Database Interview Questions

Categories:
 Written by:
Written by:Nathan Rosidi
We’ll show you the most common SQL concepts you need to know to solve database interview questions.
Today, the database is almost a synonym with SQL. Even though those are two separate things, the popularity of SQL for working with databases made it unimaginable to know databases without knowing SQL or vice versa.
In this article, we’ll solely focus on SQL coding questions. This is the single most important technical skill for anyone working with databases. Of course, it’s not the only skill, so you might want to find out the other skills needed to be a data scientist.
All other database interview questions can contain a little bit of this or a little bit of that, depending on the job description. But by covering the SQL questions, we’ll cover one technical skill that is, almost without exception, required in every data science job you take up. Be it data analyst, data engineer, or data scientist; you’ll have to know SQL.
We’re going to show you topics that represent the SQL knowledge required for every data science position.
How will we approach this? On the StrataScratch platform, the questions are also categorized in the topic family. We’ll use this to give you the most popular topics as a common ground for every data science job position.
The Seven Common Topics Tested in SQL Database Interview Questions
The topics most tested are:
- Aggregate functions and the DISTINCT clause
- WHERE clause
- GROUP BY clause
- Ranking rows and LIMIT clause
- Subqueries and CTEs
- JOINs
- Data organizing and pattern matching
We’ll shortly explain every concept, and then we’ll go through some SQL database interview questions that test it. These concepts are, of course, interweaving, so usually, several of those concepts are tested in one question, sometimes even all of them.

1. Aggregate Functions and the DISTINCT Clause
The aggregate functions, as the name suggests, aggregate data. How do they do that? They perform a calculation on a data set and return one row with a single value.
Maybe you don’t know they’re called that, but you probably used some of the most popular aggregate functions:
- SUM()
- COUNT()
- MIN()
- MAX()
- AVG()
For example, this easy Twitch database interview question requires both aggregate functions and GROUP BY knowledge:
Session Type Duration
Last Updated: February 2021
Calculate the average session duration (in seconds) for each session type.
Link to the question: https://platform.stratascratch.com/coding/2011-session-type-duration
Answer:
SELECT session_type,
avg(session_end -session_start) AS duration
FROM twitch_sessions
GROUP BY session_type;To solve this problem, you need to calculate the session duration using the AVG() function on a difference between session start and end, i.e., the session duration. Since you have to show data on a session type level, you’ll also have to use GROUP BY on a session_type column.
The code will return this result:
| session_type | duration |
|---|---|
| viewer | 1908 |
| streamer | 1310.818182 |
Aggregation of data is one of the main ways to organize and clean data, which is one of the data scientist’s jobs. A great way to practice aggregate functions is the Mode Analytics SQL tutorial on aggregate functions. Of course, you can solve some of the StrataScratch interview questions too.
For example, the Unique Users Per Client Per Month question by Microsoft:
Unique Users Per Client Per Month
Last Updated: March 2021
Write a query that returns the number of unique users per client for each month. Assume all events occur within the same year, so only month needs to be be in the output as a number from 1 to 12.
“Write a query that returns the number of unique users per client per month”
Or maybe a little more complex one by DoorDash:
“Write a query that returns the average order cost per hour during hours 3 PM -6 PM (15-18) in San Jose. For calculating time period use 'Customer placed order datetime' field. Earnings value is 'Order total' field. Order output by hour.”
One of the useful tools for data scientists is the DISTINCT clause, which selects only unique values. This is helpful when you have to report on events that can happen multiple times on various levels, e.g., a customer, order, day level. It is often used with aggregate functions, that’s why we’ll show it to you in this section.
To solve this Postmates database interview question, you’ll need the DISTINCT clause:
Customer Average Orders
Last Updated: February 2021
How many customers placed an order and what is the average order amount?
“How many customers placed an order and what is the average order amount?”
Link to the question: https://platform.stratascratch.com/coding/2013-customer-average-orders
Answer:
In this query, you’ll use the COUNT() to count the number of customers. You need the DISTINCT keyword to count every customer only once. There’s also an AVG() function for calculating the average order amount.
Here’s the output:
| count | avg |
|---|---|
| 5 | 139.22 |
2. WHERE Clause
In SQL, the WHERE clause serves as a data filter. Once the filtering criteria are set up using the WHERE clause, the SQL statement will return data that fulfill these criteria.
This Forbes database interview question asks you to filter data in a very straightforward way:
“Find companies in the financial sector based on Europe and Asia.”
Link to the question: https://platform.stratascratch.com/coding/9678-find-finance-companies-based-in-europe-and-asia
Answer:
SELECT
company
FROM forbes_global_2010_2014
WHERE
(continent = 'Asia' OR continent = 'Europe') AND
(sector = 'Financials');You’re working with only one table here. You have to set two criteria using the WHERE clause to get the correct result. The first one is the companies have to be from Europe or Asia. The second one is the company’s sector has to be financial.
Run the code, and you’ll get this output. We’re showing only several first rows here:
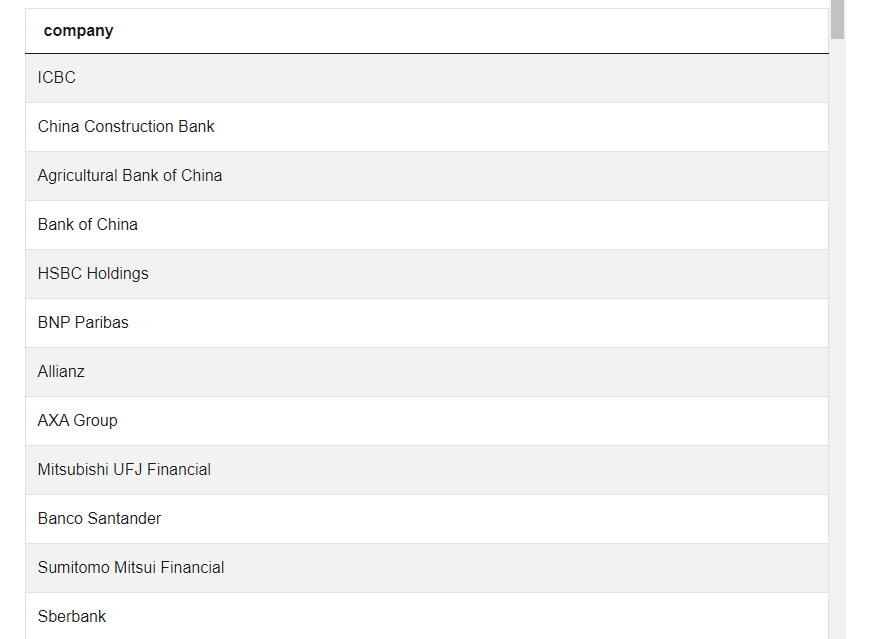
The WHERE clause can also be used with the SELECT statement too. One good example of how this is done is the Top Cool Votes database interview question by Yelp:
Top Cool Votes
Last Updated: March 2020
Find the review_text that received the highest number of cool votes.
Output the business name along with the review text with the highest number of cool votes.
Link to the question: https://platform.stratascratch.com/coding/10060-top-cool-votes
Answer:
SELECT business_name,
review_text
FROM yelp_reviews
WHERE cool =
(SELECT max(cool)
FROM yelp_reviews);This query simply selects all the business and review texts. However, we don’t need all this data, but only the business with the highest number of ‘cool’ votes. The criteria are stated in the WHERE clause, and the businesses with the highest number of ‘cool’ votes are selected with the help of the MAX() aggregate function in the SELECT statement.
