40+ Data Science Interview Questions From Top Companies


Categories:
 Written by:
Written by:Nathan Rosidi
Overwhelming you with the data science interview questions is the only way to make sure your data science interview doesn’t end underwhelmingly.
We can’t give you all the questions and answers you need for a data science job interview. You know that already. But we can provide you with the amount that gets close to getting everything you need.
Covering as many data science interview question types as possible makes the territory where the interview question can surprise you increasingly smaller. We’re doing this job for you in this article. But the rest of the work is on you.
All the questions we have gathered on StrataScratch show the data science interview questions can be categorized into two or eight categories, depending on how you look at them.
Two main categories are:
- Coding questions
- Non-coding questions
The non-coding questions could be further separated into seven categories:
- System design
- Probability
- Business Case
- Statistics
- Modeling
- Technical
- Product
Data Science Coding Interview Questions
These include all the questions where the coding skills are tested. It doesn’t matter which language is tested. It could be SQL, Python, R, or any other programming language required for the data science position you want. Coding is one of the most important skills for data scientists. It is no surprise that this is the most numerous category of data science interview questions. So what questions could you expect if you apply for a job at one of the top companies?


At Meta/Facebook interview, you could get the following question:
Interview Question #1: Find whether the number of seniors works at Meta/Facebook is higher than its number of USA based employees
Last Updated: April 2020
Find whether the number of senior workers (i.e., more experienced) at Meta/Facebook is higher than number of USA-based employees at Facebook/Meta. If the number of senior workers is higher then output as 'More seniors'. Otherwise, output as 'More USA-based'.
Link to the question: https://platform.stratascratch.com/coding/10065-find-whether-the-number-of-seniors-works-at-facebook-is-higher-than-its-number-of-usa-based-employees
Answer:
SELECT
CASE
WHEN n_seniors > n_usa_based
THEN 'More seniors'
ELSE 'More USA-based'
END AS winner
FROM
(SELECT
SUM(CASE WHEN is_senior THEN 1 ELSE 0 END) AS n_seniors
FROM
facebook_employees) seniors
LEFT JOIN
(SELECT
COUNT(*) AS n_usa_based
FROM
facebook_employees
WHERE
location = 'USA'
) us_based
ON TRUE
This interview tests numerous SQL concepts, such as:
- SELECT statement
- CASE statement
- Subqueries
- Aggregate functions
- JOINs
These are also the concepts most often tested to various degrees by any top company. It doesn’t mean that’s everything you need to know, but it’s highly unlikely that you’ll get a coding interview question not testing at least one of those concepts. This is the basis on which you have to build because some questions can get much trickier than this one.
Let’s analyze how the solution uses all the concepts.
It, first, uses the SELECT and CASE statement to allocate values to certain data. The criteria try to decide whether there are more seniors or USA-based employees.
The answer uses a subquery in the FROM clause to get this from one table. There’s also an aggregate function SUM() and, again, CASE statement. This part of the code queries the table facebook_employees to sum the number of senior employees. It does that by allocating the value ‘1’ to every senior employee and then adding all the values.
This subquery is then LEFT JOINed with another one. The second subquery uses the COUNT() aggregate function to find the number of employees based in the USA.
Another top company you might want to join is Twitter. Its question asks you to:
Interview Question#2: Unique Salaries
Last Updated: April 2019
Find the top three distinct salaries for each department. Output the department name and the top 3 distinct salaries by each department. Order your results alphabetically by department and then by highest salary to lowest.
Link to the question: https://platform.stratascratch.com/coding/9898-unique-salaries
To answer this data science interview question, you need the subqueries. One important SQL concept not tested in the previous question is the RANK() window function. Additionally, you’ll also have to order your data and filter it using the WHERE clause. Try your hand below:
The solution that you should get:
To work at Apple as a data scientist, you’ll probably first have to answer this question:
Interview Question #3: Count the number of user events performed by MacBookPro users
