Microsoft SQL Interview Questions for Data Science Position


Categories:
 Written by:
Written by:Vivek Sankaran
In this article, we have discussed real-life Microsoft SQL interview questions with detailed solutions for the Data Science position.
Recent Microsoft SQL interview questions for the Data Science position
In this article, we discuss real-life Microsoft SQL interview questions with detailed solutions for the Data Science position. We solve these SQL interview questions step by step and we will also provide you with a process to solve similar problems and optimize code once you get the solution.
Data Science Role at Microsoft
Microsoft operates in a range of technology domains serving both B2B and B2C segments. The Data Science role at Microsoft is therefore dependent on the business unit that you are interviewing for as well as the seniority of the role.
Areas Tested in Microsoft SQL Interviews
The main concepts tested in the Microsoft SQL Data Science Interviews include.
- Subquery
- Window Functions
- DENSE_RANK()
- CTE
- Group By
- Joins
- Datetime functions
You can practice these and more such questions on the StrataScratch platform and become interview ready.
Microsoft SQL Interview Question
Last Updated: March 2021
Write a query to identify all companies (customer_id) whose mobile usage ranks in the bottom two positions. Mobile usage is the count of events where client_id = 'mobile'. Companies with the same usage count should share the same rank, and all companies in the bottom two ranks should be included. Return the customer_id and event count, sorted in ascending order by the number of events.
You can try to solve this Mobile Usage question by Microsoft
Dataset
Assumptions
The last statement of this Microsoft SQL interview question should tell you that there are going to be edge cases. Therefore, you need to incorporate that in your assumptions. Further, it is advisable that you mention it while confirming your assumptions to showcase that you have read the problem properly.
Since you typically will not have access to the underlying data in the interview, you will have to ensure that your solution boundaries are reasonably well defined. The first thing that strikes you when you look at the schema is the number of id fields that are present in the data. It will not be a bad idea to confirm with the interviewer regarding the assumptions that you make and their validity.
What are the assumptions on the data and the table?
Let us look at each of the id fields.
- id, time_id and user_id appear to be the serial number, timestamp, and user id fields. They can be safely ignored for solving this problem.
- customer_id appears to be the company identifier. This is our grouper field for the data. We will aggregate the data, grouping by this field.
- client_id this field represents the platform identifier – mobile, desktop, etc. We need to subset the data based on this field, since we want to extract only the mobile client_id as per the problem.
- event_id would be the identifier for an event and event_type will describe the type of event.
Again, please clarify these assumptions with the interviewer to ensure that you do not end up on the wrong track.
Logic
Once we get a handle on the data, this Microsoft SQL interview problem appears quite straightforward. A prime example of how the right assumptions can make your life quite easy.
- We need to subset the events based on client_id = ‘mobile’
- Then, count the number of events grouped by customer_id
- Rank the companies (customer_id) in the ascending order of the number of events.
- Select the lowest two (in this case companies ranked 1 and 2) from the data.
Wait!! There is a sting in the tail.
We were required to choose the appropriate ranking algorithm for this. It is mentioned that in case of a tie, list all the companies with the same rank. So our plain vanilla RANK() function will not suffice. We need to use the DENSE_RANK() function. Let me illustrate the difference with a simplified dataset.
Suppose we have a table of time taken to complete a task by a set of students. A simple rank function will give us results akin to this.

