How Does Python For Loop Range Function Work?

Categories:
 Written by:
Written by:Nathan Rosidi
Learn how to use Python’s for loops and range() together to automate repetitive tasks, clean data, and tackle real-world coding problems.
If you want to do repetitive tasks a specific number of times, you probably know the combination of for and range().
For and range work together like peanut butter and jelly, like coffee and morning code reviews, and when using both, you can process datasets, clean records, or automate workflows without writing the same code fifty times.
In this guide, we’ll cover how for loops and range() actually work together, starting from the basics and moving to real interview questions inspired by Uber and Visa.
What Are for Loops in Python?
Loops in Python are a simple way to run the same action over a set of items. Not theory. Automation.
You give Python a sequence. It does the repetitive work without copy-paste.
Here is how to implement a countdown with Python by using a for loop:
import time
print("Starting countdown...")
for i in range(3, 0, -1):
print(f"Please wait... {i}")
time.sleep(1)
print("Go!")
Here is the output.

When the code finishes, it counts down from 3 to 1, pausing one second between numbers. Then it prints “Go!” In short, it gives a start signal.
Why use for loops?
- Less code, more work done. One pattern handles the repetition. No copy-paste.
- Readable and predictable. Start, stop, step. Everyone on your team gets it.
- Flexible. Lists, strings, dicts, and file lines. If it’s iterable, it plays nice.
What is range() in Python?
range() gives you numbers on demand. No list created, just a lightweight sequence for counting or indexing.
For instance, the following code produces numbers between 0 and 5.
print(list(range(5)))
Here is the output.
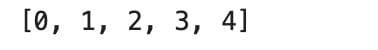
Notice that it starts at zero and stops before 5. This is Python's way of counting, zero-indexing.
range() Types, Syntax & Parameters
You can use ranges in three different ways by combining start, stop, and step arguments.
range(stop): Just define where it will stop.range(start, stop): Define start and stop.startis the first number in the sequence (inclusive).stopis the point where the range ends (exclusive).
range(start, stop, step): Define start, stop, and step.stepdefines how much the value increases or decreases each time.
range(stop)
Let’s write a range that stops at 8.
print(list(range(8)))
Here is the output.
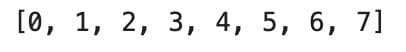
range(start, stop)
Now, let’s start the numbers from 3 by adding the start parameter to the range function.
print(list(range(3, 8)))
Here is the output.
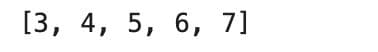
range(start, stop, step)
Let’s find odd numbers from 1 to 10. How can we find them? We know 1 is an odd number, and the next odd number is 3 and 5. So we start at one, define step 2, and stop at 10 because the question asks us to find odd numbers between 1 and 10.
print(list(range(1, 10,2)))
Here is the output.
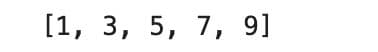
How range() Works and How for Loops Interact With It
When you use a range inside a for loop, you can limit the for loop with the range function.
For instance, if you want to send an email to 5 customers and have a confirmation after each one, you can write a for loop like this (start at one and stop at 6):
for customer_id in range(1, 6):
print(f"Sending email to customer #{customer_id}")
Here is the output.
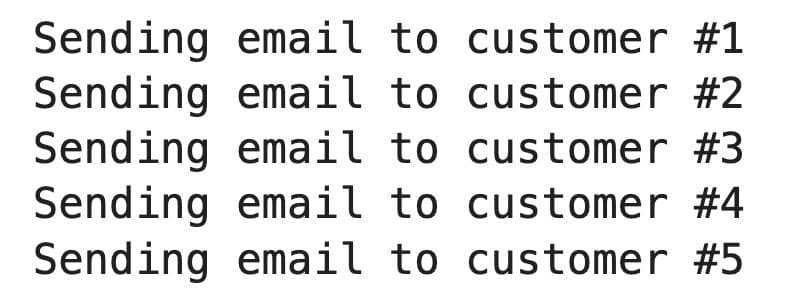
The loop runs exactly 5 times. customer_id starts at one and stops before 6, giving you IDs 1 through 5.
