MS SQL Interview Questions That Will Challenge Your Skills


Categories:
 Written by:
Written by:Nathan Rosidi
Solving actual MS SQL interview questions is the best way of preparing for a technical interview. Here’s a detailed guide on how to challenge your skills.
You heard about Microsoft SQL Server, right? Who hasn’t heard about one of the most popular databases? If you haven’t, you probably lived under the stone for the last, erm, ten years? I’ll turn that stone with this article and show you why Microsoft SQL Server (MS SQL) – a cornerstone of modern database management – is a critical skill for data professionals.
I’ll also aim to help prepare candidates for MS SQL interviews by exploring key concepts, presenting a range of interview questions from beginner to advanced levels, and offering tips to excel in these interviews.
Understanding MS SQL and Its Importance
MS SQL is a relational database management system (RDBMS) developed by Microsoft in 1989. Currently, it’s the third most popular RDBMS in the world.


But its popularity goes further than November 2023. It was the third most popular database the month before and the year before. In fact, if you look at the graph below, you can see that MS SQL has been among the three most popular databases consistently for the last ten years.

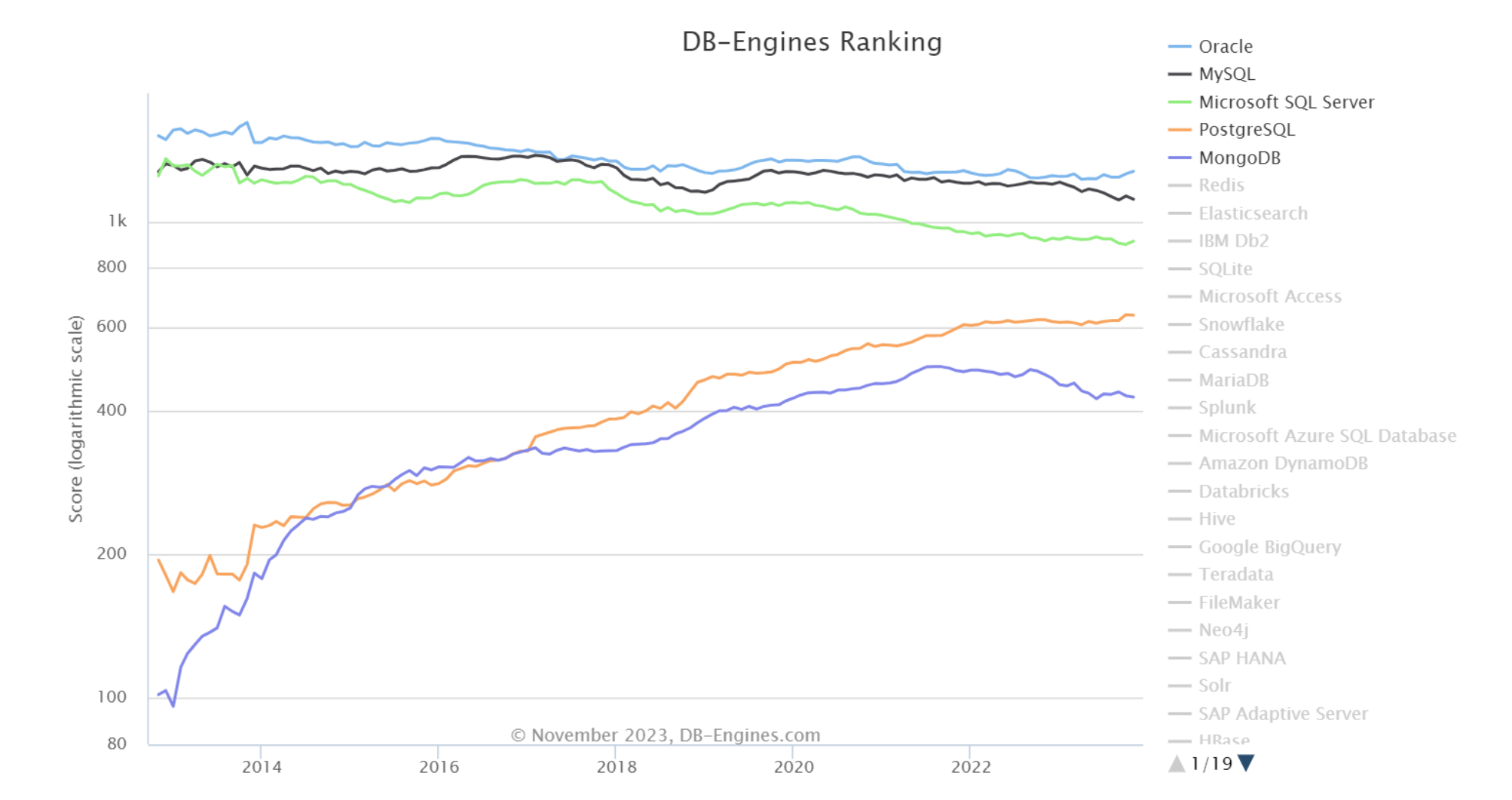
No doubt it’s popular, but what features make it so widely used?
Overview and Role of MS SQL in Businesses and IT
MS SQL’s role extends far beyond mere data storage; it drives decision-making, operational efficiency, and strategic planning across diverse companies and industries.

All these features make MS SQL extremely popular when it comes to putting together data into a coherent, manageable form.