And this is the output:
| business_name | review_text |
|---|---|
| Roka Akor | I hate to admit it, but it had been a long while since my last visit to Roka Akor. I deserve a hand slap. But last week, I had the perfect excuse to p |
| Lunardis | This is the nicest grocery store in the city. I actually met my wife at this grocery store while shopping for avocados. |
For practicing the WHERE clause, you can select from numerous StrataScratch questions that test that. It could be a rather simple one, like this one by Ring Central:
Inactive Free Users
Last Updated: January 2021
Return a list of users with status free who didn’t make any calls in Apr 2020.
Or it could be a hard one, as this one by Microsoft:
Most Popular Client For Calls
Last Updated: March 2021
Select the most popular client_id based on the number of users who individually have at least 50% of their events from the following list: 'video call received', 'video call sent', 'voice call received', 'voice call sent'.
3. GROUP BY Clause
The following important SQL interview topic for any aspiring data scientist for database interview questions is the GROUP BY clause. Because, aside from aggregating and filtering data, you’ll also have to group it. That’s exactly what the GROUP BY clause does: it groups all the rows with the same value in the column(s) you’re grouping by.
This clause is also often used with the aggregate functions. That’s why it’s important to know both.
To solve the following SQL database interview question from Airbnb, you’ll have to know the aggregate functions, the GROUP BY clause, and also the HAVING clause, which is also common with the GROUP BY:
3 Bed Minimum
Last Updated: January 2018
Find the average number of beds in each neighborhood that has at least 3 beds in total. Exclude listings where neighbourhood is missing or an empty string.
Output results along with the neighborhood name and sort the results based on the number of average beds in descending order.
Link to this database interview question: https://platform.stratascratch.com/coding/9627-3-bed-minimum
Answer:
SELECT neighbourhood,
avg(beds) AS n_beds_avg
FROM airbnb_search_details
WHERE neighbourhood IS NOT NULL
GROUP BY neighbourhood
HAVING sum(beds) >= 3
ORDER BY n_beds_avg DESC;This query selects the neighbourhood and calculates the average number of beds using the AVG() aggregate function. To get the average on a neighbourhood level, you need to group data by this column. This database interview question also requires that neighbourhoods shown should have at least three beds in total. To calculate this, you need the SUM() aggregate function put in the HAVING clause.
The HAVING clause is also used for filtering data along with the WHERE clause. The main difference is that WHERE is used before grouping data while HAVING is used after you’ve grouped the data.
Finally, the code above sorts data by the average number of beds in descending order. To do that, you need the ORDER BY clause. This nicely leads us to the fourth important SQL topic for database interview questions.
Before that, here’s the code output:
| neighbourhood | n_beds_avg |
|---|---|
| Pacific Palisades | 6 |
| Windsor Terrace | 5 |
| Hayes Valley | 5 |
| Redondo Beach | 5 |
| Hell's Kitchen | 4 |
| Rancho Palos Verdes | 4 |
| Manhattan Beach | 4 |
| Temple City | 4 |
| The Rockaways | 4 |
| Long Beach | 3.33 |
| Astoria | 3.33 |
| Westlake | 3.17 |
| Lincoln Park | 3 |
| West Los Angeles | 3 |
| Cow Hollow | 3 |
| Topanga | 3 |
| Malibu | 2.5 |
| 2.2 | |
| East Village | 2 |
| Alphabet City | 2 |
| Loop | 2 |
| East Harlem | 1.67 |
| Bedford-Stuyvesant | 1.67 |
| Mid-Wilshire | 1.67 |
| Harlem | 1.58 |
| Studio City | 1.5 |
| Bernal Heights | 1.5 |
| Williamsburg | 1.33 |
| Dorchester | 1 |
4. Ranking Rows and LIMIT Clause
Ranking rows is usually done by one of the following window functions:
- ROW_NUMBER()
- RANK()
- DENSE_RANK()
SQL window functions, by definition, are the SQL functions that use the set of data (or window) to perform the calculation. They can seem similar to the aggregate functions, but the main difference is the window functions don’t show the result in one row, but they leave the original data and return results in an additional column beside it.
The Ranking Most Active Guests database interview question by Airbnb is a good example:
Ranking Most Active Guests
Identify the most engaged guests by ranking them according to their overall messaging activity. The most active guest, meaning the one who has exchanged the most messages with hosts, should have the highest rank. If two or more guests have the same number of messages, they should have the same rank. Importantly, the ranking shouldn't skip any numbers, even if many guests share the same rank. Present your results in a clear format, showing the rank, guest identifier, and total number of messages for each guest, ordered from the most to least active.
Link to the question: https://platform.stratascratch.com/coding/10159-ranking-most-active-guests
Answer:
SELECT
DENSE_RANK() OVER(ORDER BY sum(n_messages) DESC) as ranking,
id_guest,
sum(n_messages) as sum_n_messages
FROM airbnb_contacts
GROUP BY id_guest
ORDER BY sum_n_messages DESC;This query uses the DENSE_RANK() to rank guests by the sum of number of their messages. Along with rank, the output will show the guest ID and the total number of messages per guest. The result will be shown by the number of messages in descending order.
