Python's Advanced Concepts: Copying, Regex, Decorators


Unlocking Python's Potential: Exploring Advanced Concepts - Shallow vs. Deep Copying, Regular Expressions, and Decorators
Learning advanced Python concepts will improve your coding skills and workflow. Managing data frames with shallow versus deep copying gives you more options. Extracting patterns with regular expressions lets you parse text powerfully. Optimizing code with decorators streamlines your work.
Adopting techniques like these equips you with solid solutions for common challenges. They open the door to writing more flexible, efficient, clean code, allowing more complex and creative projects.
In this article, we will cover these techniques, and afterward, we will see their implementation with Python. Let’s start.

Shallow vs Deep Copying of Python DataFrames
Shallow and deep copying in Python DataFrames are two approaches to generate a new DataFrame from an existing one.
In shallow copying, the new DataFrame shares the same memory location with the original DataFrame, so any changes made to the new DataFrame will affect the original DataFrame.
With deep copying, you get a completely separate copy of the original DataFrame. Changes to this new DataFrame won't impact the original one.
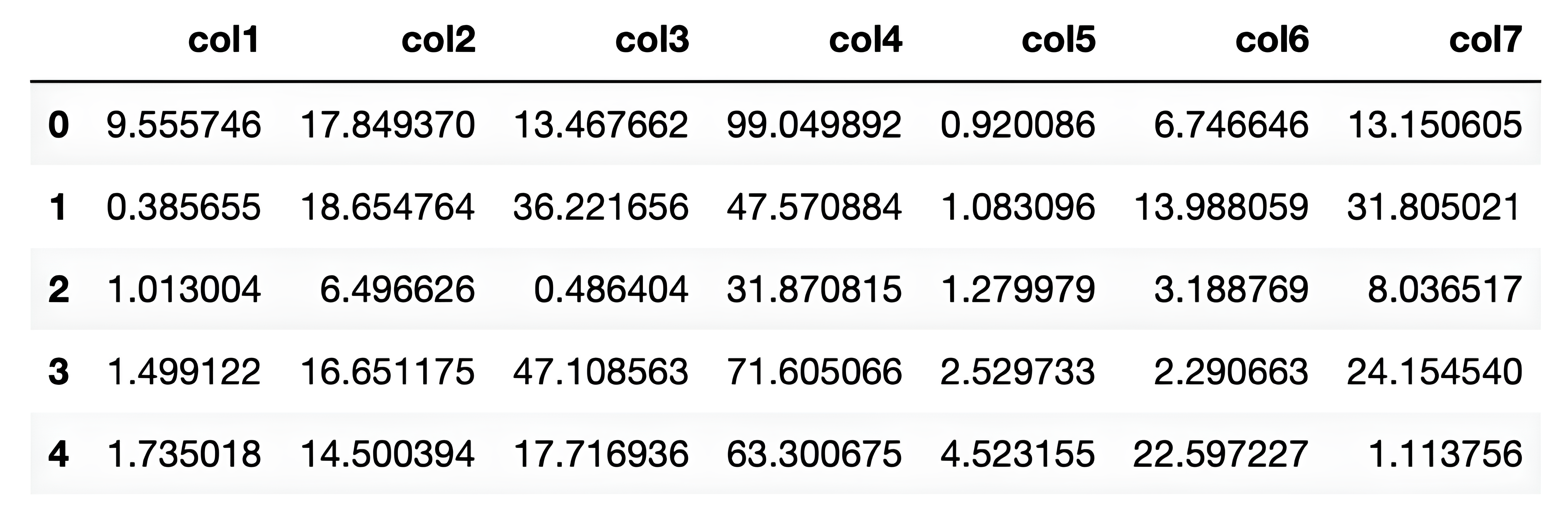
Now let’s code it to understand better. In the following code, a data frame is created with random data and column names.
