DoorDash SQL Interview Questions


Categories:
 Written by:
Written by:Nathan Rosidi
A detailed walkthrough of one of the interesting DoorDash SQL interview questions and solution.
The DoorDash SQL interview question we selected for you today is interesting because it requires you to know a variety of SQL concepts. It tests your ability to deal with different types of data by using the functions such as TO_CHAR() and EXTRACT(). Also, it involves the aggregate functions and CASE statement.
We’ll not just throw the question and solution at you. What you’ll find if you continue to read is our advice on how to approach answering the question, and not only this one. You can use it for any other DoorDash or other companies’ SQL interview questions. We believe this can help you greatly in any SQL interview you find yourself in.
To make it even more helpful, we made a video that will make it easier for you to follow everything we’ll talk about here. Or vice versa.
DoorDash SQL Interview Question
Extremely Late Delivery
The question we want to talk about is this one.


Link to the question:
https://platform.stratascratch.com/coding/2113-extremely-late-delivery
If you have researched the company beforehand (highly recommended!), this is the time to demonstrate your understanding of the business.
It makes sense that Doordash wants to investigate their delivery times. Especially in the food industry, on-time delivery is crucial to ensuring customer satisfaction. Aside from this, it also affects food quality and safety. Food needs to be served fresh!
Imagine you’re a data analyst at DoorDash, and Management wants to know, for every month, what percentage of their orders are ‘extremely late deliveries’. A delivery is considered ‘extremely late’ if the order is delivered more than 20 minutes late of the predicted delivery time.
Intuitively, we would monitor the number of ‘extremely late’ deliveries month on month. However, we cannot look at this number alone. The total deliveries will change monthly and fluctuate based on season, holidays, and due to the general growth of the company. A better metric to track is the percentage of total orders that are ‘extremely late’. This is exactly what this DoorDash SQL interview question is asking us to do.
Ideally, we want to see this metric lower over time or at least, be kept within a certain threshold. Otherwise, this is a cause for concern, leading to low ratings, less repeat business, and poor food quality. Sooner than you think, the company is out of business. And you’re out of your job!
We can’t prepare you for losing your job, but we can for getting one!
Solution Approach Framework to Solve this DoorDash SQL Interview Question

Now that you understand the problem you need to solve, let’s start formulating the solution.
Using a framework for that will help you structure your thoughts and communicate them in a way that the interviewer can follow. This is important because oftentimes, it is not only your coding skills that are being tested but your communication skills as well.
The framework we recommend consists of the following steps.
- Explore and understand the dataset
- Confirm and state your assumptions
- Outline your high-level approach in English or pseudo-code
- Code the solution
- Code optimizations (if there are any)
If you are not yet familiar with this, go check out this video where all the steps are explained in detail.
1. Explore the Dataset
We are provided with the delivery_orders table showing the delivery ID, the time when the order was placed, when it was predicted to be delivered, when it was actually delivered, the rating provided to that delivery, as well as the IDs of the dasher (rider), the restaurant, and the consumer (customer).
Here’s the table structure.
| delivery_id: | varchar |
| order_placed_time: | datetime |
| predicted_delivery_time: | datetime |
| actual_delivery_time: | datetime |
| delivery_rating: | int |
| dasher_id: | varchar |
| restaurant_id: | varchar |
| consumer_id: | varchar |
Once an order is placed, it is assigned a unique delivery ID, and the relevant details about the order like the customer, the restaurant, the date, and time of order are then logged. The delivery time/expected time of arrival of delivery is computed, and the order is assigned to a dasher/rider whose ID is also included in the table. Once the order is delivered, the exact time is logged, and the customer provides their feedback through a rating.
2. Confirm and State Your Assumptions
The question doesn’t offer info on what happens if the order is canceled or the delivery is in transit, i.e., placed but not yet delivered.
You can clarify this with the interviewer. We don’t have this option, so we’ll assume that the dataset contains only fulfilled orders.
3. Outline the High-Level Approach
Now, let’s unpack what is required to get the target output table. This DoorDash SQL interview question asks us to show the proportion of extremely late orders for each month.
The output should show months in a YYYY-MM format, with the corresponding percentage of extremely late orders in the second column.
To get the dates in a desired format, we need to extract the month and year information from the order_placed_date column.
As for the percentage, it requires calculating the total number of late orders and the total number of orders for every month.
Getting to the number of total orders is easy: we only need to count the number of unique delivery IDs. But what about the total number of extremely late orders per month?
In order to determine whether an order is an ‘extremely’ late order or not, we will have to compare the columns predicted_delivery_time and actual_delivery_time. If the actual delivery time exceeds the predicted delivery time by more than 20 minutes, then we have an ‘extremely late’ order.