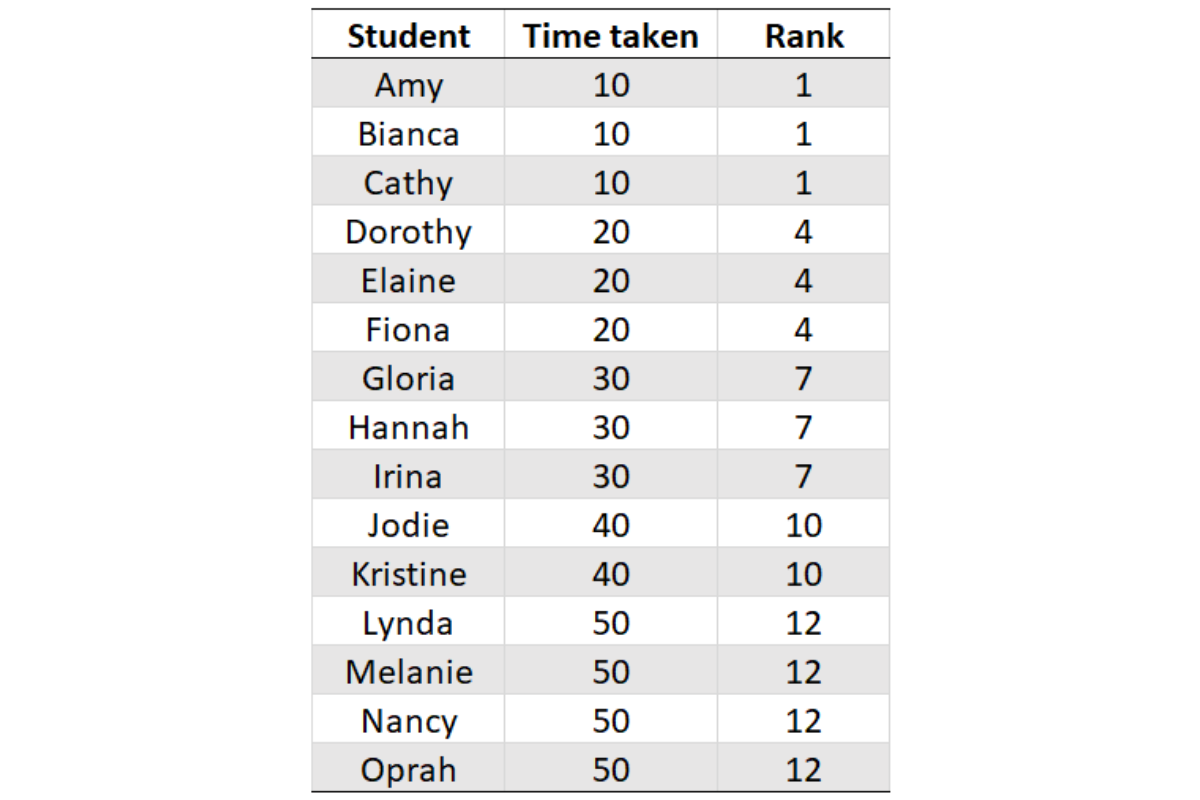
If you observe carefully, three girls – Amy, Bianca and Cathy are tied for the first spot. Hence, the next rank is 4. Our interview question however requires us to list the bottom two companies by number of events. In case there is a tie for the first spot, there will not be any second spot. However, there will be a second lowest event and we are required to report that. We will need something like this.
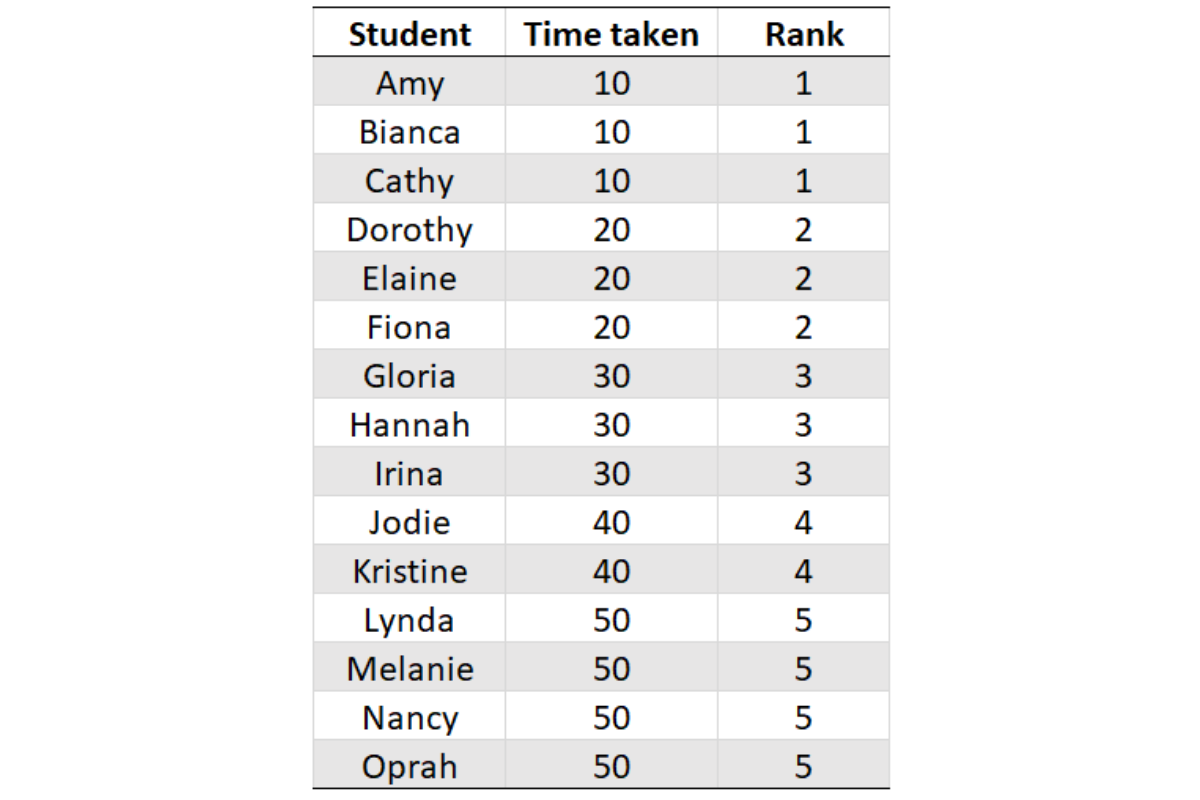
To accomplish this in SQL, we use the function DENSE_RANK(). As per the documentation, DENSE_RANK() ranks the values without leaving any gaps. For most cases, RANK() and DENSE_RANK() will return the same values. However, in case of a tie, there will be dissimilarities. This fine distinction is the difference between the complete solution and an incomplete one.