Key Concepts and Components of MS SQL
Understanding MS SQL's key concepts and components is crucial for effectively utilizing its capabilities. I won’t go into too much detail; in that case, it would be best to just link to MS SQL technical documentation.
You can read the details there, and I got you covered with an overview of the main concepts.


Basic SQL Commands
One of the important MS SQL concepts I mentioned above is T-SQL, which is Microsoft’s SQL dialect (or flavor) used in MS SQL.
The most commonly used commands in T-SQL belong to two categories.
1. Data Definition Language (DDL)
DDL commands are used to define and modify the database structure or schema. They are used for creating, altering, and dropping database objects like tables, indexes, and views. These commands are:
- CREATE – For creating new database objects; for example, a new table.
- ALTER – For modifying an existing database object; for example, add, delete, or modify columns in an existing table.
- DROP – For deleting objects from the database; for example, remove a table and all data stored in it.
- RENAME �– For renaming a table.
- TRUNCATE TABLE – For removing all records from a table.
2. Data Manipulation Language (DML)
DML commands are used for managing data within database objects, like tables. These include:
- SELECT – For querying data from a database; for example, retrieving data from one or more tables.
- INSERT – For inserting data into a table.
- UPDATE – For modifying existing data within a table.
- DELETE – For removing data from the table.
The command you’ll use most often is SELECT. For the list of all T-SQL statements, go here.
MS SQL Interview Questions
After all these technicalities, we can now look into MS SQL interview questions. I’ll divide them into beginner, intermediate, and advanced-level questions.
The technical interviews mainly revolve around the coding questions. However, you could also be asked some technical non-coding questions, so I’ll cover these, too.
Beginner-Level MS SQL Interview Questions
Non-Coding MS SQL Interview Question #1: WHERE and HAVING
This question by Spotify wants you to explain the difference between WHERE and HAVING clauses in SQL.
Last Updated: May 2022
What is the main difference between a WHERE clause and a HAVING clause in SQL?
Link to the question: https://platform.stratascratch.com/technical/2374-where-and-having
Answer: Both WHERE and HAVING are used for filtering data in SQL. The main difference is that WHERE filters data before data grouping and aggregation, so the SQL aggregate functions can’t be used in it.
Meanwhile, with HAVING, data is filtered after grouping and aggregation. Due to its purpose, HAVING takes aggregate functions as filtering conditions.
Non-Coding MS SQL Interview Question #2: Left Join and Right Join
This question by Credit Acceptance asks you to show your understanding of the difference between LEFT JOIN and RIGHT JOIN.
Last Updated: March 2021
What is the difference between a left join and a right join in SQL?
Link to the question: https://platform.stratascratch.com/technical/2242-left-join-and-right-join
Answer: With a LEFT JOIN, all of the rows from the left table will be returned, and the missing values from the right table will be filled with NULL values.


Meanwhile, a RIGHT JOIN is the opposite of a LEFT JOIN, where all the rows from the right table will be returned, and the missing values from the left table will be filled with NULL values.

Coding MS SQL Interview Question #1: Finding Doctors
The question by Google is one of the examples where you have to show a basic understanding of the SELECT statement and filtering data using WHERE.
Last Updated: May 2023
Find doctors with the last name of 'Johnson' in the employee list. The output should contain both their first and last names.
Link to the question: https://platform.stratascratch.com/coding/10356-finding-doctors?code_type=5
Dataset: You need to query the employee_list table.
Answer and Explanation: Your output should show the first and last names of doctors whose last name is ‘Johnson’.
First, you need to specify the columns in SELECT that you want to output. In this case, these are first_name and last_name.
Then, reference the table employee_list in the FROM clause. This will return all employees, so you need to filter data.
You do that using the WHERE clause. The first filtering condition is that the last name is ‘Johnson’. To add the second condition that needs to be simultaneously met, you need the keyword AND. After that, you simply write the second condition: the employee’s profession needs to be ‘Doctor’.
SELECT first_name,
last_name
FROM employee_list
WHERE last_name = 'Johnson' AND profession = 'Doctor';
Run the above query, and you’ll get a list of all doctors whose surname is Johnson.
Coding MS SQL Interview Question #2: Finding Updated Records
Here’s a question by Microsoft where you need to find each employee's current salary. You’ll need to show you know how to group, aggregate, and sort data to solve it.
Last Updated: November 2020
We have a table with employees and their salaries, however, some of the records are old and contain outdated salary information. Find the current salary of each employee assuming that salaries increase each year. Output their id, first name, last name, department ID, and current salary. Order your list by employee ID in ascending order.
Link to the question: https://platform.stratascratch.com/coding/10299-finding-updated-records?code_type=5
Dataset: The question gives the table ms_employee_salary.
Answer and Explanation: Start by selecting the necessary columns from the table ms_employee_salary. These are id, first_name, last_name, and department_id.
Now, the question wants you to find the current salary of each employee. It also gives you an info that the salaries increase each year. This hints that every employee’s current salary equals their highest salary. To find these, you need to use the aggregate function, namely MAX(). It returns the highest value.
After referencing the table in FROM, you can group data. To show each employee's current (or maximum) salary, you need to group data by all columns in SELECT, except the one with the aggregate function in it. That’s because all the columns appearing in SELECT must also be in GROUP BY. The aggregated column isn’t allowed in GROUP BY.
Finally, you need to sort the output. You do that using the ORDER BY clause. The list needs to be sorted in ascending order, i.e., from the lowest to the highest employee ID. You achieve this by writing the keyword ASC (ascending) after the column you want to sort by.