Behind the scenes, Python iterates through a sequence produced by range(), just as it would when you loop through a list in Python or other iterables.
What happens behind the scenes?
- Loop starts: Python asks
range(1, 6)for the first number → gets 1 - Executes: prints the message for customer #1
- Loop continues: asks for the next number → gets 2
- Executes: prints the message for customer #2
- This repeats until
customer_idreaches 5 - Loop ends: no more numbers from
range(1, 6)
Programming Challenges Using for and range
We will solve three different challenges by using for loops and range together.
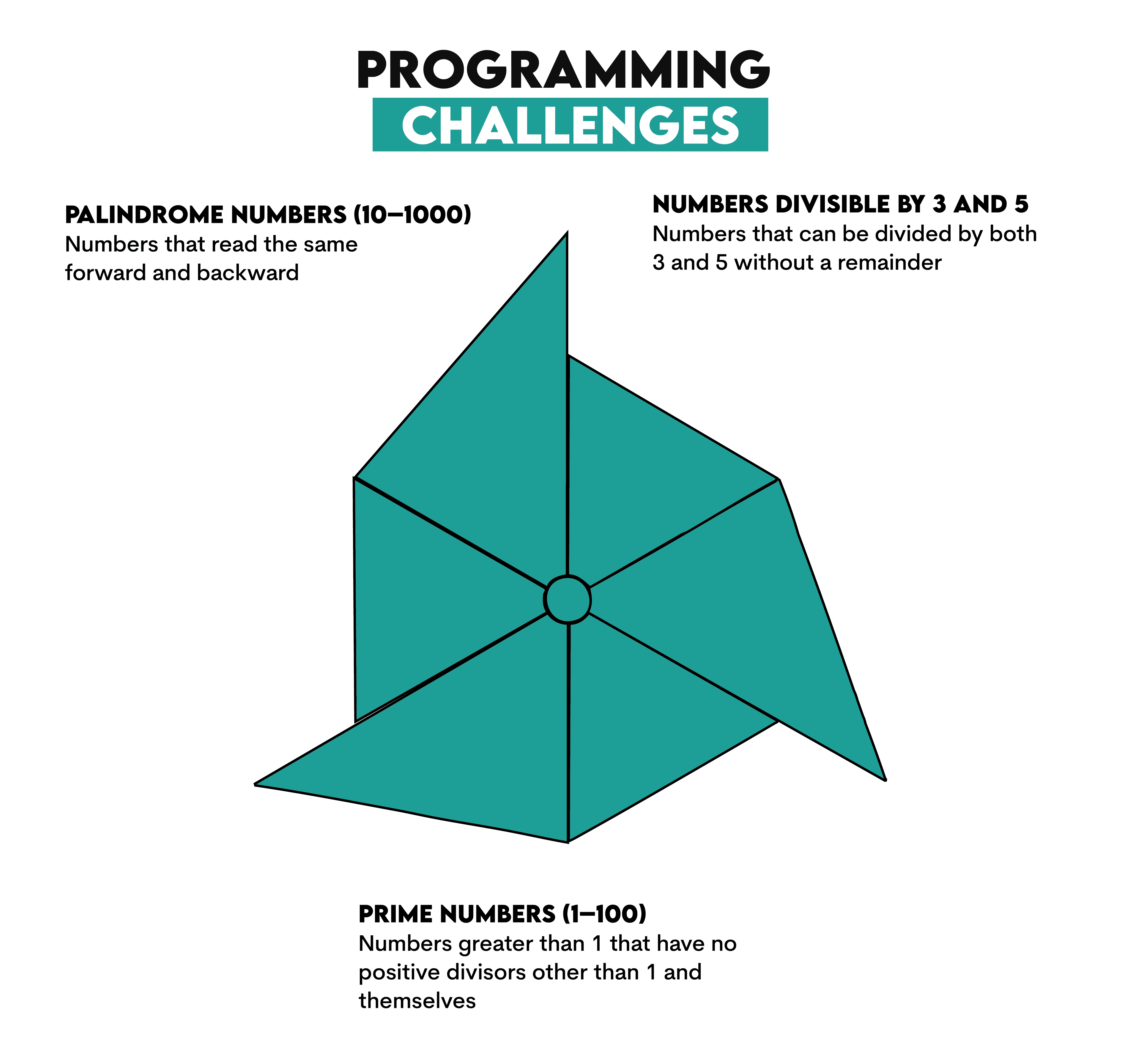
Challenge 1: Numbers Divisible by 3 and 5
Let’s start with the mathematical challenge.