Here it is:
| ranking | id_guest | sum_n_messages |
|---|---|---|
| 1 | 882f3764-05cc-436a-b23b-93fea22ea847 | 20 |
| 1 | 62d09c95-c3d2-44e6-9081-a3485618227d | 20 |
| 2 | b8831610-31f2-4c58-8ada-63b3601ca476 | 17 |
| 2 | 91c2a883-04e3-4bbb-a7bb-620531318ab1 | 17 |
| 3 | bdaf2e68-86dd-40d9-a5a1-9cc95ea25d91 | 16 |
| 3 | 6133fb99-2391-4d4b-a077-bae40581f925 | 16 |
| 4 | d328a4a0-df5f-4851-a864-a8845b45c1e0 | 15 |
| 4 | 94139517-e7e9-4afb-8b5d-bb6f306bf751 | 15 |
| 4 | 9b145027-2723-4c5f-988c-b5118c899912 | 15 |
| 5 | 136c10f8-af53-4e5a-a5b3-d9c9c495b166 | 13 |
| 5 | 6c541a87-d864-4de8-ae05-70ae57b50976 | 13 |
| 6 | 5dacf820-a573-4ce2-9fd8-0d7ed979b822 | 11 |
| 6 | 8375dde4-0de9-402c-8833-2127c1504601 | 11 |
| 7 | b2fda15a-89bb-4e6e-ae81-8b21598e2482 | 10 |
| 7 | 6a8cf97f-8a77-4b55-b79a-b560bca414a4 | 10 |
| 7 | bd8f3dd6-fecc-479a-a88f-1d0049600e9f | 10 |
| 8 | 845e3c1d-6c06-4ef2-ade5-7eecefb56fbe | 9 |
| 8 | 29ef2346-5fda-45d7-b4ed-eb34967a62b3 | 9 |
| 8 | 5ed478e0-eae9-4537-826a-04ec779c1fd2 | 9 |
| 8 | 125242de-91b4-43bd-a926-75ae4b7a9322 | 9 |
| 9 | 14f943bb-74e9-458b-be55-203dc7220688 | 8 |
| 9 | d418a1ab-b181-40a7-90fe-7216e40dc354 | 8 |
| 9 | aa9cf5bf-5667-4212-8018-1cb8beee530e | 8 |
| 9 | 25cfc206-89aa-4e63-b2f4-3cbb8631d9fb | 8 |
| 9 | 7e309181-e61e-426b-baef-dd031d5660d3 | 8 |
| 9 | 5c4b64d5-4869-4a02-b36c-c451758559e0 | 8 |
| 9 | 67aece73-e112-4e9e-9e05-8a2a94b003b9 | 8 |
| 9 | 02f0a750-34da-4268-94e8-f1a371f0460e | 8 |
| 9 | ca6a9321-d7f9-42e9-aeb1-5d1832034da0 | 8 |
| 9 | 70180687-5888-4946-9578-83ab678cb997 | 8 |
| 10 | b6a8b1f9-5b40-4edd-91f3-ee522b0f9e5b | 7 |
| 10 | 673af82f-6a4d-4fd5-8485-4459670da9bc | 7 |
| 10 | f4602827-8672-4545-8887-43702f8c7ecc | 7 |
| 11 | eaa8118b-aba6-4c25-96cd-c72f01d6b063 | 6 |
| 11 | fad1a097-a511-4f44-a603-6a271c1f159e | 6 |
| 11 | 8af13d02-bd2c-40fd-afd7-e4fe3a6a622e | 6 |
| 12 | 8d23aa41-c77c-4bbe-98bc-66abecfefbfe | 5 |
| 12 | bb490ede-8a70-4d61-a2e8-625855a393e2 | 5 |
| 12 | eda96881-7b23-413a-9f6f-b45dc9fe2a5b | 5 |
| 12 | 3e6c2466-74fe-44c0-a6f3-dda79755d30a | 5 |
| 12 | d61d88ae-7910-4832-8116-aab4603ab3b0 | 5 |
| 12 | 176a2fb8-1de3-483a-92a3-34a826a91f5a | 5 |
| 12 | 72f07b78-99e1-46ac-8452-19dd2053eca3 | 5 |
| 12 | 2889fccc-37ab-4a66-8d64-41b31314c7fc | 5 |
| 12 | 4ec2c8ec-9325-4b66-a370-820a56fbd1a3 | 5 |
| 12 | d528e24b-7c1f-446f-9bb0-a4ecb77c3acd | 5 |
| 12 | 86b39b70-965b-479d-a0b0-719b195acea2 | 5 |
| 13 | 3e6fbc52-3e54-4a74-9ca1-7ce13048aab7 | 4 |
| 13 | 6cbb33d1-6ecc-4f74-8b6a-a43d07d484b6 | 4 |
| 13 | e3cdd90a-8097-4220-9722-2b914d761a84 | 4 |
| 13 | 679d857b-08b8-4748-b703-86735aa42296 | 4 |
| 13 | f54989cf-459b-409d-be6a-9534a53cc4a9 | 4 |
| 13 | a09bf912-b21d-4859-b194-8512c30695f6 | 4 |
| 13 | 3c3ec192-acd7-4c91-8e82-18cff7d859ec | 4 |
| 13 | 0f4ea370-702c-4f08-a00d-98e67c2a3574 | 4 |
| 13 | a1a53da7-7a33-4693-8568-1d7f2cd32e31 | 4 |
| 13 | a03f86ca-5c44-4e66-8695-71c380cfc48b | 4 |
| 13 | 70a2c590-f854-4ca6-adf5-03fc081cfddf | 4 |
| 13 | 20418fda-ffb2-46a3-9581-863725497c05 | 4 |
| 13 | 1a66fe1c-fea6-4ec6-96c4-3ea3e0c7815e | 4 |
| 13 | b91e6323-bd26-4172-9070-1a4993fdc397 | 4 |
| 13 | e0d259e6-1b67-4964-a6dc-e8a8c69d3e01 | 4 |
| 13 | a9f7ffb1-4970-492b-b448-4bd9d0fbeef3 | 4 |
| 13 | 924f864f-db83-4945-9a65-cf42a657ca68 | 4 |
| 14 | 2acf0e64-9da0-47c9-b0f9-1eceab379f84 | 3 |
| 14 | f1877c99-430e-41e1-818a-713ff82f09da | 3 |
| 14 | 598f8459-96f6-4400-8bce-1474757dd589 | 3 |
| 14 | ebe81cf8-6037-43f2-81d2-fd386f5da74f | 3 |
| 14 | 9a45a950-b4f7-4f16-abe6-f9286abf2641 | 3 |
| 14 | 9e5e2865-f257-4d19-9f79-9388ae925ad7 | 3 |
| 14 | 1759c05e-f12a-4eaa-8059-3bcaca443c88 | 3 |
| 14 | c0075f4f-0cb0-489b-9f12-bf1dff573488 | 3 |
| 14 | e8e41881-d3bf-4f1e-b55e-6052eae23ef6 | 3 |
| 14 | b8285e97-9f11-4aec-bb05-e21f612ee41f | 3 |
| 14 | ffc234be-ca13-4bcb-a472-1c136b800891 | 3 |
| 15 | f5ba8f82-682e-4ec9-9c6e-cedc2cd628ca | 2 |
| 15 | 996d1871-8986-481b-8bbf-1a1420c68c90 | 2 |
| 15 | 15eb6f98-98ee-491e-8eeb-b5e2c61bfd8a | 2 |
| 15 | 4de8c8ea-728a-467a-aa69-4800e8880c95 | 2 |
| 15 | b3e35a8f-5503-4d78-adb8-7693097dfca7 | 2 |
| 15 | 67c4e87c-8a8f-4da4-a965-b89c9d74666b | 2 |
| 15 | 425aa1ed-82ab-4ecf-b62f-d61e1848706d | 2 |
| 15 | 4995debc-b753-4401-b556-a2bcbb897eba | 2 |
| 15 | 18d343e3-0ef0-4bb7-8cd9-b83d3fbbb82f | 2 |
| 15 | 37a63847-b09a-4f32-81a5-97cfb8e84c6d | 2 |
| 15 | be8a5e0c-e3fb-4517-a799-e1ed8a05b6e6 | 2 |
| 15 | e764ddb5-126e-4474-8e4e-4bdc330b51d1 | 2 |
| 15 | 6cb23070-821b-467d-b4d0-af04645a0703 | 2 |
| 15 | eb3500c2-b0b9-4753-8ab3-3fad4d5777f1 | 2 |
| 15 | 0187b377-ad1c-4da4-8a17-568b2c9098f4 | 2 |
| 15 | e079182c-7628-4f49-8301-29ff8b4938ec | 2 |
| 15 | 0a8e121b-c09c-4de1-abcc-81bce87de29e | 2 |
| 15 | 126ed661-fa20-4041-ac16-ec118bbcce3b | 2 |
| 15 | 7424d151-b449-40e1-9e8f-c258289c581c | 2 |
| 16 | b11cd744-101d-409b-9a55-7e151f2e79d5 | 1 |
| 16 | ea445eea-3fac-4edd-b1d6-569f57f6abe4 | 1 |
LIMIT is also used for ranking rows. Its primary function is to limit the number of rows shown in the output. Combine it with ORDER BY, and you have a great tool for showing top N values, which is often in reporting.
When speaking of using LIMIT, this database interview question from Yelp is a good showcase of its use:
Most Checkins
Find the top 5 businesses with the most check-ins. Output the business id along with the number of check-ins.
