NumPy Array Slicing in Python

 Written by:
Written by:Nathan Rosidi
NumPy Array Slicing in Python: exploring its syntax, versatility, and the profound impact it can have on data manipulation and analysis.
"Data is the new oil," they say, and indeed, in the realm of artificial intelligence and machine learning, this oil powers the engines. Mastering the art of NumPy array slicing is akin to refining this oil, a skill that can significantly enhance the efficiency and effectiveness of your data manipulation tasks.
In this article, I'll share insights into the powerful technique of NumPy array slicing, offering you a toolkit for navigating the vast sea of data with precision and agility. Let’s start!
What is NumPy Array Slicing in Python?
NumPy array slicing allows you to access different elements of a list. It will enable you to modify data more efficiently. Slicing makes it easy to operate if you are working with a one-dimensional or multi-dimensional array or sometimes even in data frames.
The slicing operation returns a view of the original array, which means that modifications to the sliced array will affect the original array. This behavior ensures memory efficiency but requires careful handling to avoid unintended changes.
Basic Syntax of NumPy Array Slicing in Python

The basic syntax for array slicing in NumPy follows the format: array[start:stop:step]. Here's what each part means:
- start: The index at which the slice starts. If omitted, it defaults to the beginning of the array.
- stop: The index at which the slice ends. The slice does not include this index. If omitted, slicing goes up to and including the last element.
- step: Specifies the step size between each index selected. If omitted, the step size defaults to 1.
In the given example, we first create a one-dimensional NumPy array with integers from 0 to 9 using np.arange(10).
Then, we slice this array from index 1 to index 5 (inclusive of 1 and exclusive of 6), resulting in a new array sliced_arr that contains the elements [1 2 3 4 5].
This shows how slicing allows us to easily select a subset of an array's elements based on their indices.
import numpy as np
# Create a one-dimensional array
arr = np.arange(10) # Array of integers from 0 to 9
print("Original array:", arr)
# Slice from index 1 to index 5
sliced_arr = arr[1:6]
print("Sliced array:", sliced_arr)
Here is the output.

Simple Slicing of 1D Arrays
Slicing 1D arrays in NumPy is straightforward. You specify the start, stop, and step within square brackets to select a portion of the array.
In the following code;
- The first slice arr[:5] selects the first five elements of the array, demonstrating how omitting the start index defaults to 0.
- The second slice arr[5:] selects elements from index 5 to the end, showing that omitting the stop index includes all elements to the array's end.
- The third slice arr[3:8:2] selects every second element between index 3 and 7, illustrating how the step size alters the selection.
Let’s see the code.
import numpy as np
# Create a one-dimensional array
arr = np.arange(10)
# Select items at the beginning to index 4
slice1 = arr[:5]
print("Array up to index 4:", slice1)
# Select items from index 5 to the end
slice2 = arr[5:]
print("Array from index 5:", slice2)
# Select items from index 3 to 7 with a step of 2
slice3 = arr[3:8:2]
print("Array from index 3 to 7 with step 2:", slice3)
Here is the output.
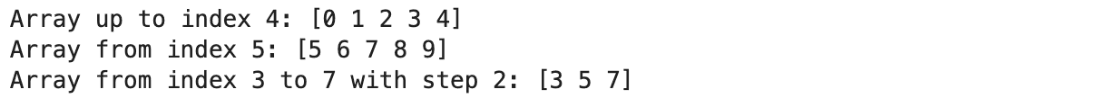
Slicing of 2D Arrays
Slicing 2D arrays in NumPy allows you to access subsets of the array's rows and columns. The syntax extends to array[row_start:row_stop:row_step, column_start:column_stop:column_step], allowing for versatile data manipulation.
Consider a 2D array representing a matrix. We'll slice it to access specific rows, columns, and submatrices. Here is what we will do:
- The matrix[1, :] slice selects all elements in the second row, showing how to slice rows.
- The matrix[:, 2] slice selects all elements in the third column, demonstrating column slicing.
- The matrix[:2, :3] slice selects the first two rows and the first three columns, creating a submatrix.
Let’s see the code.
import numpy as np
# Create a 2D array (3x4 matrix)
matrix = np.array([[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]])
# Select the second row
row2 = matrix[1, :]
print("Second row:", row2)
# Select the third column
col3 = matrix[:, 2]
print("Third column:", col3)
# Select a submatrix (first two rows, first three columns)
submatrix = matrix[:2, :3]
print("Submatrix of first two rows and three columns:", submatrix)
Here is the output.