Now that we have fixed our logic, let us move forward to solving this Microsoft SQL interview question for the Data Science position. We will combine as many steps as possible to make the code more optimized.
Solution:
1. Subset events based on client_id = ‘mobile’
select * from fact_events where client_id = 'mobile';

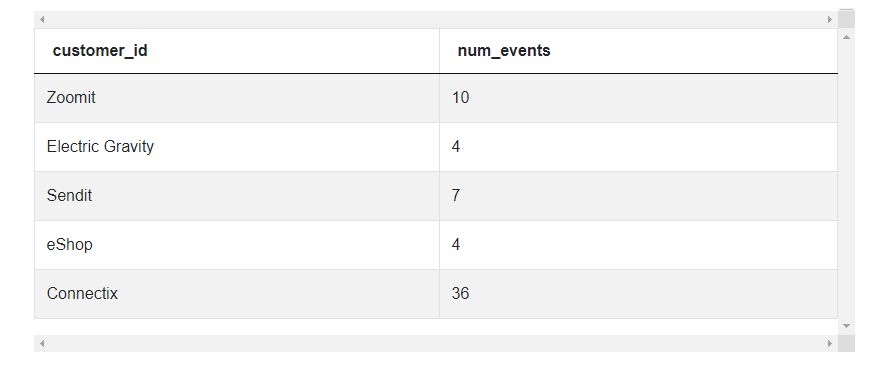
2. Count the number of events grouped by customer_id
select customer_id, count(*) as num_events from fact_events
where client_id = 'mobile'
group by customer_id;
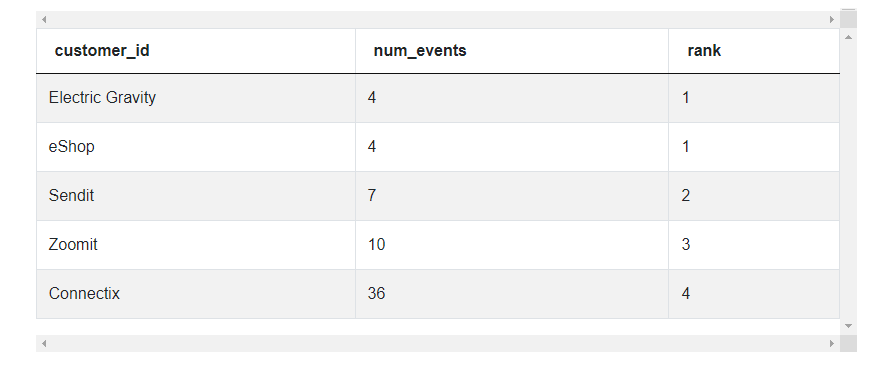
3. Rank the companies (customer_id) in the ascending order of the number of events. Use DENSE_RANK()instead of RANK()
select customer_id, count(*) as num_events,
dense_rank() over (order by count(*)) as rank from fact_events
where client_id = 'mobile'
group by customer_id;
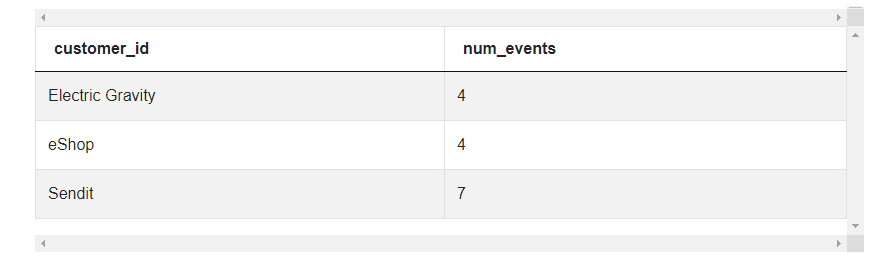
4. Finally, select the lowest two (in this case companies ranked 1 and 2 by the number of events) from the data
select customer_id, num_events from
(
select customer_id, count(*) as num_events,
dense_rank() over (order by count(*)) as rank
from fact_events
where client_id = 'mobile'
group by customer_id) q1
where rank <=2
order by num_events asc;
Optimization
This is a popular follow-up question. What should one look for? Low hanging fruits include condensing CTEs and subqueries or removing JOINs and using a CASE statement instead.