Count the number of user events performed by MacBookPro users. Output the result along with the event name. Sort the result based on the event count in the descending order.
Link to the question: https://platform.stratascratch.com/coding/9653-count-the-number-of-user-events-performed-by-macbookpro-users
The solution here returns the event_name column and uses the COUNT() function to count the number of events. This has to be done only for MacBook Pro users, so you might want to use the WHERE clause to filter data. Finally, you’ll have to group and order data the way the question asks. Try your hand below:
The solution that you should get:
Google being very popular among data scientists means you should take a look at their questions too. For instance, they could ask you to find the number of speakers by language.
Interview Question #4: Number of Speakers By Language
Find the number of speakers of each language by country. Output the country, language, and the corresponding number of speakers. Output the result based on the country in ascending order.
Link to the question: https://platform.stratascratch.com/coding/10139-number-of-speakers-by-language
You’ll again use the COUNT() aggregate function to find the number of speakers. This time, the main difference is that you need a distinct number of speakers. You have tables playbook_events and playbook_users to get all the required information. To do that, you’ll have to join them using the INNER JOIN. While the syntax is not much different compared to other joins, you’ll have to have a thorough understanding of joining tables to choose the adequate type of join. Making a mistake here could easily give you a wrong answer to the question.
As with the previous question, you’ll also have to know how to group and order data in the desired way.
Here's the solution that you should get:
If you want to work at Yelp, you could come across this medium level data scientist interview question:
Interview Question #5: Find the top 5 cities with the most 5 star businesses
Find the top 5 cities with the highest number of 5-star businesses.
The output should include the city name and the total count of 5-star businesses in that city, considering both open and closed businesses. If two or more cities have the same number of 5-star businesses, assign them the same rank, and skip the next rank accordingly. For example, if two cities tie for 1st place, the following city should be ranked 3rd.
Link to the question: https://platform.stratascratch.com/coding/10148-find-the-top-10-cities-with-the-most-5-star-businesses
The main SQL concept tested here is a Common Table Expression or CTE. In it, you’ll have to use the COUNT() aggregate function along with the RANK() window function, too, to get the number of 5-star businesses in each city and rank them according to this number.
Once you get that, you’ll want to reference the CTE to return the city and the number of 5-star businesses. Since you need only the top five cities, you’ll need to filter the results using the WHERE clause and order them. Try to solve it below:
Here's the solution:
Airbnb could ask you to find the day of the week that most people check-in. Here’s the full question:
Interview Question #6: Find the day of the week that most people check-in
Find the day of the week that most people want to check in. Output the day of the week alongside the corresponding check-in count.
Link to the question: https://platform.stratascratch.com/coding/9762-find-the-day-of-the-week-that-most-people-check-in
How would you answer this data science interview question? For starters, you have to know this question tests working with dates. So to solve this problem, you’ll need to know some date functions, such as DATE_PART. From then on, it’s easy to use the COUNT() function to count the number of check-ins. Of course, the result will have to be grouped on a weekday level and ordered in descending order to get the day of the week with the most check-in on top of the results. Then you’ll only need the LIMIT statement to return only this one row with the most check-ins.
Here's the solution:
Here you can practice more such SQL interview questions and Python interview questions.
Data Science Non-Coding Interview Questions
The data science non-coding interview questions test all other technical skills, bar the coding, required for the particular job. Every subcategory is, more or less, dedicated to one technical non-coding skill.


The System Design Data Science Interview Questions
This category of questions is there to test your ability to solve system design problems and create systems from scratch.
They are somewhere between the theoretical and practical questions. To give you an example, here’s an easy question by General Assembly:
Interview Question #7: Python Dictionary to Store Data

