Twitter Data Scientist Interview Question


Categories:
 Written by:
Written by:Nathan Rosidi
Multiple approaches for solving Twitter Data Scientist interview question. We’ll closely examine one of the interesting Twitter data science interview questions.
This Twitter data scientist interview question can be solved in several different ways and we’ll cover four of them in detail. Keep reading to discover that while all the approaches are correct, some of them are better and may land you a job!
Twitter is one of the world’s largest and most influential social networks. In 2021 it reached the milestone of 200 million users. Twitter as the company solely works for maintaining and further developing the social platform and the network of APIs associated with it. In December 2020 it employed over 5500 people. Headquartered in San Francisco, US, it has offices in multiple large cities all over the world. Additionally, Twitter offers many remote positions to be filled from several countries in North America, Europe, Asia and Oceania.
Data Science Position at Twitter
Twitter usually has dozens of open data science positions. Most of them have to do with the platform itself, anything from ads and algorithms, through cloud-based applications to fraud and abuse detection. While the specifics depend on each position, many data scientists at Twitter are expected to design, implement, and analyze experiments to determine how new models or products affect existing parts of the platform or to use the product understanding and conducted analyses to suggest product improvements. Other tasks include creating accurate and statistically sound summary metrics to evaluate the performance of products, communicating findings to executives and cross-functional teams and even reviewing other data scientists’ code and results.


Speaking of requirements, Twitter usually expects their data scientists to be proficient with Python / R and SQL and familiar with Spark. Additionally, the applicants should have experience using data intelligently to optimize product performance and good understanding of how to grow and shape data tools and datasets to improve data-driven decision making.
Twitter Data Scientist Interview Question
The question that we are going to examine in detail in this article has been asked during an interview at Twitter. It’s titled “Highest Salary In Department” and the key challenge is finding maximum values of the dataset but separately for each category.
Last Updated: April 2019
Find the employee with the highest salary per department. Output the department name, employee's first name along with the corresponding salary.
Link: https://platform.stratascratch.com/coding/9897-highest-salary-in-department?python=
We’re being asked to find the employee with the highest salary per department. Furthermore, it’s specified that the output should include the department name, employee's first name and the corresponding salary.
This Twitter data scientist interview question may seem like a short and simple question but as we will see, the answer is not that straight-forward and requires using some more advanced SQL functions. In fact, there exist multiple ways of solving this interview question and in this article, we’ll discuss four of them.
Framework to Solve the Problem
To make the process of solving this interview question easier, we will follow an easy framework that can be applied to any data science problem. It only has three steps but it creates a logical pipeline for approaching problems concerning writing code for manipulating data. The three steps are following:
- Understand your data:
- List your assumptions about the data columns so that you know which columns you should use
- If you still don’t feel enough confident that you understand your data, view the first couple of rows of your data (single or multiple tables). Or ask for some example values so you understand the actual data, not just the columns. It will not only help you identify the edge cases but also limit your solution to the bounds of your assumption.
- Formulate your approach:
- Now, start writing down the logical steps that you have to program/code.
- You also need to identify the main functions that you have to use/implement to perform the logic.
- Don't forget that interviewers will be watching you. They can intervene when needed. So, make sure you ask them to clarify any ambiguity. Your interviewers will also specify if you can use the ready-made functions, or if you should write the code from scratch.
- Code Execution:
- Build up your code in such a way that it doesn't look oversimplified or overcomplicated either.
- Build it in steps based on the steps we have outlined with the interviewer. That means the code is not going to be efficient. That’s fine. You can talk about optimization at the end of your interview.
- Here's the most important point. Try to ignore overcomplicating your code with multiple logical statements and rules in each block of code. You can define a block of code as a CTE or subquery. The reason you can do this is that it’s self-contained and separate from the rest of the code.
- Don't be quiet while laying down your code. Talk about your code as the interviewer always evaluates your problem-solving skills.
Understand your data
Let’s start by examining the data. At a Twitter data scientist interview, you usually won’t be given any actual records, instead you’ll see what tables or data frames are there and what are the columns and data types in these tables.
