Machine Learning Engineer Interview Questions


Categories:
 Written by:
Written by:Nathan Rosidi
Are you a machine learning engineer looking for a new job? Find out what kind of questions major tech companies ask the candidates for this very position!
Machine learning engineers can be thought of as specialized data scientists whose main task is to prepare models for deployment. In many cases, their goal is to predict values or labels given a large dataset. This may have an application in finances, medicine, meteorology, and countless other areas. Other tasks that machine learning engineers may expect to work on include creating intelligent recommendation systems or performing clustering on sets of unlabeled data.
Because of this heavy focus on machine learning models in their everyday work, the questions that the machine learning engineers are asked at technical interviews are different from other data-related positions and concern modeling a lot. Nevertheless, the candidates for this position should expect both simple coding tasks, usually to be solved using Python, R, or SQL, as well as purely theoretical questions. The latter regard typically the basics of the machine learning discipline, the definitions of well-known models or evaluation methods, but may also be about probability or statistics. Meanwhile, the coding challenges are not particularly complicated as they are meant to be solved within a couple of minutes and often concern performing an estimation based on a few simple rules.
Machine Learning Engineer Coding Interview Questions

Machine Learning Engineer Interview Question #1: Recommendation System

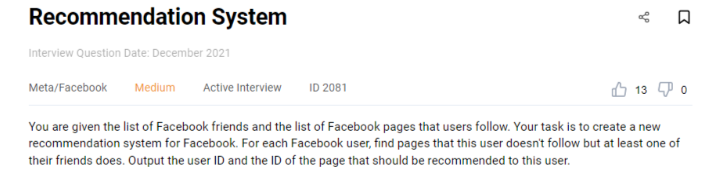
This machine learning engineer interview question has recently been asked during technical interviews at Meta and is a perfect example of what machine learning engineers may expect to solve. The candidate is given a list of Facebook friends and the list of Facebook pages that users follow. The task is to create a new recommendation system for Facebook. For each Facebook user, we should find pages that this user doesn't follow, but at least one of their friends does. The output should include the user ID and the page ID that should be recommended to this user.
Link to the question: https://platform.stratascratch.com/coding/2081-recommendation-system
As mentioned in the text of the question, to solve this problem, we should use two relatively simple datasets:
- users_friends has two columns (user_id and friend_id) and is a list of Facebook friends,
- users_pages also has two columns (user_id and page_id) and is a list of Facebook pages that users follow
user_friends
| user_id: | int64 |
| friend_id: | int64 |
user_pages
| user_id: | int64 |
| page_id: | int64 |
This is what the top rows of the users_friends dataset may look like. The first row, for instance, means that a user with ID 1 is a friend of a user with ID 2.

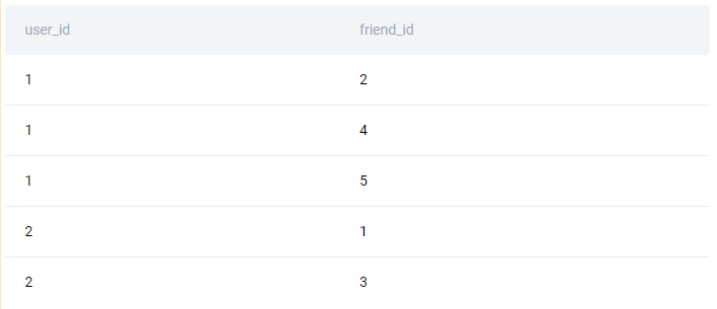
And this is what the top rows of the users_pages dataset may look like. We can find out, for example, that the user with ID 1 follows two pages with IDs 21 and 25.

