Importing Pandas Dataframe to Database in Python

 Written by:
Written by:Nathan Rosidi
Learn how to upload your data from a pandas dataframe to a database in the cloud.
In this article, we’ll talk about how to upload your data from a pandas dataframe to a database in the cloud. This is a continuation of the article - Data analytics project ideas that will get you the job, where we talked about building the one and only data science project you need and where I introduced the infrastructure you can build for data science projects. The first part is to collect data from an API as your data source. I took you through how to do that in our previous blog - Working with Python APIs For data science project. Now that you have the data from the API saved in a pandas dataframe, we need to get it into a database table.
Github link: https://github.com/Strata-Scratch/api-youtube
Why do we need to import pandas dataframe to a database?
The biggest reason why you’d want to save your data to a database is to save all your data on another server (a database) rather than it stored locally on your computer, which would take up memory. You can store cleaned up versions of your data without having to clean it up every time you build an analysis.
And another reason is that most data science companies store their data in databases so it’s really important to learn how to pull and push data to and from databases.
Let’s walk through how we can load data from a pandas dataframe to database table in the cloud, and perform a second operation where we update the same table with new data. We'll do this in a scalable way, which means our code can handle potentially millions of rows without breaking pandas or running out of memory.
Check out our post "How to Import Pandas as pd in Python" for more details.
Setup
Create a Database on the Cloud (AWS)
We’re going to create a Postgres database on AWS and use the psycopg2 library to connect to the database on python. There’s a bunch of tutorials on how to do this so I won’t cover exactly how to spin up a database.
I’m creating an RDS instance on AWS and as you can see here my database is called “database-yt”

All our connection information is also found on AWS.
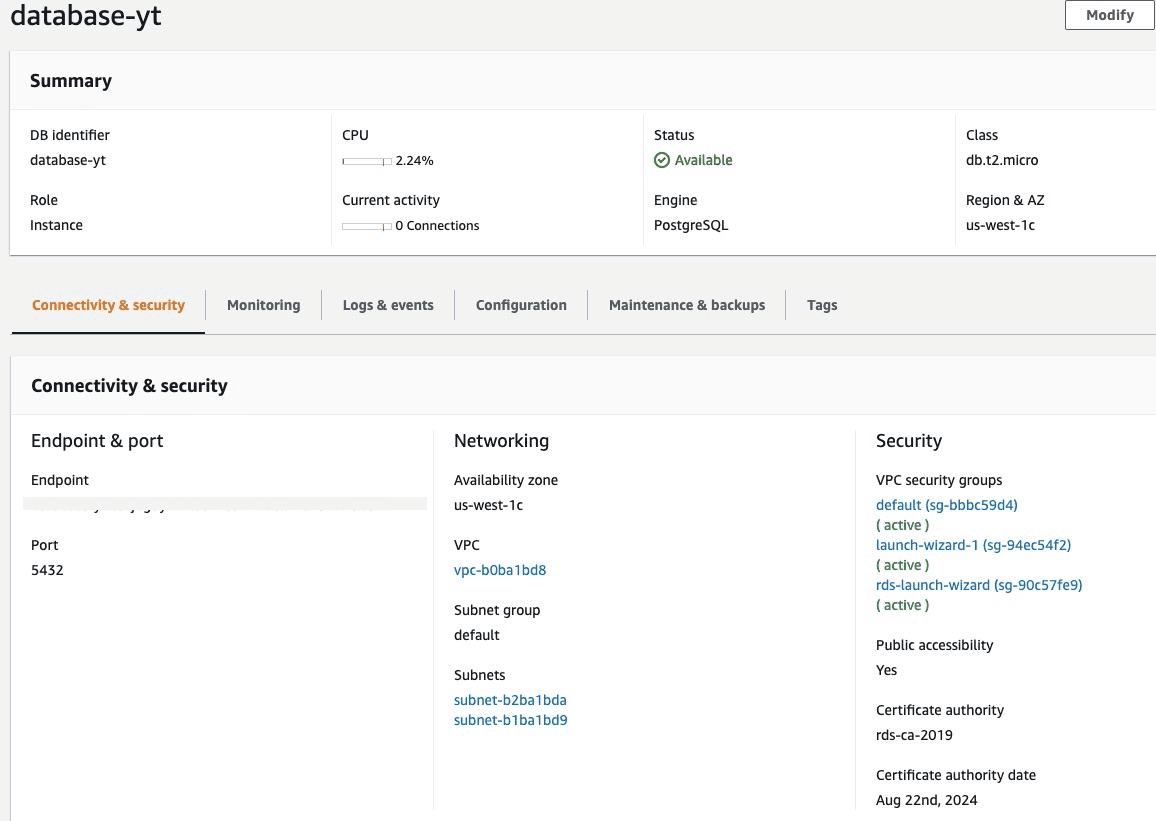
Save all that information for when you connect to the database in python.
