Amazon Data Science Interview Questions

Categories:
 Written by:
Written by:Irakli Tchigladze
In this article, we’ll solve one of the Amazon data science interview questions to show how to approach these questions the right way.
Prepare for an interview to get the data scientist job at Amazon.
Amazon is an e-commerce giant and one of the most valuable brands in the world. Data collection and analysis is the key to Amazon’s business model. The e-commerce giant uses data to personalize user experience, create and design products, and even to improve the efficiency of their business operations.
Considering the importance of data for its business model, Amazon is always looking for promising data scientists to join its ranks.
During the interview process, you’ll most likely have to write an SQL query to solve a business problem. Interviewers look at how you approach the problem to rate your analytical, comprehension skills, as well as your ability to pay attention to details.
In this article, we’ll solve one of the Amazon data science interview questions to show how to approach these questions the right way.
Basic to Intermediate Concepts Tested in Amazon Data Science Interview

Amazon processes massive amounts of data every day, so interviewers are looking for candidates who can write efficient code. Overall knowledge of SQL is also important.
Besides displaying these skills during the interview, you’ll need them to excel at your day-to-day job. Once you get it, you need to show good results to stand out and advance your data science career.
Writing efficient SQL queries comes down to using the most appropriate tools the language has to offer.
Let’s take a look at some of the most important concepts tested in Amazon data science Interviews:
Self joins
JOINs are an important feature of SQL with wide potential applications. Knowledge of Self Joins will allow you to work with multiple references of a single table, which is necessary to solve the question outlined in later sections of this guide.
Proficiency in Self Joins includes knowing how to use aliases to reference the same table two or even three times. A good candidate also knows how to give aliases depending on the context to improve readability of the code.
JOIN and ON statements go hand-in-hand, so it’s important to know how to write the latter as well. ON statements describe the relationship between two tables, or in the case of SELF JOINs, the relationship between two references of the same table.
You can use ON statements to filter the records to meet certain criteria. Check out “SQL JOIN Interview Questions” for some examples of using JOINs. Knowing how to set up the condition is essential to get the desired results. Setting up conditions often involves checking equality or doing comparison.
INTERVAL
Lots of SQL questions deal with date and time, so you need to be proficient in date formatting and performing arithmetic operations with date values. INTERVAL function allows you to increase a date value by, for example, one year, or ten days.
In SQL, interval values are essential for performing arithmetic operations on date and time values. An ideal candidate should be able to create a basic interval value using the INTERVAL keyword, to specify the value and time unit, such as ‘10 Days’. It also pays off to know that interval values are case insensitive.
In general, candidates should have at least basic knowledge of adding and subtracting date values, and know what happens to date values after these operations.
The article “SQL Scenario Based Interview Questions” describes the INTERVAL function and arithmetic operations on date-time values in general.
SQL Logical Operators
Proficiency in logical operators is necessary to set up complex conditions. They allow you to find answers for SQL questions where you have to find records that satisfy certain criteria. Being proficient in logical operators means being able to chain them to get the desired result.
In the later sections of this guide, we will solve a question that requires you to use AND and BETWEEN logical operators. However, that’s only the tip of the iceberg, because there are many more types of logical operators in SQL.
To maximize your chances of getting a data science job, learn about all different types of logical operators and have an understanding of possibilities for using logical operators in SQL.
Data Types in SQL
Data type is one of the most important concepts in SQL. All candidates who go into the Amazon data science interview should have some idea of possibilities for working with each data type and possible functions to use with each one.
All aspiring data scientists should be able to find out the data type of a value in SQL. In addition to that, they should be able to explain differences between how humans read values, vs how computers read them. For instance, what makes SQL treat some number values as numbers, but others as text, even if they look like a number?
It will be helpful to know the rules for working with each data type. For example, knowing the fact that numerical values can not contain spaces or commas may help you avoid a mistake.
Casting values
Data science Interview questions are meant to be challenging. Often you need to cast one value type into another to work with it.
It’s essential to know the functions used for transforming values, and their syntax. Some functions have shorthand syntax, which can be useful for readability of the code. One of the right solutions to our question uses double colon syntax to perform arithmetic operations on date values.
Amazon Data Science Interview Question Walkthrough
Let’s go through one simple question Amazon interviewers use to test a candidate's proficiency in SQL.
