Python Interview Questions for Data Scientist Position


Categories:
 Written by:
Written by:Nathan Rosidi
Python interview questions for data scientist position that are targeted towards beginners or someone who is looking for more challenging tasks.
Introduction
You probably have heard about the data scientist. These are the people who bring out magic from seemingly endless matrices of numbers. But the role of data scientist does not just end with numbers. Typically, a data scientist is a person who is well versed in statistics and computer science. While statistics is the basic need for the job, knowing how to manipulate the rows and columns of data effectively with the given environment is vital. Data scientists are responsible for capturing the data, making sure that the data captured is statistically significant, and finally performing data engineering. Data engineering includes cleaning the data, removing noise, filling in missing values with the help of stakeholders, and finally revealing the concealed patterns to a focused problem.
Technical Concepts Tested in these Python Interview Questions for Data Scientist
In this post, we shall be walking over for beginner to mid-level data science personnel. To solve any data-related question it is necessary to first understand the data. Be sure to use the technology that you are comfortable with and have command on, so that data manipulation and performing operations such as aggregates, sorting, and averages are not a trouble. Capabilities to merge, sorting and groupby operations and filtration of data shall be tested in the following two Python interview questions for data scientist position. Summaries of data such as averages, unique values, and counting shall also be tested in these Python interview questions. In Python interview question 1, you shall also come across the date operation. Throughout this post Python language will be our choice to solve the questions, however, any other programming language such as SQL can also be used to apply and solve; concepts shall remain the same.
Data Scientist Python Interview Question #1
Customers Report Summary (in Python)
Summarize the number of customers and transactions for each month in 2017, filtering out transactions that were less than $5.


Question Link: https://platform.stratascratch.com/coding-question?id=2040&python=1
Data Exploration
Table of Schema
| customer_id | int64 |
| store_id | int64 |
| transaction_date | datetime64[ns] |
| transaction_id | int64 |
| product_id | int64 |
| sales | int64 |
Dataset

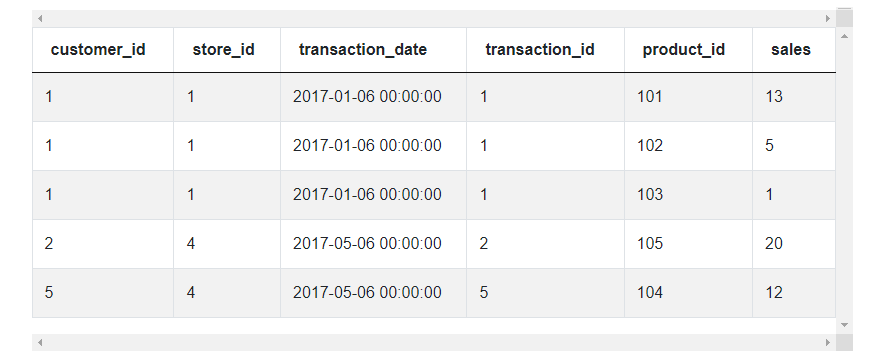
Assumptions
There are no complicated assumptions for this Python interview question. To begin with, we can assume the following:
- The data is already cleaned and does not have any missing values.
- Since we only need to summarize the transactions per month for customers, transaction_id and customer_id are sufficient for us to do the job. We are not concerned with the details of transactions or customers.
Step by Step Approach to Solve this Python Interview Question for Data Scientist
Below is a step-by-step framework to solve the question. We shall try to understand the data, draw assumptions, and then break the question into smaller questions. The point I want to make here is that this framework can be used to solve data science challenge no matter how complex it is.
- Understand the data
Look at the schema of the data. What do the columns hold? What is the type of data? Are there any missing values? What is the type of data? Do we need typecasting? - Any assumption needed?
We have already discussed our assumptions. When you are taking any interview/coding test, make sure to convey the assumptions to your interviewer. - Use the date column to get the month
As the question states that you need to summarize the data for the months of 2017. So how do you find the month? Refer to point 1, you should know the data you are dealing with. Hence if the date is present in the data, you can use the datetime methods to extract months from it. - Count the customers and aggregate the transactions
We need now to summarize the count of customers and transactions sum. This is now easy since we already have extracted the month. Use groupby to distribute the data into groups and perform math operations. - Filter out transactions less than 5$
Now how the interviewer needs to have the final answer. Here we need to show the transactions where the sum is greater than 5$.
Code in Increments
- Understand the data you have.
wfm_transactions.head()
wfm_transactions.dtypes- Filter out any transactions that are not of the year 2017. We do it using the below code:
wfm_transactions[wfm_transactions['transaction_date'].dt.year == 2017]- We have to group the transactions based on date, customer, and the transactions. Hence, we group the transactions, pick the sales column and then find the sum. As a Pandas dataframe, we will need to reset the index for the sum and rename the new column to total_amount.
result.groupby(['transaction_date','transaction_id', 'customer_id'])
['sales'].sum().reset_index(name ='total_amount')- Now that we have grouped the transactions and we have the total amount, filter the transactions.
result[result['total_amount'] >= 5]- As the final result needs to have the data month wise, pick the month from the date and then group on the basis of this. We shall use the agg function available in the Python Pandas and it will do the job for us.
result['month'] = result['transaction_date'].dt.month
result = result.groupby('month')[['transaction_id','customer_id']].agg
({'customer_id':['nunique'], 'transaction_id':['count']})- To conclude we shall need to remove the first level in the data. I am not going into the details here. Lastly, for the final output, rename the columns
result.columns = result.columns.droplevel(0)
result = result.reset_index().rename(columns={'count':'transactions',
'nunique':'customers'})Final Solution
Using the steps mentioned above below is the complete code for the solution. I have used the minimal nested syntax.
import pandas as pd
result = wfm_transactions[wfm_transactions['transaction_date'].dt.year == 2017].groupby(['transaction_date','transaction_id', 'customer_id'])['sales'].sum().reset_index(name ='total_amount')
result = result[(result['total_amount'] >= 5)]
result['month'] = result['transaction_date'].dt.month
result = result.groupby('month')[['transaction_id','customer_id']].agg({'customer_id':['nunique'], 'transaction_id':['count']})
result.columns = result.columns.droplevel(0)
result = result.reset_index().rename(columns={'count':'transactions', 'nunique':'customers'})
Data Scientist Python Interview Question #2
Products Report Summary (in Python)
Find the number of transactions and total sales for each of the product categories in 2017. Output the product categories, number of transactions, and total sales in descending order. The sales column represents the total cost the customer paid for the product so no additional calculations need to be done on the column.
Only include product categories that have products sold.