In the case of this Twitter data scientist interview question, there is only one table called ‘employee’ with 14 columns. What this table represents is a list of employees of a certain company. Each row corresponds to a single person - an employee, and the columns store various details about them, such as name, surname, age, address etc.
| id | int |
| first_name | varchar |
| last_name | varchar |
| age | int |
| sex | varchar |
| employee_title | varchar |
| department | varchar |
| salary | int |
| target | int |
| bonus | int |
| varchar | |
| city | varchar |
| address | varchar |
| manager_id | int |
What’s important to realise is that to solve this Twitter data scientist interview question, we don’t need to worry about all of the columns, only a few of them will contain all the information we’re interested in. Let’s look at the interview question again and try to think which columns may be of interest to us. We’re being asked to ‘find the employee’, or simply speaking find a row, ‘with the highest salary’ so we’ll need to find the maximum values in the ‘salary’ column. What’s more, we’re interested in the highest salary ‘per department’ so we’ll be focusing on the column ‘department’. Finally, aside from the department name and the salary, we are also being asked to output ‘employee's first name’ and so the column ‘first_name’ will also come in handy. That’s why, even though the dataset has 14 columns, we will only be using the three of them.
Solution 1: Inner query
Formulate Approach
The next step, according to the general framework for solving data science questions, is to outline a few general steps we’ll need to perform to answer this question. These are very high-level but writing them down in the beginning will make the process of writing the code much easier for us.
This article will cover a few different methods of solving this Twitter data scientist interview question, so we’ll go through the steps of formulating the approach and code execution several times, once for each solution. Firstly, we’ll see how to solve this interview question using an inner and outer join. Here are the general steps to follow:
- Let’s start with an inner query that produces only two tables: the department name and for each department, the highest salary in this department.
- In this inner query, to find the highest salary, we can use the MAX() function and group the results by department column.
- In the final step, we’ll use the outer query to find the name of an employee such that the department name and the salary amount from the inner query match the name.
Code execution
To write the SQL code for this question, let’s simply follow the general steps that we’ve just defined and translate them into code. The key part of this approach is that we have the inner and outer query. You can think about it as taking the original data table, using the inner query to create a new table, and finally producing the required output in the outer query by using both the original table and the table from the inner query.
Looking at the first step, we can start by writing the code for the inner query. The goal is to create a table with only the department and the highest salary. These data come from the ‘employee’ table, so we can start like this:
SELECT
department,
salary
FROM employee
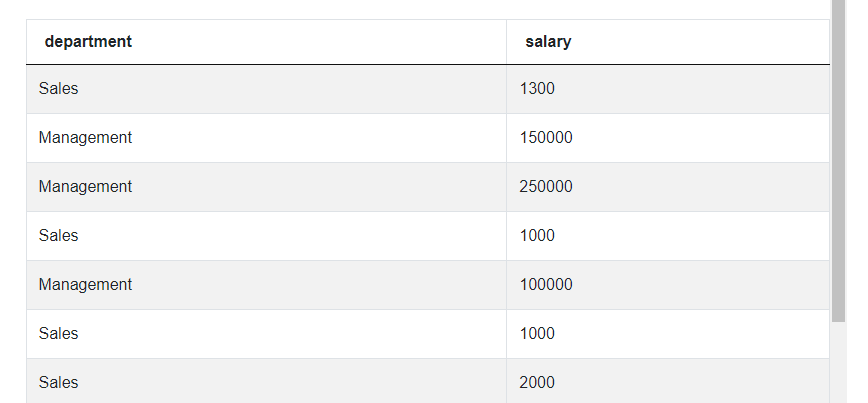
This code produces the table with only two columns, but it returns all possible salaries for each department. We, on the other hand, are only interested in the highest salaries. So logically, we can use the MAX() function to let SQL find the highest value. But since we’re not looking for the single highest salary in the entire dataset but rather the highest salary in each department, we can add the GROUP BY statement to ensure exactly that. This is the second step from the approach we formulated earlier.