SELECT id,
first_name,
last_name,
department_id,
MAX (salary) AS current_salary
FROM ms_employee_salary
GROUP BY id,
first_name,
last_name,
department_id
ORDER BY id ASC;
Here’s the snapshot of the output you get by running the code above.
Intermediate-Level MS SQL Interview Questions
After warming you up with the beginner-level MS SQL interview questions, I think you are now ready to go to little more complex interview questions.
Non-Coding MS SQL Interview Question #1: Table Joins
In answering this question by Deloitte, you need to show your understanding of the Cartesian product and OUTER JOIN.
Link to the question: https://platform.stratascratch.com/technical/2387-table-joins
Answer: Cartesian product is a table where each row of the left table joins with each row of the right table, making all possible ordered pairs. This is illustrated in the image below.

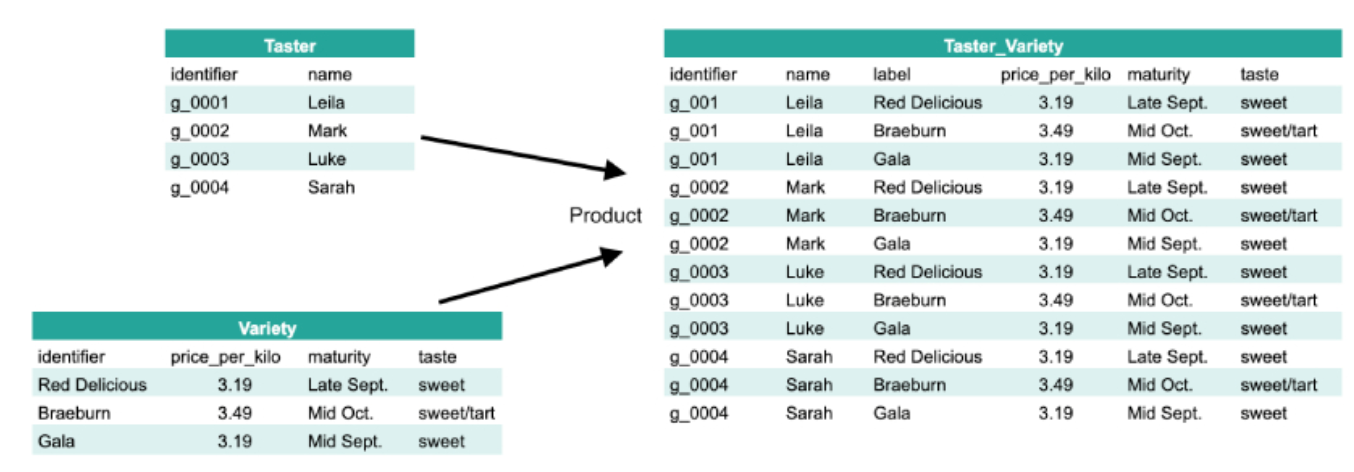
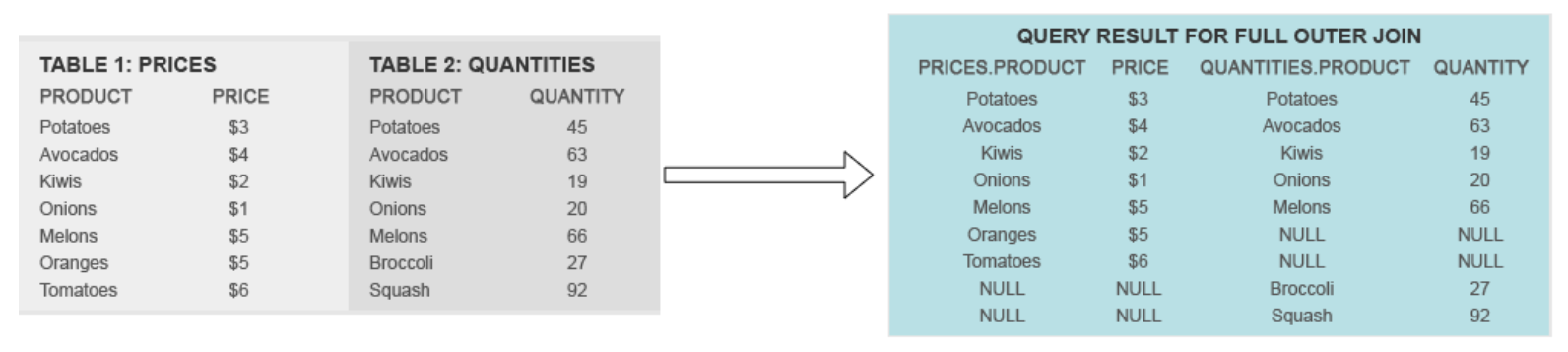
Outer join returns all the rows from both tables. When matching rows exist for the right and the left table, they are merged. When no matching rows exist for the row in the left table, the columns of the right table are null padded. Similarly, when no matching rows exist for the row in the right table, the columns of the left table are null padded.
This is shown here.

Non-Coding MS SQL Interview Question #2: Union Versus Union All
Answering this question by Meta will show your understanding of UNION and UNION ALL and their performance.
Last Updated: June 2022
What is the difference in query performance between using UNION versus UNION ALL in SQL?
Link to the question: https://platform.stratascratch.com/technical/2384-union-versus-union-all
Answer: UNION and UNION ALL are members of the set operators in SQL. They combine the results of two or more queries into a single result.