Question Link: https://platform.stratascratch.com/coding-question?id=2039&python=1
Dataset and Schema

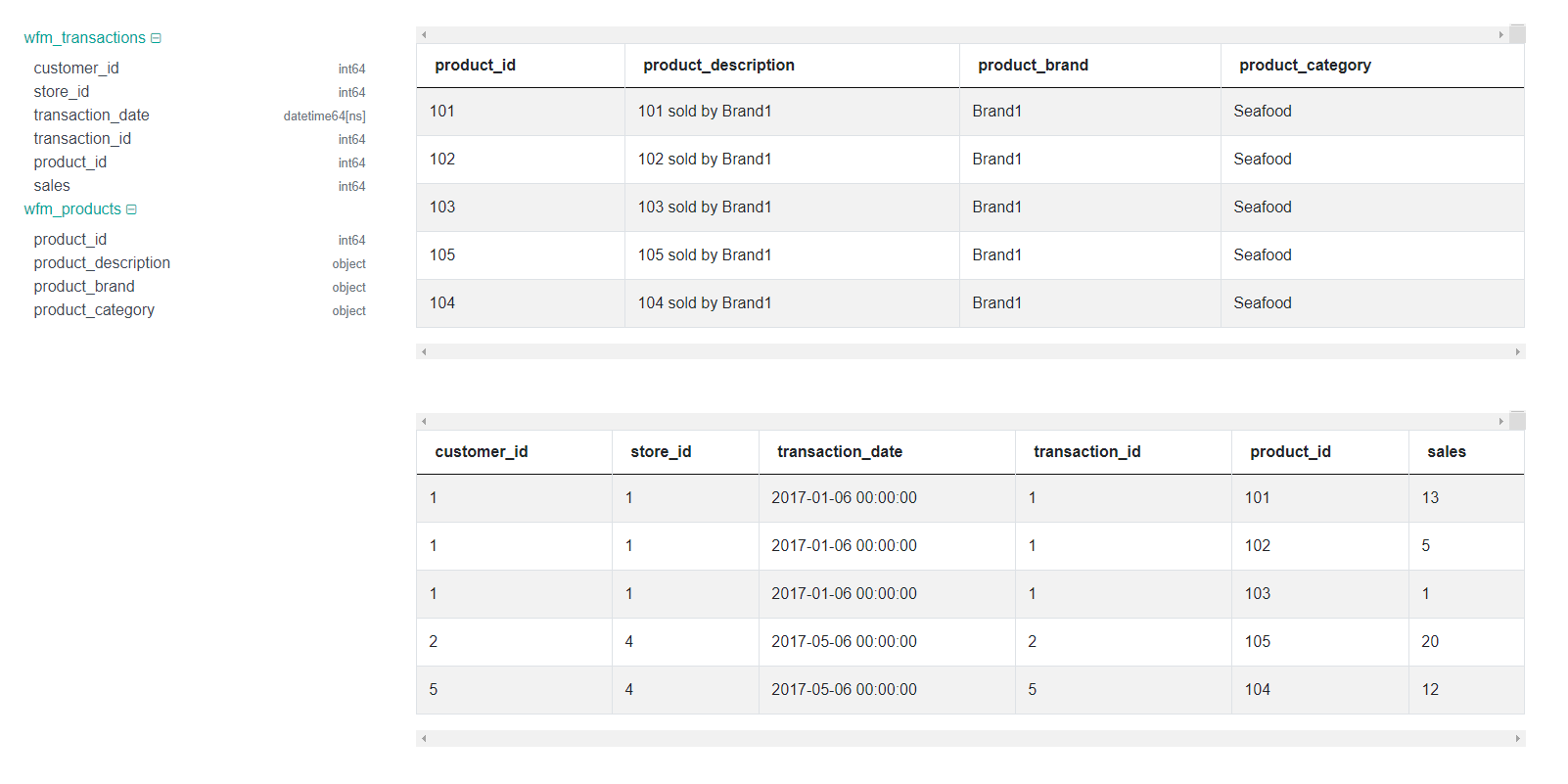
High-Level Solution
I strongly recommend the mid-level users solve this challenge themselves. To help the beginners, I will walk you to the approach needed for the solution.
The description of the question shows that this is one of the straightforward Python interview questions for data scientist position hence no assumption is required. Let’s begin
- First, notice that the question consists of two datasets. Recall from Python, dataframe is used to hold the data. So, you will need two dataframes.
- Next, our data will not make sense until it is combined to form only one dataset. By combining we shall complete the piece in the puzzle and understand the data more easily.
- You cannot join the two datasets until you know which column is present in both tables. Go through your dataset and identify which column is present in both.
- In Python to combine the two dataframes, we use the merge method available in the dataframe class. As a challenge, I am not going into the arguments required for the merge method. I encourage you to stretch yourself and figure this out. But once you have merged the dataset, pick only the columns that are needed in the final answer or needed in the requirements. Avoid picking up the complete dataset.
- Now that you have merged the dataset, you can see that only transactions which took place in 2017 are to be considered. Hence filter out all the transactions apart from this year.
- Next, to count the number of transactions per product and aggregate the sales, it is necessary to distribute the data into categories. The product_category is the column to group the data into. We use the groupby method to group the data. Once grouped the agg is the method available to count and sum the transactions.
- Lastly, you will need to sort the result as asked in this data scientist Python interview question.