Create a Google Colab or Jupyter Notebook
Just like with our other projects, we can use either Google Colabs or Jupyter Notebooks. I’m going to use Google Colabs.
The first thing to do is to install the python-postgres wrapper, psycopg2, to make it easier to connect to your database via python. I’m also importing the necessary libraries to do my work, like pandas.
!pip install psycopg2
import psycopg2 as ps
import pandas as pdConnect to Database
Enter your credentials for the database you have created.
host_name = 'database-XXXX.us-west-1.rds.amazonaws.com'
dbname = 'XXXX'
port = '5432'
username = 'XXXX'
password = 'XXXXX'Now, let's create a function that’ll allow you to pass the credentials over to the database and make the connection.
def connect_to_db(host_name, dbname, port, username, password):
try:
conn = ps.connect(host=host_name, database=dbname, user=username,
password=password, port=port)
except ps.OperationalError as e:
raise e
else:
print('Connected!')
return connUpload/Import Data
At this point, you can import your data and save it as a pandas dataframe. If you’re following what I’m doing, I extracted my data by connecting to the Youtube API and pulling data from there. Refer to our previous article - Working with Python APIs For Data Science Project.
Here we'll keep things clean and use 2 separate notebooks to transfer our data from one notebook to another, we’ll save it as a csv and upload it. But in reality, if we had collected data from an API and saved it as a pandas dataframe, we would just use the same notebook to upload it to our database.
youtube_videos = pd.read_csv('youtube_videos.csv', index_col=0)
youtube_videos.head()Create Database Table
SQL create table command
Let’s create the table. We’re going to use SQL to obviously create the table but we’ll add a variable %s to our CREATE TABLE command so that we can change the table name without touching the actual SQL command. This makes it easier and reduces human error when you’re experimenting and testing.
We have a CREATE TABLE IF NOT EXISTS and then the parameter %s where %s is the placeholder for my table name. Since we know the table schema already because we have the pandas dataframe of our data, we’re just going to name the columns and add the data types. It’s a standard CREATE TABLE SQL query. We then save everything in a variable named create_table_command.
create_table_command = ("""CREATE TABLE IF NOT EXISTS %s (
video_id VARCHAR(255) PRIMARY KEY,
video_title TEXT NOT NULL,
upload_date DATE NOT NULL DEFAULT CURRENT_DATE,
view_count INTEGER NOT NULL,
like_count INTEGER NOT NULL,
dislike_count INTEGER NOT NULL,
comment_count INTEGER NOT NULL
)""")
And just like with creating the connection to the database, we’ll wrap everything in a function called create_table.
def create_table(curr, tablename):
create_table_command = ("""CREATE TABLE IF NOT EXISTS %s (
video_id VARCHAR(255) PRIMARY KEY,
video_title TEXT NOT NULL,
upload_date DATE NOT NULL DEFAULT CURRENT_DATE,
view_count INTEGER NOT NULL,
like_count INTEGER NOT NULL,
dislike_count INTEGER NOT NULL,
comment_count INTEGER NOT NULL
)""")
curr.execute(create_table_command, [ps.extensions.AsIs(tablename)])Passing the connection to the database to the function
We’ll pass the Postgres connection cursor() called curr and the table name to the create_table function. The cursor is a class instance that allows you to run SQL commands and fetch results. It basically allows python code to execute sql commands in a database session.
conn = connect_to_db(host_name, dbname, port, username, password)
curr = conn.cursor()Executing a SQL command
We’ll then use the execute() method to our cursor() class to execute the SQL command.
curr.execute(create_table_command, [ps.extensions.AsIs(tablename)])
The first part of the execute() method requires the SQL CREATE TABLE command which is saved in create_table_command and since there’s a parameter %s that represents the table name, we need to also pass the table name into the command. We can do that by passing the table name in our variable tablename using [ps.extensions.AsIs(tablename)].