SELECT
department,
MAX(salary)
FROM employee
GROUP BY department
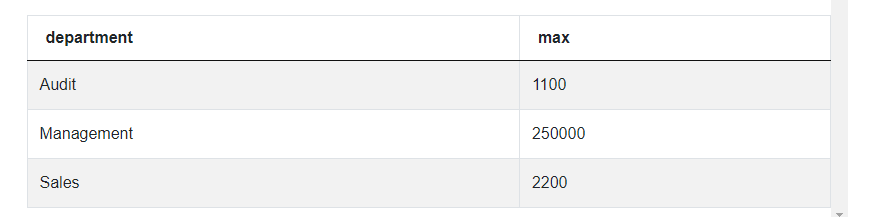
As you can see, the results look much better, we have our three departments and each one has a single highest salary. What we’re missing is the name of the employee behind each salary. Following the third step, we’ll use the outer query to produce the output as required. We’ll have 3 columns, department, employee’s first name and the salary, so we can start by writing:
SELECT
department,
first_name,
salary
FROM employeeThis is a very simple query that returns three columns from the original dataset. Again, we have all possible employees and all their salaries but we only want to see the three employees with the highest salary in each department. For this, we need to filter the data and in SQL this can be done with a WHERE clause. What we want our filter to do is to look at the salary and department in each row and leave it only if such a combination exists in our inner query that we wrote earlier. This can be achieved with the statement like this:
WHERE (department , salary) IN
(SELECT
department,
MAX(salary)
FROM employee
GROUP BY department
);This code is a filter where we want the combination of department and salary to appear in the data table that we created using the inner query. You can see that the inner query from before is in the code, right after the IN keyword. Now, we have the entire solution, here’s the full code for solving this Twitter data scientist interview question using the inner and outer query approach:
SELECT
department,
first_name,
salary
FROM employee
WHERE (department , salary) IN
(SELECT
department,
MAX(salary)
FROM employee
GROUP BY department
)
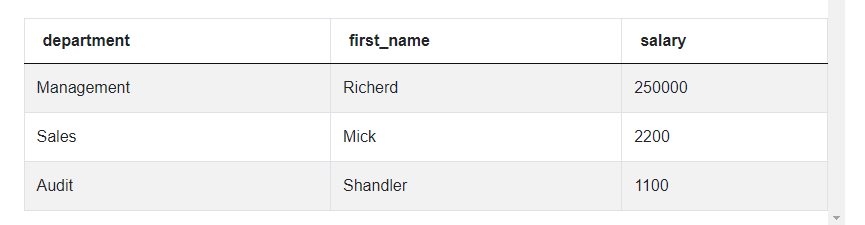
Solution 2: Join
We have just covered one way to solve this data scientist interview question from Twitter but, as we discussed before, there are multiple approaches to answering it. The next solution is similar to what we have just done but with one major twist. In the first approach, we virtually defined the two data tables and then combined them using the inner and outer query construction. In this solution, we’ll still define the two tables but we’ll use an SQL function JOIN for combining the tables. So let’s see how it’s done.
Formulate Approach
We’ll keep following the general framework for solving data science interview questions from the beginning. The data are still the same so we don’t need to repeat the ‘Understand the data’ step, but let’s go through formulating the approach again. It will be very similar to the first one but will have a few important differences.
- The first step is, again, to create a table where we have only two columns: the department name and for each department, its highest salary. Before we used the inner query for it, this time it’ll just be one of our 2 tables that we’ll then merge using the JOIN function. In the JOIN function, we say about the left table and the right table that are joined together. In the code, we’d first write the name of the left table, then the JOIN keyword and finally the right table. Let’s stick to this terminology. In our case, the left table will be the original dataset employee and the right table will only have unique department names and their corresponding highest salaries.
- To get the list of departments and the highest salaries in each department, we’ll use exactly the same method as before with the MAX function and grouping the results by department. So the next two steps stay the same as before.
- In the next step, we’ll want to use the JOIN function and combine the original dataset with this right table that we’ve just defined. In the JOIN function, we need to specify which columns need to match, in other words what columns are identical in both tables we’re merging. Usually, we’d go with some kind of ID column, but here, we can use this to also filter the results. You’ll see what is meant by that once we start writing the code, but for now let’s just say that we want to merge the left and right tables such that both the department name and the salary match.
- After this step, we’ll be left with just a few rows, each one corresponding to one employee who earns the highest salary in their department. It’s close to what we want but the table will contain all the 14 columns from the original dataset. The question, on the other hand, only asks us to return the 3 details: the name, the department and the salary so we need to remember to select only these 3 columns.
Code Execution
Having defined the steps again, let's turn them into code. The first three of the steps make us define the right column using the MAX function and grouping by department. This is exactly what we did in the first solution, so this part of the code will be identical.
SELECT
department,
MAX(salary)
FROM employee
GROUP BY departmentPreviously, this would be our inner query, this time we’ll treat it differently. Let’s add the JOIN function. The JOIN function always goes in the FROM statement in SQL, so we’ll start with the generic SELECT statement and in FROM we’ll join the original table employee with the query that we’ve just written.