import pandas as pd
import numpy as np
# Define the column names
columns = ['col1', 'col2', 'col3', 'col4', 'col5', 'col6', 'col7']
# Generate random data for the DataFrame with different scales for each column
data = np.concatenate([
np.random.rand(10000, 1) * 10, # scale of 0-10 for col1
np.random.rand(10000, 1) * 20, # scale of 0-20 for col2
np.random.rand(10000, 1) * 50,# scale of 0-50 for col3
np.random.rand(10000, 1) * 100,# scale of 0-100 for col4
np.random.rand(10000, 1) * 5,# scale of 0-5 for col5
np.random.rand(10000, 1) * 25,# scale of 0-25 for col6
np.random.rand(10000, 1) * 35,# scale of 0-35 for col7
], axis=1)
# Create the DataFrame with the specified columns and data
df = pd.DataFrame(data, columns=columns)
# Print the first few rows of the DataFrame to check if it's created properly
df.head()
Here is the output.

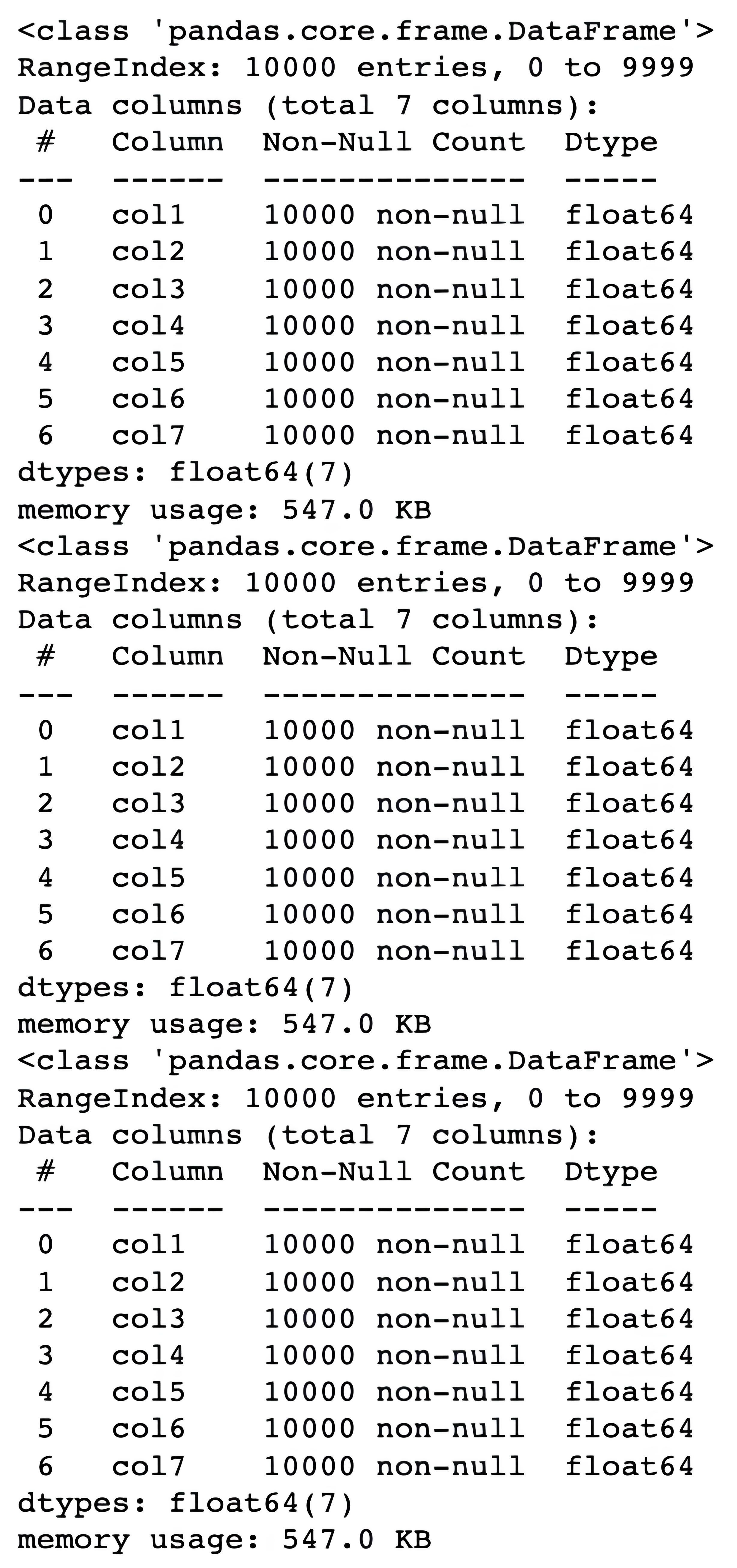
Then two new DataFrames are created, df2 and df3. The difference between df2 and df3 is that df2 is created using the copy() method with the deep argument set to True, which means it is a deep copy of the original DataFrame.