The question is marked as ‘medium’ difficulty, and gives candidates a fairly simple assignment: to return the list of active users. It also gives you the definition of what an active user is. It’s better to read the question multiple times before starting to work on a solution.
Finding User Purchases
Last Updated: December 2020
Identify returning active users by finding users who made a second purchase within 1 to 7 days after their first purchase. Ignore same-day purchases. Output a list of these user_ids.
Link to the question: https://platform.stratascratch.com/coding/10322-finding-user-purchases
To answer the question, applicants must find the records that satisfy the specified criteria. The most challenging part of the question is to set up a condition that reflects the criteria in the question description.
The first step should be to analyze what it means to be an ‘active user’, and translate it into SQL code. Then you should decide on your approach to the problem. You should aim for efficiency and find the solution with the least amount of code.
Available Dataset
Data Assumptions
Candidates trying to analyze available data for this question have an easy task: there is just one table with five columns.
Let’s examine each column of the only available amazon_transactions table:
- We use the id value of the order itself to make sure that we compare two separate orders to determine the time interval between them, not compare an order with itself.
- To identify the users who placed the order we will have to work with values from the user_id column.
- Product variety is not an important factor, so the item column can be ignored.
- The interval between two orders is an important factor, so we will have to work with values from the created_at column.
- The revenue column is not important, because the question doesn’t mention or imply the need to calculate the sales volume in any way.
Still, there may be some details that require attention. For instance, looking at available data, you’ll notice that the created_at column contains just date values without time. In this case, you might be confused about what to do in instances when some users have placed two orders on the same day.
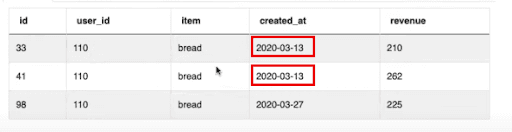
In this scenario, it would be difficult to figure out which order should come first, and which will be second. To find a solution to this dilemma, you need to digest the formulation of the question.
The definition of active user does not give any importance to sequence of orders. As long as they happened within any given 7-day window, it doesn’t matter which order came first. What matters is that the time interval between them is between 0 and 7 days.
When confused about outlier cases in the data, the first thing you should do is carefully read the phrasing of the question. If the question contains a keyword to help you make a decision, you should proceed with your approach.
There are some cases when you have to be communicative, and double-check with the interviewers to make sure you stay on the right track. Still, you shouldn’t go overboard; it’s important to display independence and analytical thinking skills.
Solution Logic
Before writing any SQL code, a candidate should digest the question and logically formulate her approach. Read every sentence carefully, because sometimes only one word can change the meaning of the task. By asking the question, interviewers are testing not only your SQL skills, but also your ability to listen and comprehend the assignment.
In SQL, Joins are useful for working with the time difference between two rows. Considering the fact that we have just one table, we’ll probably have to use a Self Join. Your overall approach should consist of the following steps:
- Create two references to this table and connect them with a Self Join
- Use the ON statement to set up the conditions to find the rows that meet the criteria
- Handle the edge cases
The question asks us to return user_id values of the individual rows that meet the condition (being an active user). When thinking of a solution for this problem, it’s very important to pay attention to the definition of what constitutes an active user.
Any two purchases made within the 7-day window is enough to qualify one as an ‘active user’. To find the orders that meet the criteria we will cross-check all the orders to find a pair that meets the criteria.
The most challenging part of this Amazon data science interview question is setting up a chain of conditions.
The first condition is that the orders must be placed by the same person. In other words, we should go through both references of the table to find order records with the same user_id value.
The next step is to compare the id of the order itself. This is necessary to avoid the situation when we compare the order to its own copy from another table, and count it as another instance of ‘active user’, just because both copies of the order have the same date.
Finally, when comparing two orders, we have to check that one of them occurred on the same day, or within the seven-day period from the first one. For that, we can use simple comparison operators <, >, =.
To compare the dates of two orders, we’ll have to access their created_at value. Let’s imagine we have date values x and y. In SQL, checking if x > y means checking if x happened after (in other words, more recent) than y.
To check if a certain date value is older than another, we use the less than ( < ) sign. The condition x < y would check if x occurred before y.
We will use the equality(=) and greater than (>) operators to check if the second order took place on the same day or later than the created_at value of the first order. But how do we check if the second order happened no more than 7 days later from the first one?
