Amazon Data Scientist Interview Questions


Categories:
 Written by:
Written by:Nathan Rosidi
Advanced Amazon data scientist interview questions that will test your date manipulation and formatting skills as well as your window function knowledge.
Amazon Data Science Interview
Amazon is the biggest online retailer and one of the largest internet companies. Amazon constantly needs innovative data scientists to meet its ever-growing data needs. At Amazon, the role of a data scientist depends on the specific team. Amazon has many different teams that work on different products and services. These teams include:
- Amazon Web Services (AWS),
- Supply Chain Optimization Technologies (SCOT),
- Alexa,
- Middle Mile Planning Research and Optimization Science (mmPROS),
- North America Supply Chain Organization (NASCO), and many more.
In this article, we’ll have one of the most common Amazon data science interview questions that has a common analysis you'd be performing on your data science job. You will most likely to get this question in your interview for the data scientist position. It will not only test your advanced data manipulation skills but also your communication skills as you'll guide the interviewer through your solution.
Amazon Data Scientist Interview Question
Monthly Percentage Difference
Given a table of purchases by date, calculate the month-over-month percentage change in revenue. The output should include the year-month date (YYYY-MM) and percentage change, rounded to the 2nd decimal point, and sorted from the beginning of the year to the end of the year.
The percentage change column will be populated from the 2nd month forward and can be calculated as ((this month's revenue - last month's revenue) / last month's revenue)*100.
Link to the question: https://platform.stratascratch.com/coding/10319-monthly-percentage-difference
Date manipulations and window functions can be considered advanced SQL skills, but the combination of these 2 technical concepts make this Amazon data science question even more difficult. First, we have to break this question down -- The solution will be detailed. It will guide you through building the solution so you know exactly what’s going on and how the data is being manipulated at each step.
4-Step Framework to Solve This Data Science Interview Question
Our approach to solving this data scientist interview question by Amazon involves 4 steps.