Link to the question: https://platform.stratascratch.com/coding/10053-most-checkins
Answer:
SELECT
business_id,
sum(checkins) AS n_checkins
FROM yelp_checkin
GROUP BY
business_id
ORDER BY
n_checkins DESC
LIMIT 5;
Again, you have to know aggregate functions here. The SUM() function, more specifically, to sum the number of check-ins. Since you want your data on a business level, you’ll have to use GROUP BY. Then you order data according to the number of check-ins in descending order. To get the top five, you just need to limit the output to the first five rows.
And there it is:
| business_id | n_checkins |
|---|---|
| 4k3RlMAMd46DZ_JyZU0lMg | 137 |
| TkEMlu88OZn9TKZyeY9CJg | 39 |
| 4p6Wce7Ed707QS2-yQkvZw | 31 |
| Ehy00JWQixgoXzisVKhvag | 22 |
| ujgpePdD8Q-fP1mPFnw0Qw | 17 |
5. Subqueries and CTEs
For more complex queries, it’s often necessary to know subqueries or CTEs, ideally both.
A subquery is a query within a larger query. It can usually be found in another SELECT statement or in the WHERE clause.
Let’s see how subqueries work by answering the database interview question from Spotify. Aside from subqueries, you also need to know aggregate functions, the WHERE, GROUP BY, and ORDER BY clauses.
Top 10 Songs
Find the number of unique songs of each artist which were ranked among the top 10 over the years. Order the result based on the number of top 10 ranked songs in descending order.
Link to the question: https://platform.stratascratch.com/coding/9743-top-10-songs
Answer:
SELECT
artist,
count(distinct song_name) AS top10_songs_count
FROM
(SELECT
artist,
song_name
FROM billboard_top_100_year_end
WHERE
year_rank <= 10
) temporary
GROUP BY
artist
ORDER BY
top10_songs_count DESC;This query selects artists and counts the number of distinct songs. It does that from a subquery. This subquery searches for songs that were among the top 10 over the years. After that, the result is grouped on an artist level and sorted by the number of distinct songs in descending order.
If you like Elvis Presley, you’ll be happy to see him on top of our result:
| artist | top10_songs_count |
|---|---|
| Elvis Presley | 9 |
| Mariah Carey | 7 |
| Usher | 6 |
| Whitney Houston | 5 |
| Beatles | 5 |
| Elton John | 5 |
| Toni Braxton | 4 |
| Boyz II Men | 4 |
| TLC | 4 |
| Madonna | 4 |
| Rod Stewart | 4 |
| Bee Gees | 4 |
| Katy Perry | 4 |
| Paul McCartney | 4 |
| Michael Jackson | 4 |
| Beyonce | 4 |
| Rihanna | 3 |
| Paula Abdul | 3 |
| Lady Gaga | 3 |
| Diana Ross | 3 |
| Ludacris | 3 |
| Gwen Stefani | 3 |
| Lionel Richie | 3 |
| Ace Of Base | 3 |
| The Black Eyed Peas | 3 |
| Nelly | 3 |
| Kelly Clarkson | 3 |
| En Vogue | 3 |
| Andy Gibb | 3 |
| Dean Martin | 3 |
| John Oates | 3 |
| Maroon 5 | 3 |
| Alicia Keys | 3 |
| Temptations | 3 |
| matchbox twenty | 3 |
| Daryl Hall | 3 |
| Kanye West | 3 |
| Taio Cruz | 2 |
| Color Me Badd | 2 |
| Akon | 2 |
| Captain and Tennille | 2 |
| Bette Midler | 2 |
| Perry Como | 2 |
| Bobby Vinton | 2 |
| Phil Collins | 2 |
| Timbaland | 2 |
| John Cougar | 2 |
| Rolling Stones | 2 |
| Ashanti | 2 |
| Mac Davis | 2 |
| Macklemore | 2 |
| Puff Daddy | 2 |
| T-Pain | 2 |
| Mama's and The Papa's | 2 |
| Train | 2 |
| Association | 2 |
| Wham! | 2 |
| Justin Timberlake | 2 |
| Righteous Brothers | 2 |
| Wings | 2 |
| R. Kelly | 2 |
| Celine Dion | 2 |
| Roberta Flack | 2 |
| Everly Brothers | 2 |
| 50 Cent | 2 |
| Barbra Streisand | 2 |
| John Denver | 2 |
| Monica | 2 |
| Roy Orbison | 2 |
| Ryan Lewis | 2 |
| Monkees | 2 |
| Beach Boys | 2 |
| Savage Garden | 2 |
| Mr. Mister | 2 |
| Sean Paul | 2 |
| Fergie | 2 |
| Fleetwoods | 2 |
| Nelly Furtado | 2 |
| Flo Rida | 2 |
| Chicago | 2 |
| Simon and Garfunkel | 2 |
| Bobby Darin | 2 |
| Nicki Minaj | 2 |
| Jackson 5 | 2 |
| Bruno Mars | 2 |
| Four Tops | 2 |
| Olivia Newton-John | 2 |
| Sly and The Family Stone | 2 |
| Snoop Dogg | 2 |
| Chris Brown | 2 |
| Frankie Valli | 2 |
| Janet | 2 |
| OutKast | 2 |
| Pat Boone | 2 |
| Janet Jackson | 2 |
| Christina Aguilera | 2 |
| Chubby Checker | 2 |
| Jay-Z | 2 |
| Supremes | 2 |
| Donna Summer | 2 |
| Survivor | 2 |
| Ciara | 2 |
| Bryan Adams | 2 |
| Fifth Dimension | 1 |
| Florida Georgia Line | 1 |
| Foreigner | 1 |
| Foundations | 1 |
| Four Seasons | 1 |
| Frankie Avalon | 1 |
| Frank Sinatra | 1 |
| Freda Payne | 1 |
| Freddy Fender | 1 |
| fun. | 1 |
| Gale Garnett | 1 |
| Gary Wright | 1 |
| George Harrison | 1 |
| George Michael | 1 |
| Gilbert O'Sullivan | 1 |
| Glen Campbell | 1 |
| Gloria Gaynor | 1 |
| Gnarls Barkley | 1 |
| Gogi Grant | 1 |
| GoonRock | 1 |
| Gotye | 1 |
| Grand Funk Railroad | 1 |
| Green Day | 1 |
| Gregory Abbott | 1 |
| Guess Who | 1 |
| Guns N' Roses | 1 |
| Guy Mitchell | 1 |
| Hayley Williams | 1 |
| Heart | 1 |
| Herb Alpert | 1 |
| Herman's Hermits | 1 |
| Hi-Five | 1 |
| Highwaymen | 1 |
| Hoobastank | 1 |
| Hot | 1 |
| Hugo Montenegro | 1 |
| Human League | 1 |
| Imagine Dragons | 1 |
| Impressions | 1 |
| INXS | 1 |
| Irene Cara | 1 |
| James Blunt | 1 |
| James Ingram | 1 |
| Jamie Foxx | 1 |
| Janelle Monae | 1 |
| Ja Rule | 1 |
| Jason Mraz | 1 |
| Jennifer Lopez | 1 |
| Jewel | 1 |
| J. Frank Wilson and The Cavaliers | 1 |
| J. Geils Band | 1 |
| Jim Croce | 1 |
| Jimmy Dorsey | 1 |
| Jimmy Gilmer and The Fireballs | 1 |
| Jimmy Jones | 1 |
| Jim Reeves | 1 |
| Jive Five | 1 |
| Joan Jett and The Blackhearts | 1 |
| Joe Dowell | 1 |
| Joe Tex | 1 |
| John Lennon | 1 |
| Johnnie Taylor | 1 |
| Johnny Horton | 1 |