Advanced Slicing Techniques
NumPy offers more sophisticated slicing techniques that allow for even greater flexibility and efficiency in data manipulation.
Slicing using steps
You can use steps in slicing to skip elements within the specified range.
# Create a 1D array
arr = np.arange(10)
# Select elements with a step of 3
step_slice = arr[::3]
print("Elements with a step of 3:", step_slice)
Here is the output.

Slicing with Negative Indexes
Negative indices allow you to start counting from the end of the array.
# Select the last three elements
neg_slice = arr[-3:]
print("Last three elements:", neg_slice)
Here is the output.

Boolean Indexing
Boolean indexing lets you select elements based on a condition.
# Create a 2D array
matrix = np.array([[1, 2], [3, 4], [5, 6]])
# Select elements greater than 3
bool_idx = matrix > 3
print("Elements greater than 3:", matrix[bool_idx])
Here is the output.

Fancy Indexing
Fancy indexing involves passing arrays of indices to select multiple elements.
# Select elements at specified positions
fancy_index = arr[[2, 5, 6]]
print("Elements at positions 2, 5, and 6:", fancy_index)
Here is the output.
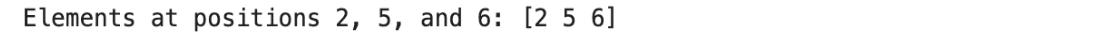
Modifying Shapes
You can use slicing to modify the shape of arrays, such as flattening or reshaping.
# Flatten the matrix
flat_matrix = matrix.flatten()
print("Flattened matrix:", flat_matrix)
# Reshape the array
reshaped_arr = arr.reshape((2, 5))
print("Reshaped array into 2x5 matrix:", reshaped_arr)
Here is the output.
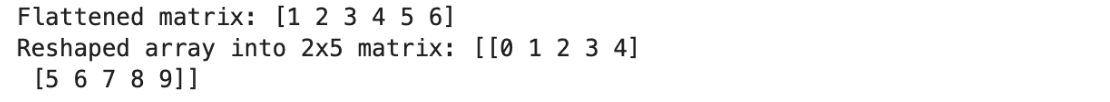
Real-world Applications of Array Slicing in Python
Filtering Data
Filtering data is a fundamental step in data preprocessing, helping in narrowing down the dataset to relevant samples based on specific criteria. For instance, in classification tasks, one might want to analyze data from a single class separately or remove samples that do not meet certain conditions.
We'll use the Iris dataset to demonstrate filtering. This dataset contains measurements of 150 iris flowers from three species. We'll filter the dataset to select only the samples belonging to the 'setosa' species.
# Flatten the matrix
flat_matrix = matrix.flatten()
print("Flattened matrix:", flat_matrix)
# Reshape the array
reshaped_arr = arr.reshape((2, 5))
print("Reshaped array into 2x5 matrix:", reshaped_arr)
We used the Iris dataset to demonstrate filtering. This dataset contains measurements of 150 iris flowers from three species. We filtered the dataset to select only the samples belonging to the 'setosa' species. Let’s see the output.

Sampling for Machine Learning
Creating representative training and testing datasets in machine learning is vital for developing robust models. Sampling techniques, such as train-test split, ensure that models are not overfitting and can generalize well to unseen data.
We'll use the Breast Cancer dataset to demonstrate how to split the dataset into training and testing subsets. This dataset is used for binary classification, where the goal is to predict whether a tumor is malignant or benign.
Let’s see the code.
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=42)
print("Training set size:", X_train.shape[0])
print("Test set size:", X_test.shape[0])
Here is the output.

