Data Engineer Interview Questions


Categories:
 Written by:
Written by:Nathan Rosidi
A blog for all the budding Data Engineers to understand some SQL interview questions with hands-on practice through the StrataScratch platform.
Today we are going to cover the interview questions for a Data Engineer role. This article will cover some basic concepts and skills needed for a data engineer and then it will focus more on the hands-on practice with SQL.
An interview for a Data Engineer can be overwhelming if you are just starting in this field. The interview will test you on some behavioral questions, your communication skills, your problem-solving ability, and SQL!! SQL is bread and butter for any Data Engineer and typically most companies will have a SQL round, wherein you will be given a problem to solve. This can be a bit intimidating, but if you practice enough, it can be a cakewalk. To practice SQL questions, the interactive StrataScratch platform has a wide range of problems you can try.
As a data engineer, your main responsibility will be to extract the data from different sources, transform the data and load the data (ETL process). This will include working on the data but also working on the data infrastructure so that you can provide data to other teams within the organization. You will be responsible for the data accuracy, data management, and in some cases data governance. To be a Data Engineer, you need to have excellent problem-solving skills with good technical skills.
In this article, we will cover some of the most important skills for a Data Engineer and understand some of the interview questions with hands-on practice through the StrataScratch platform.
In this article, we will cover:
- SQL Interview Questions for Data Engineers
- Fundamental SQL concepts
- Non-Coding Questions
We will be using the StrataScratch platform to discuss the SQL questions. Before we start tackling them, let’s discuss what skills are required to be a good Data Engineer.
What Makes a Good Data Engineer?
A good data engineer should be able to:
- Build and maintain database systems
- Understand and be proficient in programming languages - especially Python and SQL
- Understand how to extract, transform and load the data
- Understand Cloud Technology and Systems Design
- Understand Database Modeling
Apart from the technical skills, a Data Engineer should also have good communication skills in order to explain the different data sources available and how it can be used. Now that you know what skills are required, let's jump on to the type of questions that are usually asked in the data engineer interview.
The Data Engineering Interview Question Types
- SQL Coding Questions
- Fundamental SQL and Non-Coding Questions
Let’s discuss these data engineer interview question types in detail.
SQL Coding Questions
Not every position in the Data role uses the same SQL concepts. Data Engineering roles will tend to focus more towards data architecture, ETL processes, and SQL optimization while other roles like Data Analysts or Data Scientists will focus more on querying the results from SQL query to help the business make data-driven decisions.
Data Engineers work very closely with data scientists and data analysts. Their main role is to process the data in such a way that it will be clean and useful so that Data Scientists can work on it. To do that, Data Engineers need to know SQL concepts in detail. As a Data Engineer, you cannot avoid knowing SQL, often you need to know it at an advanced level as compared to Data Analysts or Data Scientists.
The interviewers will test your SQL knowledge right from the basic concepts to the advanced ones. Whenever you write a SQL code or a Python script, you need to ensure that the script is optimized and follows the SQL best practices. Once you read the problem, don’t jump directly to writing the code. Take some time, understand the problem better and think how you will solve it. Try to implement a framework that helps you break down the problem in multiple steps. Having a framework has its benefits.
- It helps you to understand and structure the problems better
- Avoids making unnecessary mistakes
- Helps in simplifying the problem rather than overcomplicating it
- It saves time
The Framework for Solving Data Engineer SQL Coding Questions
We like a framework which has four steps:
- Explore the dataset
- Select columns that are required to solve the problem
- Writing the coding logic (maybe a pseudo code)
- Writing the code
Exploring the Dataset
With every question, you will have a table to work with. Take your time to understand how the table looks and how the structure of the table is. Go through all the columns in the dataset.
This is an important step. You need to understand what are the different data types in the dataset. Depending on the data types, you can choose which functions to use. You will understand which column’s data types should be changed. For example, if the date is represented as text, you will have to change its data type to timestamp/Date, etc.
Other than the data types, you can check if there are any duplicates or there are any null values in the dataset. This way, you will understand what each row represents.
This is a critical step to solve any question. Explore and understand your dataset!
Select Columns
After you explore the dataset, you will identify which columns would solve the question. Not all the columns in the dataset will be required to solve the problem. This will ensure that you reduce the amount of data that you work with and thereby reduce the runtime of the program. Test evaluators always check whether the best practices are implemented in SQL or not. So make sure your SQL code is optimized and the first step to do that is selecting only the required columns.
Writing Code Logic
Once you understand which columns are required, write down the logic to solve a specific question. Literally use pen and paper to build that logic before you start writing the code. This will help you in breaking down the code into smaller steps and eventually will help you in writing the code. This will ensure that you have a clear understanding of the problem and can develop logic in the code.
Coding
Once you have a handwritten code logic, you can start writing the code. This time you will have to focus on the syntax and run the code successfully to get the required output.
Having such a framework will help you in structuring your thoughts and writing the code effectively. Now that you know the framework, let’s start off with SQL.
SQL topics useful for coding sections:
In this section, we are going to focus on the below concepts and look at some of the data engineer interview questions asked by many companies.
- Aggregation, Grouping, Ordering, Filtering
- Joins and Unions
- CTEs , Subqueries, Window Functions
These topics are extremely important for Data Engineers.
1. Aggregation, Grouping, Ordering & Filtering
The aggregation functions perform calculations on multiple rows and return the result as one value, collapsing the individual rows in the process. When an aggregation function is used, you need to group the data on fields which are not aggregated by using a GROUP BY clause.
Filtering is used when you need to extract a subset of data by using a specific condition. You can use WHERE and HAVING clauses to filter the data as per your needs.
For more detailed explanations, use our SQL cheat sheet or a guide to the SQL aggregate functions.
2. Joins and Unions
Data Engineers are typically responsible for collating different data sources together and providing a cleaner source of information for the Data Scientists or Data Analysts. In order to collate data from different sources, they need a good understanding of SQL Joins and Unions. There are different types of joins based on the application, you can read about the concept in the Technical Skills for Data Analyst article.
3. CTEs, Sub Queries, and Window Functions
As the queries become more complex, it’s not always possible to write a single query and do all the analysis. Sometimes, it’s necessary to create a temporary table and use the results in a new query to perform analysis at different levels. We can use a subquery, a CTE (Common Table Expression), or a TEMP (Temporary) table for this. As a Data Engineer, you need to understand these concepts to write better and optimized SQL queries. For more information about these concepts, check the Technical Skills for Data Analyst article.
Data Engineer SQL Example Interview Questions
Data Engineer Interview Question #1: Total AdWords Earnings