SELECT *
FROM employee JOIN (SELECT
department,
MAX(salary)
FROM employee
GROUP BY department)This code will not work because, as you may remember, we still need to specify which columns need to match. We do it by using the ON keyword after the JOIN function. We’ll say that the column department from the left table needs to match with the column department from the right table and at the same time, the column salary from the left table needs to match with the column max_salary from the right table.
SELECT *
FROM employee JOIN (SELECT
department,
MAX(salary) as max_salary
FROM employee
GROUP BY department)
ON department=department and salary=max_salaryThere’s a small issue with this code though. While the columns salary and max_salary have different names and it’s clear that one comes from the left table and the other from the right table, it’s not the case with the department column. Saying department=department is not only confusing, but it’ll also break the code. We need to differentiate between the two columns and it can be done using aliases. Basically, we can define our own names for the left and right tables and then add it to the column names. The alias can be anything, but most frequently to name tables we only use single letters, so let’s call the original table employee ‘e’ and the right table ‘r’.
SELECT *
FROM employee e JOIN (SELECT
department,
MAX(salary) as max_salary
FROM employee
GROUP BY department) r
ON e.department=r.department and e.salary=r.max_salary

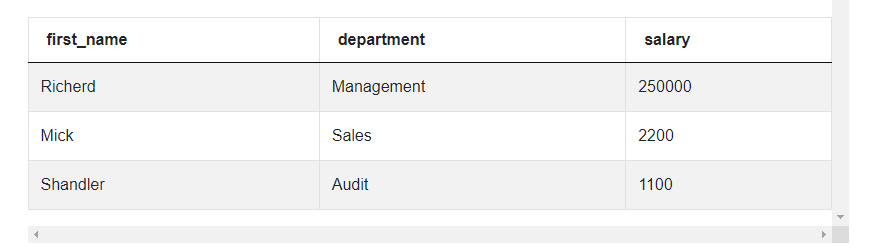
As expected, we can see only three rows, where each of the rows is one employee. Each of these employees earns the highest salary in their department. The last step is to only leave the three columns we’re interested in. So let’s replace the Asterix in the SELECT clause with the columns we want to see to obtain our final code for this approach.
SELECT
e.first_name,
e.department,
e.salary
FROM employee e
JOIN (SELECT
department,
MAX(salary) as max_salary
FROM employee
GROUP BY department) r
ON e.department=r.department and e.salary = r.max_salary;
Solution 3: Window function
We have already seen two ways in which we can solve this twitter data scientist interview question, but there are more possible approaches. This one uses a more complicated SQL structure called a window function. The window function is somewhat similar to the GROUP BY statement and can be used to aggregate the results when using functions such as MAX or COUNT. The difference is that instead of reducing the data to only include the categories and values, like with GROUP BY, it preserves the original rows and adds a column with aggregated results. You’ll see exactly what it means in a moment when we start writing the code, but first, let’s again define the general steps we’ll follow.
Formulate Approach
- In this case let’s use the inner and outer query approach, similar to what we saw in the beginning, but this time we’ll treat the inner query as a table and will execute it in the FROM clause. This time, we want the inner query to return the original data set, plus a new column with the highest salary in each department.
- To create this column, we’ll use the window function. This can be done using two keywords: OVER and PARTITION BY and in our case we want to aggregate the records, or partition them, by department.
- The next step will be about the outer query, we’ll simply use the inner query in the FROM clause but since it returns all the columns from the original dataset, we’ll only need to leave the three columns we’re asked for in the question, so the first name, department name and the salary. Thus, in the outer query, we’ll need to select only these 3 columns
- After the previous step, we’ll only have 3 columns, but will still have all the rows from the original data set. Luckily, we have the additional column with the highest salary in each employee’s department. We can use it to leave only these rows, or only these employees, where their salary is equal to the highest salary in their department.
Code Execution
Let’s get to writing the code using the SQL window function! We start with the inner query, and we can begin by writing it similar to as we saw before:
SELECT *,
MAX(salary)
FROM employeeThis time we want the inner query to return all the columns from the employee table, so we put an Asterix in the SELECT clause. Normally, having this code, we’d now add a GROUP BY statement to aggregate the results. We’ll do it differently, with the mentioned window function. Its syntax is quite simple as we just add the OVER and PARTITION BY keywords. It’ll create a new column for us that we can call ‘highest_salary’.
