How to Effectively Use the PySpark 'isin' Function

Categories:
 Written by:
Written by:Nathan Rosidi
PySpark isin explained with filtering examples using lists, variables, combined columns, and a real interview-style case study
Filtering is often used in data analysis, and the PySpark isin function offers a clean and efficient way to do it. In this guide, we will explore what it is, how it can be used in various examples, and apply it through an interview question to test our skills.
What is the isin Function in PySpark?
PySpark's isin function helps you filter a dataset using a list of options. If a value matches any option you provide, the output will be true; otherwise, it will be false. If you’re new to PySpark or want a complete overview of its capabilities, check out What Is PySpark for a deeper introduction before diving into specific functions like isin.
Let’s say we have a dataset that includes three different fruits, as shown below.
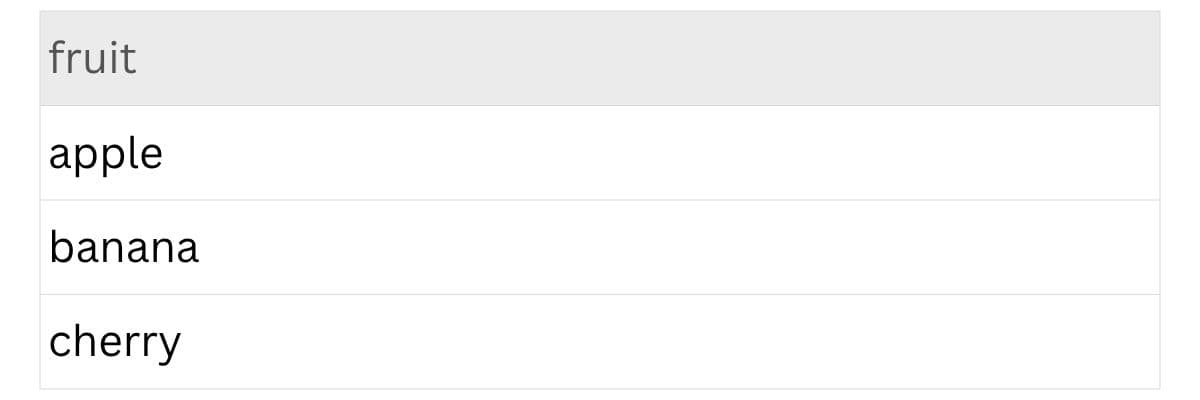
Let’s apply the isin method on this column and see what it returns. Here is the code.
df['fruit'].isin(['banana', 'cherry'])Here is the output.
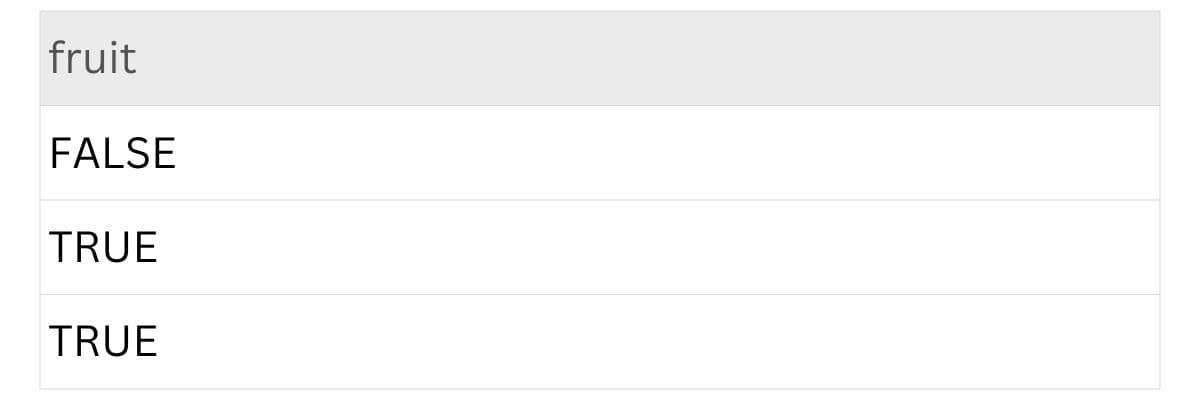
The screenshot above shows whether each value in the column matches anything in the list we defined. Since we only checked for ‘banana’ and ‘cherry’, ‘apple’ does not match and returns False, while the other two return True.
Why Use PySpark isin?
It can be challenging to understand repeating or conditions when you have to match a column against several values. The isin function keeps your code simpler and helps clarify the reasoning.
Additionally, it performs well with filter operations, especially in pipelines.
Basic Example of PySpark isin
Let’s work with a set of product categories. Here is our dataset.
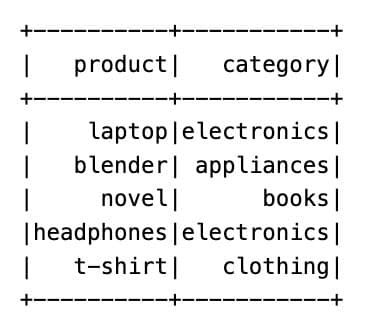
Next, we will filter the dataset and return only rows where the category is either “electronics” or “books”. Here is the code.
filtered = df.filter(col("category").isin("electronics", "books"))
filtered.show()
Here is the output.