UNION does that by returning only the unique records. UNION ALL returns all records from all queries, including duplicates.
Because of its characteristics, UNION ALL executes faster as it simply merges all the results. UNION has to go through each record, determine whether it’s a duplicate or not, and return the output based on that.
Coding MS SQL Interview Question #1: Favorite Customer
Here’s a popular question asked at eBay, Spotify, and Amazon interviews. It tests your knowledge of SQL JOINs, data aggregation, grouping, and filtering using HAVING.
Last Updated: May 2019
Find "favorite" customers based on the order count and the total cost of orders. A customer is considered as a favorite if he or she has placed more than 3 orders and with the total cost of orders more than $100.
Output the customer's first name, city, number of orders, and total cost of orders.
Link to the question: https://platform.stratascratch.com/coding/9910-favorite-customer?code_type=5
Dataset: You will be working with two tables to solve the question.
The first table is customers, which shows the list of customers.
The second table is orders, which shows details about each individual order.
Answer and Explanation: I’ll start by explaining the JOIN part, and then I’ll build the query around it.
So, the question asks you to output the customer’s first name, city, number of orders, and total cost of orders. To get this data, you’ll need to join the tables.
Start by writing SELECT and then referencing the first table in FROM. This is table customers, in our case, and we give it an alias ‘c’, so we won’t have to write the table’s full name later on.
Then, use INNER JOIN, just in case some customers haven’t placed any orders yet. In it, you need to reference the table orders and give it an alias ‘o’.
After that, state the joining condition using ON. The tables are joined on a shared column. In this case, these are columns id and cust_id.
SELECT
FROM customers c
INNER JOIN orders o ON c.id = o.cust_id;
Now, we can add columns to the SELECT statement. We first select the first name and city required by the question.
Then, we need to calculate the number of orders, which we do with the COUNT() aggregate function. The last column is the total cost of all orders, which we calculate using SUM().
To get these calculations by customer, we group the output by first name, city, and, additionally, by ID.
SELECT c.first_name,
c.city,
COUNT(o.id) AS order_count,
SUM(total_order_cost) AS total_cost
FROM customers c
INNER JOIN orders o ON c.id = o.cust_id
GROUP BY c.first_name, c.city, c.id;
The final step is to filter the output to show customers with more than 3 orders and the total cost of orders above $100. The filtering has to be done after the aggregation, so we use HAVING. The rest is easy: we just copy the two calculation columns and set the criteria using the operator ‘greater than’ (>). Since both criteria have to be met, we use the keyword AND between them.
SELECT c.first_name,
c.city,
COUNT(o.id) AS order_count,
SUM(total_order_cost) AS total_cost
FROM customers c
INNER JOIN orders o ON c.id = o.cust_id
GROUP BY c.first_name, c.city, c.id
HAVING SUM(total_order_cost) > 100
AND COUNT(o.id) > 3;
The output shows three customers that satisfy all the criteria.
Coding MS SQL Interview Question #2: World Tours
The next question is by Expedia, Amadeus, and Google. You need to find how many travelers ended up back in their home city. This MS SQL interview question requires you to know aggregation, grouping, joins, and filtering data. However, the main focus is on the common table expressions (CTEs).
Last Updated: March 2022
A group of travelers embark on world tours starting with their home cities. Each traveler has an undecided itinerary that evolves over the course of the tour. Some travelers decide to abruptly end their journey mid-travel and live in their last destination. Given the dataset of dates on which they travelled between different pairs of cities, can you find out how many travellers ended back in their home city? For simplicity, you can assume that each traveler made at most one trip between two cities in a day.
Link to the question: https://platform.stratascratch.com/coding/2098-world-tours?code_type=5
Dataset: The question provides you with the table travel_history.
Answer and Explanation: Let’s break down the solution into several CTEs. They are basically subqueries written more systematically and clearly.
Regarding the CTE syntax, you start by writing the keyword WITH and naming the CTE. In our case, the first CTE is called start_end_dates. The name is followed by the keyword AS, and then you write a regular SELECT statement in the parentheses. This first CTE will show the tour’s start and end dates by a traveler.
The start date is the earliest date, which we find using MIN(). Conversely, the end date is the latest date, so we use MAX() to find it and group the output by the traveler.
WITH start_end_dates AS (
SELECT traveler,
MIN(date) AS start_date,
MAX(date) AS end_date
FROM travel_history
GROUP BY traveler
)
The output of this CTE is shown below.
Now, we need to add another CTE, which is simple. Write the second CTE’s name (without the WITH keyword), add AS, and then write the SELECT statement in parentheses. You also need to separate the two CTEs with a comma.
This second CTE joins the travel_history table with the first CTE on the traveler column and where the date equals the start date.
WITH start_end_dates AS (
SELECT traveler,
MIN(date) AS start_date,
MAX(date) AS end_date
FROM travel_history
GROUP BY traveler
),
start_cities AS (
SELECT h.traveler,
start_city
FROM travel_history h
JOIN start_end_dates d ON h.traveler=d.traveler
AND date=start_date
);
By selecting the traveler and start city, this CTE will show us the list of travelers from the first CTE and their start cities.
Let’s now add the third CTE the same as we did the second one. This one’s name end_cities. It’s almost the same as the previous one. The only difference is that it shows the end cities, so the second joining condition is where the date equals the end date.