| Johnny Preston | 1 |
| Johnny Rivers | 1 |
| Jon Bon Jovi | 1 |
| Jon Secada | 1 |
| Jordin Sparks Duet With Chris Brown | 1 |
| Kay Starr | 1 |
| K-Ci and JoJo | 1 |
| Ke$ha | 1 |
| Keith Sweat | 1 |
| Kelly Rowland | 1 |
| Kenny Loggins | 1 |
| Kenny Nolan | 1 |
| Kenny Rogers | 1 |
| Kid Rock | 1 |
| Kiki Dee | 1 |
| Kimbra | 1 |
| Kim Carnes | 1 |
| Klymaxx | 1 |
| Knack | 1 |
| Kool and The Gang | 1 |
| Krayzie Bone | 1 |
| Kris Kristofferson | 1 |
| Kris Kross | 1 |
| Lady Antebellum | 1 |
| Lauren Bennett | 1 |
| LeAnn Rimes | 1 |
| Lenny Kravitz | 1 |
| Leona Lewis | 1 |
| Les Baxter | 1 |
| Lifehouse | 1 |
| Lil Jon | 1 |
| Lil Wayne | 1 |
| Linkin Park | 1 |
| Lipps, Inc. | 1 |
| Lisa Loeb | 1 |
| Little Eva | 1 |
| Little Stevie Wonder | 1 |
| Lloyd Price | 1 |
| LMFAO | 1 |
| Lonestar | 1 |
| Los Del Rio | 1 |
| Louis Armstrong | 1 |
| Love Unlimited Orchestra | 1 |
| Lulu | 1 |
| Manhattans | 1 |
| Mario | 1 |
| Mario Winans | 1 |
| Mark Dinning | 1 |
| Mark Morrison | 1 |
| Marvin Gaye | 1 |
| Mary MacGregor | 1 |
| Mary Wells | 1 |
| Melanie | 1 |
| Men At Work | 1 |
| MFSB | 1 |
| Michael McDonald | 1 |
| Michael Sembello | 1 |
| Milli Vanilli | 1 |
| Missy Elliott | 1 |
| Montell Jordan | 1 |
| Mr. Acker Bilk | 1 |
| Nancy Sinatra | 1 |
| Natasha Bedingfield | 1 |
| Nayer | 1 |
| Neil Sedaka | 1 |
| Nelson Riddle | 1 |
| Next | 1 |
| Ne-Yo | 1 |
| Nickelback | 1 |
| Nilsson | 1 |
| Nine Stories | 1 |
| Olivia | 1 |
| One Direction | 1 |
| OneRepublic | 1 |
| Osmonds | 1 |
| Otis Redding | 1 |
| Patsy Cline | 1 |
| Patti Austin | 1 |
| Patti Labelle | 1 |
| Paula Cole | 1 |
| Paul and Paula | 1 |
| Paul Anka | 1 |
| Paul Mauriat | 1 |
| Paul McCoy | 1 |
| Paul Simon | 1 |
| P. Diddy | 1 |
| Peaches and Herb | 1 |
| Percy Faith | 1 |
| Perez Prado | 1 |
| Petey Pablo | 1 |
| Petula Clark | 1 |
| Pharrell | 1 |
| Pink Floyd | 1 |
| Pitbull | 1 |
| Plain White T's | 1 |
| Platters | 1 |
| Player | 1 |
| Poison | 1 |
| Police | 1 |
| Prince | 1 |
| Puddle Of Mudd | 1 |
| Queen | 1 |
| Raiders | 1 |
| Rare Earth | 1 |
| Rascals | 1 |
| Ray Charles | 1 |
| Ray Dalton | 1 |
| Ray Parker Jr. | 1 |
| Ray Stevens | 1 |
| Real McCoy | 1 |
| Redbone | 1 |
| Red Hot Chili Peppers | 1 |
| REO Speedwagon | 1 |
| Rick Astley | 1 |
| Rick Springfield | 1 |
| Ricky Martin | 1 |
| Rita Coolidge | 1 |
| Robbie Nevil | 1 |
| Robert John | 1 |
| Robert Palmer | 1 |
| Robin Thicke | 1 |
| Roxette | 1 |
| Sammy Davis Jr. | 1 |
| Sam The Sham and The Pharaohs | 1 |
| Sara Bareilles | 1 |
| Seal | 1 |
| Sensations | 1 |
| Sgt. Barry Sadler | 1 |
| Shai | 1 |
| Shakira | 1 |
| Shania Twain | 1 |
| Shelley Fabares | 1 |
| Sheryl Crow | 1 |
| Shirelles | 1 |
| Silk | 1 |
| Sinead O'Connor | 1 |
| Sir Mix-a-Lot | 1 |
| Sixpence None The Richer | 1 |
| Skeeter Davis | 1 |
| Sleepy Brown | 1 |
| Slim Thug | 1 |
| Snow | 1 |
| Sonny James | 1 |
| Spice Girls | 1 |
| Starship | 1 |
| Static Major | 1 |
| Steve Miller Band | 1 |
| Steve Winwood | 1 |
| Stevie Wonder | 1 |
| Sting | 1 |
| String-a-longs | 1 |
| Sugar Ray | 1 |
| Surface | 1 |
| SWV | 1 |
| Tab Hunter | 1 |
| Tag Team | 1 |
| Taylor Swift | 1 |
| Tears For Fears | 1 |
| Terror Squad | 1 |
| Terry Jacks | 1 |
| The All-American Rejects | 1 |
| The Calling | 1 |
| Thelma Houston | 1 |
| The Miracles | 1 |
| The Pussycat Dolls | 1 |
| The Wanted | 1 |
| Three Dog Night | 1 |
| T.I. | 1 |
| Tiffany | 1 |
| Timmy T | 1 |
| Tina Turner | 1 |
| Tom Jones | 1 |
| Tommy Edwards | 1 |
| Tommy James and The Shondells | 1 |
| Tommy Roe | 1 |
| Tony Orlando and Dawn | 1 |
| Tony Rich Project | 1 |
| Tracy Chapman | 1 |
| Turtles | 1 |
| UB40 | 1 |
| Vanessa Carlton | 1 |
| Vanessa Williams | 1 |
| Van Halen | 1 |
| Village People | 1 |
| Village Stompers | 1 |
| Walter Murphy and The Big Apple Band | 1 |
| Wanz | 1 |
| Wayne Newton | 1 |
| We Five | 1 |
| Whitesnake | 1 |
| Wilbert Harrison | 1 |
| Wild Cherry | 1 |
| will.i.am | 1 |
| Will To Power | 1 |
| Wilson Phillips | 1 |
| Wiz Khalifa | 1 |
| Wreckx-N-Effect | 1 |
| Wyclef Jean | 1 |
| Yes | 1 |
| Young Jeezy | 1 |
| Young Rascals | 1 |
| 3 Doors Down | 1 |
| Yung Joc | 1 |
| Aaliyah | 1 |
| Adele | 1 |
| Afrojack | 1 |
| a-ha | 1 |
| Alan O'Day | 1 |
| All-4-One | 1 |
| Amy Grant | 1 |
| ? and The Mysterians | 1 |
| Anita Baker | 1 |
| Anita Ward | 1 |
| Archie Bell and The Drells | 1 |
| Archies | 1 |
| A Taste Of Honey | 1 |
| Baauer | 1 |
| Bangles | 1 |
| Belinda Carlisle | 1 |
| Bell Biv Devoe | 1 |
| Bill Withers | 1 |
| Billy Idol | 1 |
| Billy Joel | 1 |
| Billy Preston | 1 |
| Billy Vaughn | 1 |
| B.J. Thomas | 1 |
| Blondie | 1 |
| B.o.B | 1 |
| Bobby Brown | 1 |
| Bobby Gentry | 1 |
| Bobby Goldsboro | 1 |
| Bobby Lewis | 1 |
| Bob Seger | 1 |
| Bone Thugs-N-Harmony | 1 |
| Bon Jovi | 1 |
| Bonnie Tyler | 1 |
| Box Tops | 1 |
| Brandy and Monica | 1 |
| Breathe | 1 |
| Brenda Lee | 1 |
| Britney Spears | 1 |
| Browns | 1 |
| Bruce Hornsby and The Range | 1 |
| Busta Rhymes | 1 |
| Calvin Harris | 1 |
| Carly Rae Jepsen | 1 |
| Carly Simon | 1 |
| Carole King | 1 |
| Carpenters | 1 |
| Carrie Underwood | 1 |
| Cascades | 1 |
| C+C Music Factory | 1 |
| Cee Lo Green | 1 |
| Chaka Khan | 1 |
| Chamillionaire | 1 |
| Champs | 1 |
| Cher | 1 |
| Chic | 1 |
| Chiffons | 1 |
| Chingy | 1 |
| Colby O'Donis | 1 |
| Commodores | 1 |
| Coolio | 1 |
| Cream | 1 |
| Culture Club | 1 |
| Daniel Powter | 1 |
| David Bowie | 1 |
| David Rose | 1 |
| David Seville | 1 |
