Most Common DoorDash Data Scientist Interview Questions


A completely new set of DoorDash Data Scientist Interview Questions. We’ll give you a guide on how to approach and successfully solve these most common data scientist interview questions from DoorDash.
Introduction
DoorDash is an online logistics platform with the main focus being on food ordering and food delivery. As a US market leader in food delivery with 56% market share, DoorDash collects massive amounts of data. Collected data is then utilized for search ranking, menu classification, recommendations and other tasks that improve their platform. For that, they are in constant search for Data Scientists and Machine Learning Engineers that would help them scale and improve their ML models.
Technical Concepts Tested in DoorDash Data Scientist Interview Questions
In light of this, we felt it would be helpful to give you some advice on how to be successful in the data science job interview at DoorDash. We’ll give you an overview of technical concepts that are tested in DoorDash data scientist interviews. Also, we’ll show you some data scientist interview questions from DoorDash and their relation with technical concepts.
In the table below you can see the main technical concepts you need to know to solve DoorDash’s data scientist interview questions:
| ISODOW function | ntile function |
| WINDOW functions | EXTRACT date/time values (HOUR, YEAR...) |
| AVG/SUM | WHERE/HAVING clause |
DoorDash data scientist interview questions test your knowledge of transforming raw data you’re given and shaping it into the appropriate structure that can be used to solve the question. For that, you need to have a pretty decent knowledge of SQL and its helper functions. For example, the question could ask you to calculate the average salary per weekday and not give you the weekday column. But you’ll have some other column (maybe a datetime column) that you must identify and transform it to extract a weekday value for each row. In PostgreSQL, you have the ISODOW function to extract a weekday from a datetime column. It would be good to go over all date/time helper functions before the interview at DoorDash.
Furthermore, DoorDash data scientist interview questions could demand to calculate a result for a subset of data. You need to be familiar with WHERE/HAVING clauses to filter out unwanted data, e.g. you can be asked to return restaurants that are in the top 10% for their generated revenue. But let’s look at some example questions to have a better sense of what you need to know for a DoorDash data science interview.
DoorDash Data Scientist Interview Questions
DoorDash Data Scientist Interview Question #1: Lowest Revenue Generated Restaurants
Question link: https://platform.stratascratch.com/coding-question?id=2036