WITH start_end_dates AS (
SELECT traveler,
MIN(date) AS start_date,
MAX(date) AS end_date
FROM travel_history
GROUP BY traveler
),
start_cities AS (
SELECT h.traveler,
start_city
FROM travel_history h
JOIN start_end_dates d ON h.traveler=d.traveler
AND date=start_date
),
end_cities AS (
SELECT h.traveler,
end_city
FROM travel_history h
JOIN start_end_dates d ON h.traveler=d.traveler
AND h.date=end_date
);
With this CTE, we now also have the list of travelers and their end cities.
As a final step, we need to add the main query and join the second and third CTE. Then, we simply use COUNT(*) to count the number of travelers and apply the filter in WHERE, so the output shows those travelers whose start city is the same as the end city. In other words, they returned to their home city.
WITH start_end_dates AS (
SELECT traveler,
MIN(date) AS start_date,
MAX(date) AS end_date
FROM travel_history
GROUP BY traveler
),
start_cities AS (
SELECT h.traveler,
start_city
FROM travel_history h
JOIN start_end_dates d ON h.traveler=d.traveler
AND date=start_date
),
end_cities AS (
SELECT h.traveler,
end_city
FROM travel_history h
JOIN start_end_dates d ON h.traveler=d.traveler
AND h.date=end_date
)
SELECT COUNT(*) AS n_travelers_returned
FROM start_cities s
JOIN end_cities e ON s.traveler=e.traveler
WHERE start_city = end_city;
The code returns the number of travelers that satisfy all the requirements.
Advanced-Level MS SQL Interview Questions
Gradually, we’ve come to the questions where you have to show an advanced level of SQL knowledge. The advanced-level questions can involve all the previous concepts but in the context of more complex problems.
At this level, you can also expect to see SQL CASE WHEN, SQL window functions, recursive queries, and the use of various functions, including the string functions.
Here are the many examples of advanced SQL interview questions you can use for practice.
Non-Coding MS SQL Interview Question #1: SUBSTRING() Versus CHARINDEX()
You can find this question on Guru99. It asks: “What is the difference between SUBSTRING and CHARINDEX in the SQL Server?”.
Answer: The SUBSTRING() function returns a part of the string (substring) within a given string.
For example:
SELECT SUBSTRING('SQL Server', 1, 3)
This expression will search the substring ‘SQL Server’ from the first letter (specified as 1) on the left, and will return three characters (defined as 3). In other words, the output is ‘SQL’.
On the other hand, CHARINDEX() returns the position of a specified character within a string.
For example:
SELECT CHARINDEX('Q', 'SQL Server')
The above query looks for the letter ‘Q’ in the string ‘SQL Server’. The output is 2, as this letter is found in the second position from the left.
Non-Coding MS SQL Interview Question #2: RANK() Versus DENSE_RANK()
This question from LearnSQL.com asks: “What’s the Difference Between RANK() and DENSE_RANK()?”
Answer: Both RANK() and DENSE_RANK() belong to the family of ranking window functions.
RANK() will rank data, but will assign the same rank to rows with the same values. The next rank of the non-tie values will be skipped, so the ranking is not sequential. Here’s the illustration of ranking in descending order with RANK().

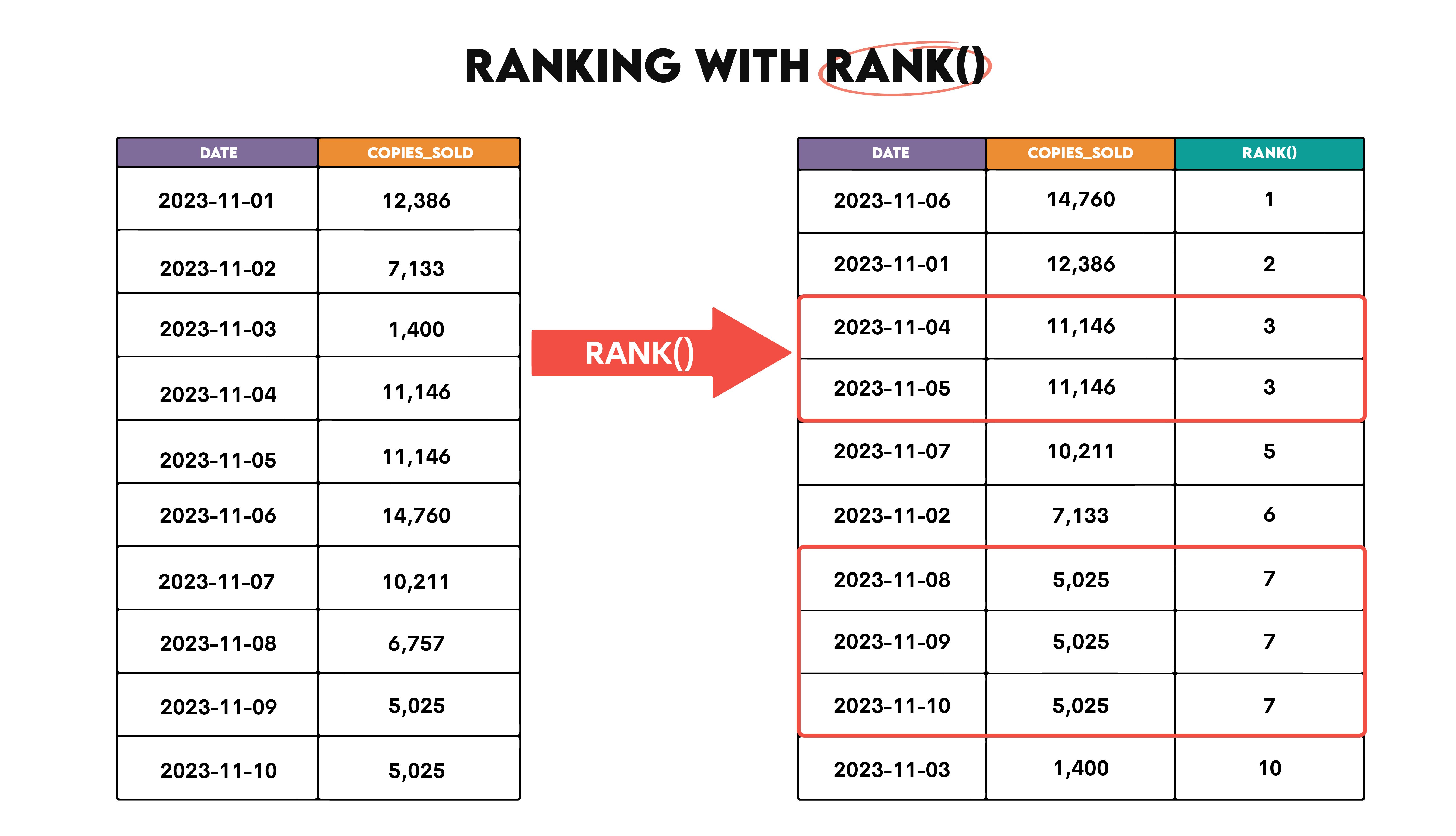
The first highlighted rows are both ranked third. The next row is not ranked fourth, so the one rank is skipped.