Task: The task is to find all numbers between 1 and 100 that are divisible by both 3 and 5.
Solution Walkthrough: To do that, we need to check every number from 1 to 100.
Let's use the range(1, 101) because the stop value is exclusive.
for num in range(1, 101):
A number is divisible by another if the remainder is 0. We use the modulo operator % to check this. We need both conditions to be true.
if num % 3 == 0 and num % 5 == 0:
If both conditions are met, print the number. We use end=" " to print numbers on the same line, separated by spaces.
Here is the entire code, where we add print for better readability.
print("Numbers divisible by both 3 and 5:")
for num in range(1, 101):
if num % 3 == 0 and num % 5 == 0:
print(num, end=" ")
Here is the output.

Challenge 2: Prime Numbers (1–100)
We found odd numbers between 1 and 10, but let’s find prime numbers between 1 and 100.
Task: A prime number is only divisible by one and itself. The task is to find all primes between 1 and 100.
Solution Walkthrough: We start from 2 because 1 is not considered a prime number. We check every number up to 100; that’s why we set the end as 101.
for num in range(1, 101):
We create a flag variable that starts as True. If we find any divisor, we'll change it to False.
is_prime = TrueWe need to test if any number from 2 up to our current number can divide it evenly. This is a nested loop.
for divisor in range(2, num):
If we find a number that divides evenly (remainder is 0), then our number is not prime. We set the flag to False and break out of the loop early to save time.
if num % divisor == 0:
is_prime = False
break
Here is the entire code where we add print for readability.
print("Prime numbers between 1 and 100:")
for num in range(2, 101):
is_prime = True
for divisor in range(2, num):
if num % divisor == 0:
is_prime = False
break
if is_prime:
print(num, end=" ")
Here is the output.

Challenge 3: Palindrome Numbers (10–1000)
A palindrome number reads the same forward and backward (e.g., 151, 1991).
Task: The task is to find all palindrome numbers between 10 and 1000.
Solution Walkthrough: We iterate through all numbers from 10 to 1000.
for num in range(1, 1001):
To easily reverse and compare, we convert the number to a string.
num_str = str(num)
Python's slice notation [::-1] reverses a string. This reads the string from end to beginning with a step of -1.
num_str[::-1]
If the original string equals the reversed string, it's a palindrome.
if num_str == num_str[::-1]:
print(num, end=" ")
Here is the entire solution, where we add print for readability.
print("Palindrome numbers between 1 and 1000:")
for num in range(1, 1001):
num_str = str(num)
if num_str == num_str[::-1]:
print(num, end=" ")
Here is the output.

Real-World Applications of for Loops and range() in Business
Finding a palindrome or prime numbers is all well, but what is the business use of using for loop and range()?
Here are several examples.
Real-Life Examples
In this section, we’ll solve two real-life interview questions from Uber and Visa and show additional real-life business cases.
Business Case 1: Interview Question from Uber
Find The Combinations
Find all combinations of 3 numbers that sum up to 8. Output 3 numbers in the combination but each combination must use three different rows (do not reuse the same record).
In this question, Uber asked us to find all combinations of three numbers that sum up to 8, without using the same number twice. Let's break down this problem step by step.