SELECT *,
MAX(salary) OVER(PARTITION BY department) AS highest_salary
FROM employee
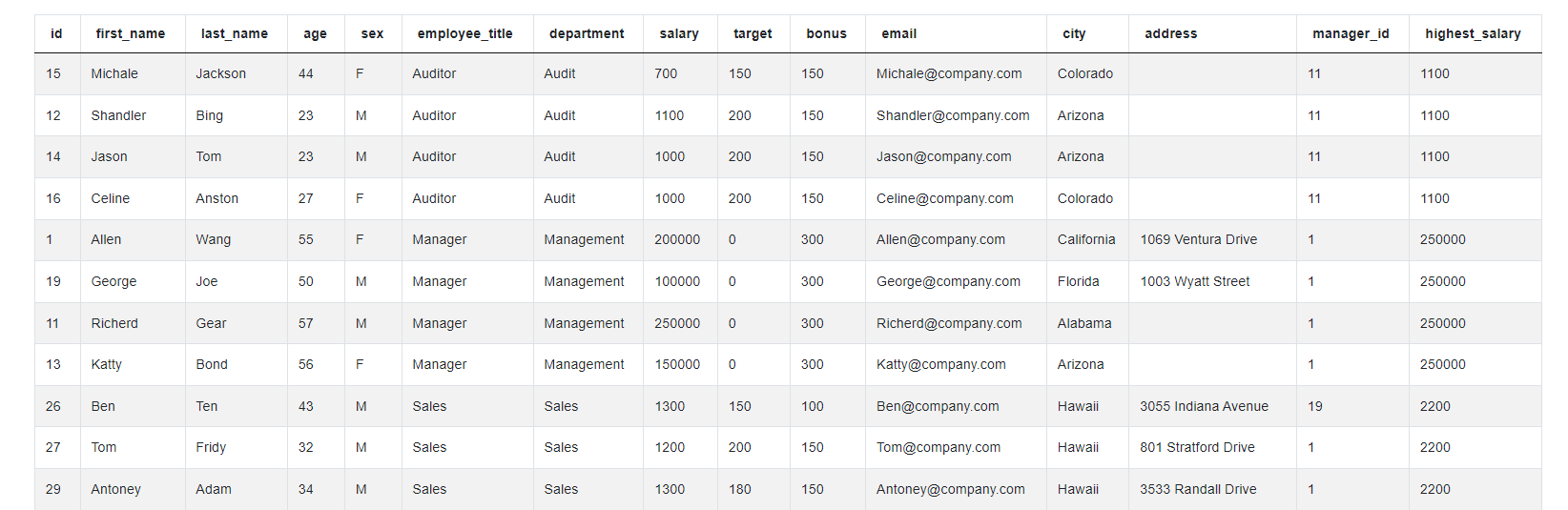
As it can be seen, we have the original dataset and there is this new column highest_salary that gives us a certain value for each row, or for each employee. However, it’s not the salary of this employee, instead, it’s the highest salary in this employee’s department. That’s why we have so many repetitions there because all employees from the same department will have the same value in this column.
The next step is creating the outer query and selecting the three columns we’re interested in. So we add the column names in the SELECT clause and move the inner query that we’ve just written to the FROM clause. What’s important is that when a subquery is in the FROM clause, it needs to be given an alias. Again, the aliases for tables are frequently just single letters, so let’s call it ‘a’. Surprisingly, we won’t use this alias ‘a’ anywhere else because we won’t have any conflicting column names, but it just needs to be there for the code to run.
SELECT
department,
first_name,
salary
FROM (SELECT *,
MAX(salary) OVER(PARTITION BY department) AS highest_salary
FROM employee ) a
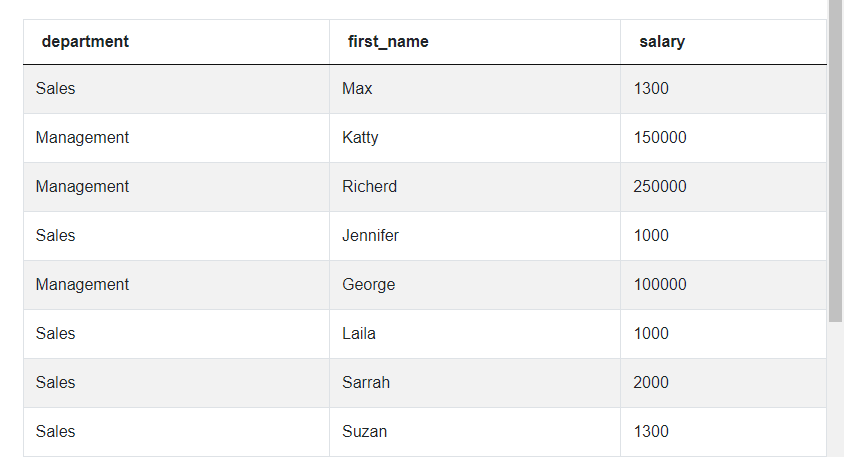
We can see that we have only three columns, the ones that we’re interested in, but we can still see all the rows from the original dataset, all the employees. That’s why we have this final step in which we filter the results. We only want to leave the rows where the employee's salary is equal to this employee’s department’s highest salary and we can do it using the WHERE clause and the column ‘highest_salary’ that we created in the inner query. And this is also our entire code that answers this Twitter data scientist interview question.
