logic of ROW_NUMBER() dictates, they are not ranked the same.
ROW_NUMBER() With Two Columns in ORDER BY
The data can be ranked by multiple columns using ROW_NUMBER().
I can take the code from the previous example and rank data by two criteria or columns: salary and joining_date.
Same as earlier, I want the workers to be ranked by their salary in ascending order. But also, if there are employees with the same salary, I want them to be ranked from the latest to the oldest joining date.
To achieve that, you add another column in the ORDER BY clause and specify the ordering type.
SELECT first_name,
last_name,
salary,
joining_date,
ROW_NUMBER() OVER(ORDER BY salary ASC, joining_date DESC) AS worker_rank
FROM worker;
Here’s the output.
Using ROW_NUMBER() to Find the Top N Values
One of the very common uses of ROW_NUMBER() is to create a top list of values, e.g., top-selling products, highest-paid employees, countries with the most/fewest subscribers, etc.
I’ll use the same example as earlier to find the five highest-paid workers. First, I rank them by salary in descending order.
SELECT first_name,
last_name,
salary,
joining_date,
ROW_NUMBER() OVER(ORDER BY salary DESC) AS worker_rank
FROM worker;
How to get the the top five salaries from this? One idea would be to use WHERE with the column worker_rank.
SELECT first_name,
last_name,
salary,
joining_date,
ROW_NUMBER() OVER(ORDER BY salary DESC) AS worker_rank
FROM worker
WHERE worker_rank <=5;
This wouldn’t work. There’s an error that says ‘column "worker_rank" does not exist’ in the WHERE line.
This is because filtering is executed before selecting columns, so the column worker_rank doesn’t exist yet when the WHERE clause is being executed.
I can try to avoid this error by copying the same window function from the worker_rank column to the WHERE clause.
SELECT first_name,
last_name,
salary,
joining_date,
ROW_NUMBER() OVER(ORDER BY salary DESC) AS worker_rank
FROM worker
WHERE ROW_NUMBER() OVER(ORDER BY salary DESC) <=5;
This doesn’t work, either! The error message is self-explanatory: ‘window functions are not allowed in WHERE’.
So, what to do now? The workaround is actually quite simple. Just take the initial code that ranks the users by salary, write it as a subquery, and then use WHERE to find the top five values.
SELECT *
FROM
(SELECT first_name,
last_name,
salary,
joining_date,
ROW_NUMBER() OVER(ORDER BY salary DESC) AS worker_rank
FROM worker) AS ranking
WHERE worker_rank <=5;
The output shows five workers with the highest salaries.
Advanced Applications of SQL ROW_NUMBER()
After going through some elementary applications of SQL ROW_NUMBER() and practicing code writing, I think we’re now ready for the more advanced examples.
ROW_NUMBER() With Aggregate Functions and GROUP BY
Here’s an interview question by Google, which is a great example of how to integrate ROW_NUMBER() with aggregate functions and GROUP BY.
Last Updated: July 2021
Find the email activity rank for each user. Email activity rank is defined by the total number of emails sent. The user with the highest number of emails sent will have a rank of 1, and so on. Output the user, total emails, and their activity rank.
• Order records first by the total emails in descending order. • Then, sort users with the same number of emails in alphabetical order by their username. • In your rankings, return a unique value (i.e., a unique rank) even if multiple users have the same number of emails.
Link to the question: https://platform.stratascratch.com/coding/10351-activity-rank
The question wants you to rank the users by their email activity, i.e., the total number of emails sent. The most active user will be ranked as the first.
The requirement is to return a unique rank, even if multiple users have the same level of activity. This calls for the use of ROW_NUMBER(). There’s an additional request to rank the users by alphabetical order in case there are two or more users with the same number of sent emails.
I use COUNT(*) to find the number of emails sent. In ROW_NUMBER(), I again use the same function, because the first level of ranking is by the number of emails sent descendingly. The second level of ranking is by user in alphabetical order, that’s why I add another column to ORDER BY.
The output is grouped by the from_user column, so all the calculations will be shown on a user level. Finally, I sort the output from the highest to the lowest activity level and by user alphabetically. This is, again, the question’s requirement.