If you're wondering how much python is required for data science work, check out our article How Much Python is Required for Data Science.
Conclusion
This post walked you through the relatively mid-level Python interview questions for data scientist position. These data scientist interview questions can be answered using both SQL and Python. However, we went over them using Python since Python is also helpful in application development to bring a holistic view to your skills set. Check out more Python interview questions here that are being asked in Data Science Interviews at top companies.
I cannot stress enough the fact that data science interview questions look rather complicated at first, however, you should not be confused looking at the dataset and requirements. Keeping yourself focused is the first weapon in your arsenal. Secondly almost every time in data science interviews and tests, data science questions can be solved using a series of steps. Follow the step-by-step procedure to break down the data scientist interview question into smaller questions making sure you are not strayed away. It is ok to have presumptions. Assumptions allow you to make decisions. Be sure to communicate your assumptions to the examiner and the reasons for the assumption as well.
In both Python interview questions, the skill tested is how efficiently you can manipulate the data. In real-world scenarios, there can be multiple tables. It is vital to know and understand how to merge the datasets and manipulate the data. The groupby is a must-to-have skill and mastering it is necessary to excel in your data science career. These questions also aim at how you perform the data manipulations and filter the data, as well as sorting the values as needed in the question. Feel free to use the technology of your choice, just remember to adopt the procedural approach to solving questions.
Share