Dimensionality Reduction
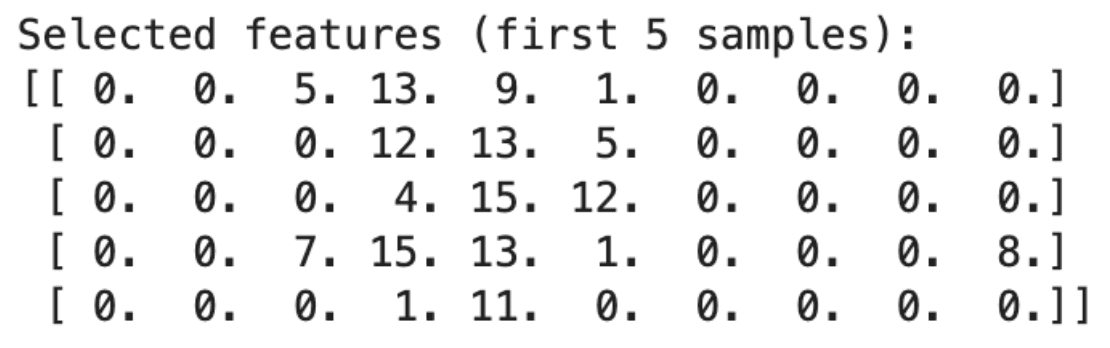
Dimensionality reduction is a process used to reduce the number of input variables in a dataset. By selecting a subset of relevant features or transforming them, one can simplify the model, reduce overfitting, and improve performance.
The Digits dataset, consisting of 8x8 pixel images of handwritten digits, is ideal for demonstrating dimensionality reduction. We'll select a subset of features from the dataset for analysis, reducing the complexity of the data.
Let’s see the code.
# Flatten the matrix
flat_matrix = matrix.flatten()
print("Flattened matrix:", flat_matrix)
# Reshape the array
reshaped_arr = arr.reshape((2, 5))
print("Reshaped array into 2x5 matrix:", reshaped_arr)
Here is the output.
Anomaly Detection
Anomaly detection is used to identify unusual data points that deviate significantly from the majority of the data. Detecting anomalies is crucial in many fields, such as fraud detection, fault detection, and outlier removal before further data analysis.
We'll identify anomalies in the sepal length of Iris flowers. Anomalies will be defined as sepal lengths that are significantly higher or lower than the average.
from sklearn.datasets import load_iris
import numpy as np
# Load Iris dataset
iris = load_iris()
sepal_length = iris.data[:, 0] # Sepal length is the first column
# Compute the mean and standard deviation
mean_sepal_length = np.mean(sepal_length)
std_sepal_length = np.std(sepal_length)
# Identify anomalies as those beyond 2 standard deviations from the mean
anomalies_filter = np.abs(sepal_length - mean_sepal_length) > 2 * std_sepal_length
anomalies = sepal_length[anomalies_filter]
print("Anomalous sepal lengths:", anomalies)
Here is the output.
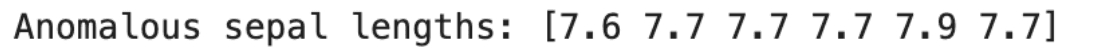
Data Cleaning
Data cleaning is essential for improving the data quality by removing inaccuracies, inconsistencies, and outliers. In datasets like the Iris dataset, data cleaning can help remove or correct measurements significantly different from others, ensuring a more accurate analysis.
We'll clean the Wine dataset by focusing on a specific chemical property, such as alcohol content. Outliers will be defined as samples with alcohol content significantly different from the majority, using the same outlier detection method based on the interquartile range (IQR).
from sklearn.datasets import load_wine
import numpy as np
# Load the Wine dataset
wine = load_wine()
wine_data = wine.data
alcohol_content = wine_data[:, 0]
# Calculate IQR for alcohol content and filter outliers
q1, q3 = np.percentile(alcohol_content, [25, 75])
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
# Apply filter for outliers
filtered_alcohol_content = alcohol_content[(alcohol_content > lower_bound) & (alcohol_content < upper_bound)]
# Determine the number of removed samples
original_count = len(alcohol_content)
filtered_count = len(filtered_alcohol_content)
removed_samples = original_count - filtered_count
print(f"Original sample count: {original_count}, After cleaning: {filtered_count}")
print(f"Removed samples: {removed_samples}")
Here is the output.

Even if any data is not removed for this example, try using this technique in your example and see what has changed.
If you want to know more about NumPy, check this one.
Conclusion
We've gone through the intricacies of NumPy array slicing, exploring its syntax, versatility, and the profound impact it can have on data manipulation and analysis.
Remember, slicing is not just about cutting through data; it's about sculpting your dataset into a masterpiece of insights and discoveries. Practice is paramount in mastering these techniques; the more you experiment with slicing, the more adept you'll become at unveiling the hidden stories within your data.
Share