Understanding the problem
We have a dataset called transportation_numbers that contains two columns, index and number. Let’s preview it:
Our task is to find every possible combination of three different numbers that add up to exactly 8.
The tricky part? We can't use the same number twice (like 2 + 2 + 4 won't work even if there are multiple 2s in the dataset).
To solve this problem, we will follow the seven steps shown in the image below.
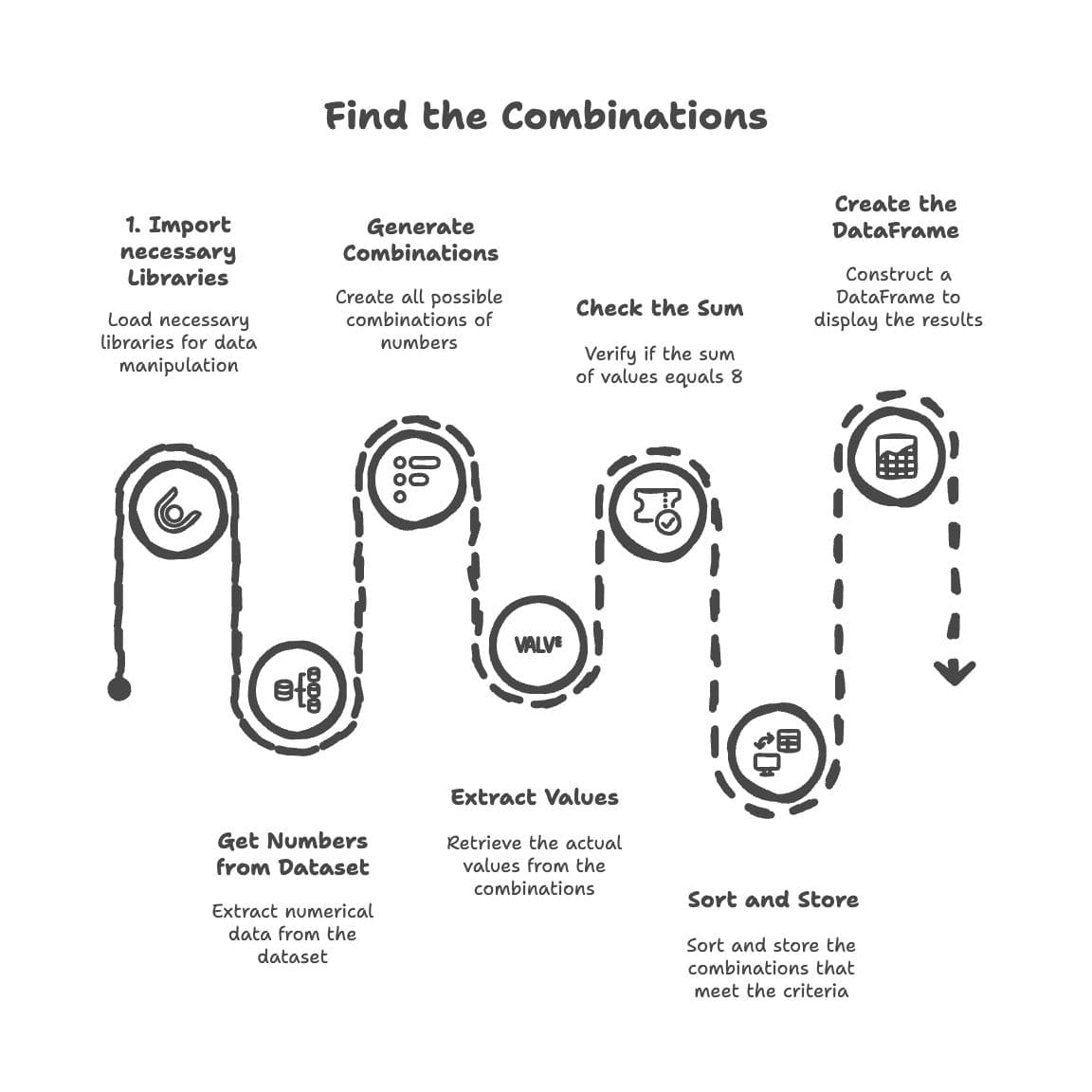
Step 1: Import necessary libraries
We need pandas for data handling and Python's combinations function to generate all possible three-number combinations.