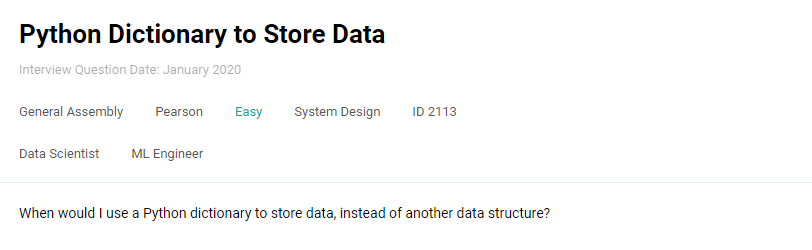
Link to the question: https://platform.stratascratch.com/technical/2113-python-dictionary-to-store-data
Answer:
I would use a Python dictionary to store data when the code readability is important and the speed of getting the data. I would also use it when the order of data is not essential.
There could also be questions on how to build the whole recommendation system. An example is this data scientist interview question by Audible:
Interview Question #8: Build a Recommendation System


Link to the question: https://platform.stratascratch.com/technical/2148-build-a-recommendation-system
The system design question could also require writing a “general” SQL code to achieve something. For example, a Meta/Facebook question:
Interview Question #9: GROUP or ORDER BY


Link to the question: https://platform.stratascratch.com/technical/2170-group-or-order-by
Another such example would be a question by Pinterest:
Interview Question #10: iPhone and Web logs

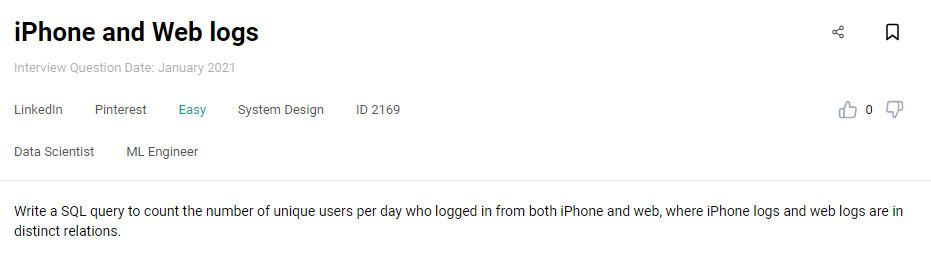
Link to the question: https://platform.stratascratch.com/technical/2169-iphone-and-web-logs
You could also get a question that will involve thinking of metrics to compare the performance of two backend engines. It’s again a question by Meta/Facebook:
Interview Question #11: Comparing Performance of Engines


Link to the question: https://platform.stratascratch.com/technical/2006-comparing-performance-of-engines
The question by Medium is an example of the system design problem-solving question:
Interview Question #12: Books Collection

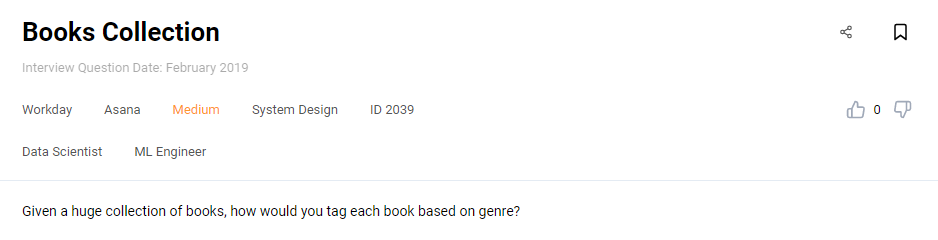
Link to the question: https://platform.stratascratch.com/technical/2039-books-collection
The Probability Data Science Interview Questions
These are statistics questions focused only on one statistics area. Namely, probability. They are designed to test how you would calculate the probability of different outcomes dressed in real-life situations.
Rare are the people who don’t like spaghetti. If you like them, you’ll also like this question. Even if you don’t like spaghetti, it will do good to you if you try to solve it. It’s a question by Natera:
Interview Question #13: Mom's Spaghetti


