Learn PySpark Joins Easily with This Guide

Categories:
 Written by:
Written by:Nathan Rosidi
Master Inner, Left, and Complex Joins in PySpark with Real Interview Questions
PySpark joins aren’t all that different from what you’re used to for other languages like Python, R, or Java, but there are a few critical quirks you should watch out for.
In this article, we will explore these important concepts using real-world interview questions that range from easy to medium in difficulty.
By the end, we will explore the traps, best practices, and the details that might be missed. But first, let’s break things down and discover how these joins really work, what they are, and how they can be used in PySpark. Sounds good? So let’s start!
What is a PySpark Join?
Pyspark joins let you combine rows from two dataframes based on a common key. Several joins exist, like:
- Inner
- Left
- Right
- Outer
- Cross
- Semi
PySpark Joins Example: Left Join Explained
Each of these joins works for a different purpose. Now let's see PySpark Join in action.
In this, we will use the dataset from a hard-level question, which we’ll solve later in the article.
Find the number of employees who received the bonus and who didn't
Find the number of employees who received the bonus and who didn't. Bonus values in employee table are corrupted so you should use values from the bonus table. Be aware of the fact that employee can receive more than one bonus. Output value inside has_bonus column (1 if they had bonus, 0 if not) along with the corresponding number of employees for each.
Link to this question: https://platform.stratascratch.com/coding/10081-find-the-number-of-employees-who-received-the-bonus-and-who-didnt
Preview the datasets
In this question, Microsoft and Dell want us to find the number of employees who received the bonus and those who didn’t. There are two datasets. Here is the first one.
And here is the second dataset.
But what if we want to know who received the highest and lowest bonuses?
To figure out, we need to combine the bonus and employee tables. We use left join on;
- Bonus.worker_ref_id = employee.id
Then sort by bonus_amount
from pyspark.sql import functions as F
bonus = bonus.withColumn("bonus_amount", F.col("bonus_amount").cast("int"))
joined = bonus.join(employee, bonus["worker_ref_id"] == employee["id"], how="left")
max_bonus = joined.orderBy(F.col("bonus_amount").desc()).select("first_name", "bonus_amount").limit(1)
# Lowest bonus
min_bonus = joined.orderBy("bonus_amount").select("first_name", "bonus_amount").limit(1)
# Show results
max_bonus.show()
min_bonus.show()
Here's the output.

You can see that Allen got the highest bonus and Joe got the lowest one.
Easy-Level PySpark Joins Question From Meta
Find all posts which were reacted to with a heart
Find all posts which were reacted to with a heart. For such posts output all columns from facebook_posts table.
Link to this question: https://platform.stratascratch.com/coding/10087-find-all-posts-which-were-reacted-to-with-a-heart
In this question, Meta has asked us to find all posts that were reacted to with a heart.
Preview the datasets
As you can see, there are two different datasets.
- facebook_reactions
- facebook_posts
Now let’s see the first dataset, facebook_reactions.
Here is the second dataset, facebook_posts.
Solving with PySpark Inner Join
To solve this question, we will perform a filter + inner join. First, we filter facebook_reactions where the reaction is “heart”. Then we join this result with facebook_posts using post_id as the key. Finally, we select all columns from facebook_posts. Here is the solution:
import pyspark.sql.functions as F
heart = facebook_reactions.filter(F.col('reaction') == 'heart').select('post_id')
result = heart.join(facebook_posts, on='post_id').dropDuplicates(['post_id'])
result.toPandas()
Here is the result.

Great, we’ve solved the easy question. Now, let’s continue with the medium question.
Medium-Level PySpark Joins Question From Meta
Users By Average Session Time
Last Updated: July 2021
Calculate each user's average session time, where a session is defined as the time difference between a page_load and a page_exit. Assume each user has only one session per day. If there are multiple page_load or page_exit events on the same day, use only the latest page_load and the earliest page_exit. Only consider sessions where the page_load occurs before the page_exit on the same day. Output the user_id and their average session time.
Link to the question: https://platform.stratascratch.com/coding/10352-users-by-avg-session-time
In this question, Meta asked us to calculate each user's average session time, and of course, there are a lot of different conditions we should meet.
Preview the dataset
Let’s see the dataset, facebook_web_log.
