Ranking in Python and SQL

Categories:
 Written by:
Written by:Nathan Rosidi
In this article, we will explore the ranking parameters that can help you handle the ranking tasks in a more efficient and accurate manner.
We discussed the basics of ranking in Python in our previous tutorial “Methods for Ranking in Pandas” where we looked into the most commonly used parameters of the Pandas ranking function. Specifically, we understood the various methods of ranking, which is crucial in dealing with ties. Aside from ranking methods, there are other parameters in the Pandas ranking function that allow for further customization and refinement of how ranks are determined. Understanding these parameters is critical in working with datasets that require more complex ranking techniques, such as percentile ranking or dealing with missing data.
In this article, we will explore these parameters so you will be better equipped to handle ranking tasks in a more efficient and accurate manner. We will also demonstrate how to implement some of the ranking methods in SQL, which is a vital skill for data analysts and data scientists, especially in organizations that use SQL as their primary data storage and retrieval language.
By the end of this article, you will have a comprehensive understanding of ranking methods in both Python and SQL, which will make you feel more confident in tackling ranking questions and analyzing datasets.
Parameters of the ranking function
The Pandas rank() function has several parameters that allow you to customize your ranking based on your dataset. These parameters include:
- pct: to return percentile rankings
- na_option: to control how nulls are dealt with during ranking
- axis: to rank rows or columns.
- numeric_only: to rank numeric or non-numeric columns
pandas.DataFrame.rank
DataFrame.rank(axis=0, method=’average’, numeric_only=false, na_option=’keep’, ascending=True, pct=False)Pct = False
Did you know that in pandas, you can obtain percentage rankings instead of integer rankings? By default, the .rank() method sets ‘pct’ to False and returns integer rankings. However, when set to True, .rank() computes percentage rankings that are normalized from 0 to 1.
Percentage rankings are useful when you want to compare rankings across different columns, regardless of their actual values. They provide a standardized way of measuring an individual's performance or status relative to the rest of the group. This is why percentage rankings are commonly used in fields like education and healthcare.
So, what exactly is a percentage ranking and how is it calculated?
What is percentile ranking?
- percentage of values in the distribution that are less than or equal to the given value or have a lower rank
Essentially, the percentile ranking tells you the percentage of values in the distribution that are less than or equal to the given value or have a lower rank. For example, if a student scored 80 out of 100 on a test and the distribution of scores in the class is such that 60% of the students scored below 80, then the percentile ranking of the student's score is 60%.
Let’s look at a question example from General Assembly.
Find the 80th percentile of hours studied
Find the 80th percentile of hours studied. Output hours studied value at specified percentile.
- The dataset has already been loaded as a pandas.DataFrame.
- print() functions and the last line of code will be displayed in the output.
- In order for your solution to be accepted, your solution should be located on the last line of the editor and match the expected output data type listed in the question.
The question asks us to find the 80th percentile of hours studied. In other words, “80% of the students studied less than x hours?”
But let’s expand this requirement. To show how ranking works, we’ll list the hours studied, rank them, and show the percentile rank.
To solve this, we will have to use the ranking function, setting pct to True.
# Import your libraries
import pandas as pd
# Start writing code
sat_scores.head()
sat_scores['percentile_rank'] = sat_scores['hrs_studied'].rank(axis = 0 , pct = True)
sat_scores['rank'] = sat_scores['hrs_studied'].rank(axis = 0)
sat_scores[['hrs_studied', 'rank', 'percentile_rank']].sort_values(by='percentile_rank', ascending=False)
| hrs_studied | rank | percentile_rank |
|---|---|---|
| 200 | 128 | 1 |
| 199 | 126.5 | 0.99 |
| 199 | 126.5 | 0.99 |
| 197 | 124 | 0.97 |
| 197 | 124 | 0.97 |
The above output shows the first 28 rows, which is enough to demonstrate everything.
As you can see, the top value (i.e. 200 hours) gets a percentile rank of 1 because 100% of the values are ranking below this (while the lowest will get 0 because it is already the lowest rank).