Link to the question: https://platform.stratascratch.com/technical/2024-moms-spaghetti
Answer:
Every time we connect two ends, one of these conditions occurs: either we create a loop or we create a longer spaghetti.
On the first trial, we have N spaghetti and 2N ends. We grab one end and the probability that we pick up the other end of the same spaghetti and make a loop is 1 in 2N − 1.
On the second trial, we have N − 1 spaghetti and 2N − 2 ends. Hence, the probability that we get a loop this time is 1/(2N − 3). The pattern repeats for the third trial onwards and we can formulate the number of loops as:
The question by Zenefits asks you to calculate the probability of winning the rolling dice:
Interview Question #14: First to Six


Link to the question: https://platform.stratascratch.com/technical/2060-first-to-six
If you know how to answer the question, you also increase your probability of getting a job. And maybe makes you more reluctant to bet your money on rolling dice.
One more question for (potential) gamblers is the probability of drawing two cards from a card deck. The Meta/Facebook question asks you exactly that:
Interview Question #15: Pair by Drawing 2 Cards


Link to the question: https://platform.stratascratch.com/technical/2241-pair-by-drawing-2-cards
One more question that’s not too difficult to answer is the one by Belvedere Trading. Trading decisions sometimes seem to be based on throwing a coin. No wonder they’re interested in knowing if you can solve this data science interview question:
Interview Question #16: 3 Heads Probability

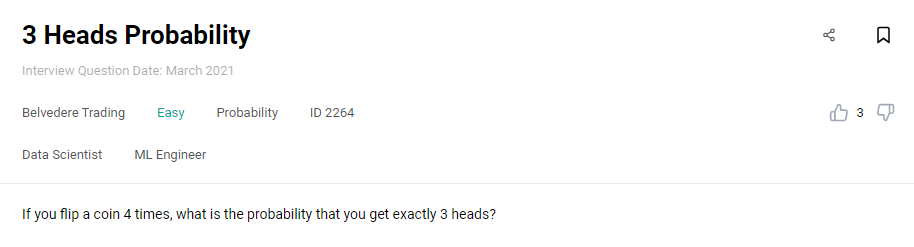
Link to the question: https://platform.stratascratch.com/technical/2264-3-heads-probability
One of the hard questions is the one asked by Jane Street:
Interview Question #17: Ask One Question To Win


Link to the question: https://platform.stratascratch.com/technical/2273-ask-one-question-to-win
Find more such probability interview questions here → 30 Probability and Statistics Interview Questions for Data Scientists
The Business Case Data Science Interview Questions
The third category of non-coding questions is business case questions. These questions involve case studies and questions related to the company/business that require data science skills.
Such questions don’t necessarily have a correct answer. Even if they have it, there are probably several correct answers or at least several ways to get the answer. The point here is that you showcase your way of thinking how you approach business problem-solving. The process here is more important than the exact solution.
One example of such a question is the “Finding Invalid Schools” question by Meta/Facebook:
Interview Question #18: Finding Invalid Schools


Link to the question: https://platform.stratascratch.com/technical/2211-finding-invalid-schools
There are several solutions to this data science interview problem.
Answer 1: Use Facebook data about users and schools.
Approach: Create a graph/cluster of similar users based on their location, age, etc. If some school has only one or a few occurrences it’s probably fake. Instead of looking at similar users, we can only consider user’s friends (and maybe friends of friends) to make this more scalable. It’s very likely that the user’s Facebook friends attend the same school as a user. Another idea is to use school data on Facebook to verify its invalidity. If a school does not have a picture or the school’s name is abnormal, there’s a big chance it’s fake (we can use Machine Learning for this).
Pros: We depend only on app data, we can make the solution scalable.
Cons: If there is not enough application data, our approach will not work. And even if there is, there is no 100% certainty it’s correct. If some school is new and/or users have not updated the high school info it’s possible we claim the high school as invalid, even though it is not invalid.
Answer 2: Use government data that is publicly accessible.
Approach: Fetch a list of schools and compare the user’s school with this list.
Pros: Very quick and probably 100% correct.
Cons: Such access is not a common thing in most countries. Also, we depend on outside sources and if the source is not working we can’t use it.
Answer 3: Reporting mechanism.
Approach: Give an option to users to report invalid high schools of other users. Based on the number of reports make a decision if a school is invalid.
Pros: Simple solution that depends on users' activity.
Cons: It’s not 100% secure. Also, it could be hard to motivate users for making such explicit actions.
Those are some suggestions on how you could approach answering the question. You can try to solve one more Meta/Facebook question by yourself:
Interview Question #19: McD's Big Macs