For our solution:
- Let us look at all the queries to see if we can condense/collapse some.
- Can we do away with the subquery? We cannot. Window functions are not supported in the HAVING or WHERE statement. So, you need a subquery.
- What are other ways to write this? You can use a CTE or a temp table.
- You then might get asked, which one perform's better?
- What's the difference between a CTE and a Temp Table?
- Temp tables if you are going to use this for other queries.
- Temp tables can be indexed so this itself can make the query faster.
Additional Microsoft SQL Interview Questions for the Data Science Position
Microsoft SQL Interview Question #1: Users Exclusive Per Client
Last Updated: March 2021
Considering a dataset that tracks user interactions with different clients, identify which clients have users who are exclusively loyal to them (i.e., they don't interact with any other clients).
For each of these clients, calculate the number of such exclusive users. The output should include the client_id and the corresponding count of exclusive users.
You can try to solve this Users Exclusive problem by Microsoft
Dataset
This Microsoft SQL interview problem uses the same fact_events dataset used in the previous problem. This problem is roughly the same level of difficulty as the one we discussed. However, the manipulations needed are slightly different. This real-life Microsoft SQL Data Science interview question can be solved using multiple DISTINCT conditions and subqueries.
Approach
- Identify the users with only one client_id
- From this group of users, query the respective client_id
Microsoft SQL Interview Question #2: Top Company Where Users Use Desktop Only
Last Updated: March 2021
Write a query that returns the company (customer_id column) with the highest number of users who have only used desktop. Users who may have used mobile at any point are ignored, but companies may still have mobile users.
You can try to solve this Desktop Users problem by Microsoft
Dataset
This problem uses the same fact_events dataset used in the previous problems. This problem can be thought of as a combination of the previous two problems. This real life Microsoft SQL Data Science problem can be solved using RANK() statements and subqueries.
Approach
- Identify the Desktop users who use only one client.
- Aggregate these events attended by these users by company (customer_id)
- Find the company with the highest number of users using the RANK() function. Note here we will get the same result irrespective whether we use the RANK() or the DENSE_RANK() functions. Can you figure out why?
Microsoft SQL Interview Question #3: New And Existing Users
Last Updated: March 2021
Calculate the share of new and existing users for each month in the table. Output the month, share of new users, and share of existing users as a ratio. New users are defined as users who started using services in the current month (there is no usage history in previous months). Existing users are users who used services in current month, but they also used services in any previous month. Assume that the dates are all from the year 2020. HINT: Users are contained in user_id column
You can try to solve this New and Existing users problem by Microsoft
Dataset
This is one of the toughest Microsoft SQL interview questions. This too uses the same fact_events dataset. To solve this real-life Microsoft Data Science problem, you will need a combination of CTE, date time functions and JOINs. You can check out our ultimate guide on SQL interview questions to learn more about these and other data manipulation questions using SQL.
Approach
- Extract month from time_id field. You can use the DATE_PART() or EXTRACT() functions to accomplish this.
- Aggregate the total number of active users per month.
- Find the number of New Users for each month.
- To do this find the first time_id and then extract the month from that time_id
- Merge the queries or CTEs and calculate the new and existing user shares for each month
Check out our post Microsoft Data Scientist Interview Questions which is focused exclusively on Python perspective to solve this question.
Conclusion
In this article of Microsoft SQL interview questions for Data Science position, we have discussed in detail an approach to solving a real-life Microsoft Data Science interview question. The question was not too tough, however we needed to understand the data and appreciate the fine difference between the RANK() and the DENSE_RANK() functions.
This can be accomplished only with practice of solving a variety of problems. Join our platform to practice more such data science interview questions from data science companies like Google, Facebook, Amazon, Microsoft, Netflix and more. We have a community of over 20,000 aspiring data scientists seeking to improve their coding skills, prepare for interviews, and jump start their career.
Share