In case of ties here, rankings are determined by the average percentile rank of the tied group.
Regarding the 80th percentile, it’s at 163 hours. The next amount of hours studied (162) is below the 80th percentile.
na_option = ‘keep’
The ‘na_option’, which allows you to control how nulls are dealt with during ranking. By default, na_option is set to 'keep', which means that there is no ranking returned for these records. However, you can set the na_option to 'bottom' or 'top' which assigns either the lowest or highest rank to these rows.
# Import your libraries
import pandas as pd
import numpy as np
# Start writing code
sat_scores.head()
sat_scores['rank_default'] = sat_scores['hrs_studied'].rank()
sat_scores['rank_natop'] = sat_scores['hrs_studied'].rank(na_option='top')
sat_scores['rank_nabottom'] = sat_scores['hrs_studied'].rank(na_option='bottom')
sat_scores.sort_values(by='rank_natop')
| school | teacher | student_id | sat_writing | sat_verbal | sat_math | hrs_studied | id | average_sat | love | rank_default | rank_natop | rank_nabottom |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Washington HS | Frederickson | 12 | 642 | 287 | 282 | 12 | 642 | 4 | 132 | |||
| Washington HS | Spellman | 25 | 502 | 291 | 716 | 25 | 502 | 4 | 132 | |||
| Petersville HS | Davis | 38 | 779 | 656 | 724 | 38 | 779 | 4 | 132 | |||
| Petersville HS | Davis | 33 | 756 | 595 | 427 | 33 | 756 | 4 | 132 | |||
| St. John's | Tran | 127 | 266 | 789 | 481 | 127 | 266 | 4 | 132 |
As you can see here, the default option leaves the rank null but we can change this easily to give it the top or bottom rank.
axis = 0
The axis tells you whether to rank rows or columns. Most of the time we are ranking rows and the default option caters to this. However, if you ever find yourself with another dataset type, like a time series of KPIs, you might want to rank columns instead to identify the trends over time for each KPI (represented by a column). To do this, set the axis to 1 instead of 0.
numeric_only = True
Again, with the ‘numeric_only’ option, the default option is set to the usual use case which is ranking based on numeric values. However, if you want to rank both numeric and non-numeric values like arranging records by name as well, you can do so by setting this to False.
Ranking in SQL and Python

Data analysts and scientists typically must be proficient in SQL and Python so now that you know the variations of ranking in Python, let’s discover their equivalent functions in SQL!
Percentile Ranking

In SQL, you can achieve this by using the percent_rank() window function. Why don’t you try it on the same question example?
Find the 80th percentile of hours studied
Find the 80th percentile of hours studied. Output hours studied value at specified percentile.
SELECT *,
percent_rank() OVER (ORDER BY hrs_studied) as study_percentile
from sat_scores
Order by study_percentile
| school | teacher | student_id | sat_writing | sat_verbal | sat_math | hrs_studied | id | average_sat | love | study_percentile |
|---|---|---|---|---|---|---|---|---|---|---|
| St. John's | Rajaram | 101 | 407 | 535 | 312 | 0 | 101 | 407 | 0 | |
| Washington HS | Spellman | 17 | 353 | 308 | 231 | 4 | 17 | 353 | 0.01 | |
| St. John's | Williams | 120 | 213 | 633 | 248 | 8 | 120 | 213 | 0.01 | |
| St. John's | Williams | 106 | 521 | 722 | 591 | 8 | 106 | 521 | 0.01 | |
| St. John's | Williams | 105 | 669 | 316 | 409 | 9 | 105 | 669 | 0.03 |
By default, nulls are left at the bottom and therefore, get the largest ranking (i.e. close to 1). This is unlike the Python rank function where nulls were not given any ranking by default unless we change the na_option parameter.
To rank nulls, you can specify this in the order by clause. For example:
SELECT *,
percent_rank() OVER (ORDER BY hrs_studied NULLS FIRST) as study_percentile
from sat_scores
Order by study_percentile
Why don’t you try this?