Link to the question: https://platform.stratascratch.com/technical/2002-mcds-big-macs
Another question that tests your problem-solving creativity is Uber’s question:
Interview Question #20: Determining Origin City


Link to the question: https://platform.stratascratch.com/technical/2014-determining-origin-city
Think about it. Which data would you need to have, and how would you collect it?
While the previous question doesn’t necessarily require the company’s product knowledge, the next one does. Here’s Spotify’s question on improving the app experience:
Interview Question #21: Spotify Data

Link to the question: https://platform.stratascratch.com/technical/2054-spotify-data
You’ll probably have to be a Spotify user to answer this data science interview question. That way, you can put yourself in the user’s shoes and even think about what you would improve in the app.
Here’s an easier question by DemystData. You would probably know to answer it even if you didn’t work in finance. Being in situations where you needed to prove your income is probably enough:
Interview Question #22: Financial Institution

Link to the question: https://platform.stratascratch.com/technical/2069-financial-institution
One question by Travel Click for sure is not interested in the correct answer:
Interview Question #23: Windows in NYC


Link to the question: https://platform.stratascratch.com/technical/2090-windows-in-nyc
How would you try to get this number? It could be any city, not only New York City. You’d probably have to know the approximate number of people living and working in the city. Maybe that would be a good start for answering the question?
The Statistics Data Science Interview Questions
We already covered the probability questions, which can also be considered statistics questions. You could expect all the statistics topics in this category, except probability.


For example, Meta/Facebook could ask you something about mean and median:
Interview Question #24: Mean, Median Age in Mexico


Link to the question: https://platform.stratascratch.com/technical/2013-mean-median-age-in-mexico/
Answer:
To find out which one is higher between the mean and the median, we need to find out first how the age distribution looks like in Mexico. As a rule of thumb, we can determine which one is higher with the following scenario:
If the age is normally distributed, the mean is going to be equal to the median.
If the age distribution is right-skewed, then the mean is larger than the median.
If the age distribution is left-skewed, then the median is higher than the mean.
According to Statista, which you can see more in detail via this link: https://www.statista.com/statistics/275411/age-distribution-in-mexico, Mexico constantly has a right-skewed distribution from 2010 until 2020.
People ages 0-14 occupy 25-29% of the total population in Mexico.
People ages 15-64 occupy 64-66% of the total population in Mexico.
People ages above 65 occupy 6-7% of the total population in Mexico.
Thus, the mean age in Mexico is higher than the median.
The more theoretical question could be one by Travelport:
Interview Question #25: R^2 Value


Link to the question: https://platform.stratascratch.com/technical/2153-r2-value
A little bit of formulas writing is tested by FINRA question:
Interview Question #26: Pearson's Correlation Coefficient


“Prove why Pearson's correlation coefficient is between -1 and 1.”
Link to the question: https://platform.stratascratch.com/technical/2191-pearsons-correlation-coefficient
To answer the question, you need to know what Pearson’s correlation is. Then the Cauchy-Schwarz inequality can help you prove why Pearson’s correlation coefficient is between -1 and 1.
A little more practical question is by Glassdoor:
Interview Question #27: Survey Response Randomness


Link to the question: https://platform.stratascratch.com/technical/2205-survey-response-randomness
Do you know how to answer this data science interview question? A slight hint: Cronbach’s alpha. Now you have to elaborate on this.
The question for those that will be more into machine learning is this one by DST Systems:
Interview Question #28: Variance in Unsupervised Model