SELECT from_user,
COUNT(*) AS total_emails,
ROW_NUMBER() OVER (ORDER BY COUNT(*) DESC, from_user ASC) AS ranking
FROM google_gmail_emails
GROUP BY from_user
ORDER BY 2 DESC, 1;
Here’s the output.
ROW_NUMBER() With PARTITION BY
Using the optional clause PARTITION BY with ROW_NUMBER() gives even more possibilities and flexibility.
The question by Amazon is a good example of this.
Last Updated: May 2023
You are given a dataset of online transactions, and your task is to identify product codes whose unit prices are greater than the average unit price of sold products.
• The unit price should be the original price (i.e., the minimum unit price for each product code). • The average unit price should be computed based on the unique product codes and their original prices.
Your output should contain productcode and unitprice (the original price).
Link to the question: https://platform.stratascratch.com/coding/2164-stock-codes-with-prices-above-average
The question requires you to find the product code of items whose unit prices are greater than the average unit prices of the product codes sold.
I’ll use CTEs when writing the solution. Here’s the first one. Its purpose is to number the rows of each product code, as the question wants me to base calculations on each product code separately. To achieve this, I partition the data by productcode.
The row numbering is done from the oldest to the latest date. This allows me to identify the first occurrence of each product code, i.e., every product code with the value 1 in the column first_p. This is also necessary to find the product code’s original price, required by the question.
Additionally, I’m including product codes whose quantity is above zero, i.e., a negative value means the product codes have been returned, and the question wants to exclude such products.
WITH products AS
(SELECT productcode,
unitprice,
ROW_NUMBER() OVER(PARTITION BY productcode
ORDER BY invoicedate ASC) AS first_p
FROM online_retails
WHERE quantity > 0),
If I run only this SELECT, this is the output sample.
Let’s now add the second CTE. It references the first CTE and returns only the first occurrences of the product codes.
first_occurrence AS
(SELECT productcode,
unitprice
FROM products
WHERE first_p = 1);
I can now combine the two CTEs into one query and write the final SELECT statement. It references the second CTE, and uses the subquery in the WHERE clause to find the product codes with the unit price above the average unit price.
WITH products AS
(SELECT productcode,
unitprice,
ROW_NUMBER() OVER(PARTITION BY productcode
ORDER BY invoicedate ASC) AS first_p
FROM online_retails
WHERE quantity > 0),
first_occurrence AS
(SELECT productcode,
unitprice
FROM products
WHERE first_p = 1)
SELECT productcode,
unitprice
FROM first_occurrence
WHERE unitprice >
(SELECT AVG(unitprice)
FROM first_occurrence);
Here’s the required output.
Best Practices of Using SQL ROW_NUMBER()
To use SQL ROW_NUMBER() to its full potential, consider the following best practices.
Tips on Using SQL ROW_NUMBER() Effectively and Efficiently
1. Define Clear Ordering Criteria: Always use ROW_NUMBER() with a well-defined ORDER BY clause. This ensures that the numbering is consistent and predictable. This is especially important in PostgreSQL and MySQL, which allow using ROW_NUMBER() without ORDER BY.
2. Use in Conjunction with PARTITION BY: When applicable, combine ROW_NUMBER() with PARTITION BY to create unique numbers within each partition, which is useful for analyzing subsets of data.
3. Understand the Data Context: Be aware of the context in which you're using ROW_NUMBER(). It's particularly effective for ranking, pagination, and deduplication tasks.
4. Balance Need vs. Performance: While ROW_NUMBER() is powerful, consider whether a simpler query could achieve the same goal with better performance.
5. Test Thoroughly: Always test your queries in a development environment to ensure they produce the expected results, especially in complex scenarios involving multiple window functions or large datasets.
Common Pitfalls and How to Avoid Them
The pitfalls of using SQL ROW_NUMBER() are mainly connected to ignoring the above tips.
1. Unpredictable Results Without ORDER BY: Never use ROW_NUMBER() without an ORDER BY clause, as this can lead to non-deterministic results.
2. Overlooking Performance Costs: Be cautious of using ROW_NUMBER() on very large datasets without proper optimization, as it can be resource-intensive.
3. Misunderstanding PARTITION BY: Misusing the PARTITION BY clause can lead to incorrect numbering or inefficient query execution. Ensure the partitioning is relevant to your analytical needs.