Solution - Using Aliases in PySpark Joins for Complex Queries
We use the same dataset twice, once for “page_load” and once for “page_exit”. Each part is filtered and aliased to avoid column conflicts during the join operation. Next, we merge them by using “user_id”. That’s how we keep only records where load time comes before exit.Aliasing here is important. It lets us reference each version of data during grouping and filtering. Here is the code:
from pyspark.sql import functions as F
from pyspark.sql.window import Window
# Filter for 'page_load' and 'page_exit' separately and join on 'user_id' with condition
df = facebook_web_log.filter(F.col('action') == 'page_load').select('user_id', 'timestamp').alias('load') \
.join(facebook_web_log.filter(F.col('action') == 'page_exit').select('user_id', 'timestamp').alias('exit'),
on='user_id', how='left') \
.filter(F.col('load.timestamp') < F.col('exit.timestamp'))
# Instead of converting to date, truncate the timestamp to the start of the day for grouping
df = df.withColumn('date_load', F.date_trunc('day', F.col('load.timestamp')))
# Group by user_id and date_load, calculate max load and min exit timestamps per day
df = df.groupBy('user_id', 'date_load') \
.agg(F.max('load.timestamp').alias('timestamp_load'), F.min('exit.timestamp').alias('timestamp_exit'))
# Calculate duration in seconds
df = df.withColumn('duration', F.col('timestamp_exit').cast('long') - F.col('timestamp_load').cast('long'))
# Filter out non-positive durations
df = df.filter(F.col('duration') > 0)
# Calculate the mean duration in seconds per user
df = df.groupBy('user_id') \
.agg(F.mean('duration').alias('avg_session_duration'))
# Convert the DataFrame to Pandas for final output
result = df.toPandas()
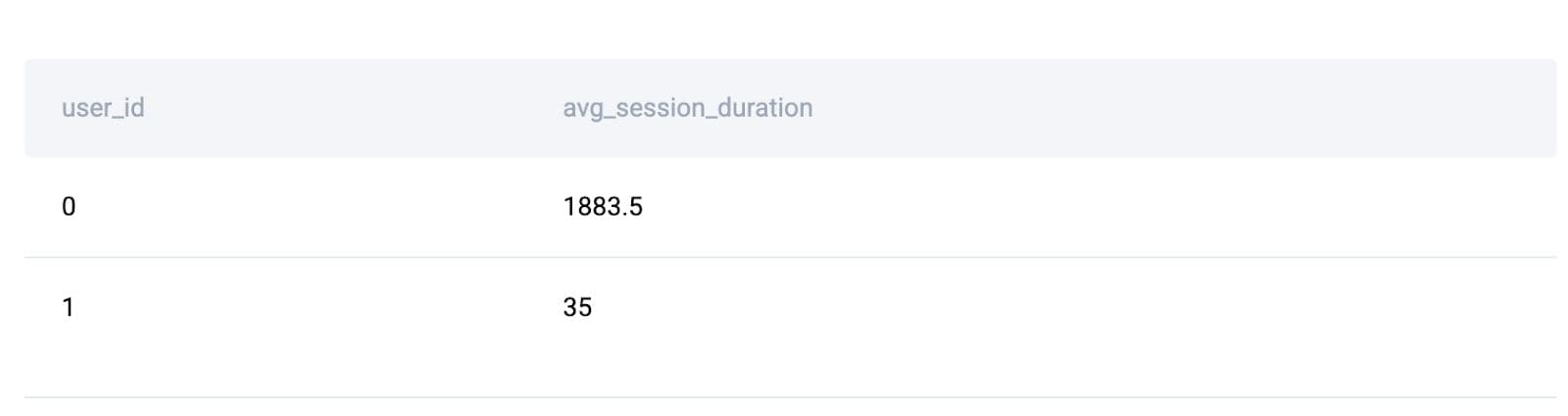
result
Here is the expected output.
Hard-Level PySpark Joins Question From Dell
Find the number of employees who received the bonus and who didn't
Find the number of employees who received the bonus and who didn't. Bonus values in employee table are corrupted so you should use values from the bonus table. Be aware of the fact that employee can receive more than one bonus. Output value inside has_bonus column (1 if they had bonus, 0 if not) along with the corresponding number of employees for each.