SELECT
department,
first_name,
salary
FROM (SELECT *,
MAX(salary) OVER(PARTITION BY department) AS highest_salary
FROM employee ) a
WHERE salary = highest_salarySolution 4: Rank
Let’s take a look at one more possible way of solving this interview question. This one is similar to the previous solution with the window function and you’ll see that we can use this function again. The difference is that we’ll use the RANK function which, as the name suggests, allows us to create an additional column with a ranking of selected values. Since we’re interested in the highest salaries, making the ranking of salaries in each department and then selecting the first places is what we’re gonna do here.
Formulate Approach
Let’s start, again, by formulating our general steps for solving this task. Similar to the previous approach, we’ll have the inner query in the FROM clause of the outer query. So in the first step let’s define what the inner query will do.
- In the beginning let’s select the three columns we’re interested in: the first name, department and the salary.
- Next, let’s use the RANK function in combination with the window function from before to create a new column. This new column will be a ranking of the salaries in each department, where the highest salary will get rank 1, the second highest rank 2 and so on.
- Finally, we can use the ranking we’ve just created in the outer query and filter the rows only leaving these, where the rank is equal to 1.
Code Execution
Let’s write the code again, following the general approach we’ve just outlined. First, we want to select the three columns in, what will be, the inner query.
SELECT department,
first_name,
salary
FROM employeeNow we can add the line that will create the ranking. We can start by writing something very similar to the code from the previous approach. Let’s just replace MAX(salary) with the RANK() function:
RANK() OVER (PARTITION BY department) AS rankThis looks familiar but it won’t work. We said that the results need to be aggregated by department but we didn’t specify which value the rank function should be ranking and in what way. We can achieve this by adding an ORDER BY statement. This will tell the RANK function to assign ranking to the rows in the same way they’re ordered, while keeping the ranking separate for each department. It’s important to add the keyword DESC for descending ordering of the salaries, otherwise the lowest salary in each department would get ranking 1 and this wouldn’t be useful for us.
RANK() OVER (PARTITION BY department ORDER BY salary desc) AS rankNow, let’s put everything together and add the inner query to the FROM clause of the generic outer query. Again, we need to assign an alias to the inner query, so let’s go with a letter ‘a’ like before.
SELECT *
FROM (SELECT department,
first_name,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary desc) AS rank
FROM employee) a
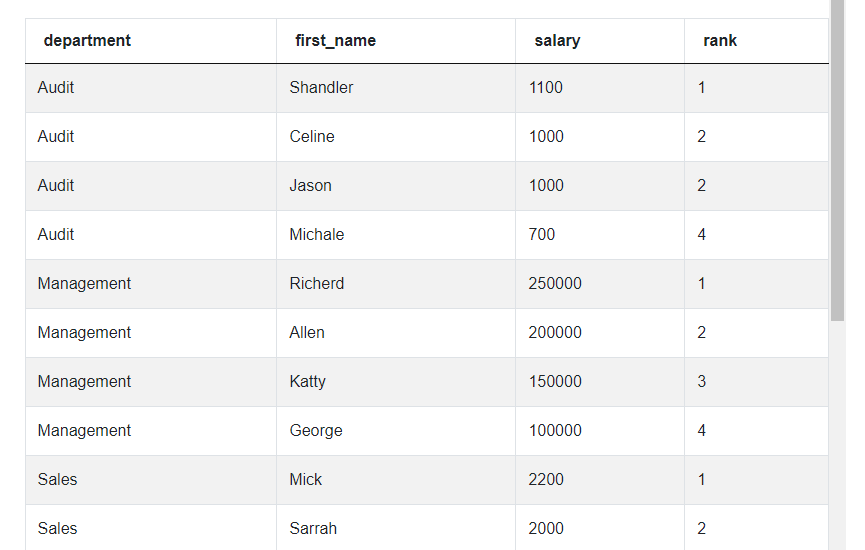
Running this code, we can see the new column ‘rank’ with the ranking of the highest salaries in each department. We can use this column and filter the results by adding a WHERE clause and only leaving the rows where there’s a number 1 in the rank column.