On the other hand, df3 is assigned directly to the original DataFrame, so it is a shallow copy.
The compare() function is used to compare the attributes of the three DataFrames to show that changes made to df2 do not affect the original data frame, while changes made to df3 will affect the original data frame.
Let’s see the code.
# without doing deepcopy
df3 = df
# deepcopy
df2 = df.copy(deep=True)
#Now let’s write a function, which compares our dataframe.
def compare():
df.info()
df2.info()
df3.info()
Alright, now let’s run our custom function.
Here is the code.
compare()
Here is the output.

Alright, now let’s change the df3 to observe the changes.
Here is the code.
df.drop(["col1"], axis = 1, inplace = True)
Now, let’s run our custom compare() function to see the changes.
Here is the code.
compare()
Here is the output.

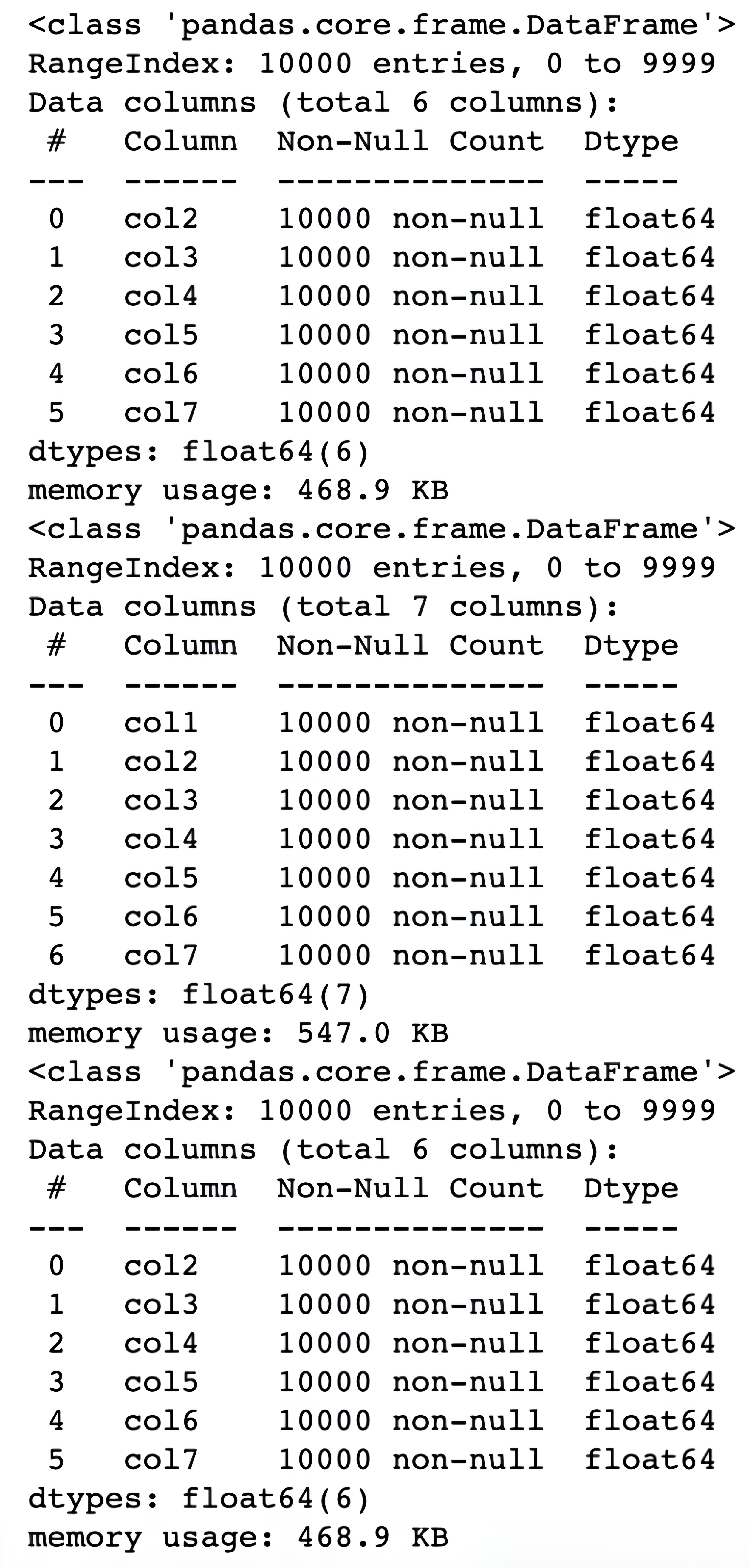
As you can see, df2 does not changes because it is a deep copy, however, when df has changed, df3 changes accordingly, because these data frames share the same memory location since it is a shallow copy of our data frame.
Regular Expressions