“How to calculate variance in an unsupervised model?”
Link to the question: https://platform.stratascratch.com/technical/2210-variance-in-unsupervised-model
You could do it on an example of k-means clustering. To get the variance of the model, you’ll have to define the formula of both within-cluster and between-cluster variations separately.
Deloitte is interested in the Shapiro-Wilk test:
Interview Question #29: Shapiro-Wilk Test

Link to the question: https://platform.stratascratch.com/technical/2331-shapiro-wilk-test
What is it used for? Do you need the null hypothesis, and how do you form it? How does the p-value compare with the significance level? Those are all questions that could frame your approach to answering the question.
The Modeling Data Science Interview Questions
When you get the modeling questions, they will test your knowledge about machine learning and statistical modeling. That means you need to show how you’d use these technical skills to generate sample data and predict real-world events.
Here’s one such question by Amazon:
Interview Question #30: Colinearity in Data Analysis

Link to the question: https://platform.stratascratch.com/technical/2140-colinearity-in-data-analysis
Answer:
What is Collinearity or Multicollinearity?
Collinearity typically occurs during regression analysis and can happen when one independent variable in a regression model is linearly correlated with another independent variable.
Why Collinearity becomes a problem?
When we are dealing with regression analysis, we will get a fitted coefficient for all of the independent variables that contribute to the result of the dependent variable, for example:
In the equation above, Y is the dependent variable, while X1 and X2 are the independent variables. We normally can interpret the coefficient (in the equation above 0.4 for X1 and 0.5 for X2) of each independent variable as the contribution of one specific independent variable ( for example X1) to the dependent variable (Y) when we change the value of that independent variable (X1) while keeping the value of another independent variable (X2) constant.
If we have collinearity, this means that if we change the value of X1, the coefficient of X2 would most likely change as well, which makes it difficult for us to interpret the model and the statistics.
The variance of the model might get inflated due to collinearity, which might give us a 'false' p-value result. This would lead us to the confusion to pick which independent variables are statistically significant that need to be included in the final regression model.
How to deal with Collinearity?
There are two common ways to deal with collinearity:
- Using Variance Inflation Factor or VIF.
VIF measures the ratio between the variance for a given coefficient with only the corresponding independent variable in the model versus the variance for a given coefficient with all independent variables in the model.
A VIF of 1 means the tested independent variable is not correlated with the other predictors. VIF of 1-5 indicates medium collinearity. Meanwhile, VIF above 5 indicates strong collinearity with other independent variables. - Using Correlation Matrix
A correlation matrix normally shows us the Pearson's correlation between two independent variables. If Pearson's correlation between two independent variables is above 0.75, we can consider that those two independent variables have high collinearity.
Without understanding at least in theory what a machine learning concept is, you won’t get a job. This Salesforce data scientist interview question tests this nicely:
Interview Question #31: Machine Learning Concept

Link to the question: https://platform.stratascratch.com/technical/2042-machine-learning-concept
Similarly phrased question is the one by SparkCognition on the random forest:
Interview Question #32: Random Forrest

Link to the question: https://platform.stratascratch.com/technical/2070-random-forrest
Try it yourself; it’s potentially not as easy as you might think. Of course, you know what a random forest is. But you have to explain it in non-technical terms. If you can do it, then you really understand!
In your modeling, you’ll also use linear and logistic regression. No wonder IBM is interested in knowing how you’ll handle this question:
Interview Question #33: Logistic Regression and Linear Regression

Link to the question: https://platform.stratascratch.com/technical/2089-logistic-regression-and-linear-regression
You’ll also be working with algorithms, be it your or someone else’s. That’s why it’s essential to know the answer to this data science interview question from Netflix:
Interview Question #34: Better Algorithm


Link to the question: https://platform.stratascratch.com/technical/2108-better-algorithm
The unavoidable step of modeling is a model evaluation. You’ll have to show you’re familiar with it by answering the General Assembly question:
Interview Question #35: Model Evaluation Procedures

Link to the question: https://platform.stratascratch.com/technical/2120-model-evaluation-procedures
The Technical Data Science Interview Questions
The technical data science interview questions could also be considered theoretical questions. They mainly focus on testing the candidate’s knowledge of various data science concepts. Often these questions require theoretical explanations of concepts within a particular programming language, such as SQL or Python. That way, they can be considered the theoretical mirror of the coding questions in a way.