import pandas as pd
from itertools import import combinations
Step 2: Get the numbers from the dataset
We extract the numbers from the dataset and convert them to a list we can work with.
values = transportation_numbers['number'].to_numpy()
The to_numpy() method converts the pandas column into a NumPy array, which works efficiently with the combinations function.
Step 3: Generate combinations
Now we need to create every possible group of 3 numbers from our values. The combinations function does this for us.
triples = []
for i, j, k in combinations(range(len(values)), 3):
Here, range(len(values)) gives us the indices (positions) of all numbers. The combinations function picks three indices at a time. So if we have values [1, 2, 3, 4, 5], it generates combinations like (0,1,2), (0,1,3), (0,1,4).
Step 4: Extract values
For each combination of indices, we get the actual numbers at those positions.
a, b, c = values[i], values[j], values[k]
Step 5: Check the sum
We test if these three numbers add up to 8.
if a + b + c == 8:Step 6: Sort and store
To ensure consistency (so that [1,2,5] and [5,2,1] are treated as the same), we sort the numbers before storing them.
x, y, z = sorted([a, b, c])
triples.append((x, y, z))
Step 7: Create the DataFrame
Finally, we convert our list of valid combinations into a pandas DataFrame with appropriate column names.
result = pd.DataFrame(sorted(set(triples)), columns=['num_1', 'num_2', 'num_3'])
We use set(triples) to remove any duplicate combinations, then sorted() to order them nicely.
Here is the entire solution.
- The dataset has already been loaded as a pandas.DataFrame.
- print() functions and the last line of code will be displayed in the output.
- In order for your solution to be accepted, your solution should be located on the last line of the editor and match the expected output data type listed in the question.
Business Case 2: Interview Question from Visa
Five-Year Sales Growth Regions
Last Updated: March 2025
Find all regions where sales have increased for five consecutive years. A region qualifies if, for each of the five years, sales are higher than in the previous year. Return the region name along with the starting year of the five-year growth period.
In this question, Visa asked us to find all regions where sales have increased for five consecutive years.
For each qualifying region, we need to return the region name along with the starting year of the five-year growth period.
Let's break down this problem step by step.
Understanding the problem
We have a dataset called regional_sales that contains sales data for different regions across multiple years. Let’s preview it:
A region qualifies if, for each of five consecutive years, the sales are higher than the previous year.
We need to identify these regions and specify when their five-year growth streak began. To solve this problem, we will follow the seven steps shown in the image below.