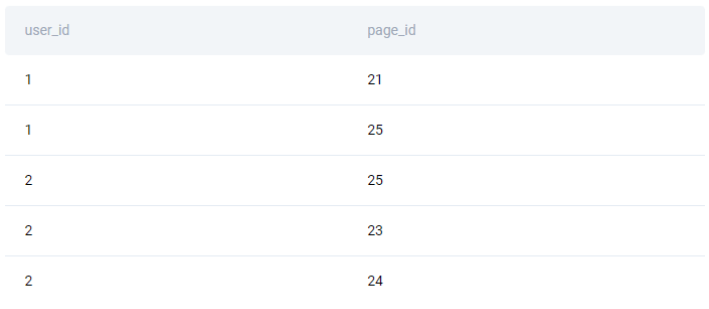
Before we start writing the code, it’s a good practice to define a few general and high-level steps that we will follow to solve the interview question. Doing this can be truly lifesaving and prevents us from getting lost in coding during a stressful job interview. In the case of this machine learning engineer interview question, we can define three such steps:
- Merge the two tables to create a list of pages that each user's friends follow,
- Compare this list with users_pages and remove rows that exist in both,
- Remove duplicates from this list;
1. Merge the two tables to create a list of pages that each user's friends follow
In Python, the first step can be completed using a merge() function such that we match the friend_id column from the users_friends table with the user_id column from the users_pages table.
friends_pages = users_friends.merge(users_pages, left_on='friend_id', right_on='user_id')
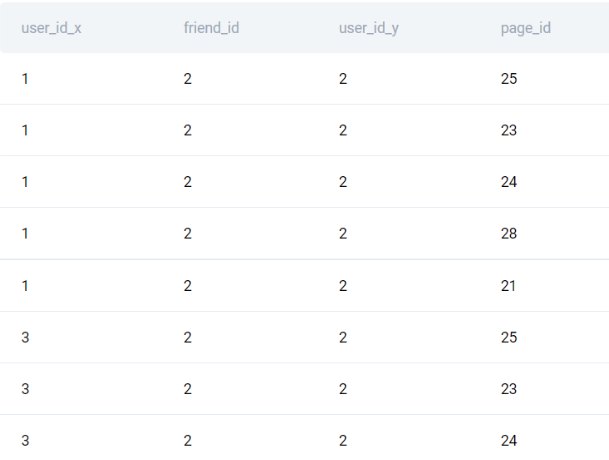
Since we’re only interested in the user and which pages their friends follow, we can remove the middle two columns from the dataset that we have obtained using the following code:
friends_pages = friends_pages[['user_id_x','page_id']]2. Compare this list with users_pages and remove rows that exist in both
Next, we move on to the next step which is about comparing the list that we have now, containing the pages that users’ friends follow, with the original users_pages table. The question that we aim to answer with this step is which pages that a user’s friends follow are also followed by this user. To achieve this, we can once again use the merge() function, this time matching both the user_id and page_id columns in both datasets. It’s crucial to perform a left merge in this case so that even if a user doesn’t follow a page that one of their friends does, the ID of this page is preserved in the table.
comparison = friends_pages.merge(users_pages, how='left', left_on=['user_id_x','page_id'], right_on=['user_id','page_id'])
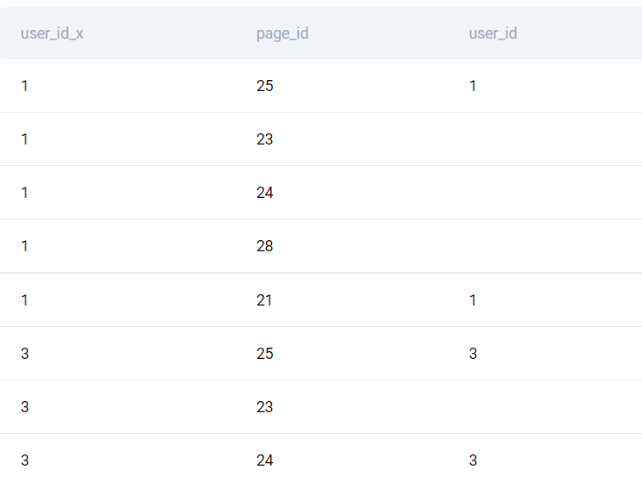
Looking at the current output, pay special attention to the first and third columns. The ID in the first column comes from the list that we have obtained in the first step, while the ID in the third column is from the users_pages table. Then, if cells in both columns are non-empty, this means that one of this user’s friends follows a certain page, but this user also follows this page. This happens in the first row above - a friend of user 1 follows a page with ID 25 but user 1 also follows this page. At the same time, a friend of user 1 follows a page with ID 23, but user 1 does not follow it themselves - this means that our system should recommend the page with ID 23 to user 1.
3. Remove duplicates from this list
Hence, the final step will be to filter these data leaving only these rows where the third column is empty - we can use the Pandas isna() function. Finally, we will also need to remove duplicates that may occur if more than one of a user’s friends followed a certain page, using the drop_duplicates() function.
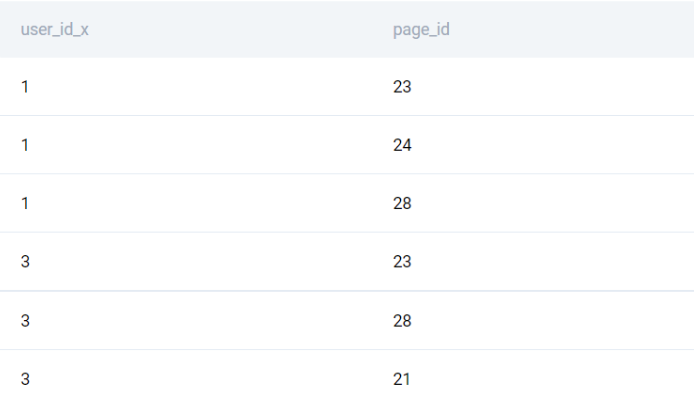
result = comparison[comparison['user_id'].isna()][['user_id_x', 'page_id']].drop_duplicates()
Thus, the final Python code producing the expected solution for this machine learning engineer interview question from Meta is as follows:
friends_pages = users_friends.merge(users_pages, left_on='friend_id', right_on='user_id')
friends_pages = friends_pages[['user_id_x','page_id']]
comparison = friends_pages.merge(users_pages, how='left', left_on=['user_id_x','page_id'], right_on=['user_id','page_id'])
result = comparison[comparison['user_id'].isna()][['user_id_x', 'page_id']].drop_duplicates()