Ranking (method=’min’)

Using this guest dataset from Airbnb, we will rank guests according to their age with the eldest receiving the top rank.
Rank guests based on their ages
Rank guests based on their ages. Output the guest id along with the corresponding rank. Order records by the age in descending order.
Recall that in Python, we used the .rank() function and set ascending to False.
airbnb_guests['rank'] = airbnb_guests['age'].rank(method='min', ascending = False)| guest_id | rank |
|---|---|
| 8 | 1 |
| 5 | 2 |
| 6 | 3 |
| 9 | 4 |
| 10 | 5 |
In SQL, we’ll use the rank window function and specify that age should be ordered in descending order.
SELECT
guest_id,
RANK() OVER(ORDER BY age DESC)
FROM airbnb_guests
| guest_id | rank |
|---|---|
| 8 | 1 |
| 5 | 2 |
| 6 | 3 |
| 9 | 4 |
| 10 | 5 |
Look at the ties and notice that the RANK() window function in SQL is using the minimum method to rank tied groups. In case you haven’t watched our previous ranking video, the minimum method gives the lowest possible rank to the tied values. For example, guests with ages 27 occupy positions 6 and 7. Because of the tie, 6 is now used as the rank of both guests.
Ranking (method=’dense’)
In Python, we use the rank() function with method='dense' to achieve a ranking with no gaps between ranks. In SQL, we use the dense_rank() window function to achieve the same result.

Let’s attempt this question in SQL.
Ranking Hosts By Beds
Last Updated: July 2020
Rank each host based on the number of beds they have listed. The host with the most beds should be ranked 1 and the host with the least number of beds should be ranked last. Hosts that have the same number of beds should have the same rank but there should be no gaps between ranking values. A host can also own multiple properties. Output the host ID, number of beds, and rank from highest rank to lowest.
To start with, let’s get the number of beds listed by each host.
SELECT
host_id,
sum(n_beds) as number_of_bedsFROM airbnb_apartments
GROUP BY host_id
Then, let’s add in the ranking:
SELECT
host_id,
sum(n_beds) as number_of_beds,
DENSE_RANK() OVER(ORDER BY sum(n_beds) DESC) as rank
FROM airbnb_apartments
GROUP BY host_id
ORDER BY number_of_beds desc
| host_id | number_of_beds | rank |
|---|---|---|
| 10 | 16 | 1 |
| 3 | 8 | 2 |
| 6 | 6 | 3 |
| 5 | 5 | 4 |
| 7 | 4 | 5 |
And this achieves the ranking method we want, which is to not have gaps in the ranking.
Ranking (method=’first’)
In Python, we use the rank() function with method='first' to assign a unique rank to every record. In SQL, we use the row_number() window function to achieve the same result.

Activity Rank
Last Updated: July 2021
Find the email activity rank for each user. Email activity rank is defined by the total number of emails sent. The user with the highest number of emails sent will have a rank of 1, and so on. Output the user, total emails, and their activity rank.
• Order records first by the total emails in descending order. • Then, sort users with the same number of emails in alphabetical order by their username. • In your rankings, return a unique value (i.e., a unique rank) even if multiple users have the same number of emails.
First, let’s get the total number of emails sent out by each user.
SELECT from_user,
count(*) as total_emails
FROM google_gmail_emails
GROUP BY from_user
Then, let’s use this as a basis for our ranking. We can use row_number() in SQL to create the unique rankings.
SELECT from_user,
count(*) as total_emails,
row_number() OVER ( order by count(*) desc, from_user asc)
FROM google_gmail_emails
GROUP BY from_user
order by 2 DESC, 1
| from_user | total_emails | row_number |
|---|---|---|
| 32ded68d89443e808 | 19 | 1 |
| ef5fe98c6b9f313075 | 19 | 2 |
| 5b8754928306a18b68 | 18 | 3 |
| 55e60cfcc9dc49c17e | 16 | 4 |
| 91f59516cb9dee1e88 | 16 | 5 |
And there you have it - ranking methods in Python and SQL.