A regular expression, often abbreviated as regex or regexp, consists of character sequences that establish a search pattern. In programming languages like Python, they are frequently used to find and alter text.
A regular expression is made up of a combination of special characters and text. Special characters in regex have unique functions and help match certain patterns in text. For instance, the '.' symbol matches any one character, and the '*' symbol matches zero or more of the character that comes before it.
Suppose you have a large dataset of email addresses and want to extract the domain names from these email addresses. You can employ regular expressions to find the pattern corresponding to the domain name.
In this example, I'm using the re-module in Python to define a regular expression that matches email addresses.
But first, let’s load the libraries and download the fraud email dataset from Kaggle here.
This dataset originated from this data set, which contains Nigerian fraudulent emails.
Also, we will filter the data frame to work with fraudulent emails.
Then let’s look at the first 10 rows of the dataset.
Here is the code.
#Fraud Email Dataset, here: https://www.kaggle.com/datasets/llabhishekll/fraud-email-dataset?resource=download
import re
import pandas as pd
#Read df here
df = pd.read_csv("/Users/randyasfandy/Downloads/fraud_email_.csv")
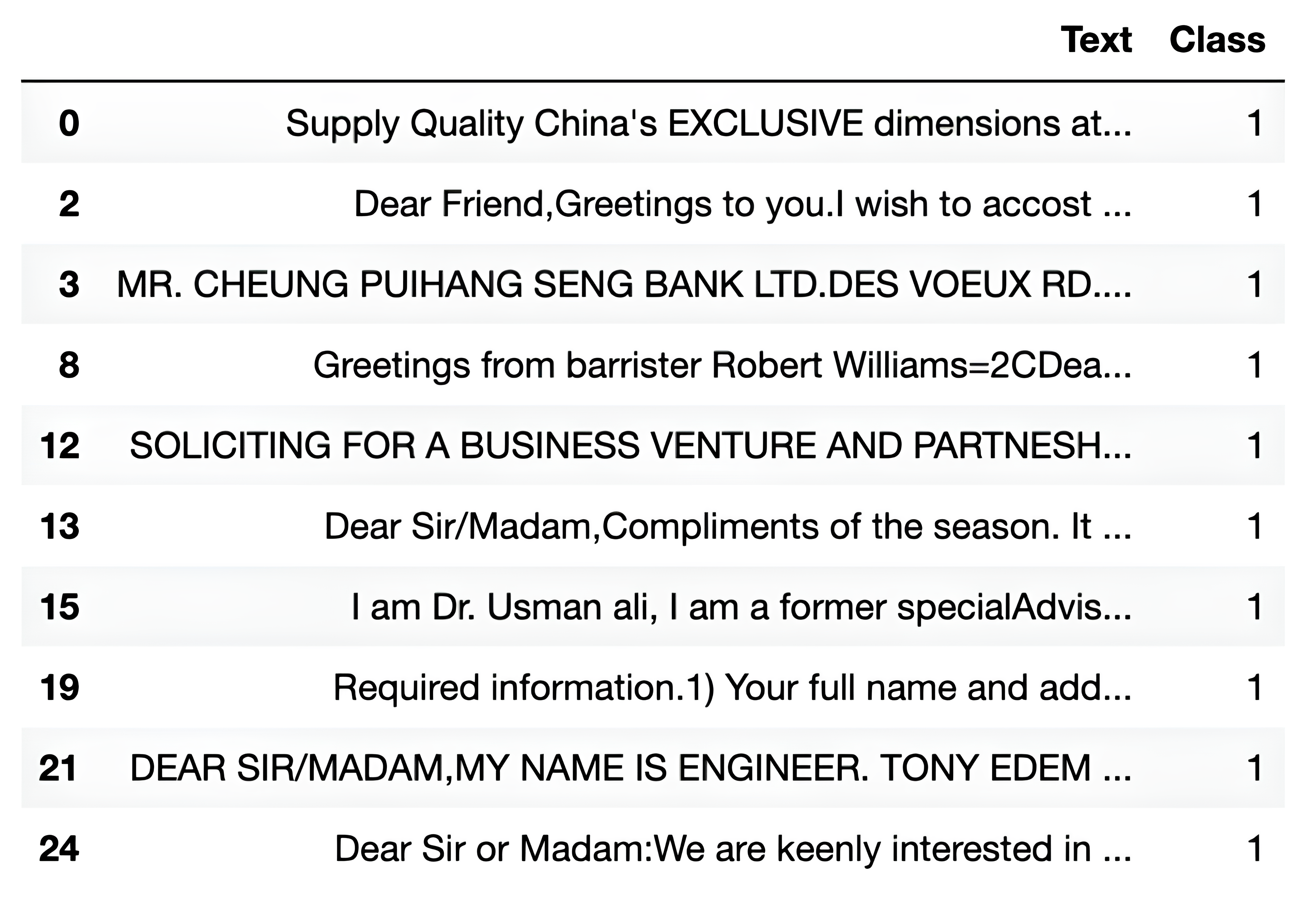
df = df[df["Class"] == 1]
df.head(10)
Here is the output.

First, we will define a regex to create emails from that list. In the following code, we will define a regular expression pattern to match email addresses and extracts all matching emails from the 'Text' column of a DataFrame using the findall() method.
The resulting list of emails is then converted into a flat list and only strings are retained in the final list. Here is the code.
# Define a regular expression to match email addresses
email_regex = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
# Extract emails from the 'Text' column of the DataFrame
emails = df['Text'].str.findall(email_regex)
# Print the resulting list of emails
email_df = emails.explode()
email_list = email_df.tolist()
email_list = [email for email in email_list if isinstance(email, str)]
email_list
Here is the output.