For example, you could come across this data science interview question by Southwest Airlines:
Interview Question #36: UNION and UNION ALL

Link to the question: https://platform.stratascratch.com/technical/2083-union-and-union-all
Answer:
UNION and UNION ALL are SQL statements that are useful to concatenate the entries between two or more tables. In general, they have the same functionality.
The main difference between UNION and UNION ALL is that the UNION command will only extract the relevant entries that are unique (no duplicates) while UNION ALL will extract all of the relevant entries, including the duplicates.
You see, while you didn’t have to write an SQL code containing UNION or UNION ALL, you still had to know what these two SQL statements do.
Speaking of SQL, you could be required to explain the difference between different joins. For example, like in this Credit Acceptance question:
Interview Question #37: Left Join and Right Join

Link to the question: https://platform.stratascratch.com/technical/2242-left-join-and-right-join
We shouldn’t forget Python is also massively used in data science. That’s why you should also know something about Python’s dictionary to answer the Moore Capital Management question:
Interview Question #38: Python Dictionary

Link to the question: https://platform.stratascratch.com/technical/2091-python-dictionary
A hint? The answer should have something to do with hash tables. Wink-wink, nudge-nudge.
The questions don’t have to be about the programming languages concepts. The Goldman Sachs question is one such example:
Interview Question #39: Square Root of Two

Link to the question: https://platform.stratascratch.com/technical/2229-square-root-of-two
The questions could be concerning data, like in this IBM question:
Interview Question #40: Dealing with Missing Values


Link to the question: https://platform.stratascratch.com/technical/2255-dealing-with-missing-values
The answer should involve describing which two types of data could be missing and how you fill the missing data in each data type.
Not only the data but the interview question could also test your theoretical knowledge of databases. One of the popular questions is the one by Deloitte on database normalization:
Interview Question #41: Database Normalization

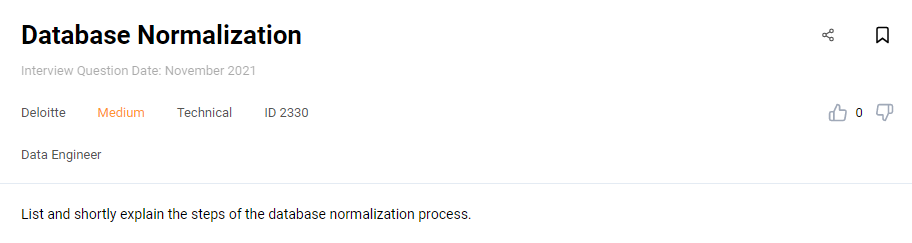
Link to the question: https://platform.stratascratch.com/technical/2330-database-normalization
You should know what the purpose of database normalization is. Then you should list all the steps in this process and explain how this step fulfills the goal of normalization.
The Product Data Science Interview Questions
The product questions are the least universal questions you could get at an interview. They are designed to test your knowledge of the specific company’s product(s). That way, they’re not only testing your problem-solving skills but also how familiar you are with the company itself and its products. The ideal scenario would be to be a long-time customer itself.
Visa could be interested in credit card activity:
Interview Question #42: Credit Card Activity


Link to the question: https://platform.stratascratch.com/technical/2342-credit-card-activity
Another question asking to show your product knowledge is the one by eBay:
Interview Question #43: Identify Ebay Objects


Link to the question: https://platform.stratascratch.com/technical/2075-identify-ebay-objects
Yammer, on the other hand, is interested in reports on the content upload:
Interview Question #44: Spike in Uploads