Machine Learning Engineer Interview Question #2: Naive Forecasting
This question was asked during technical machine learning interviews at Uber. This is a great example of how companies expect candidates to perform prediction without using a complicated machine learning model but rather by encoding a number of simple rules. In this way, the interviewer not only checks the candidate’s approach to prediction tasks but also verifies the ability to code, e.g., in Python.

Link to the question: https://platform.stratascratch.com/coding/10313-naive-forecasting
The task is to develop a naïve forecast for a new metric called "distance per dollar", defined as the (distance_to_travel/monetary_cost) in our dataset, and measure its accuracy. To develop this forecast, we are asked to sum "distance to travel" and "monetary cost" values at a monthly level before calculating "distance per dollar". This value becomes the actual value for the current month. The next step is to populate the forecasted value for each month. This can be achieved simply by getting the previous month's value in a separate column. Once we have actual and forecasted values, we should evaluate our model by calculating an error matrix called root mean squared error (RMSE). RMSE is defined as sqrt(mean(square(actual - forecast)). We are asked to report the RMSE rounded to the 2nd decimal spot.
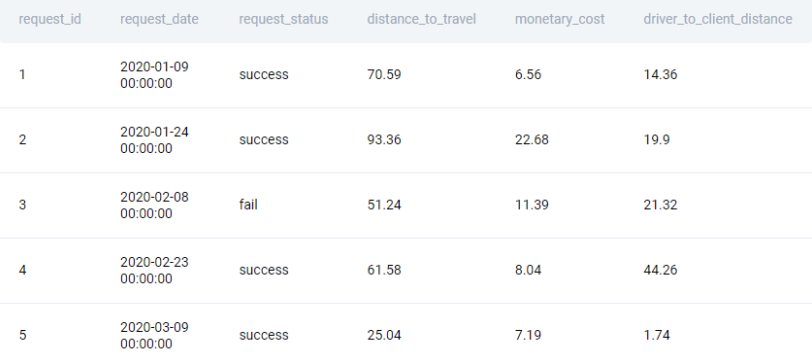
To solve this task, we should use a table uber_request_logs that has 6 columns with various datatypes:
uber_request_logs
| request_id: | int64 |
| request_date: | datetime64[ns] |
| request_status: | object |
| distance_to_travel: | float64 |
| monetary_cost: | float64 |
| driver_to_client_distance: | float64 |
This is what the top rows of this dataset uber_request_logs may look like:

In this case, the text of the interview question already suggests which steps we should take to reach the solution. But to reiterate, this is the high-level approach to solving this interview problem in Python:
- Extract month from request_date column,
- Aggregate the data by month while calculating the sum of distance_to_travel and monetary_cost,
- Divide the sum of distance_to_travel by the sum of monetary_cost to get the monthly distance per dollar,
- Use a shift() function to create a column with the distance per dollar from the previous month,
- Aggregate the data by the month, distance per dollar, and the distance per dollar from the previous month,
- Use a numpy square function to raise the difference between the distance per dollar from the previous month and the distance per dollar to the second power,
- Take the average of the calculated values and take the square root of this average,
- Output the number rounded to 2 decimal places;
Machine Learning Engineer Interview Question #3: Words With Two Vowels
Aside from the questions concerning naive forecasting or building rule-based recommendation systems, the candidates for the machine learning engineering positions are sometimes asked to manipulate text. This type of question is especially common if the position deals with natural language processing. One example is this machine learning engineer interview question from Google, where we are being asked to find all words which contain exactly two vowels in any list in the table.

Link to the question: https://platform.stratascratch.com/coding/9794-words-with-two-vowels
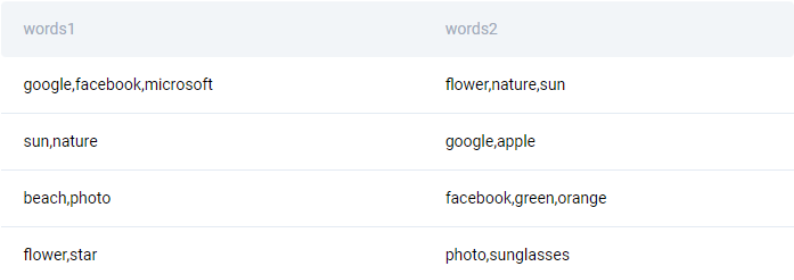
The dataset is also rather simple and contains two columns. Eventually, each cell in the dataset, no matter in which column it is, contains a list of several words divided by a comma.
google_word_lists
| words1: | object |
| words2: | object |
There can be any number of words in a list, and lists from two different cells may have different lengths. This is what this dataset may look like:

Even though both the task and the dataset appear simple at first glance, this question is actually quite difficult to solve in Python and requires a number of steps to obtain the required output:
- Explode and split each word per row under words1 and 2. Do this by using str.split(delimiter) then assigning it back to the df using assign() then explode() to transform each element of a list-like to a row,
- Select the column containing these words and convert it to a list using tolist(),
- Perform the same procedure for words under words2,
- Concatenate both lists using the Operator '+',
- Use drop_duplicates(column_name) to get distinct values in the specified column,
- Create a column containing the count of vowels per word. Use str.count(pattern),
- Filter out the DataFrame by indexing [ ] and select the values where the value under the vowel column is equal to 2, then enclose the column to return in [[ ]];
Note that this question would actually be much easier to solve using SQL in which you can use functions such as unnest() or string_to_array(). However, the machine learning engineer interviews are predominantly performed in Python or R.
Machine Learning Engineer Theoretical Interview Questions
Machine Learning Engineer Interview Question #4: Regression Definition
While the range of theoretical questions asked to machine learning engineers at technical interviews is very broad, there are a couple of types of questions that come up more frequently. One of them is to explain a certain machine learning concept in very simple terms, such as if we were explaining it to an executive with no technical background or to a child. Belvedere Trading is one of the companies that ask questions such as this to find the words to explain Regression to 8 years old.