SELECT *
FROM (SELECT department,
first_name,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary desc) AS rank
FROM employee) a
WHERE rank=1
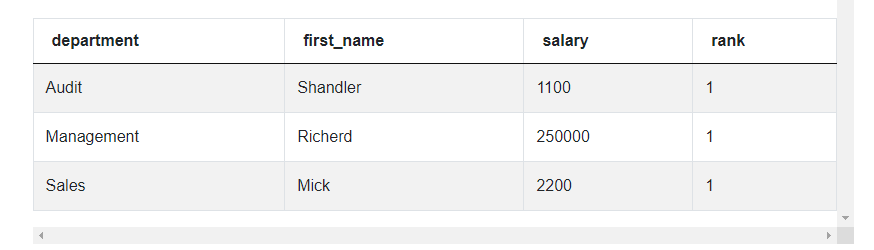
This is more like it, we only have 3 rows, one for each department and we can only see the employees with the highest salary in each department. We’re almost done, but there’s one more detail to solve. This Twitter data scientist interview question only asks us to output 3 columns but we can see 4 in our output. This is because the code still outputs the column ‘rank’ from the inner query. To change this, we need to specify which columns to return in the outer query.
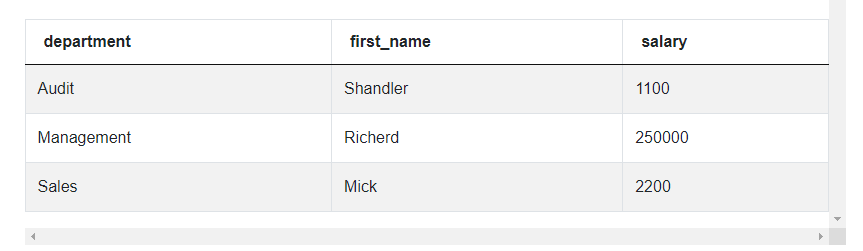
SELECT department,
first_name,
salary
FROM (SELECT department,
first_name,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary desc) AS rank
FROM employee) a
WHERE rank=1
Comparison of Approaches
We have gone through the 4 different ways in which this one interview question from Twitter can be solved. All of them are correct, meaning, they all result in an expected output, according to what we were asked in the question. But can it be possible that some approaches are better than the others?
One issue is the performance and efficiency, in other words the speed with which the code outputs the results. In a very small dataset like the example that we were using we won’t see any difference, but if the dataset had hundreds of thousands of rows, these small design decisions become important. And what’s more, showing the understanding of SQL performance during an interview will definitely give you some extra points. So which of the solutions we discussed is the most efficient?
In general, using the window functions results in much better performance than other methods of aggregating the results. Therefore, the last 2 methods will produce the required output faster than the approaches that use older techniques such as the GROUP BY clause or the JOIN function. Then, since the MAX and RANK functions take nearly identical time, the third and fourth solutions should have almost the same performance.
The window functions are also a newer and less known but at the same time much more powerful technology. Therefore, showing that you understand them will look really good during your interview. The same could be the case with using the RANK function instead of the well-known MAX. Probably the best you can do at an interview is to solve the question using any of the window functions approaches but also comment on the existence of other ways for solving the question, such as the JOIN or GROUP BY approaches, adding that these have worse performance for large datasets.
Conclusion
In this article, we have discovered multiple different ways for solving only one data science interview question from Twitter. Remember that the 4 methods mentioned here are not all the possibilities and there exist countless other ways, be it more or less efficient, for answering this interview question!
On our platform, you can practice answering more data science interview questions by constructing solutions to them but always try to think of other ways to solve them, maybe you’ll come up with a more efficient or a more elaborate approach. Make sure to post all your ideas to benefit from the feedback of other users, you can also browse all their solutions for inspiration!
Share