Let’s imagine x is a current date. You can use the INTERVAL function to ‘add’ 7 days to the current date, and then use it for comparison.
We’ll have to use the AND logical operator to chain together multiple conditions outlined above.
Keep in mind that we have to find the user_id values of the active users. That’s easy, since these records already include the user_id column. We just have to find the two order records that satisfy these requirements, and output the user_id value from one of the references.
Finally, we also have to handle the case when a user becomes active more than once. Question description does not ask us to find out the number of times a user became active, so we don’t need to keep track of multiple instances of users becoming active. We can use the DISTINCT keyword to make sure the final list includes only unique user IDs.
Solution Approach
Step 1: Create two references to the table
Since we’re trying to find two orders that happened within a certain period, we’ll need to have two references to the same table. For the sake of simplicity, we’ll call them a and b.
SELECT *
FROM amazon_transactions a
JOIN amazon_transactions bStep 2: Set up the condition
Now we come to the difficult part. We have to set up the condition to make sure that:
- The orders were placed by the same user,
- We are not comparing the order to itself,
- The order from the second reference was created later than the one in the first, but no later than 7 days.
We’re going to use the AND logical operator, so the SQL returns only the rows that satisfy all three conditions.
We’ll use simple syntax of the INTERVAL function to check if two orders fall within a 7-day window.
SELECT *
FROM amazon_transactions a
JOIN amazon_transactions b ON a.user_id = b.user_id
AND a.id != b.id
AND b.created_at >= a.created_at
AND b.created_at <= a.created_at + INTERVAL '7 day'Now, if we run the code and take a look at the output, you’ll see all the rows that satisfy the criteria:
| id | user_id | item | created_at | revenue | id | user_id | item | created_at | revenue |
|---|---|---|---|---|---|---|---|---|---|
| 3 | 120 | milk | 2020-03-18 | 176 | 25 | 120 | biscuit | 2020-03-21 | 858 |
| 6 | 103 | bread | 2020-03-29 | 862 | 22 | 103 | milk | 2020-03-31 | 290 |
| 10 | 141 | banana | 2020-03-17 | 812 | 68 | 141 | bread | 2020-03-21 | 118 |
| 16 | 122 | bread | 2020-03-06 | 593 | 7 | 122 | banana | 2020-03-07 | 952 |
| 17 | 128 | biscuit | 2020-03-24 | 160 | 36 | 128 | milk | 2020-03-28 | 498 |
Step 3: Output user_id values, handle edge cases
The question asks us to output the user_id values of active users, not the entire row. We have to modify our SELECT statement to return the user_id values from one of the references.
Some users order a lot, so they might satisfy our conditions for being an ‘active user’ multiple times. We can use the DISTINCT statement to display each user only once.
SELECT DISTINCT a.user_id
FROM amazon_transactions a
JOIN amazon_transactions b ON a.user_id = b.user_id
AND a.id != b.id
AND b.created_at >= a.created_at
AND b.created_at <= a.created_at + INTERVAL '7 day'Run this code and you’ll see the list of unique user_id values of active users.
| user_id |
|---|
| 100 |
| 103 |
| 105 |
| 109 |
| 110 |
| 111 |
| 112 |
| 114 |
| 117 |
| 120 |
| 122 |
| 128 |
| 129 |
| 130 |
| 131 |
| 133 |
| 141 |
| 143 |
| 150 |
Another Right Solution
There are multiple ways to set up the condition to check whether two orders happened within the 7-day period. This is a slightly different approach from the StrataScratch platform:
SELECT DISTINCT(a1.user_id)
FROM amazon_transactions a1
JOIN amazon_transactions a2 ON a1.user_id=a2.user_id
AND a1.id <> a2.id
AND a2.created_at::date-a1.created_at::date BETWEEN 0 AND 7
ORDER BY a1.user_idIn this case, we use BETWEEN and AND logical operators to check if the time difference between two dates falls between 0 and 7 days.
Final Words
In this article, we walked through one of the interesting questions asked of data scientist candidates at Amazon interviews.
Preparing for a data science job interview by studying questions is a good start, but being truly prepared comes down to having a thorough understanding of all SQL concepts to come up with efficient solutions.
Check out our other posts like “Amazon SQL Interview Questions” and “Amazon Data Analyst Interview Questions” to polish your skills in SQL and maximize your chances of landing a job at Amazon.
Share