AsIs() is a function that is used to take off the quotes around the table name. Because if we pass a table name without this function it will read like “video” with the quotes in the SQL query, so we use AsIs() to tell postgre that you should take this as the name without the quotes.
Now we can connect to the database, name our table, and create the table on the database in the cloud with these three lines of code.
curr = conn.cursor()
TABLE_NAME = "videos"
create_table(curr,TABLE_NAME)Load Your Data into the Database Table
The data is in our pandas dataframe. There are two ways we can handle passing all the data from the dataframe to the database. The method you choose depends on the nature and size of your data.
- Rows are never updated once they make it to the database.
~ In this case, you just need to append new data as new rows in your database table. - Rows are updated when there's new data in the columns
~ In this case, not only do you need to append new data as new rows but you need to also update the values in existing rows. For example, since I’m dealing with Youtube video data from my channel, I have a list of videos on my channel, their view count and comment count. These counts change over time so when I pull data from the Youtube API a second time, I will need to both update the counts of existing videos and add new videos to the database table. This is a much more complicated process.
The case for scalability
And depending on how much data you have either from the API or from the database, you might not want to update the table all at once. This can lead to huge INSERTs and UPDATEs that could introduce performance and memory issues depending on the volume of data. One way around this is to update one row at a time.
In our case, we don’t have a lot of data but we do need to check to see if a video exists in the database table and update it with new counts. And we also need to insert new videos that have been extracted from the Youtube API. All this data is saved on our local computer (or Google’s Colab server) until it makes it to our database, so as my video list grows, so does the amount of memory needed to make an update. This is why updating row by row is best.
Update Existing Videos in the Database Table
Check to see if the video exists
Let’s check to see if a video exists first. This will help us load all our videos to the database for the first time and for all following times after.
But we want to perform an UPDATE if the video exists and we want to append a new video to the database table if the video doesn’t exist in the table. So some pseudocode could look like this.
for i, row in df.iterrows():
if check_if_video_exists(): # If video already exists then we will update
update_row()
else: # The video doesn't exists so we will append to the db table
append(row)
Basically, what this code is saying is to go through the dataframe one row at a time using iterrows() and check to see if the video exists. If it does, do an update on the row. If it does not, append the video information to the database table. DataFrame.iterrows is a generator which yields both the index and row (as a Series).
This will also work for an initial load since the videos will not exist since there are no videos in the table.
Let’s write the check_if_video_exists() function first
In order to check to see if a video exists in the database, we run a simple SQL command. We just need to feed the command the video_id that comes from our pandas dataframe.
query = ("""SELECT video_id FROM VIDEOS WHERE video_id = %s""")
curr.execute(query, (video_id,))And to wrap it in a function, we’ll write:
def check_if_video_exists(curr, video_id):
query = ("""SELECT video_id FROM VIDEOS WHERE video_id = %s""")
curr.execute(query, (video_id,))
return curr.fetchone() is not None
fetchone() returns a single row from a table, so if we found a video with the required id, it should return the row, otherwise it will return None. (https://pynative.com/python-cursor-fetchall-fetchmany-fetchone-to-read-rows-from-table/)
Update the table if the video exists
Let’s say our video exists in the database table. Now we should update those database records with the new counts we extracted from the Youtube API that’s saved in our pandas dataframe.
This is an easy UPDATE SQL command:
query = ("""UPDATE videos
SET video_title = %s,
view_count = %s,
like_count = %s,
dislike_count = %s,
comment_count = %s
WHERE video_id = %s;""")
vars_to_update = (video_title, view_count, like_count, dislike_count,
comment_count, video_id)
curr.execute(query, vars_to_update)
This is a regular UPDATE SQL command. The %s are just parameters for variables so that we can insert the proper values in the SQL command.