Link to the question: https://platform.stratascratch.com/coding/10164-total-adwords-earnings
The question asks you to find the total AdWords for each business type. Let’s use the framework that we have learnt.
1. Explore the Dataset
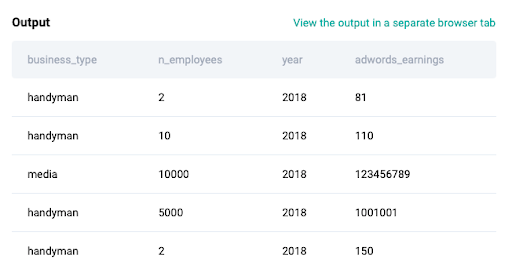
Select all the columns from this table and understand what each row represents. From selecting all the columns, we get the below output (top 5 rows)
SELECT *
FROM google_adwords_earnings
LIMIT 5
2. Select Required Columns
This data engineer interview question asks you about the total adwords earnings for each business type. This means we need two columns; one is ‘adwords_earnings’ and the other is ‘business_type’. With these two columns, we can solve the question.
3. Writing Code Logic
Once you have identified the columns that are required to solve the problem, think about what functions you will need. We need to calculate the total adword earnings for each business type. That means for each business type, we need to sum up the total earnings and this can be done by using an aggregate function called SUM(). Since we are aggregating the total earnings for each business type, we need to use the GROUP BY clause as well.
- Select ‘Business_Type’
- SUM(adwords_earnings)
- Use GROUP BY since we are using an aggregate function
4. Write the Code
SELECT business_type,
SUM(adwords_earnings) AS total_earnings
FROM google_adwords_earnings
GROUP BY 1In this problem, we have selected the business type, used the SUM() function to calculate the total earnings, and used the GROUP BY clause at the end. Instead of GROUP BY 1, you can also use GROUP BY BUSINESS_TYPE.
Output:


Data Engineer Interview Question #2: Primary Key Violation

Link to the question: https://platform.stratascratch.com/coding/2107-primary-key-violation
This question asks you which customer IDs are violating primary key constraints i.e. which customer IDs are non-unique (more than one record). The output should have all the customer IDs who are violating the primary key constraint and the number of times that customer ID is appearing in the table.
Let’s use our framework to solve this problem.
1. Explore the Data
This data set has a customer ID, name, city, date of birth, and pin code. Just from the sample data in the below screenshot, we can see C274 has three customer names associated with it and this certainly violates the primary key constraint.