4. Ignoring Index Usage: Neglecting the impact of indexes on columns involved in the ORDER BY and PARTITION BY clauses can degrade performance.
5. Data Modification Side Effects: Be aware that using ROW_NUMBER() in data modification queries (like UPDATE) can be tricky and may not always work as expected.
Performance Implications and Optimization Strategies
1. Optimize Indexing: Index the columns used in the ORDER BY and PARTITION BY clauses to speed up the sorting and partitioning process.
2. Minimize Row Processing: Apply filters (using the WHERE clauses) before ROW_NUMBER() to reduce the number of rows processed.
3. Smart Partitioning: Use PARTITION BY judiciously. Unnecessary or overly granular partitioning can negatively impact query performance.
4. Limit Result Set: When dealing with large datasets, try to limit the result set (using WHERE, TOP, or LIMIT) before applying ROW_NUMBER().
5. Use Appropriate Hardware Resources: Ensure that the database server has sufficient memory and CPU resources to handle complex queries, especially those involving large datasets and multiple window functions.
6. Analyze Execution Plans: Regularly review query execution plans to identify and address potential performance bottlenecks.
7. Stay Informed on Database-Specific Optimizations: Different SQL databases might offer specific optimizations for window functions like ROW_NUMBER(). Stay updated with the latest documentation and best practices for your particular database system.
Differences Across SQL Databases
Regarding the ROW_NUMBER() syntax in different databases, it’s the same basic syntax I showed in this article in all four most popular databases.
Except this: PostgreSQL and MySQL allow ROW_NUMBER() without ORDER BY, while ORDER BY is mandatory in MS SQL Server and Oracle.
But if you’re always using ORDER BY (which is highly advisable!), there are no differences for you from the point of writing a code, no matter what database system you use. Yet, there are some other behind-the-scenes differences.
1. PostgreSQL
- Performance: PostgreSQL generally handles ROW_NUMBER() efficiently, especially with proper indexing. It also supports parallel query processing, which can improve performance on large datasets.
- Integration With Advanced Features: PostgreSQL offers robust support for window functions, including ROW_NUMBER(), and integrates well with other advanced features like CTEs and various JOIN types.
- Partitioning and Ordering: PostgreSQL's ROW_NUMBER() works seamlessly with its advanced partitioning capabilities, providing efficient data organization and retrieval.
2. MySQL
- Feature Availability: MySQL introduced window functions, including ROW_NUMBER(), in version 8.0. Earlier versions do not support this function natively.
- Performance Aspects: While MySQL supports ROW_NUMBER(), its performance optimization, especially for large datasets, may not be as advanced as some other databases.
- Capabilities: MySQL's implementation of ROW_NUMBER() may lack some of the more advanced capabilities seen in other systems.
3. MS SQL Server
- Efficient Execution: SQL Server is known for its efficient execution of window functions, including ROW_NUMBER(). It often provides good performance out of the box, especially when indexes are used effectively.
- Integration with SQL Server Features: ROW_NUMBER() in SQL Server works well with its T-SQL extensions and is commonly used in tandem with CTEs for complex data manipulation tasks.
- Scalability: SQL Server handles ROW_NUMBER() well in large-scale databases, making it suitable for enterprise-level applications.
4. Oracle
- Optimization and Performance: Oracle Database typically offers strong performance with ROW_NUMBER(), thanks to its sophisticated optimizer and ability to handle complex queries efficiently.
- Advanced SQL Features: Oracle's implementation of ROW_NUMBER() is robust, supporting a wide range of advanced SQL features and offering specific optimizations through hints and directives.
- Handling of Large Datasets: Oracle excels in managing large datasets, and the use of ROW_NUMBER() in such environments is generally very efficient, particularly with proper indexing and partitioning.
Conclusion
After reading this article, you should be able to leverage SQL ROW_NUMBER()function in your data manipulation and analysis work. I totally encourage that!
Now you know how window functions and, specifically, ROW_NUMBER() works. I introduced you to its syntax, elementary, and more complex uses, as well as differences from the other two raking window functions: RANK() and DENSE_RANK().
I sprinkled several interview questions from our platform that are a good showcase for the SQL ROW_NUMBER() use. There are many more questions where you can practice ROW_NUMBER(), window functions in general, and other concepts for the SQL interview questions.
Share