To weed the extremely late orders, we’ll use the CASE statement.
Turning this verbose description into steps:
- TO_CHAR() – extract month and year from the column order_placed_date in the format YYYY-MM
- CASE statement – identify extremely late deliveries at the row level
- EXTRACT() – get the difference between the actual and predicted delivery time in minutes
- SUM() – get the total number of the extremely late deliveries
- COUNT() and DISTINCT – get the total number of all deliveries; divide the previous step to get the percentage
- CAST() - get the decimal point in the percentage (FLOAT)
- GROUP BY – get the output by month
Once you list all the steps, check them with the interviewer. It helps you get feedback early on. If all’s good, you can start coding.
4. Code the Solution
Coding will now simply mean translating the above steps into an SQL code.
1. Extract Month and Year
We will use the TO_CHAR() function to get data in the desired format.
SELECT TO_CHAR(order_placed_time,'YYYY-MM') AS year_month
FROM delivery_orders;
If your idea was to use maybe the EXTRACT() or DATE_PART() function instead, you can. However, these functions won’t directly get you the format you need, which is YYYY-MM. If you want to learn more about datetime manipulation, check out our video.
2. Identify the Extremely Late Deliveries
The CASE statement is an IF-THEN-ELSE statement in SQL that will allow us to identify the extremely late deliveries.
SELECT TO_CHAR(order_placed_time, 'YYYY-MM') AS year_month,
CASE
WHEN (prediced_delivery_time - actual_delivery_time) > 20 THEN 1
ELSE 0
END
FROM delivery_orders;
However, for this to work, we need to extract minutes and subtract them.
3. Show Difference in Minutes
In this step we’ll use the EXTRACT() function. The code looks like this so far.
SELECT TO_CHAR(order_placed_time, 'YYYY-MM') AS year_month,
CASE
WHEN EXTRACT(MINUTE
FROM (actual_delivery_time - predicted_delivery_time)) > 20 THEN 1
ELSE 0
END
FROM delivery_orders;
4. Number of Extremely Late Deliveries
The CASE statement will show integer 1 besides every extremely late delivery. To get their number, we use the SUM() aggregate function.
SELECT TO_CHAR(order_placed_time, 'YYYY-MM') AS year_month,
SUM(CASE
WHEN EXTRACT(MINUTE
FROM (actual_delivery_time - predicted_delivery_time)) > 20 THEN 1
ELSE 0
END)
FROM delivery_orders;
5. Number of All Deliveries
The next step is to find the number of all unique deliveries using COUNT() and DISTINCT. Also, the number of extremely late deliveries has to be divided by this number.
SELECT TO_CHAR(order_placed_time, 'YYYY-MM') AS year_month,
SUM(CASE
WHEN EXTRACT(MINUTE
FROM (actual_delivery_time - predicted_delivery_time)) > 20 THEN 1
ELSE 0
END)/COUNT(DISTINCT delivery_id)*100
FROM delivery_orders;
6. Convert to FLOAT
The above get will show the division result as an integer. Namely, as zero because the number of extremely late deliveries is lower than total deliveries.
To get around this, you can use the CAST() function. We’ll use the double-colon (::), which is a shorthand for this function.
SELECT TO_CHAR(order_placed_time, 'YYYY-MM') AS year_month,
SUM(CASE
WHEN EXTRACT(MINUTE
FROM (actual_delivery_time - predicted_delivery_time)) > 20 THEN 1
ELSE 0
END)/COUNT(DISTINCT delivery_id)::FLOAT*100 AS perc_extremely_late
FROM delivery_orders;
7. Group by Month and Year
All now remains is to use the GROUP BY clause, and you got yourself the full answer to this DoorDash SQL interview question.
SELECT TO_CHAR(order_placed_time, 'YYYY-MM') AS year_month,
SUM(CASE
WHEN EXTRACT(MINUTE
FROM (actual_delivery_time - predicted_delivery_time)) > 20 THEN 1
ELSE 0
END)/COUNT(DISTINCT delivery_id)::FLOAT*100 AS perc_extremely_late
FROM delivery_orders
GROUP BY 1;
If you run this code in the widget, you’ll get the output asked of you.