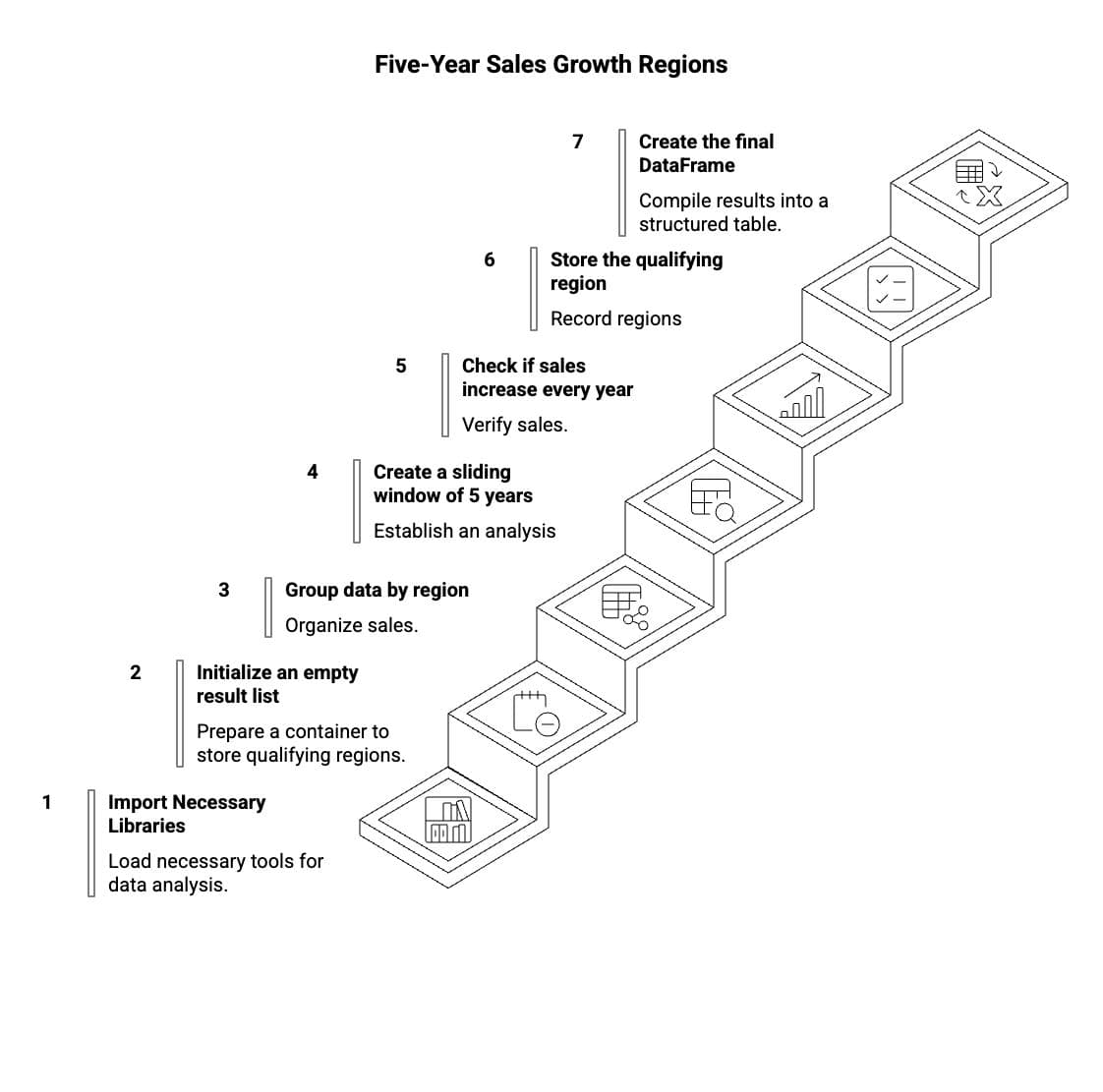
Step 1: Import necessary libraries
We start by importing pandas and organizing our data by region and year, and sorting the values.
import pandas as pd
df = regional_sales.groupby(['region_name', 'year'], as_index=False)['sales'].sum()
df = df.sort_values(['region_name', 'year'])
The sort_values() function arranges our data first by region name, then by year within each region. This ensures we're looking at sales in chronological order for each region.
Step 2: Initialize an empty result list
We need a place to store regions that meet our criteria.
result = []Step 3: Group data by region
We process each region separately to check its sales pattern.
for region, group in df.groupby('region_name', sort=False):
The groupby() function creates separate groups for each region. Setting sort=False maintains our previous sorting order.
Step 4: Create a sliding window of 5 years
For each region, we need to examine every possible five-year period. We use range() to create windows that slide through the years.
for i in range(len(group) - 4):
window = group.iloc[i : i + 5]
If a region has 10 years of data, this creates windows starting at positions 0, 1, 2, 3, 4, 5, and 6. Each window contains exactly five rows of data. The iloc function slices our data by position.