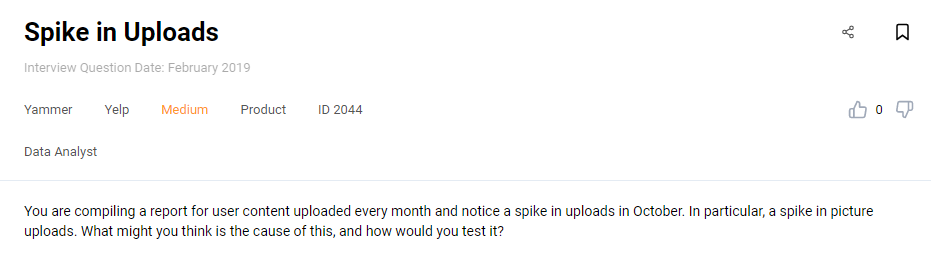
Link to the question: https://platform.stratascratch.com/technical/2044-spike-in-uploads
Being an Instagram and Facebook user could help you find the answer to this data science interview question easier:
Interview Question #45: Investigate the Discrepancy

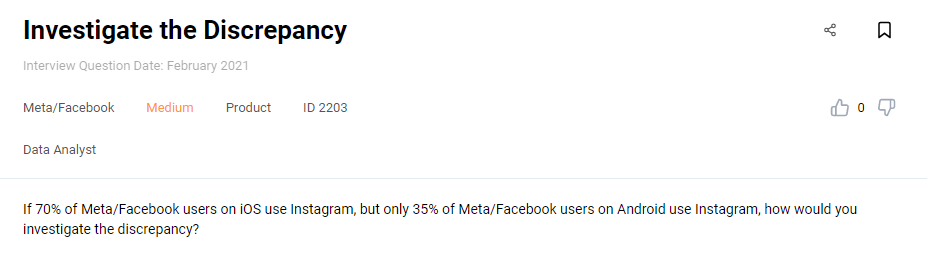
Link to the question: https://platform.stratascratch.com/technical/2203-investigate-the-discrepancy
Google has numerous products, with one of them being Google One. It’s not necessary to be a subscriber to answer this question, but it probably won’t hurt knowing how this product works:
Interview Question #46: Storage Plan Usage

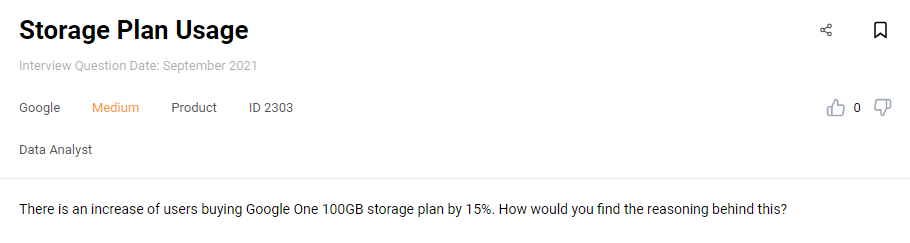
Link to the question: https://platform.stratascratch.com/technical/2303-storage-plan-usage
And if you were a Skype user (or you weren’t and you know why!) during the COVID-19 pandemic, maybe you would quickly answer this question by Microsoft:
Interview Question #47: Skype Usage


Link to the question: https://platform.stratascratch.com/technical/2321-skype-usage
As you can see, you don’t have to be an avid user of every product possible. But you should at least make yourself familiar with the products the company offers. That is especially important if you apply for some product-specific positions. It’s also helpful to know different types of product interview questions in detail.
Conclusion
In preparing for a data science job interview, there’s a vast range of question types you should cover. Two main types are coding and non-coding data science interview questions.
While the coding questions are the most common, coding is not the only skill you need to have. That’s why the non-coding questions are equally important. Their purpose is to show your statistics, modeling, and system design skills, along with product knowledge, problem-solving, and other technical skills.
This guide gives you an overview of the range of questions that await you at the data science interview for top companies. It’s not an easy task to get a job in such companies. Going through all these data science questions is only a starting point. Now is your turn to explore all other coding and non-coding interview questions.
Share