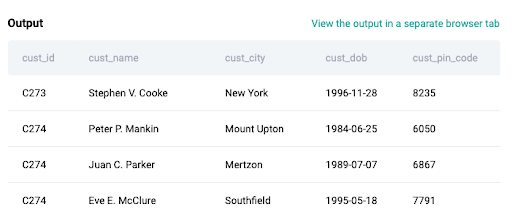
2. Select required Columns
As the output for this question, we need customer ID and the number of times that Customer ID appears in that table. Thus, we need only the customer ID and the count.
3. Writing the Logic
- Select Customer IDs from the table
- Use COUNT(*) to identify the number of times that the customer appears
- Using HAVING() to filter out only those Customer IDs which appear more than once
4. Write the Code
Step 1: Select Customer ID
SELECT cust_id
FROM dim_customerStep 2: Count the number of times that ID appears in the table
SELECT cust_id,
COUNT(*)
FROM dim_customer
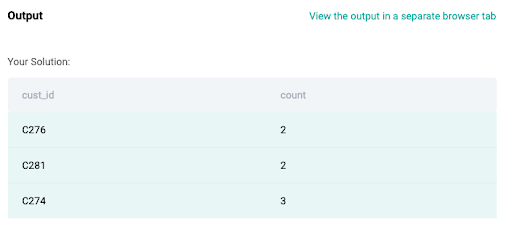
GROUP BY 1Step 3: Filter only those Customer IDs that appear more than once using the HAVING clause
SELECT cust_id,
COUNT(*)
FROM dim_customer
GROUP BY 1
HAVING COUNT(*) >1
Data Engineer Interview Question #3: Salaries Differences

Link to the question: https://platform.stratascratch.com/coding/10308-salaries-differences
In this question, we need to find the difference between the highest and lowest salaries found in the marketing and engineering departments. Let’s use our framework!
1. Explore the Dataset
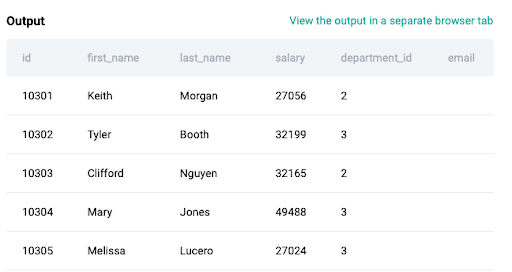
There are two tables in this dataset. One is about the employee information such as employee ID, name, salary, department ID, and email while the other table is a lookup for department ID and department name.
Employee Table:

Department Table:

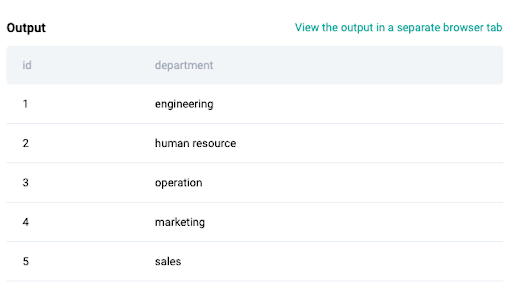
2. Select required columns
In this question, we would need a salary and department ID column from the db_employee table and department ID and department name from the db_dept table. Since the columns we need are in a different table, we will need to join them.
3. Writing the Logic
Join the two tables on department ID.
FROM db_employee emp
JOIN db_dept dept ON emp.department_id = dept.idCalculate the highest salary in the marketing department
SELECT MAX(salary)
FROM db_employee emp
JOIN db_dept dept ON emp.department_id = dept.id
WHERE department = 'marketing'Calculate the highest salary in the engineering department
SELECT MAX(salary)
FROM db_employee emp
JOIN db_dept dept ON emp.department_id = dept.id
WHERE department = 'engineering'4. Write the Code:
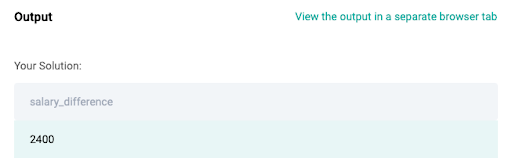
Once we have the highest salaries in the marketing and the engineering department, we can use the ABS() and calculate the difference between the two.
SELECT ABS(
(SELECT MAX(salary)
FROM db_employee emp
JOIN db_dept dept ON emp.department_id = dept.id
WHERE department = 'marketing') -
(SELECT MAX(salary)
FROM db_employee emp
JOIN db_dept dept ON emp.department_id = dept.id
WHERE department = 'engineering')) AS salary_difference
Data Engineer Interview Question #4: Best Selling Item