Summary
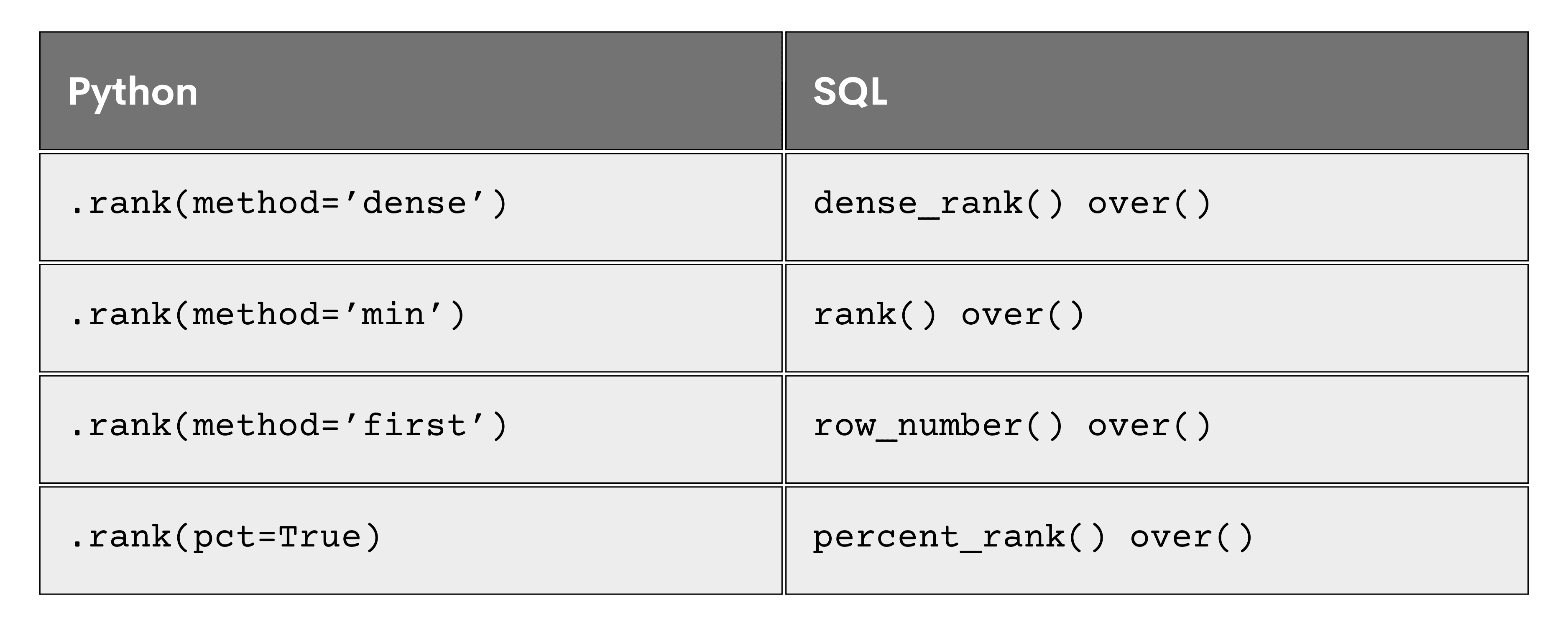
In this post, we've covered other parameters of the Pandas rank function, such as pct, na_option, axis, and numeric_only. We also looked at several ranking methods in Python and discovered their equivalents in SQL. Here’s a cheat sheet for you:
Tip!:
If you need to change the way nulls are being ranked, specify this in the ORDER BY() clause. For example, RANK() OVER(ORDER BY col NULLS FIRST)
Ranking helps identify patterns and trends in datasets so it’s an important tool for data analysis. To master ranking in SQL, check out these two articles:
Share