| Dawn | 1 |
| Debby Boone | 1 |
| Deborah Cox | 1 |
| Dee Clark | 1 |
| Dee Dee Sharp | 1 |
| Del Shannon | 1 |
| Destiny's Child | 1 |
| Diamonds | 1 |
| Dido | 1 |
| Dionne and Friends | 1 |
| Dire Straits | 1 |
| Dolly Parton | 1 |
| Domenico Modugno | 1 |
| Don McLean | 1 |
| Donna Lewis | 1 |
| Donny Osmond | 1 |
| Doors | 1 |
| Doris Day | 1 |
| Eagles | 1 |
| Earth, Wind and Fire | 1 |
| Eddie Murphy | 1 |
| Eddie Rabbitt | 1 |
| Edwin Starr | 1 |
| Ellie Goulding | 1 |
| EMF | 1 |
| Eminem | 1 |
| Emotions | 1 |
| Enya | 1 |
| Eric Clapton | 1 |
| Eurythmics | 1 |
| Evanescence | 1 |
| Eve | 1 |
| Exile | 1 |
| Extreme | 1 |
| Faith Evans | 1 |
| Fat Joe | 1 |
CTE stands for Common Table Expression, and it has a similar function to subquery. They are used to write more complex queries and to translate calculation logic that has several steps to a database language.
This database interview question by Yelp is a good start for showing you how CTE works:
Find the top 5 cities with the most 5 star businesses
Find all cities ranked in the top 5 by number of 5-star businesses, using standard competition ranking where ties receive the same rank and the following rank is skipped.
The output should include the city name and the total count of 5-star businesses in that city, considering both open and closed businesses.
Link to the question: https://platform.stratascratch.com/coding/10148-find-the-top-10-cities-with-the-most-5-star-businesses
Answer:
WITH cte_5_stars AS
(SELECT city,
count(*) AS count_of_5_stars,
rank() over(
ORDER BY count(*) DESC) AS rnk
FROM yelp_business
WHERE stars = 5
GROUP BY 1)
SELECT city,
count_of_5_stars
FROM cte_5_stars
WHERE rnk <= 5
ORDER BY count_of_5_stars DESC;Like any CTE, this one is initiated by the keyword WITH. The SELECT statement select cities with five stars, then it counts them and ranks them. The next SELECT statement references the CTE to select only those cities where their rank is five or lower, i.e., outputs the top five cities.
These are the top cities:
| city | count_of_5_stars |
|---|---|
| Phoenix | 5 |
| Toronto | 4 |
| Las Vegas | 4 |
| Edinburgh | 2 |
| Gilbert | 2 |
| Urbana | 2 |
| Scottsdale | 2 |
| Madison | 2 |
6. JOINs
For anyone who wants to use more than one table in a database, which is probably most users, knowing JOINs is essential. It’s due to the database logic, where the database is normalized, and data is separated in multiple tables.
One of the data scientists’ main jobs is to work with raw data and transform it into formats suitable for others. To do that, they need to combine multiple tables. Without JOINs, they wouldn’t be able to do that. If you’re not sure about the difference between various data science jobs, this guide through 14 different data science job positions will make everything clear.
This Amazon database interview question tests JOINs nicely. Along with that, you’ll also have to show knowledge of aggregate functions, WHERE, GROUP BY, and HAVING clauses, as well as subqueries.
Highest Cost Orders
Last Updated: May 2019
Find the customers with the highest daily total order cost between 2019-02-01 and 2019-05-01. If a customer had more than one order on a certain day, sum the order costs on a daily basis. Output each customer's first name, total cost of their items, and the date. If multiple customers tie for the highest daily total on the same date, return all of them.
For simplicity, you can assume that every first name in the dataset is unique.
Link to this database interview question: https://platform.stratascratch.com/coding/9915-highest-cost-orders
Answer:
SELECT first_name,
sum(total_order_cost) AS total_order_cost,
order_date
FROM orders o
LEFT JOIN customers c ON o.cust_id = c.id
WHERE order_date BETWEEN '2019-02-1' AND '2019-05-1'
GROUP BY first_name,
order_date
HAVING sum(total_order_cost) =
(SELECT max(total_order_cost)
FROM
(SELECT sum(total_order_cost) AS total_order_cost
FROM orders
WHERE order_date BETWEEN '2019-02-1' AND '2019-05-1'
GROUP BY cust_id,
order_date) b);The query uses the SUM() aggregate function to calculate the total order cost. To get all data you need, you have to LEFT JOIN two tables. Data is filtered on order date using the WHERE clause. Next, data is grouped by the customer’s first name and order date. You need to output the customer with the highest daily total order. To do that, you need the HAVING clause to get data where the sum of the order costs per customer and per date is equal to the order maximum. This is where you need another aggregate functions, which is MAX().
Here’s the output:
| first_name | total_order_cost | order_date |
|---|---|---|
| Jill | 275 | 2019-04-19 |
| Mark | 275 | 2019-04-19 |
Check out our post "How to Join 3 or More Tables in SQL" where we talk about using this commonly required SQL concept.
7. Data Organizing and Pattern Matching
One of the data scientists' jobs is to organize, clean, and analyze data. During this analysis, they’ll usually try to find some patterns in the data. You might ask "isn’t that something a data engineer does?". Well, yes and no. To understand the difference between data scientists and data engineers, have a look at the blog post comparing these two careers.
One good example of covering organizing data is this database interview question by the City of San Francisco:
Classify Business Type
Last Updated: May 2018
Classify each business as either a restaurant, cafe, school, or other.