The second highlighted area consists of three rows ranked as the seventh, as they all have the same number of copies sold. The following row is ranked tenth, i.e., two ranks are skipped.
SQL DENSE_RANK() also ranks the rows with the same values the same. But, the next non-tie row rank will not be skipped, i.e., the ranking is sequential. Again, the same illustration, but now with an added dense_rank() column.

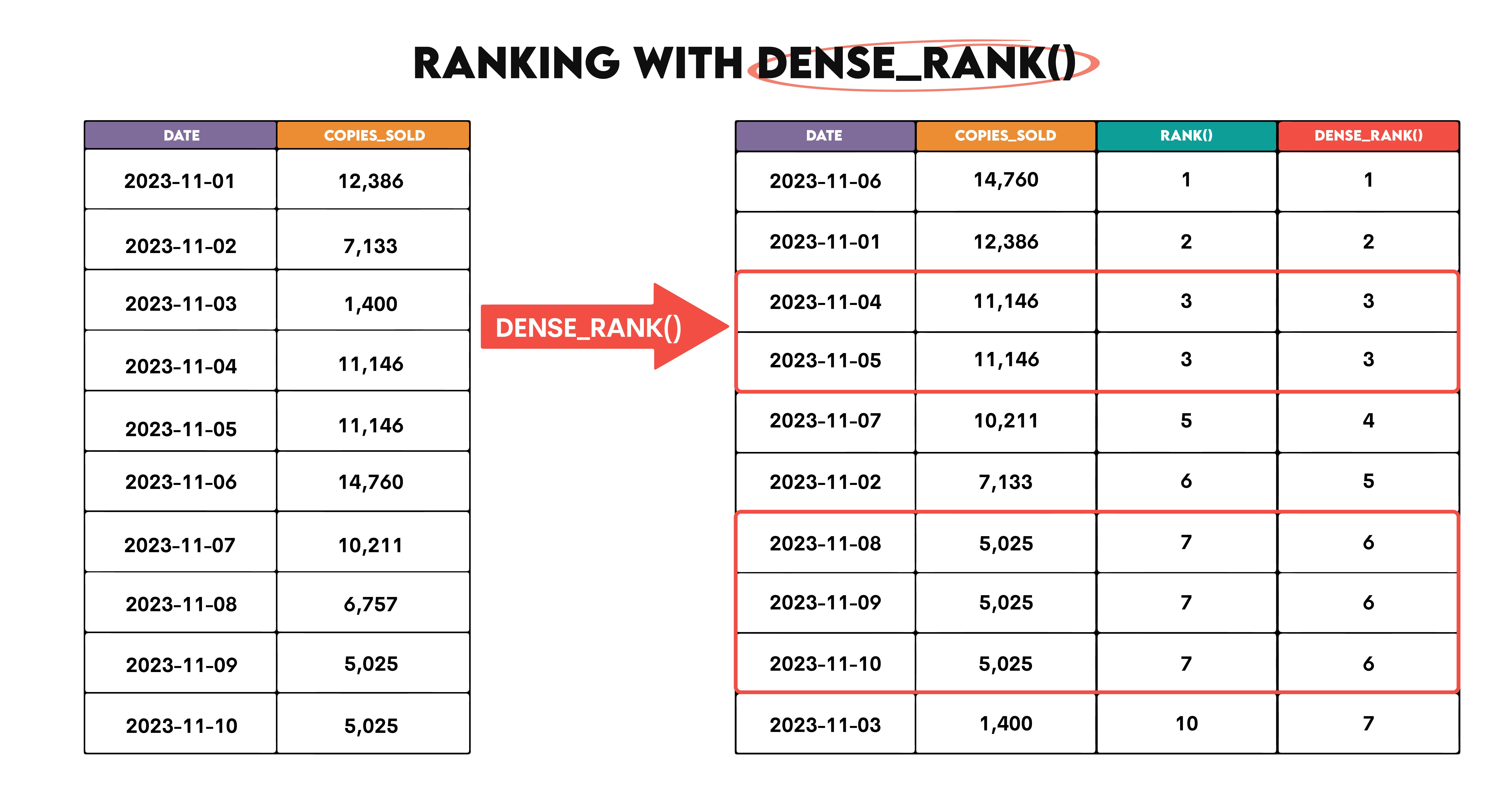
Now, the first highlighted area is ranked third, the same as with RANK(). However, the next row gets the fourth rank, not the fifth, as DENSE_RANK() doesn’t skip ranks.