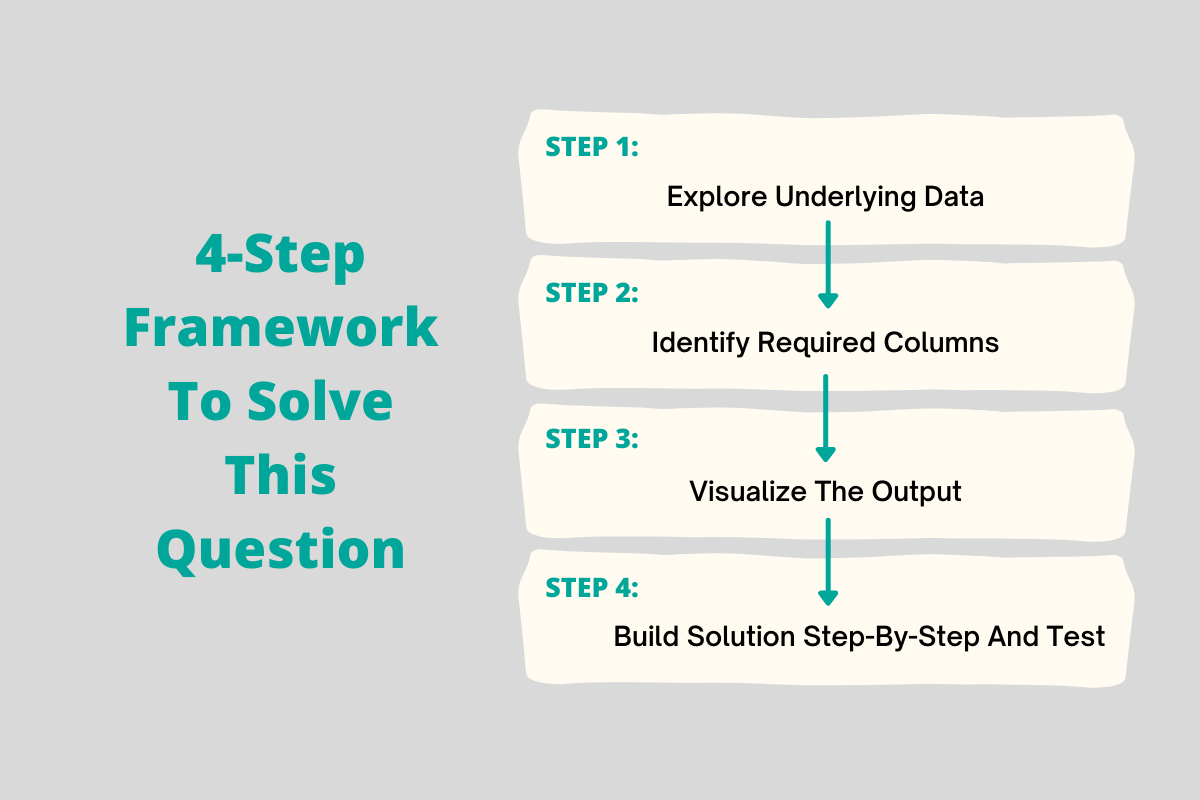
1. Explore the underlying data to study the columns and behavior of the data.
Here we can see that we have a date column (created_at) and a value column. The date column is not of date data type, which is common, as sometimes the data isn’t read in as a date, in which case we’ll need to cast or convert this column into a date column.
The value column is what will be summed up and aggregated into year-month. But it’s important to know that the created_at column is on a day scale, so we’ll need to aggregate this date column to year-month.
2. Identify the required columns
Here we’ve identified that we need the created_at column and the value column. We don’t need the other two columns.
3. Visualize the output and identify what columns to output and what aggregations are needed
According to this Amazon interview question for the data scientist position, the output will require year-month and month-over-month percentage change calculated using ((this month's revenue - last month's revenue) / last month's revenue)*100. So there are a few aggregations we’re going to need to implement to change the date to year-month and to implement the percentage change formula. But we only need 2 columns in the output -- year-month and percentage change. All the work will be to try to aggregate our data to fit this output.
4. Build solution step-by-step and test
Start coding but build your solution step-by-by and test out the query each time you add logic or a business rule.
Solution
Date format using to_char()
To solve this data scientist interview question, we’ll need to first convert the date column into a date data type because when you look at the table schema, you can see that it’s an object. If it already a date data type then you wouldn’t have to perform this operation. In Postgres, we can use this double colon, but with other SQL engines like HIVE and MySQL, you will need to use the more traditional cast() function. The cast function would look like this -- cast(created_at as date).
Once you’ve converted the created_at column to a date data type, you then want to format the date to year-month using the to_char() function. The to_char() function recognizes the date column and will format the date to your specification. In this case, we want year and month as ‘YYYY-MM’. This column, year_month, is no longer a date. It is now a character string.
SELECT
to_char(created_at::date, 'YYYY-MM') AS year_month,
*
FROM sf_transactionsThis operation is extremely common in analytics. It’s very common to aggregate data on a month level and when you’re dealing with data that spans multiple years, it makes the most sense to display year-month to separate out the years.
Calculating the month-over-month percentage change in revenue
Next in this data science question by Amazon, we’re going to calculate the month-over-month percentage change in revenue for the year_month by implementing the below formula:
(this month's revenue - last month's revenue) / last month's revenueThis might look like an easy formula to implement but it requires advanced window functions to be able to implement correctly. Let’s build this calculation step-by-step in SQL so you know exactly what’s going on under the hood.
1. Calculate the sum of the current month’s (or day’s value)
The query will calculate the value for that date in the created_at column.
SELECT to_char(created_at::date, 'YYYY-MM') AS year_month,
created_at,
sum(value)
FROM sf_transactions
GROUP BY created_at2. Calculate last month’s revenue (or the last records revenue)
Next, we’re going to calculate the last month’s revenue or in this case, given by Amazon to test the data scientists, we’re going to calculate the previous row’s revenue using the lag() function.
SELECT to_char(created_at::date, 'YYYY-MM') AS year_month,
created_at,
sum(value),
lag(sum(value), 1) OVER (ORDER BY created_at::date)
FROM sf_transactions
GROUP BY created_atThe lag() function will take the previous record because we have a 1 as a parameter. This parameter tells us which record to take so a value of 1 means to take the previous value while a value of 2 means to take the value 2 rows above the current row. Since we just want the previous row, in this case, we just need a value of 1.
What you’re seeing in the output is not an aggregation of year-month just yet. We’re keeping everything as day so that I can start with raw values before starting to aggregate things.
By calculating both the current days and previous days revenue, we have everything we need to implement the percentage change formula: (this month's revenue - last month's revenue) / last month's revenue
3. Aggregate the dates to year-month
Now that we have all the components, we need to calculate the month over month difference in revenue -- year_month, sum of values of the current month, sum of values of the previous month -- it’s time to aggregate by year-month, rather than keeping the data to the specific date.