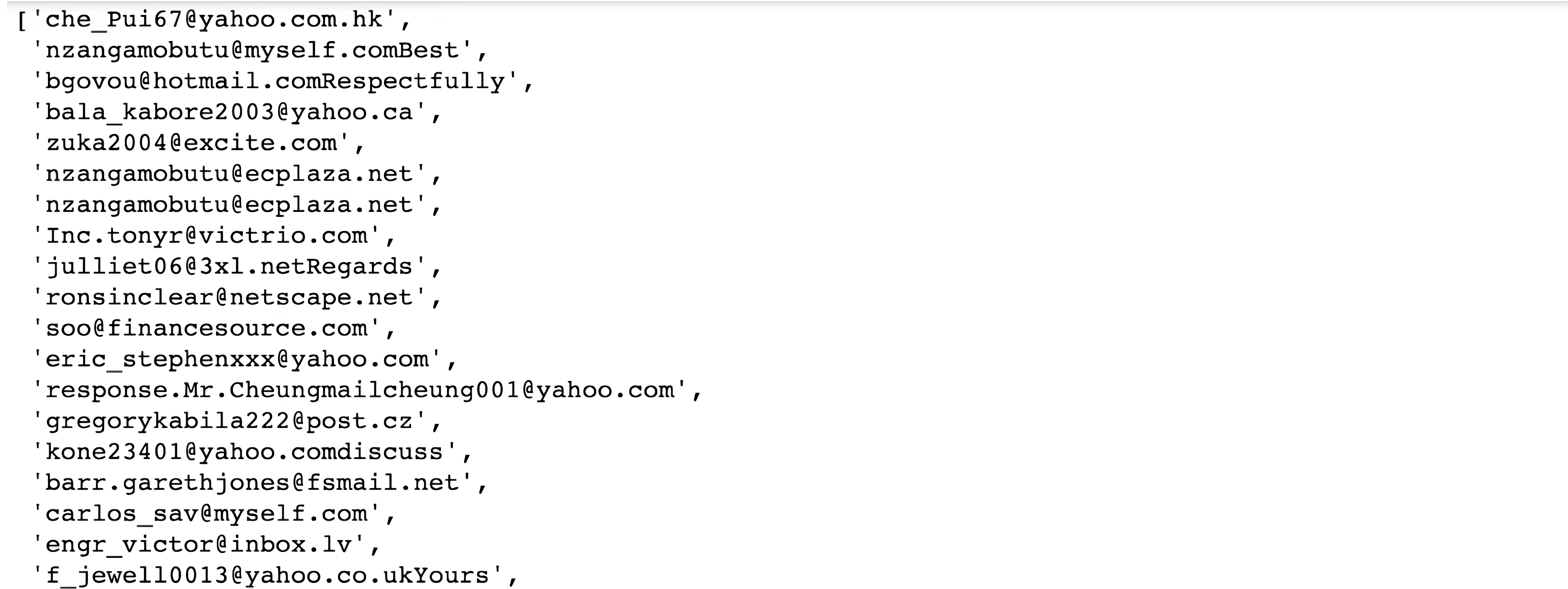
Actually, this is just a small part of our list. Let’s look at the length of our list.
Here is the code.
len(email_list)
Here is the output.


Alright, now it is time to parse this email list by using another regex.I defined a sample list of email addresses to search. Next, I create an empty list to store the extracted data, which are name, domain name, and tld(.com, .gov).
I loop through the email list and use the re.search function to search for the regular expression in each email address. If a match is found, I extract the domain name, tld, name and add it to the data list. After that, I will turn this into a pandas data frame.
By the way, if you want to learn more about pandas, here are the Types of Pandas Joins in Python. Okay, now let’s see our code.
import pandas as pd
import re
# Define a regular expression to match email addresses and extract name, domain, and TLD
regex = r"(\b[A-Za-z0-9._%+-]+)@([A-Za-z0-9.-]+\.([A-Z|a-z]{2,}))\b"
# Create an empty list to store the extracted data
data_list = []
# Loop through the email list and extract the name, domain, and TLD for each email address
for email in email_list:
# Search for the regular expression in the email address
match = re.search(regex, email)
# If a match is found, extract the name, domain, and TLD and add them to the data list
if match:
name = match.group(1)
domain = match.group(2)
tld = match.group(3)
data_list.append((name, domain, tld))
# Create a Pandas DataFrame with the extracted data
df = pd.DataFrame(data_list, columns=["name", "domain", "tld"])
# Print the DataFrame
df.head()
Here is the output.


In conclusion, regular expressions can be used in various applications, such as data cleaning, text parsing, and pattern matching. By learning how to use regular expressions in Python, you can manipulate and extract information from text data in a powerful and flexible way.
Decorators
A decorator is a function that takes another function as input and returns another function as output. The idea behind decorators is to modify the behavior of the original function without changing its code.
To explain this, let’s look at one example from machine learning.