• A restaurant should have the word 'restaurant' in the business name. This includes common international or accented variants, such as “restaurante”, “restauranté”, etc. • A cafe should have either 'cafe', 'café', or 'coffee' in the business name. • A school should have the word 'school' in the business name. • All other businesses should be classified as 'other'. • Ensure each business name appears only once in the final output. If multiple records exist for the same business, retain only one unique instance.
The final output should include only the distinct business names and their corresponding classifications.
Link to the question: https://platform.stratascratch.com/coding/9726-classify-business-type
Answer:
SELECT distinct business_name,
CASE
WHEN business_name ilike any(array['%school%']) THEN 'school'
WHEN lower(business_name) like any
(array['%restaurant%']) THEN 'restaurant'
WHEN lower(business_name) like any
(array['%cafe%', '%café%', '%coffee%']) THEN 'cafe'
ELSE 'other'
END AS business_type
FROM sf_restaurant_health_violations;This question requires you to clean data and organize it into business types. There are specific criteria needed for that, as stated in the CASE WHEN statement.
Your organized data will look like this:
| business_name | business_type |
|---|---|
| Starbucks | other |
| TAWAN'S THAI FOOD | other |
| Burger King 4525 | other |
| Tacos San Buena | other |
| BLOWFISH SUSHI | other |
| Tai Hing Inc. | other |
| ROYAL GROUND COFFEE | cafe |
| China Fun Express | other |
| Home Plate | other |
| Samiramis Imports | other |
| Modern Thai Inc. | other |
| WING HING RESTAURANT | restaurant |
| Salem Grocery | other |
| DENMAN MIDDLE SCHOOL | school |
| Sam Rong Cafe | cafe |
| Hilton Financial District- Restaurant Seven Fifty | restaurant |
| Batter Bakery | other |
| PRESIDIO THEATRE | other |
| Jay's Cheesesteak | other |
| Extreme Pizza | other |
| Events Management @ Legion of Honor | other |
| Contrada | other |
| The Castro Republic | other |
| GOLDEN PRODUCE | other |
| Subway #36339 | other |
| Cathead's BBQ | other |
| The Lord George | other |
| LOS PANCHOS | other |
| Golden Wok | other |
| TSING TAO RESTAURANT | restaurant |
| Starbucks Coffee Co | cafe |
| IRVING PIZZA | other |
| Pho Express | other |
| Wines of California Wine Bar | other |
| Pollo Campero | other |
| Del Popolo LLC | other |
| Gateway High/Kip Schools | school |
| Carbon Grill | other |
| Rock Japanese Cuisine | other |
| Howard & 6th Street Food Market Inc. | other |
| Poke Kana | other |
| Castro Street Chevron | other |
| Champa Garden | other |
| Harvest Urban Market | other |
| ABSINTHE PASTRY | other |
| STARBUCKS COFFEE CO. #603 | cafe |
| Earthbar | other |
| Miller's East Coast Deli | other |
| Annie's Hot Dogs & Pretzels | other |
| Let's Be Frank | other |
| T & L FOOD MARKET | other |
| Westfield Food Court Scullery | other |
| Ramzi's Cafe | cafe |
| Andersen Bakery | other |
| MONGKOK DIM SUM & RESTAURANT | restaurant |
| Laguna Café | cafe |
| Old Siam Thai Restaurant | restaurant |
| PASITA'S BAKERY | other |
| T & L Liquor Store Inc. | other |
| Mixt Greens | other |
| India Clay Oven Restaurant and Bar | restaurant |
| Duboce Park Cafe | cafe |
| Roxanne Cafe | cafe |
| Dip, LLC | other |
| Iza Ramen | other |
| Rotee Express | other |
| Cafe Insalata | cafe |
| Azalina's | other |
| Chez Julien | other |
| A La Turca | other |
| Tropisueño | other |
| Belly Burger | other |
| Souvla | other |
| House of Xian Dumpling | other |
| Pica Pica | other |
| Hans Coffee Shop | cafe |
| Seal Rock Inn Restaurant | restaurant |
| Cadillac Market | other |
| Crepe and Brioche, Inc. | other |
| LA VICTORIA BAKERY | other |
| Park Gyros Castro | other |
| Straw | other |
| Tenderloin Market & Deli | other |
| Prospect | other |
| Juice Craze | other |
| Bubble Cafe | cafe |
| JAVA ON OCEAN | other |
| Rico Pan | other |
| AK SUBS | other |
| Wing Lum Cafe | cafe |
| PANCHO'S | other |
| Boos Voni | other |
| Tacolicious | other |
| VIP Coffee & Cake Shop | cafe |
| A Mano | other |
| Cream | other |
| 7-Eleven, Store 2366-21389F | other |
| Heritage | other |
| Rico Pan Bakery | other |
| Fair Trade Cafe LLC | cafe |
| Dim Sum Bistro | other |
| Live Oak School | school |
| Peet's Coffee & Tea | cafe |
| Nabe | other |
| The AA Bakery & Cafe | cafe |
| Koja Kitchen CA01 | other |
| City Super | other |
| California Pizza Kitchen, Inc. | other |
| Glaze Teriyaki | other |
| John Chin Elementary School | school |
| Soo Fong Restaurant | restaurant |
| Stanford Court Hotel | other |
| MARTHA & BROS. COFFEE CO | cafe |
| Yerba Buena Tea Co (formerly Tea Smiths of SF) | other |
| Brothers Restaurant | restaurant |
| MV Taurus | other |
| Marina Meats Inc. | other |
| JIM'S RESTAURANT | restaurant |
| Brendas Meat & Three | other |
| Bayshore Taqueria | other |
| Roadside Rosy's | other |
| Coffee Cultures SOMA | cafe |
| North Point Market | other |
| MARTIN L. KING MIDDLE SCHOOL | school |
| Minna SF Group LLC | other |
| Cabin | other |
| L & G Vietnamese Sandwich | other |
| Taco Bell Cantina #31685 | other |
| DONA TERE'S MARKET | other |
| Pabu | other |
| Jersey | other |
| Ninki Sushi Bar & Restaurant | restaurant |
| BALBOA HIGH SCHOOL | school |
| Escape From New York Pizza | other |
| David's Deli & Bistro | other |
| Fresca Gardens, Inc | other |
| ITALIAN AMERICAN SOCIAL CLUB | other |
| 95117 Premium Commissary Room | other |
| MANIVANH THAI RESTAURANT | restaurant |
| SAKANA BUNE RESTAURANT | restaurant |
| Big Fish Little Fish Poke | other |
| Cecilia's Pizza & Restaurant | restaurant |
| Clay Oven Indian Cuisine | other |
| Da Cafe | cafe |
| Sushi Hon | other |
| King of Thai Noodle House | other |
| Little Vietnam Cafe | cafe |
| IL BORGO | other |
| Jackson Fillmore Trattoria | other |
| NORTH BEACH PIZZA | other |
| S & T Hong Kong Seafood | other |
| La Quinta Restaurant | restaurant |
| Maggie Cafe | cafe |
| Golden Natural Foods | other |
| Akira Japanese Restaurant | restaurant |
| Buckhorn Grill | other |
| Taqueria Dos Charros | other |
| Wing Lee BBQ Restaurant | restaurant |
| Man Sung Company | other |
| Subway 30303 | other |
| Sutter Pub and Restaurant | restaurant |