We are only interested in “electronics” and “books”, so only those rows appear in the result. Others like “appliances” or “clothing” are excluded.
Using PySpark isin with a List Variable
In some cases, you don’t want to hard-code values into isin. You can pass a list variable instead, especially when your list comes from user input or another dataset. We will define a list of allowed categories as a Python variable and use it inside the isin function.
Here is our dataset now.
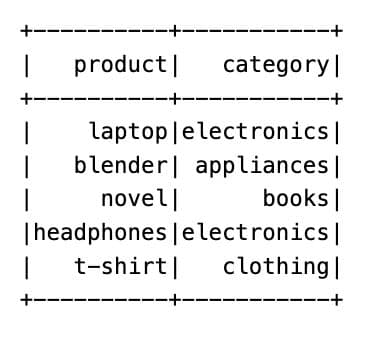
Let’s use isin with the list. Here is the code.
# List variable for filtering
target_categories = ["electronics", "books"]
# Use isin with the list
filtered = df.filter(col("category").isin(target_categories))
filtered.show()
Here is the output.
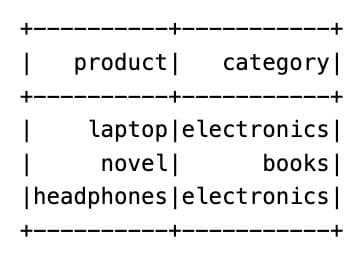
In this example, we did not write the values inside the PySpark isin; we passed a list variable. This gives more flexibility if you need to reuse or change it later.
Using PySpark isin with Multiple Columns
You may need to see if a combination of two or more columns matches some known values. Pyspark does not support applying isin across multiple columns, but we can do this by working around it.
Here is our dataset.
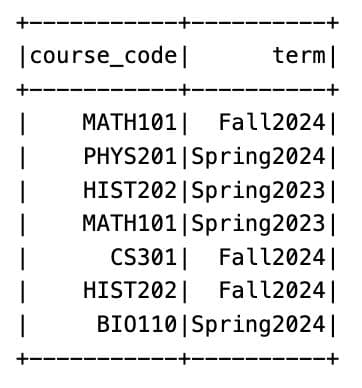
We will create a new column by combining two fields, using the "isin" function to check for specific combinations. Here is the code.
# Combine course code and term
df_combined = df.withColumn("course_key", concat_ws("_", col("course_code"), col("term")))
# Define allowed course offerings
allowed_courses = ["MATH101_Fall2024", "HIST202_Spring2023", "CS301_Fall2024"]
# Filter rows based on valid course-term combinations
filtered = df_combined.filter(col("course_key").isin(allowed_courses))
filtered.select("course_code", "term").show()
Here is the output.
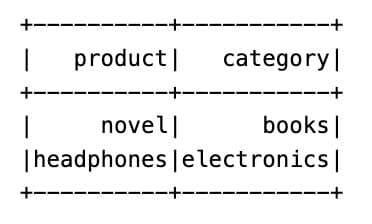
Here, we created a helper column that joins the product and category with an underscore, and then we filtered only those rows that match specific full combinations from the list.
Applying PySpark isin in a real dataset to solve a practical data analysis problem
In this real-world interview question, PySpark isin helps us quickly filter Apple device users from a large dataset.
Apple Product Counts
We’re analyzing user data to understand how popular Apple devices are among users who have performed at least one event on the platform. Specifically, we want to measure this popularity across different languages. Count the number of distinct users using Apple devices —limited to "macbook pro", "iphone 5s", and "ipad air" — and compare it to the total number of users per language.
Present the results with the language, the number of Apple users, and the total number of users for each language. Finally, sort the results so that languages with the highest total user count appear first.
Link to the question: https://platform.stratascratch.com/coding/10141-apple-product-counts
In this question, we are analyzing user data to understand how popular Apple devices are among users.
The output should include the number of Apple users, the total number of users for each language, and it should be sorted so that languages with the highest total user count appear first.
Here we will use the isin function to filter users who used Apple devices like “MacBook Pro”, “iPhone 5s”, and “iPad Air”.
The code below does three things:
- Merging user and event data
- Filtering only Apple device users using isin
- Grouping and joining to get the final result
Here is the code.
Run the code above to see the output.
The output contains a table with three columns, and each row represents a language with the number of Apple users and the total user count for that language.
Conclusion
The isin function in PySpark is a simple way to filter data against a list of values. You can use it for fixed lists, variables, or even combinations of columns with a small workaround. It helps keep your code short and easy to read, while still performing well on large datasets. When you are working on small examples or real analysis tasks, knowing how to apply PySpark isin will make your filtering steps faster and more reliable.
FAQs
When should I use the PySpark isin() function?
To filter the dataset by using a list, it is better to use the isin function.
Can’t I just use == instead?
You can use == for a single value, but for multiple values, isin() is cleaner and more efficient.
Should I pass the list directly or use a variable?
Both can work. But using a list variable would make it more flexible, especially if the values are dynamic.
Can I use PySpark isin() across multiple columns?
It works on a single column. However, you can create a new column and apply isin() to it as a workaround.
Is PySpark isin() performance-friendly for big data?
Yes, isin() is optimized to perform well on big datasets in PySpark.
Share