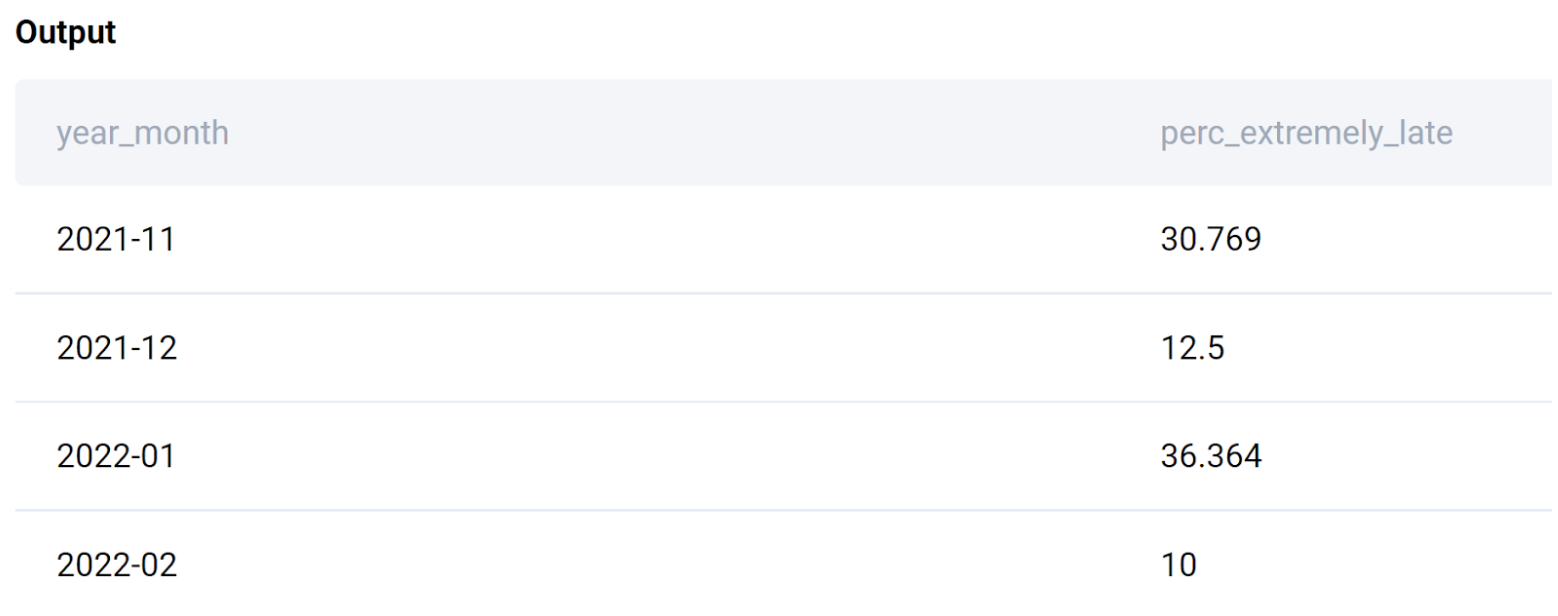
This result calls for attention as Doordash has some months with a high proportion of extremely late deliveries. The worst performance was in January 2022, with around 36% of the orders being extremely late. Likewise, November 2021 also had a troubling delivery performance at 31%. With this, the company management would want to investigate the root cause so that extremely late deliveries are kept to a minimum; otherwise, the long wait might be shunning away Doordash’s valuable customers!
5. Code Optimizations
Whether you’ll need this step or not depends on the code itself. Some codes don’t require optimization, while others do. Interviewers often like to ask for a code to be optimized. The interviewees’ ability to do that shows that they can write a code that works and an efficient one.
If you have more time left at the end of the interview, think about how you can improve the solution, even if the interviewer doesn’t ask you to optimize it.
Regarding our DoorDash question solution, we can improve it. A handy trick is to use the Common Table Expressions or CTEs.
If there are column transformations or the code is more complex, it can make your solution harder to understand and debug in case of errors. CTEs are especially helpful here!
By way of writing a CTE before aggregating the final results, we can optimize our solution.
WITH orders AS
(SELECT TO_CHAR(order_placed_time, 'YYYY-MM') AS year_month,
delivery_id,
CASE
WHEN EXTRACT(MINUTE
FROM (actual_delivery_time - predicted_delivery_time)) > 20 THEN 1
ELSE 0
END AS extremely_late
FROM delivery_orders)
SELECT year_month,
SUM(extremely_late)/COUNT(DISTINCT delivery_id)::FLOAT*100 AS perc_extremely_late
FROM orders
GROUP BY 1;
Run this code, and you’ll see it returns the same result as the first solution.
Conclusion
This medium-difficulty level DoorDash SQL interview question really showcases what the interviewers like to ask. We covered data aggregation, dealing with dates, data conversion, CASE statement, and grouping data. These are also among the popular SQL concepts tested at the job interview. There are more such DoorDash questions, so check them out on our post “Most Common DoorDash Data Scientist Interview Questions”. Try to solve some of them to see if what you learned here you can apply to other questions. And don’t forget to use the structured framework when answering questions at the interview. It really could make a difference for you!
Share