Link to this question: https://platform.stratascratch.com/coding/10081-find-the-number-of-employees-who-received-the-bonus-and-who-didnt
Dell asked us to find the number of employees who received the bonus and who did not. We have explored the datasets for this question at the beginning, so let’s continue to the solution at once.
Solving with PySpark Left Join and Null Handling
Let’s solve this by joining the employee table with the bonus table using employee.id = bonus.worker_ref_id.
Since the employees may appear multiple times in the bonus table, we use a left join to include everyone.
Next, we create a new column, has_bonus, using a simple null check: if bonus_data is null, then 0, otherwise 1. Finally, we group by has_bonus and count the distinct employee IDs in each group. Here is the solution:
import pyspark.sql.functions as F
merged_df = employee.join(bonus, employee['id'] == bonus['worker_ref_id'], how='left')
merged_df = merged_df.withColumn('has_bonus', F.when(F.col('bonus_date').isNull(), 0).otherwise(1))
result = merged_df.groupby('has_bonus').agg(F.countDistinct('id').alias('id_count'))
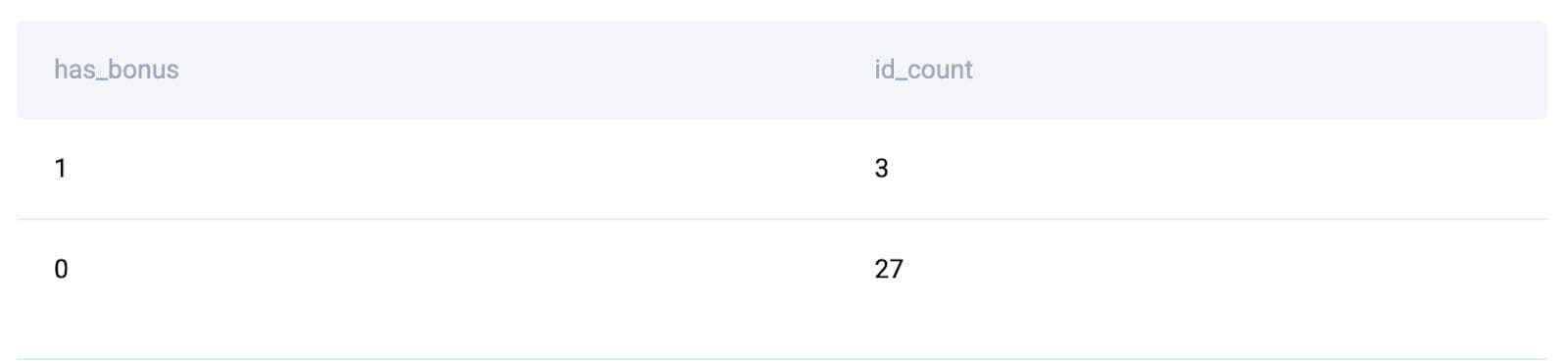
result.toPandas()
Here's the output.
Common PySpark Joins Mistakes and How to Avoid Them
Working with joins can be good and look easy until small mistakes sneak in. Here are a few common pitfalls that can throw off your results.
1. Forgetting to Handle Nulls
- When using left joins, always check for nulls in the table to identify unmatched records.
2. Not Casting Data Types
- If join keys have mismatched types, PySpark won't want you; it will just fail silently, so keep that in mind.
3. Duplicates
- If you join one-to-many relationships, you might end up with row explosions. Use .dropDuplicates() when needed to avoid it.
4. Inner Join by default
- Always specify how to join explicitly; do not rely on the default settings.
5. Alias Confusion
- When self-joining or filtering on the same table twice, always alias each filtered set. Otherwise, column references may conflict.
Quick Tips for Writing Better PySpark Joins
- Always preview the datasets before joining them.
- After a join, count your rows to verify your output.
- Use coalesce() to handle nulls when calculating or aggregating.
- When in doubt, start with a small sample to test your operation
Final Thoughts on Mastering PySpark Joins
You’ve seen how different PySpark joins work. Each example came straight from real interview questions, so you get both theory and practice. We also covered common mistakes like null handling, duplicate rows, and mismatched data types. Use the tips to stay sharp, avoid bugs, and write joins that actually work.
Share