Let’s load the libraries.
import time
import math
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import precision_score, recall_score, f1_score
Here, we will define a decorator function calculate_time that takes another function func as an argument. This decorator function returns another inner function inner1 which calculates the time taken by func when it is executed.
The inner function calculates the start time and end time of the function and calculates the time difference, which is the time taken by the function. The time is rounded to 2 decimal places and then converted to a string format with the suffix "seconds."
Finally, the time taken is printed along with the name of the function.Here is the code.
def calculate_time(func):
def inner1(*args, **kwargs):
begin = time.time()
func(*args, **kwargs)
end = time.time()
time_spent = end - begin
time_spent = round(time_spent,2)
time_spent = str(time_spent) + str("seconds")
print("Total time taken in ",func.__name__, time_spent)
return inner1
The decorator “calculate_time” is used to decorate the ”logistic_regression_scikit” function.
This means that when the logistic_regression_scikit function is executed, it will first execute the “calculate_time” function, which will then calculate the time taken by the “logistic_regression_scikit” function.
The “logistic_regression_scikit” function performs logistic regression using the scikit-learn library. It loads the iris dataset, splits it into training and testing sets, and performs a grid search to find the best hyperparameters for the logistic regression model.
The logistic regression model is then fit to the training data and evaluated on the test data. The precision, recall, and F1 score of the model are calculated and printed. Here is the code.
@calculate_time
def logistic_regression_scikit():
# Load the iris dataset
iris = datasets.load_iris()
# Split the dataset into train and test sets
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0)
# Define the hyperparameter grid for logistic regression
param_grid = {'C': [0.1, 1, 10, 100, 1000, 10000, 100000, 100000], 'solver': ['newton-cg', 'lbfgs', 'sag', 'saga']}
# Create a logistic regression model
logistic_regression = LogisticRegression(solver='lbfgs', max_iter=10000,multi_class='auto')
# Instantiate the grid search model
grid_search = GridSearchCV(estimator=logistic_regression, param_grid=param_grid, cv=5)
# Fit the grid search to the training data
grid_search.fit(x_train, y_train)
# Get the best hyperparameters
best_params = grid_search.best_params_
# Create a new logistic regression model with the best hyperparameters
logistic_regression = LogisticRegression(**best_params)
# Fit the model with the best hyperparameters on the training data
logistic_regression.fit(x_train, y_train)
# Evaluate the model on the test data
y_pred = logistic_regression.predict(x_test)
precision = precision_score(y_test, y_pred, average='macro')
recall = recall_score(y_test, y_pred, average='macro')
f1 = f1_score(y_test, y_pred, average='macro')
print("Precision: {:.2f}".format(precision))
print("Recall: {:.2f}".format(recall))
print("F1 Score: {:.2f}".format(f1))
Alright, we define our custom function. Now let’s test it. Here is the code.
logistic_regression_scikit()
Here is the output.


It looks like this function takes 7.74 seconds times to work.
It is really quick, right? Yet when it comes to applying grid search with many different parameters, or deep learning code, this time might increase drastically, so when launching a long code in your project it will be good to define a custom function and run it as a decorator in your code to measure the time spent.
Conclusion
Whether a beginner or an expert, adding these concepts will level up your Python skills. As Python expands, so will its flexible advanced capabilities. If you are eager to learn all advanced concepts, here you can read this one → “A Comprehensive Guide to Advanced Python Concepts”.
Regularly studying and practicing them will help both your current work and long-term growth as a Python programmer. So be sure to visit our platform to hone your skills. See you there!
FAQ
What are the hardest concepts in Python?
In Python, understanding pointers and memory management can be complex. Asynchronous programming and metaclasses can be really tough to grasp for beginners. But with good planning and enough exercise, these concepts can be understood.
How can I be advanced in Python?
To become proficient, practice by building various projects and exploring real-world problems, solving real-life Python interview questions. Reading code from experienced developers can help you learn new tricks.
What should an advanced Python developer know?
An advanced Python developer should master algorithms, data structures, and best coding practices. Knowing how to optimize code, understanding testing frameworks, and using version control systems like Git is essential.
Latest Posts:



Share