Link to the question: https://platform.stratascratch.com/technical/2296-regression-definition
Even for beginner machine learning engineers, it should be clear that the regression is an analysis that we use to predict an unknown event, a continuous value, based on evidence that we've gathered in the past. But how to explain a concept like that to a child?
We can provide them with a simple example that can be easily followed like this:
- Let's say that you want to go to school. You notice that it takes you only 1 minute to reach the school because it's just across the street.
- Next, you ask your friend, John: how long does it take for him to reach the school? And he says: 20 minutes. When you ask why he answered: because his house is 5 km away from the school.
- Next, you ask your other friend, Andy, the same question. He answered: It takes him 40 minutes to reach the school. Now, if you guess that Andy's house is more than 5 km away from school, then you're doing regression analysis.


Machine Learning Engineer Interview Question #5: Supervised and Unsupervised Machine Learning
While there exist types of questions that appear at technical interviews significantly more often, there are also a number of specific individual questions that are asked by interviewers more frequently than the others. One of such questions that a candidate may expect is to describe the difference between supervised and unsupervised machine learning, such as in the question that was asked by Rosetta.


Link to the question: https://platform.stratascratch.com/technical/2164-supervised-and-unsupervised-machine-learning
The answer is that supervised learning uses labeled input and output datasets, which give the model the instructions when training the algorithms. Meanwhile, unsupervised learning doesn't use the labeled datasets, which means the models work independently to discover information hidden in the datasets.
However, in questions such as this one, even if not explicitly asked for this, it’s a good practice to list a few examples of algorithms from each set. For supervised learning, the examples can be Decision Tree Classification, Logistic Regression, Linear Regression or Support-Vector Machine. For unsupervised learning, the examples include K-Means Clustering, Hierarchical Clustering, Apriori Algorithm or Principal Component Analysis.
Machine Learning Engineer Interview Question #6: Confusion Matrix
But the interview questions asked for machine learning engineer positions are not always strictly about the models. Quite often, you may encounter theoretical questions concerning the evaluation of predictions or statistics, such as this one from General Assembly. We are being asked why a confusion matrix is useful for evaluating the performance of a classifier.


Link to the question: https://platform.stratascratch.com/technical/2122-confusion-matrix
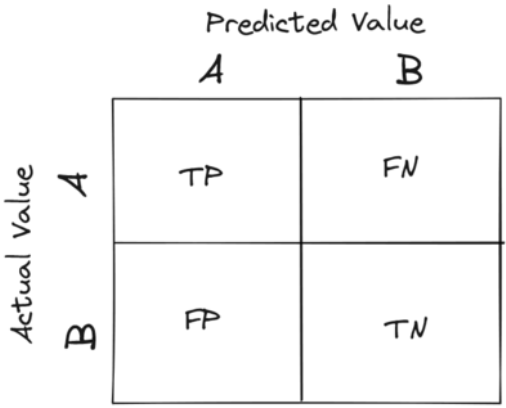
The reason why the confusion matrix is so frequently used when evaluating the performance of classifying models is that it gives us a summary of how good our classification model is in predicting the actual value of our target variable in the form of a table. It shows the true positive, false positive, true negative, and false negative values or ratios in a condensed and easy-to-read form.
But what you should remember about the machine learning engineer interview questions such as this one is that you can score extra points if, aside from just explaining the theory, you also include a drawing supporting what you are explaining. In the case of the confusion matrix, a drawing is very easy to make and quickly shows that you understand what you are explaining.

Conclusion
In this article, you could have learned more about the role of a machine learning engineer and see what kind of questions to expect when interviewing for this position in major companies. You could see that interviewers ask a mix of coding questions about making simple predictions, building rule-based systems, or manipulating strings, as well as many theory questions about the machine learning models, evaluation methods, or statistics. StrataScratch has a large collection of all these types of questions helping you prepare thoroughly for your upcoming interview.
Share