Link to the question: https://platform.stratascratch.com/coding/10172-best-selling-item
In this question, you need to find the best-selling item in each month. Let’s use our framework to solve this question.
1. Explore the Dataset
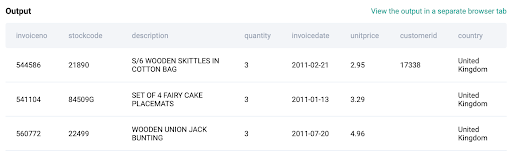
This table represents the total quantity and amount of each order along with the invoice date and the invoice number.
2. Select required Columns
From the question, we need to find the best-selling items for each month. To calculate the best-selling item, you will need quantity and unit price. Also, since you need to output the best-selling item each month, you will need the Date and Description columns as well. For the date, you will have to extract the month which we will see in the next part.
- Invoice Date
- Description
- Unit Price
- Quantity
3. Writing Code Logic
Extract the month from each date using the Date Part function.
DATE_PART('month', invoicedate) AS MONTHCalculate the total invoice paid by multiplying the unit price with the quantity ordered.
SUM(unitprice*quantity) AS total_paidSelect relevant columns and calculate the rank for each item in each month based on the total amount (unit price * quantity). For this, you will be using RANK() along with a PARTITION BY() clause since we need the best-selling item for each month and thus, we will be partitioning it by month.
SELECT DATE_PART('month', invoicedate) AS MONTH,
description,
SUM(unitprice*quantity) AS total_paid,
RANK() OVER(PARTITION BY date_part('month', invoicedate)
ORDER BY sum(unitprice*quantity) DESC) AS rnk
FROM online_retail
GROUP BY 1,
24. Write Code
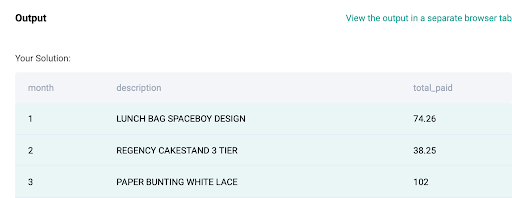
From the above steps, we ranked each item for each month based on the total billed amount. Now the question asks only for the best-selling item in each month and thus, we will be filtering the data only for rank = 1. We will be using a WITH clause to get ranking data for all the items in each month and then use a filter at the end to filter for rank = 1.
WITH best_selling_monthly AS
(SELECT DATE_PART('month', invoicedate) AS MONTH,
description,
SUM(unitprice*quantity) AS total_paid,
RANK() OVER(PARTITION BY date_part('month', invoicedate)
ORDER BY SUM(unitprice*quantity) DESC) AS rnk
FROM online_retail
GROUP BY 1,
2)
SELECT MONTH,
description,
total_paid
FROM best_selling_monthly
WHERE rnk = 1
Data Engineer Interview Question #5: Employee with Most Orders


Link to the question: https://platform.stratascratch.com/coding/2117-employee-with-most-orders
In this question, you have to find the employee or the employees with the most orders. Let’s use our framework to check the data:
1. Explore the Dataset
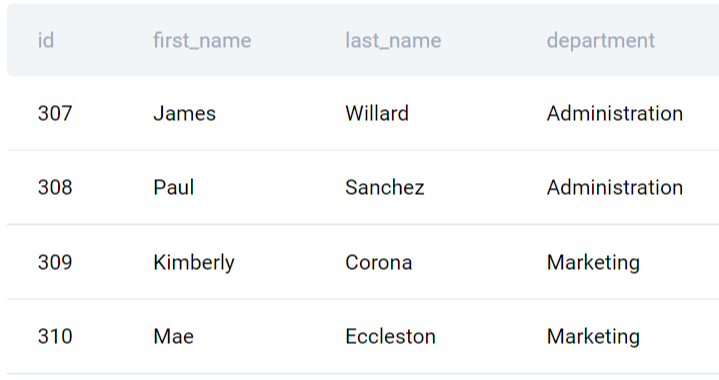
There are two tables; shopify_orders and shopify_employees. The Shopify orders table represents each order from a user, order amount, total items ordered, etc. The Shopify employees table gives information regarding the employees such as ID, First Name, Last Name, and their Department.
Shopify Orders:


Shopify Employee:

2. Select required Columns
In the Shopify orders table, you don’t need all the columns. There are many columns that are redundant for this data engineer interview question. You need to count distinct order IDs by each employee and find out which employee ID had the maximum number of orders. Thus, from the Orders table, you would need only resp_employee_id and order_id columns.
From the employees table, you will need ID and last_name. The question states that you need to output the last name of the employees with maximum orders. Thus, you will need only ID and Last Name from this table.
3. Writing Code Logic
Now that you know which columns are useful, you can start building the code logic.
As the first step, count the number of orders by each employee by using the below code:
SELECT resp_employee_id,
COUNT(DISTINCT order_id) AS orders
FROM shopify_orders
GROUP BY 1Second step would be to find the employee_id with maximum orders and for that we will be using the RANK() function.
SELECT resp_employee_id,
COUNT(DISTINCT order_id) AS orders,
RANK() OVER(
ORDER BY COUNT(DISTINCT order_id) DESC) AS emp_rank
FROM shopify_orders
GROUP BY 1This will give you the rank for each employee ID based on the number of orders. Now that you have this level of data, join it with the employees table to get the last name for all the user IDs.
SELECT resp_employee_id,
e.last_name,
COUNT(DISTINCT order_id) AS orders,
RANK() OVER(
ORDER BY count(DISTINCT order_id) DESC) AS emp_rank
FROM shopify_orders o
JOIN shopify_employees e ON o.resp_employee_id = e.id
GROUP BY 1,
2Now that you have ranks for each employee based on the number of orders along with the last names, you just need to filter for Rank = 1 to get the desired output.
4. Write the Code
WITH employee_ranking AS
(SELECT resp_employee_id,
e.last_name,
COUNT(DISTINCT order_id) AS orders,
RANK()OVER(
ORDER BY COUNT(DISTINCT order_id) DESC) AS emp_rank
FROM shopify_orders o
JOIN shopify_employees e ON o.resp_employee_id = e.id
GROUP BY 1,
2)
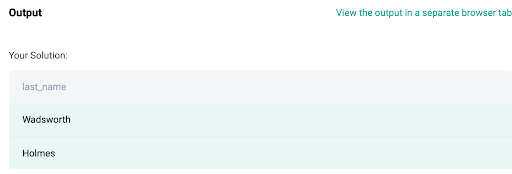
SELECT last_name
FROM employee_ranking
WHERE emp_rank = 1The logic that we have developed in step 3 is now contained in the WITH clause which is also called as a common table expression. After the WITH clause ends, we select the last name of only those records which have employee rank = 1.

Fundamental SQL and Non-Coding Questions

These are the types of data engineer interview questions where you will be evaluated on the basis of your understanding of the database concepts. You won’t need to write any code in this type of question. Some basic sample questions that might be asked in the Data Engineering interviews are below:
- General Question about SQL
- What is SQL?
- What are different types of SQL?
- What is the Primary Key?
- What is the Foreign Key?
- Relational Database Concepts
- What is RDBMS?
- What are different SQL Engines using RDBMS?
- What is the difference between SQL and No-SQL databases?
- Division of SQL Commands
- What are DDL commands? What are DQL, DML, and DCL commands?
- What is the difference between the above four types?
- Give one example of each
- Data Types
- What are the different data types in SQL?
- How would you convert integers to float?
- Joins
- What are the different types of joins?
- When is each join used?
- What is the difference between different join types?
- UNIOINs
- What is the difference between UNION and UNION ALL
- Aggregation and Rollup Functions
- What is CTE?
- When should CTE be used?
- What are Window functions and give an example?
- SQL function knowledge
- What does the COALESCE function do?
- What is the difference between WHERE and HAVING?
There is no dedicated interview where these questions are asked. It’s typically asked during the SQL coding round. So once you submit your code, the interviewer might ask you these questions as a follow-up to your code. For example, if you have used a HAVING clause, the interviewer might ask you why not a WHERE clause?
As a Data Engineer, you will be evaluated with SQL but most specifically different aspects of SQL that a Data Analyst might not be aware of. For example, you might get questions around Extract, Transform, Load (ETL).
For the data transformation process, you might be asked about various concepts in the ETL process. For example:
- Data Definition Language (DDL) Keywords
- Data Manipulation Language (DML) Keywords
- Data Control Language (DCL) Keywords
- Transaction Control Language (TCL) Keywords
- JOINs/Unions
- Indexing
- Transactions
- Views
- Stored Procedures
- Variables
- Query Optimisation
- User Defined Functions
Now that you are familiar with the fundamental question that can be asked about SQL, let’s focus on some examples from different companies.
Data Engineer Interview Question #6: Common Table Expression