Step 5: Check if sales increase every year
Within each window, we need to verify that each year's sales exceed the previous year's sales.
years = window['year'].tolist()
if (
len(years) == 5
and all(years[j] == years[0] + j for j in range(5))
and all(x < y for x, y in zip(window['sales'], window['sales'][1:]))
):
Let's break this condition down:
len(years) == 5ensures the window includes exactly five years.all(years[j] == years[0] + j for j in range(5))confirms those years are consecutive (for example, 2015–2019 with no gaps).all(x < y for x, y in zip(window['sales'], window['sales'][1:]))checks that sales rise each year without exception, indicating a strictly increasing trend.
Step 6: Store the qualifying region
If a region passes the test, we record it along with the first year of the growth period.
result.append((region, window.iloc[0]['year']))
Step 7: Create the final DataFrame
We convert our results into a properly formatted DataFrame. This final DataFrame lists every region along with the first year of its strictly increasing five-year sales period.
result = pd.DataFrame(result, columns=['region_name', 'start_year'])
Here is the entire solution:
- The dataset has already been loaded as a pandas.DataFrame.
- print() functions and the last line of code will be displayed in the output.
- In order for your solution to be accepted, your solution should be located on the last line of the editor and match the expected output data type listed in the question.
Business Use Case 3: Sending Customer Emails
You’re running a long email campaign and need to send follow-ups to the first 100 customers.
Each email should be sent automatically, and every 10th email should trigger a quick notification so you know the campaign is progressing smoothly.
Let’s see the code.
for customer_id in range(1, 101):
if customer_id % 10 == 0:
print(f"✅ Notification: {customer_id} emails sent successfully!")
Here is the output.
Business Use Case 4: Loading Training and Testing Datasets
Let’s say you’re building a machine learning model and you have multiple training and testing datasets stored separately.
Instead of loading each file manually, you can loop through all of them and load them into memory with a single clean structure.
datasets = ['train_1.csv', 'train_2.csv', 'test_1.csv', 'test_2.csv']
for i in range(len(datasets)):
print(f"Loading dataset: {datasets[i]}")
Here is the output.

With range(), you can iterate over dataset indices, load them dynamically, and even extend this pattern to preprocess or validate each file before training.
Business Use Case 5: Checking Data Quality on Sample Rows
You’re reviewing a dataset for basic quality checks.
For each record, you’ll print a quick validation message. But if the value exceeds a certain threshold, say 15, you’ll log it separately for further review.
data_values = [8, 12, 16, 20, 14, 18]
for i in range(len(data_values)):
if data_values[i] > 15:
print(f" Logged record {i}: value {data_values[i]} exceeds limit")
else:
print(f"Row {i} passed quality check.")
Here is the output.

Conclusion
The hardest truth about for and range() isn’t syntactic, it’s behavioral. You can memorize every parameter of range(start, stop, step), but it won’t matter if you still copy-paste loops, hand-index lists, or accept off-by-one bugs as normal.
The difference between clean Python and brittle Python isn’t clever tricks; it’s repeatable patterns. Use for to express intent. Use range() when the index is the point. Every other case? Loop the items themselves.
Don’t guess the bounds. State them. You already know the basics. What separates solid devs from script-tinkerers is reps. Real ones run loops against real data, watch where they break, and fix the habit that caused it.
FAQs
Can a step be non-integer?
No. It must be an integer. Floats aren’t allowed.
Can you go backwards (negative step)?
Yes. Just use a negative step like range(10, 0, -2).
What happens if stop < start?
If the step is positive, the result will be empty. Python won’t reverse it for you.
Is range() thread safe?
Yes. It’s immutable and safe to share between threads.
Why doesn’t range() accept floats or decimals?
Floats can cause rounding issues. If you need fractions, use numpy.arange() or the decimal module.
Memory usage of range vs list
range() doesn’t store numbers. It makes them when needed. list(range(...)) keeps every number in memory.
Share