Our task is to find the bottom 2% of restaurants by their generated revenue. An additional condition is that the order needs to be placed in May 2020. Query output needs to have restaurant id and its total revenue in May 2020. The question also gives a couple of hints on how to solve the question.
In our Twitch article, we explained to you a step-by-step approach to solve any Data Science interview question. In short, we need to:
- Understand the data: list assumptions you have about data, and if there is any ambiguity ask the interviewer to clear it or to show you some data examples.
- Formulate our approach: write down logical steps for solving the problem along with identifying what functions we need to use.
- Write the code: build up our code without unnecessary complications.
First, we start with data, and it looks like this:
| customer_placed_order_datetime | placed_order_with_restaurant_datetime | driver_at_restaurant_datetime | delivered_to_consumer_datetime | driver_id | restaurant_id | consumer_id | is_new | delivery_region | is_asap | order_total | discount_amount | tip_amount | refunded_amount |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2020-05-25 16:36:00 | 2020-05-25 18:17:00 | 2020-05-25 18:47:00 | 257 | 154 | 190327 | TRUE | San Jose | FALSE | 36.99 | 6 | 1.42 | 0 | |
| 2020-05-02 16:32:00 | 2020-05-02 17:59:00 | 2020-05-02 18:50:00 | 168 | 297 | 12420 | FALSE | San Jose | FALSE | 32.71 | 0 | 3.67 | 0 | |
| 2020-05-24 16:38:00 | 2020-05-24 20:03:00 | 2020-05-24 20:37:00 | 2020-05-24 20:49:00 | 290 | 201 | 106412 | TRUE | San Jose | FALSE | 33.35 | 6 | 1.25 | 0 |
| 2020-05-17 17:34:00 | 2020-05-17 18:01:00 | 2020-05-17 18:09:00 | 2020-05-17 18:35:00 | 232 | 188 | 104751 | FALSE | San Jose | FALSE | 33.02 | 6 | 2.48 | 0 |
| 2020-05-24 17:40:00 | 2020-05-24 18:04:00 | 2020-05-24 18:51:00 | 290 | 135 | 13641 | TRUE | San Jose | FALSE | 24.49 | 6 | 2.45 | 0 |
We can draw few assumptions from the dataset:
- customer_placed_order_datetime is the column that indicates when did the order placement happened
- order_total is column that holds total order value
Now we need to define our approach before coding:
- Filter out table by the only condition requested by the question - date requirement to only consider May 2020 orders. Column customer_placed_order_datetime is of type datetime so we don’t have to do any datatype conversion.
- Calculate total revenue (sum) for each restaurant_id
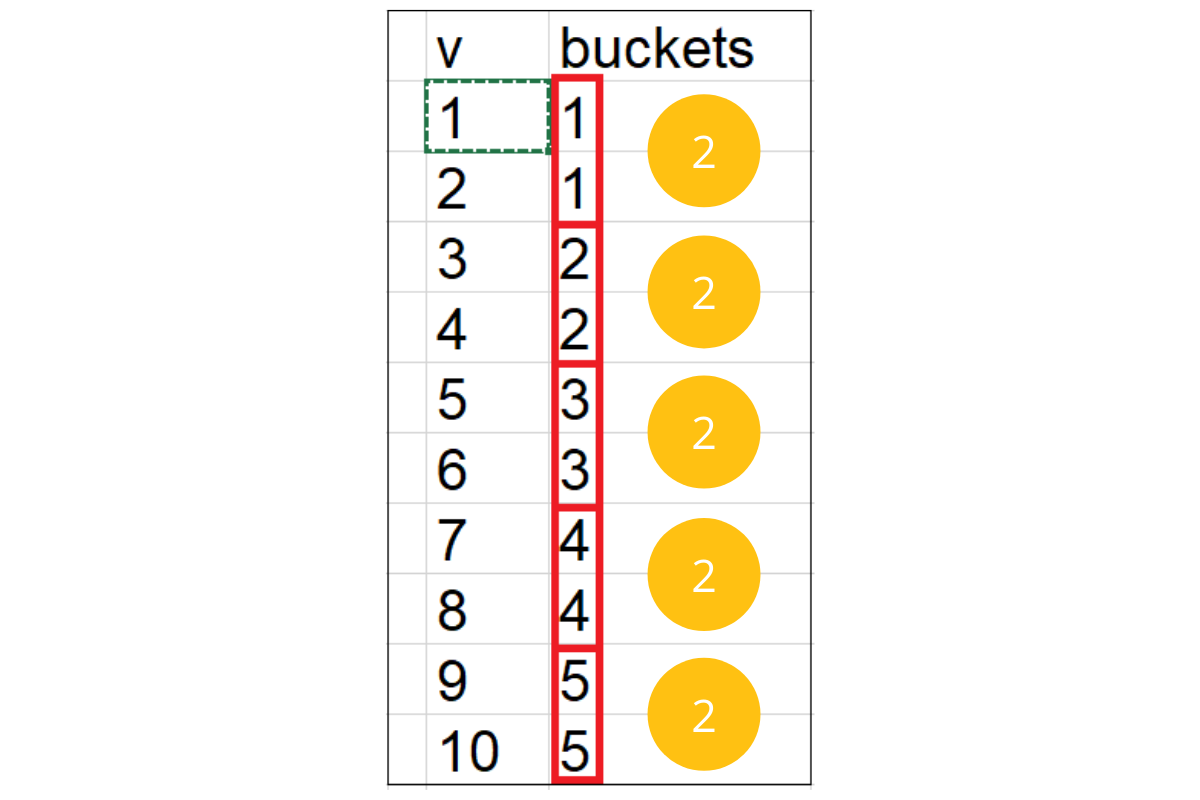
- To filter bottom 2% revenue generating restaurants question gives us a hint to partition the total revenue into evenly distributed buckets. In SQL this is possible with NTILE(n) window function which divides data into n buckets. If we divide data into 50 buckets ordered by total revenue in ascending order, restaurants in n=1 bucket will be bottom 2% by generated revenue. To order data by some column you need to specify this column in the OVER clause. In the image below you can see what NTILE(5) would actually do.
And here is the SQL code that matches our defined approach:
SELECT restaurant_id, total_order
FROM
(SELECT restaurant_id,
sum(order_total) as total_order,
ntile(50) OVER (
ORDER BY sum(order_total))
FROM doordash_delivery
WHERE customer_placed_order_datetime BETWEEN '2020-05-01' and '2020-05-31'
GROUP BY restaurant_id) sq
WHERE ntile=1
ORDER BY 2 DESCIn the DoorDash data scientist interview, this is labeled as a hard question. You need to know how to use a window function, which one is appropriate for this problem and how to utilize the output of the used window function to filter only relevant data. Furthermore, you need to identify appropriate columns for your problem among multiple similar columns.
DoorDash Data Scientist Interview Question #2: Avg earnings per weekday and hour
Question link: https://platform.stratascratch.com/coding-question?id=2034&python=

The task here is to calculate average earnings for each hour and day of the week. This DoorDash data scientist interview question gives us a hint of not only which column to use for calculating required time attributes, but also which column needs to be used for calculating earnings. Furthermore, the question has two conditions: to sort data by earning in descending order and to consider Monday as the first day of the week.
Dataset is the same as in the first question, so we can immediately start with the approach part:
- Extract hour and day of the week from the ‘Customer placed order datetime’ column. You need to be familiar with date/time functions and their syntax to extract this. For extracting hour we use the hour function, and for extracting day of the week we use the isodow function (because of the condition that Monday is first day of the week and marked as 1)
- Use hour and day of the week as a group
- Perform average over earnings column for each group
- Order the data by average earnings in descending order
Also, find our data science interview guide here that includes real questions from 80 different companies.
Conclusion
In this article, we showed you the type of questions you can expect at a DoorDash Data Scientist interview. We also explained how to use our step-by-step approach to successfully solve the DoorDash questions. This framework can be applied to every single question you can get in your data science interview.
If you want to see our solution for the second DoorDash question, but also to other DoorDash data scientist interview questions (or some other top-tier Data Science companies) head to our platform. You can find Python solutions as well if you prefer them more than SQL.
Latest Posts:



Share