Twitch Data Science Interview Question


Categories:
 Written by:
Written by:Nathan Rosidi
A brand-new Twitch data science interview question where we'll walk you through the steps on how to solve the problem and communicate with the interviewer.
Twitch is a video live streaming platform that focuses on video game live streaming, music broadcasts, and creative content. You can chat with millions of other people from around the world on Twitch. Twitch Interactive, a subsidiary of Amazon, operates the platform. The popularity of Twitch is so popular that by February 2020, the platform had 15 million daily active users and 3 million monthly broadcasters.
The Data Science Role at Twitch
Twitch has a dedicated “Science Team” that includes the roles like data scientists, data analysts, and data engineers. The data science team performs a wide range of analysis at Twitch. The data science role at Twitch includes data collection, data cleaning, and loads over a billion events per day into their data warehouse. The role is influenced by the teams that data scientists are working with. Data scientist roles and functions range from product-focused analytics to machine learning and deep learning algorithms.
Twitch Data Science Interview Question
Today, we'll walk-through one of the brand-new data science interview questions we got from Twitch. It’s a great data science interview question from Twitch with some advanced techniques that is relevant to both - interviews and questions you’d be answering on your day job. Let’s walk through this question and step-by-step approach.
The value of using a step-by-step framework is that you can rely on it during an interview where it might be a bit stressful and you’re not thinking clearly. Following these steps can help calm you down and help with covering all aspects of what you need to convey to the interviewer for a complete solution and discussion.
Question
Last Updated: January 2021
Return the number of streamer sessions for each user whose very first session was as a viewer.
Include the user ID and count of streamer sessions for users whose earliest session (by session_start) was a 'viewer' session, regardless of whether they ever had a streamer session later. Sort the results by streamer session count in descending order, then by user ID in ascending order.
Link to the question: https://platform.stratascratch.com/coding/2012-viewers-turned-streamers
Table Schema
Assumptions
The first thing to do is reiterate the question back to the interviewer. For this interview question, we’d say something like “To confirm, we’re trying to find how many streamer sessions a user has had. And a user is defined as someone that was a viewer during their first session. Is that right?”
If the interviewer agrees, then the next step is to establish your assumptions about the data and the definitions.
What are the assumptions for the data and table?
Let’s take a look at the schema without previewing the table first because you typically won’t have access to the underlying data on an interview. So you’ll need to make assumptions about how the table behaves.
Here you’re still having a conversation with the interviewer so that you both agree on the assumptions. You make statements or ask questions, like this:
- Session type would be ‘steamer’ or ‘viewer’. Or would a session type be a steamer or viewer? Are there any other types?
- Each record in the table is a session and all sessions are unique by session_id.
- Why is that important? Because if uniqueness is established, then I don’t need to do any deduplication or grouping. I can work with the data as it is. It makes my work easier.
- The data is clean, meaning that there are session_start times and end times for all sessions. Session start times are unique for each user (i.e., there shouldn’t be 2 sessions of the same start time by the same user). This often doesn’t need to be said unless you think there really can be a lot of edge cases with the data. But it’s always worthwhile to check.
- One thing I would avoid is asking some of these questions because hiring managers, like myself, might just ask you how you would handle dirty data like what you just mentioned, making the question much harder. I usually just ask those questions out of curiosity but your response wouldn’t go into my evaluation on whether or not you pass. So asking these questions takes a lot of effort on your part.
Logic
The next step is to write out your logic in words before getting solved this Twitch data science interview question.
- The first step is to identify users that had their first session as a viewer because once we have that we can count the sessions.
- Let’s rank by session start times because that will give us the correct ordering.
- We’ll return a table with user_id, session_type, and rank
- Now that we have rankings of sessions, we can filter by the 1st session and by “viewer”. So we get records where the user’s first session was a viewer. Then return the user_id
- Now we can start counting the session by user. You’ll want to use the previous filtering in the WHERE clause. So you’ll filter by users where they were viewers in their first streaming session and you’ll filter for streamer sessions. Then lastly count the number of sessions, which are records, by user_id
- Lastly order by number of sessions then user_id ASC
Once you’ve written all of these steps out. Ask the interviewer if they agree with this approach. They might mention an edge case or ask you to clarify something in the approach. Pay close attention to what they say because they’re offering you valuable information here.
You’ll often be asked to clarify a theoretical question like “what does rank() actually do as compared to the other ranking functions?”. Here you can say that “RANK gives you the ranking within your ordered partition. With the next ranking(s) skipped, Ties are assigned the same rank. Therefore, if you get 3 items at rank 2, the next rank listed would be ranked 5.”
Now let’s start to code.
Approach and Solution
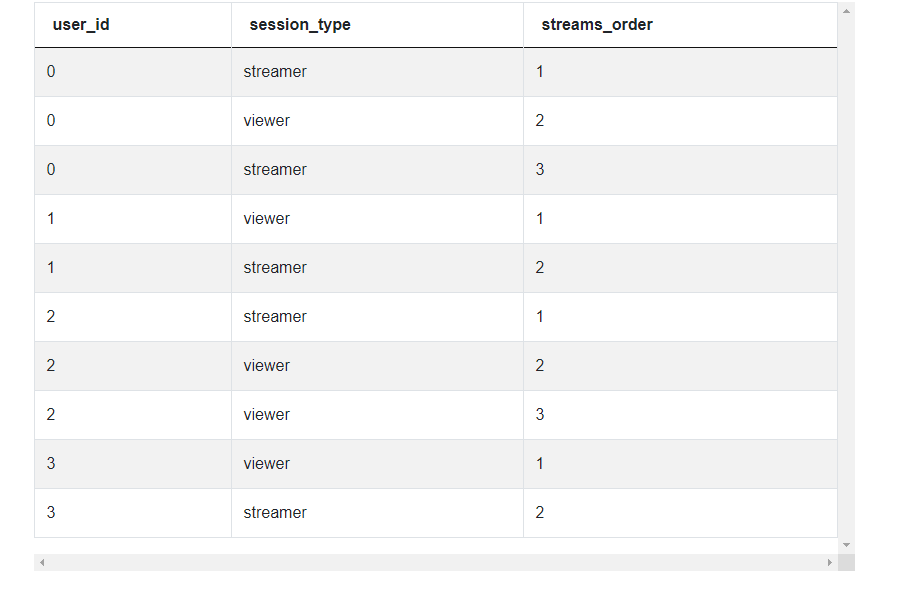
1. Sort the streams by users and session start times using rank().
SELECT user_id,
session_type,
rank() OVER (PARTITION BY user_id
ORDER BY session_start) streams_order
FROM twitch_sessionsOutput:

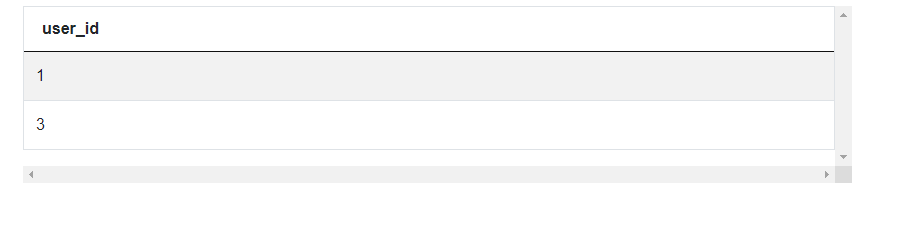
2. Take the 1st stream for each user and filter for viewers. These are the user_ids of all users that have had their first session as a viewer. This is the hard part of the question.
SELECT user_id
FROM
(SELECT user_id,
session_type,
rank() OVER (PARTITION BY user_id
ORDER BY session_start) streams_order
FROM twitch_sessions) s1
WHERE streams_order =1
AND session_type = 'viewer'Output:

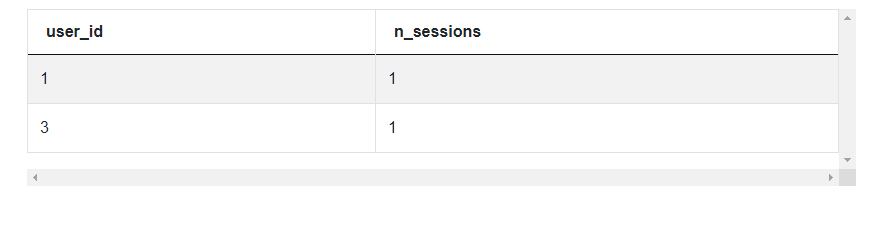
3. Now that you’ve identified the users, just count the number of sessions they’ve had as streamers. This is the easy part.
SELECT user_id, count(*) n_sessions
FROM twitch_sessions
WHERE session_type = 'streamer'
AND user_id in
(SELECT user_id
FROM
(SELECT user_id,
session_type,
rank() OVER (PARTITION BY user_id
ORDER BY session_start) streams_order
FROM twitch_sessions) s1
WHERE streams_order =1
AND session_type = 'viewer')
GROUP BY user_id
ORDER BY n_sessions DESC,
user_id ASCOutput:

Code Optimization
A very popular follow-up question is -- Can you optimize the code?
What should you look out for? The main thing is condensing CTEs and subqueries, or removing JOINs and using a CASE statement instead. Those are the low hanging fruits.
So for our solution:
- Let’s take a look at all the queries to see if we can condense/collapse some.
- Can we condense the identification of users that were first viewers? You can’t because you need to find their 1st streams regardless of if they were streamers or viewers. Then you need to create another query to work on top of your view. So you need to have these subqueries within subqueries.
- What are other ways to write this? You can use a CTE or a temp table.
- You then might get asked, which one performs better?
- https://dba.stackexchange.com/questions/13112/whats-the-difference-between-a-cte-and-a-temp-table/13117#13117
- Temp tables if you’re going to use this for other queries
- Temp tables can be indexed so this itself can make the query faster.
Check out our data science interview preparation guide to find more interview topics.
Conclusion
So this was a step-by-step approach or framework to solving this Twitch data science interview question. You can use this framework and apply it to every single question you get in your data science interview. What’s important is reiterating your question, discussing assumptions, walking through the logic before coding, and coding while explaining what you’re doing. That’s sort of how you solve all the data science problems.
What’s hard is being able to communicate eloquently throughout the entire process, thinking on your feet when questions are being asked, and coming up with the solution. So how can you get better? The answer is PRACTICE. The more you practice, the more you’ll see patterns in what’s being tested. For example, was it obvious that you needed to solve this problem using a rank()? It’s probably obvious to someone that has practiced a lot so they’re not focused on coming up with the solution, they’re focused on how to best communicate my solution to the interviewer so I don’t look like an idiot. That’s where you want to be in order to succeed.
Share