In the second highlighted area, three tied rows are ranked sixth, while with RANK(), the rank was seventh. Of course, the next ranking with DENSE_RANK() is not skipped, so it’s seventh instead of tenth.
Coding MS SQL Interview Question #1: 3rd Most Reported Health Issues
This question by the City of Los Angeles wants you to find the names of the restaurants with the 3rd most common health issue category.
Last Updated: April 2018
Each record in the table represents a reported health issue, with each issue classified based on facility type and risk score, which are combined in the pe_description column.
Filter the dataset to include only businesses whose names contain "Cafe", "Tea", or "Juice", then identify the "facility type - risk score" classification that ranks 3rd in frequency. If multiple classifications are tied for 3rd place, include all of them.
Finally, return the names of the businesses that belong to the identified classification(s).
Link to the question: https://platform.stratascratch.com/coding/9701-3rd-most-reported-health-issues?code_type=5
Dataset: The question provides you with the table los_angeles_restaurant_health_inspections.
Answer and Explanation: To solve this question, you’ll need to be knowledgeable about CTEs, aggregation, filtering data, subqueries, string operations, and window functions.
The first CTE shows the risk score (column pe_description) and counts the number of records for each risk score using the COUNT() function. To get the required output, we also need to filter it. The question asks to show only businesses with Cafe, Tea, or Juice in the name. We’ll set these conditions in WHERE using the LIKE operator and the keywords with a wildcard (%). Doing this will look for the keywords anywhere in the business name.
To get the number of businesses with the same risk score, we need to group by pe_description.
WITH counts AS (
SELECT pe_description,
COUNT(record_id) AS record_count
FROM los_angeles_restaurant_health_inspections
WHERE facility_name LIKE '%tea%'
OR facility_name LIKE '%cafe%'
OR facility_name LIKE '%juice%'
GROUP BY pe_description
);
The output of this CTE is a list of distinct risk categories and number of businesses within each category.
Now we add another CTE. It references the previous CTE and uses DENSE_RANK() to rank the risk category by the number of businesses. The OVER clause is a mandatory clause that creates a window function. In this clause, we use ORDER BY to specify the column by which we want to rank. In this case, it’s record_count from the previous CTE. Data is ranked descendingly by adding the keyword DESC.
WITH counts AS (
SELECT pe_description,
COUNT(record_id) AS record_count
FROM los_angeles_restaurant_health_inspections
WHERE facility_name LIKE '%tea%'
OR facility_name LIKE '%cafe%'
OR facility_name LIKE '%juice%'
GROUP BY pe_description
),
ranks AS (
SELECT pe_description,
DENSE_RANK() OVER(ORDER BY record_count DESC) AS category_rank
FROM counts
);
The categories are now nicely ranked.
We can now write the rest of the solution. The last SELECT statement selects the facility name from the original table.
Next, we have to filter data. The first condition is to show only businesses with the third most common risk category. So, we have to find which risk category is ranked as third. We use the subquery in WHERE and compare its output with the column pe_description using the IN operator. This subquery references the second CTE and returns the third most common risk category.
We add the second condition. This one goes through values in the facility_name column and returns only those with cafe, tea, and juice in their names. This is the same filtering we did in the first CTE.
WITH counts AS (
SELECT pe_description,
COUNT(record_id) AS record_count
FROM los_angeles_restaurant_health_inspections
WHERE facility_name LIKE '%tea%'
OR facility_name LIKE '%cafe%'
OR facility_name LIKE '%juice%'
GROUP BY pe_description
),
ranks AS (
SELECT pe_description,
DENSE_RANK() OVER(ORDER BY record_count DESC) AS category_rank
FROM counts
)
SELECT facility_name
FROM los_angeles_restaurant_health_inspections
WHERE pe_description IN
(SELECT pe_description
FROM ranks
WHERE category_rank = 3)
AND ((facility_name LIKE '%tea%'
OR facility_name LIKE '%cafe%'
OR facility_name LIKE '%juice%'));
The solution shows four businesses that meet all the requirements.
Coding MS SQL Interview Question #2: Common Letters
This interview question by Google wants you to find the top 3 most common letters across all the words from the tables.
Last Updated: February 2019
Find the top 3 most common letters across all the words from both the tables (ignore filename column). Output the letter along with the number of occurrences and order records in descending order based on the number of occurrences.
Link to the question: https://platform.stratascratch.com/coding/9823-common-letters/official-solution?code_type=5
Dataset: You’ve got two tables. The first table is google_file_store. It’s a list of files, and that also shows their content.
The second table is google_word_lists.
Answer and Explanation: To write the solution, you have to know CTEs and recursion, UNION ALL, filtering, working with strings, and some other MS SQL functions.
So, let’s start by merging all the words in one dataset. We’ll do that in a CTE using UNION ALL. We select the contents from the table google_file_store. Then, we unionize this with the query that selects the column words1 from the table google_word_lists. Then, we again use UNION ALL for the third query, which selects the column words2 from the same table as earlier.