Link to the question:https://platform.stratascratch.com/technical/2354-common-table-expression
In this question, the interviewer wants to understand whether you have basic knowledge about SQL or not. These types of questions are asked to assess your technical knowledge about the subject but also your communication skills and how well you describe any given problem.
Solution:
A Common Table Expression is a named temporary result set. You create a CTE using a WITH keyword, then reference it within a SELECT, INSERT, UPDATE, or DELETE statement.
Example:
Let’s say you have a table called restaurants with the columns restaurant_id, restaurant_name, district_id, and the number of customers. You need to write a query to display a list of restaurants alongside their district ID and the average number of customers per restaurant in that district.
Your logic might be as follows:
- Create a table with the list of districts and the corresponding average number of customers per restaurant.
- Join this table with the list of restaurants and display the required information.
- Drop the table with the average number of customers per restaurant for each district.
If you use a CTE, you don’t need to create and drop a table. You can simply reference the temporary result set created by the WITH query as you see below:
WITH avg_customers AS
(SELECT district_id,
AVG(customers) AS average_customers
FROM restaurants
GROUP BY district_id)
SELECT s.restaurant_name,
s.district_id,
avg.average_customers
FROM restaurants s
JOIN avg_customers avg ON s.district_id = avg.district_id;Data Engineer Interview Question #7: Delete and Truncate


Link to the question: https://platform.stratascratch.com/technical/2084-delete-and-truncate
Solution:
The differences between DELETE and TRUNCATE:
- TRUNCATE will remove all rows of a table, while DELETE can be used to remove specific rows of a table with the inclusion of the WHERE clause.
- TRUNCATE is a Data Definition Language (DDL) which means that it is more focused for the structure of a schema or a table, where DELETE is a Data Manipulation Language (DML) that is more focused to manipulate (delete) the entries of a schema or table.
- TRUNCATE is faster than DELETE because it doesn't log entries for each deleted row in the transaction log.
Data Engineer Interview Question #8: Linked List and Array

Link to the question: https://platform.stratascratch.com/technical/2074-linked-list-and-array
Solution:
The differences between linked lists and arrays:
- Array elements are stored sequentially in memory, while linked list elements are randomly stored in the memory.
- Array elements are independent of each other, while linked list elements are not. Each node of a linked list contains the pointer to the address of the next and the previous nodes.
- Because array elements are stored sequentially, then it is very fast to access each element of an array. Accessing an element in an array can be done by specifying its index (O(1)). Meanwhile, accessing an element in a linked list is slower because we need to traverse each element of each list (O(n)).
- The size of an array needs to be specified in advance because it works with static memory. Meanwhile, the size of a linked list can grow and shrink dynamically as we want to add or delete new elements.
- Arrays are generally slower compared to linked lists when it comes to adding or deleting elements, especially when the element is the first or last element in the sequence. To add or delete elements, we need to traverse each element of an array and restructure the position of each element afterward (O(n)). Meanwhile, adding or deleting an element at the beginning or at the end of a sequence with a linked list is much faster as we only need to change the pointer of the head or tail node (O(1)).
Summary
We hope you got a good flavor of what to expect in your next Data Engineering interview. In this article, we have looked at various aspects of the Data Engineering interview. We looked at some fundamental questions on SQL, SQL coding questions and non-coding questions around Data Transformation and Data Modeling.
Even if you have just started learning SQL, all it takes to crack the interview is practice and be persistent to solve as many questions as possible. If you don’t have a lot of on the job learning experience of SQL, practice on the StrataScratch platform. Only by writing a code, you will gain experience in tackling problems of different kinds and the syntax would become very easy to understand.
If you are very experienced in SQL and use it in your existing role, it’s always a good idea to prepare for the interview and brush up a few concepts. Usually in a business environment, people usually know concepts that they use everyday. Not everyone uses all the concepts and thus, it becomes critical to brush up various concepts in SQL.
With StrataScratch, you can tackle coding as well as non-coding questions and would be able to be a part of a community of like-minded people. You can communicate and collaborate with other aspiring Data Engineers and work towards achieving your dream job. We have more than 400 real-life SQL interview questions on the platform ranging from beginner to advanced level. We highly recommend you join the community of over 20K learners and be interview ready. All the best!
Share