| Pho Huynh Sang | other |
| HAMANO SUSHI | other |
| S. F. Gourmet Hot Dog Cart | other |
| CLEMENT BBQ RESTAURANT | restaurant |
| Urban Putt | other |
| AT&T - COMMISARY KITCHEN [145184] | other |
| West Coast Wine & Cheese | other |
| Dolores Park Outpost | other |
| NEW EMMY'S RESTAURANT | restaurant |
| SRI THAI CUISINE | other |
| Restaurante Montecristo | restaurant |
| Great Eastern Restaurant | restaurant |
| Yummy Sticks | other |
| Hot Pot Island | other |
| King of Thai Noodles Cafe | cafe |
| AT&T Park - Coffee and Ice Cream (5A+5B) | cafe |
| Jiang Ling Cuisine Restaurant | restaurant |
| SF BAGEL CO. (KATZ BAGELS) | other |
| San Francisco Marriott Union Square - Main Kitchen | other |
| SUBWAY #31419 | other |
| Roma Pizzeria | other |
| Lollipot | other |
| Boss Supermarket | other |
| Mizutani Sushi Bar | other |
| Jane the Bakery | other |
| YUMMA'S MED GRILL | other |
| The Salvation Army | other |
| Morning Brew Cafe | cafe |
| Sharetea | other |
| Old Blue | other |
| Elephant Sushi | other |
| CALIFORNIA PACIFIC MEDICAL CENTER | other |
| Crepe Cafe | cafe |
| My Ivy Corp. | other |
| Tanuki Restaurant | restaurant |
| Antonelli Brothers Meat, Fish, and Poultry Inc. | other |
| Cafe Bean | cafe |
| Ha Nam Ninh Restaurant | restaurant |
| Project Juice | other |
| New Regent Cafe | cafe |
| SENIORE'S PIZZA | other |
| Cafe Bakery | cafe |
| MICADO RESTAURANT | restaurant |
| PIZZA HUT #758280 | other |
| Angel Cafe and Deli | cafe |
| 24 Hour Fitness Club, #273 | other |
| SAFEWAY STORE #964 | other |
| General Nutrition #302 | other |
| Cafe Fiore | cafe |
| Bellissimo Pizza | other |
| 24th and Folsom Eatery | other |
| Starbucks Coffee | cafe |
| Rusty's Southern LLC | other |
| Mi Yucatan | other |
| CHA-AM RESTAURANT | restaurant |
| Allstars Cafe Inc | cafe |
| Veraci Pizza | other |
| Milkbomb Ice Cream | other |
| Chowders | other |
| House of Bagels | other |
| New Luen Sing Fish Market | other |
| Dragon Beaux | other |
| Panuchos | other |
| SH Dream Inc | other |
| The Willows | other |
| Hook a Cook | other |
| Thai Cottage Restaurant | restaurant |
| Blue Bottle Coffee | cafe |
| Golden Kim Tar Restaurant | restaurant |
| Hong Kong Clay Pot City Restaurant | restaurant |
| Chinatown Restaurant | restaurant |
| Bebebar Juice & Sandwich | other |
| Kuma Sushi + Sake | other |
| EL POLLO SUPREMO | other |
| Francisco Middle School | school |
| SO | other |
| Tupelo | other |
| TAQUERIA EL BUEN SABOR | other |
| Split Bread | other |
| Pho Luen Fat Bakery & Restaurant | restaurant |
| Pectopah LLC | other |
| PEKING WOK RESTAURANT | restaurant |
| Castagnola's Restaurant | restaurant |
| Red Jade Restaurant | restaurant |
| The Grove - Design District | other |
| Expressions Snack Bar | other |
| Dragoneats | other |
| Cafe Broadway | cafe |
| Toy Boat Dessert Cafe | cafe |
| Kate O'Brien's | other |
| SEGAFREDO | other |
| Hong Kee & Kim | other |
| The Bindery | other |
| Surisan | other |
| J.B.'S PLACE | other |
| Luke's Local Inc. | other |
| Flores | other |
| Southern Comfort Kitchen | other |
| The Good Life Grocery | other |
| Keep It, Inc. | other |
| LA ALTENA | other |
| Quickly | other |
| Bursa | other |
| Washington Bakery & Restaurant | restaurant |
| In-N-Out Burger | other |
Once the data is organized, you’ll need to find patterns in it. One good example for practicing this is the Meta/Facebook interview question:
“Find how the number of `likes` are increasing by building a `like` score based on `like` propensities. A `like` propensity is defined as the probability of giving a like amongst all reactions, per friend (i.e., number of likes / number of all reactions).
Output the average propensity alongside the corresponding date and poster. Sort the result based on the liking score in descending order.
In `facebook_reactions` table `poster` is user who posted a content, `friend` is a user who saw the content and reacted. The `facebook_friends` table stores pairs of connected friends.”
Link to the question: https://platform.stratascratch.com/coding/9775-liking-score-rating
Answer:
WITH p AS
(SELECT SUM(CASE
WHEN reaction = 'like' THEN 1
ELSE 0
END)/COUNt(*)::decimal AS prop,
friend
FROM facebook_reactions
GROUP BY 2)
SELECT date_day,
poster,
avg(prop)
FROM facebook_reactions f
JOIN p ON f.friend= p.friend
GROUP BY 1,
2
ORDER BY 3 DESC;The first concept here is the CTE which is initiated using the keyword WITH. It allocates the value 1 to every like, then sums the likes, and divides the sum by the number of all reactions. Data is then grouped by a friend. This is how we get the propensity defined in the question.
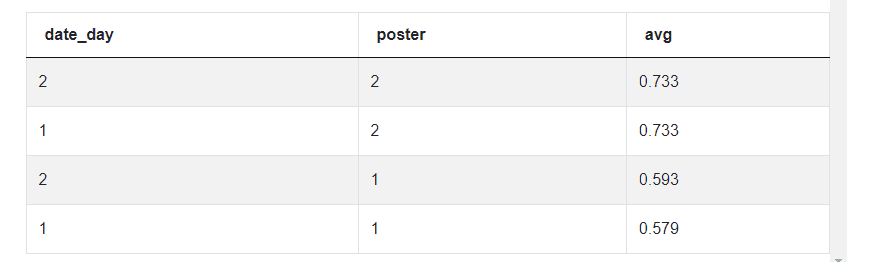
The following SELECT statement uses the CTE to calculate the average propensity using the AVG() functions. To do that, you need to JOIN two tables, group data by date and poster, and order it by propensity in descending order.
Your output should be this:
Conclusion
In total, we’ve covered seven SQL topics tested in database interview questions:
- Aggregate functions and the DISTINCT clause
- WHERE clause
- GROUP BY clause
- Ranking rows and LIMIT clause
- Subqueries and CTEs
- JOINs
- Data organizing and pattern matching
The SQL database interview questions heavily test all seven topics. You should always expect these topics because you’ll have to use them extensively if you want to work in data science.
Even though all the topics are a must, some topics are more important to specific jobs than others. Data scientists, data engineers, and data analysts will all have to know subqueries and CTEs, JOINs, and all other functions used for organizing data and finding patterns in it.
So don’t avoid these topics. But if you want to be a data engineer, you should put even more emphasis on JOINs. The same goes with data scientists and data analysts placing emphasis on all SQL concepts that are used in organizing data and finding patterns.
The best advice is to go through all these topics to make sure you have a firm grasp of the most tested SQL concepts in the job interviews. Some additional SQL questions that you must prepare are covered by the article "SQL interview questions".
Share