WITH combinedCTE AS (
SELECT contents AS word
FROM google_file_store
UNION ALL
SELECT words1 AS word
FROM google_word_lists
UNION ALL
SELECT words2
FROM google_word_lists
);
This query now shows all the content and words in one dataset.
The next CTE is a recursive query. It’s a query that returns one result, then it repeatedly references itself and stops executing once it returns all the results. We add it like regular CTE: write its name and separate it from the previous CTE with a comma.
The first SELECT in the recursive query is called the anchor member. It starts counting from 1 and selects the column word from the first CTE. It also uses SUBSTRING() to find the first letter of every string in the column word.
This SELECT will show the position of a letter (in this case, it’s only the first letter), the string, and the string's first character.
WITH combinedCTE AS (
SELECT contents AS word
FROM google_file_store
UNION ALL
SELECT words1 AS word
FROM google_word_lists
UNION ALL
SELECT words2
FROM google_word_lists
),
recursiveCTE AS (
SELECT 1 AS character_position,
word,
SUBSTRING(word, 1, 1) AS character
FROM combinedCTE
);
We continue working on a SQL recursive CTE. Now, we need to use UNION ALL to add the recursive member. It references the anchor member. For each selected word it increases the count by 1. Also, the second argument in SUBSTRING() adds one to the initial count to the starting position of a letter search within a substring.
The LEN() function is used to limit the number of recursive calls. The query needs to keep going only until the initial count (or the position of the letter) is lower than the total length of the string. This means that the query will extract each character of the string in subsequent rows of the CTE.
The query we’ve written so far returns the position of each letter, the letter itself, and the whole string where this letter can be found at the specified position.
WITH combinedCTE AS (
SELECT contents AS word
FROM google_file_store
UNION ALL
SELECT words1 AS word
FROM google_word_lists
UNION ALL
SELECT words2
FROM google_word_lists
),
recursiveCTE AS (
SELECT 1 AS character_position,
word,
SUBSTRING(word, 1, 1) AS character
FROM combinedCTE
UNION ALL
SELECT (r.character_position + 1) AS character_position,
word,
SUBSTRING(word, r.character_position + 1, 1) AS character
FROM recursiveCTE AS r
WHERE r.character_position < LEN(word)
);
Let’s now add the final touch with the SELECT that useS the recursive query output. It selects the top 3 most common letters and the number of their occurrences using the COUNT() function.
We also need to apply some filters in WHERE. The first one excludes the NULL values. The second one excludes the whitespaces.
Next, we group the output by the character and sort it by the number of occurrences in descending order.
As a final step, we use the OPTION() function to allow for an unlimited number of recursions in the CTE. This is because MS SQL automatically limits the number of recursions to 100, which is not enough to go through our complete dataset.
WITH combinedCTE AS (
SELECT contents AS word
FROM google_file_store
UNION ALL
SELECT words1 AS word
FROM google_word_lists
UNION ALL
SELECT words2
FROM google_word_lists
),
recursiveCTE AS (
SELECT 1 AS character_position,
word,
SUBSTRING(word, 1, 1) AS character
FROM combinedCTE
UNION ALL
SELECT (r.character_position + 1) AS character_position,
word,
SUBSTRING(word, r.character_position + 1, 1) AS character
FROM recursiveCTE AS r
WHERE r.character_position < LEN(word)
)
SELECT TOP 3 character,
COUNT(1) AS n_occurences
FROM recursiveCTE
WHERE character IS NOT NULL
AND character != ' '
GROUP BY character
ORDER BY n_occurences DESC
OPTION (MAXRECURSION 0);
Tips and Strategies to Excel in MS SQL Interviews
You’re now ready to go on your own and find your way of getting prepared for MS SQL interview. Here are also some tips that will help you with this.
1. Understand the Basics: Solidify your understanding of the fundamental concepts I mentioned in the dedicated section. Also, ensure you know how to use basic SQL statements and keywords. After you fill potential holes in your knowledge, your transition to intermediate and advanced MS SQL coding will be easier.
2. Practical Experience: Without this, don’t consider interviewing for a position requiring MS SQL knowledge. The best way to gain experience is if your current job requires you to use MS SQL. The other option is to get this experience through extensive practice in solving interview questions. By doing this, you’ll work with actual datasets.
3. Problem-Solving Approach: Connected with the previous point. Practicing real interview questions puts you in a position to solve the business problems you’ll encounter in your job. You have to understand the business problem, connect it with the SQL concepts, and translate it into an efficient and working code.
4. Keep Updated: Stay informed about the latest MS SQL Server updates and features.
5. Communication Skills: Clearly articulate your thought process and solutions. Even if you don’t solve the problem or make a mistake along the way, leading the interviewer through every step of the code and your reasoning for a certain approach will get you points. It’s not only important to write a working code but also to explain why you wrote such a code. Good communication is key in technical interviews.
Conclusion
Preparing for an MS SQL interview requires a blend of theoretical knowledge and practical experience. Depending on the position you apply for, the knowledge required from you will be basic, intermediate, or advanced.
If you’re just starting with MS SQL, ensure your foundations are strong, and don’t skip the basics. Then, slowly move to the more advanced topics. Even though theoretical knowledge is essential, you should focus on solving real-world problems by writing SQL code.
The single most important advice I can give you is to practice, practice, and practice! Solving as many SQL interview questions as possible will take you a long way.
Share