In this OVER() part of the query, we can reformat the create_at column so that it’s year_month. Then all we need to do is change the GROUP BY to year_month so that we’re aggregating to year_month rather than the day. The query looks like this.
SELECT to_char(created_at::date, 'YYYY-MM') AS year_month,
sum(value),
lag(sum(value), 1) OVER (ORDER BY to_char(created_at::date,
'YYYY-MM'))
FROM sf_transactions
GROUP BY year_month4. Implement the month-over-month difference formula
We have all our components separated, but the purpose of doing this is to make sure that everything we’re returning is what we’re expecting. I like to separate everything out into its own components and perform aggregations and apply logic one by one so that I know how the data is behaving.
Let’s implement the month-over-month formula now by combining the current and previous month’s sum of revenues.
Here’s what the query would look like if we separate the numerator with the denominator:
SELECT to_char(created_at::date, 'YYYY-MM') AS year_month,
(sum(value) - lag(sum(value), 1) OVER (ORDER BY to_char
(created_at::date, 'YYYY-MM'))) as numerator,
lag(sum(value), 1) OVER (ORDER BY to_char(created_at::date,
'YYYY-MM')) as denominator
FROM sf_transactions
GROUP BY year_monthHere’s what the query would look like if we created the ratio:
SELECT to_char(created_at::date, 'YYYY-MM') AS year_month,
(sum(value) - lag(sum(value), 1) OVER (ORDER BY to_char
(created_at::date, 'YYYY-MM'))) /
lag(sum(value), 1) OVER (ORDER BY to_char(created_at::date,
'YYYY-MM')) as revenue_diff
FROM sf_transactions
GROUP BY year_month5. Use a window alias to for readability
The above query is hard to read and there are pieces of code that are duplicated. You don’t want duplicated code because if you do decide to change that part of the code, you’d need to change it in all the locations where they’re duplicated. For example, if you decided to use ‘YY-MM’ format for whatever reason, you’d need to change the format in two different places. So we can use a window alias to clean up the code.
SELECT to_char(created_at::date, 'YYYY-MM') AS year_month,
(sum(value) - lag(sum(value), 1) OVER (w)) /
lag(sum(value), 1) OVER (w) as revenue_diff
FROM sf_transactions
GROUP BY year_month
WINDOW w AS (ORDER BY to_char(created_at::date, 'YYYY-MM'))Now the code is easier to read and you’ve removed the duplicate code.
6. Clean up the formatting
Lastly, in the solution of this Amazon data scientist interview question, let’s keep up the formatting according to the question. We’ll be explicit with our ordering even though the default behavior already has the date in ascending order. And then we’ll multiple the ratio by 100 to give us a percentage.
SELECT to_char(created_at::date, 'YYYY-MM') AS year_month,
(sum(value) - lag(sum(value), 1) OVER (w)) /
lag(sum(value), 1) OVER (w) * 100 as revenue_diff
FROM sf_transactions
GROUP BY year_month
WINDOW w AS (ORDER BY to_char(created_at::date, 'YYYY-MM'))
ORDER BY year_month ASCLastly, we’ll round the percentage to two decimal places using the round() function.
SELECT to_char(created_at::date, 'YYYY-MM') AS year_month,
round((sum(value) - lag(sum(value), 1) OVER (w)) /
lag(sum(value), 1) OVER (w) * 100, 2) as revenue_diff
FROM sf_transactions
GROUP BY year_month
WINDOW w AS (ORDER BY to_char(created_at::date, 'YYYY-MM'))
ORDER BY year_month ASCAlso, check out our post on Amazon SQL Interview Questions to find multiple approaches to solve a question from Amazon.
Conclusion
Do you think this data scientist interview question by Amazon was too hard? Sometimes it’s nice to take your time to break down a problem and build it up one step at a time so that you can completely understand how the data is being processed at each step.
Again, our date formatting is common in analytics. You’d be asked to present your data in this format all the time so it’s important to know how to cast your data and how to reformat it.
Window functions are also important but they can get messy as you saw in the query. A window alias is helpful to make the code more readable and to implement the DRY technique -- Don’t Repeat Yourself. Or don’t repeat code.
Taken both concepts together, it makes the data science interview question much more difficult to solve, so it’s really important to approach the question slowly and build up the solution one step at a time, one logic at a time. This helps you troubleshoot and debug, and it brings the interviewer along the way so they know how and what you’re thinking as you solve the problem.
Check out our complete interview guide on the interview process and tips and tricks to ace the interview at Amazon.
Share