Again, let’s wrap it in a function:
def update_row(curr, video_id, video_title, view_count, like_count,
dislike_count, comment_count):
query = ("""UPDATE videos
SET video_title = %s,
view_count = %s,
like_count = %s,
dislike_count = %s,
comment_count = %s
WHERE video_id = %s;""")
vars_to_update = (video_title, view_count, like_count, dislike_count,
comment_count, video_id)
curr.execute(query, vars_to_update)
Our for loop with the functions now looks like below. Curr for both functions is the database connection. Row[‘video_id’] and other columns represent the columns in the pandas dataframe where our for loop is going row by row. df.iterrows() returns two parameters i which is the row index and row which is the row as a tuple, but in our case, we don’t need to use i, just row.
for i, row in df.iterrows():
if check_if_video_exists(curr, row['video_id']): # If video already
exists then we will update
update_row(curr,row['video_id'],row['view_count'],row['like_count'],
row['dislike_count'],row['comment_count'])
else: # The video doesn't exists so we will add it to a temp df and
append it using append_from_df_to_db
tmp_df = tmp_df.append(row)
Here we’ll append all new videos (i.e., videos that do not exist in the database table) to another pandas dataframe.
Storing new videos in a new pandas dataframe
But what about new videos that don’t exist in the database table? Let’s take care of that in another for loop. But what we can do is store all the new videos in a new pandas dataframe. Our for loop is now complete with this logic.
for i, row in df.iterrows():
if check_if_video_exists(curr, row['video_id']): # If video already
exists then we will update
update_row(curr,row['video_id'],row['view_count'],row['like_count'],row['
dislike_count'],row['comment_count'])
else: # The video doesn't exists so we will add it to a temp df and
append it using append_from_df_to_db
tmp_df = tmp_df.append(row)
Insert New Videos into Database Table
Create the INSERT SQL command
To insert new videos in our database table, we need to write a SQL INSERT command.
insert_into_videos = ("""INSERT INTO videos (video_id, video_title,
upload_date,view_count, like_count, dislike_count,comment_count)
VALUES(%s,%s,%s,%s,%s,%s,%s);""")
row_to_insert = (video_id, video_title, upload_date, view_count,
like_count, dislike_count, comment_count)
curr.execute(insert_into_videos, row_to_insert)In the same manner, we wrote the UPDATE and CREATE TABLE SQL statements, we just need to write a regular SQL statement and use %s as parameters for the columns.
We’ll create a function to store these commands so that we just need to pass the video information and the connection in order to perform the INSERT.
def insert_into_table(curr, video_id, video_title, upload_date,
view_count, like_count, dislike_count, comment_count):
insert_into_videos = ("""INSERT INTO videos (video_id, video_title,
upload_date, view_count, like_count, dislike_count,comment_count)
VALUES(%s,%s,%s,%s,%s,%s,%s);""")
row_to_insert = (video_id, video_title, upload_date, view_count,
like_count, dislike_count, comment_count)
curr.execute(insert_into_videos, row_to_insert)Add new videos row by row
Let’s go row by row and insert the video data into the table. To do that, we need to use a for loop to go row by row through the pandas dataframe and insert rows one by one into the database.
Just like with the last for loop, this for loop will go through each row in the dataframe and then run the insert_into_table() function which will perform an INSERT command into the table in the database.
def append_from_df_to_db(curr,df):
for i, row in df.iterrows():
insert_into_table(curr, row['video_id'], row['video_title'],
row['upload_date'], row['view_count'], row['like_count'],
row['dislike_count'], row['comment_count'])Package Everything Up
We’ve written all the functions that handle all the work. We need some code that will execute the functions in our main part of the script.
The first part of the main will call the update_db() function where we pass it the database connection and the pandas dataframe with our video information. The update_db() function will update existing videos found in the database table with new counts or will store video information not found in the database table in a new pandas dataframe we’re calling new_vid_df.
new_vid_df = update_db(curr,df)
conn.commit()Now that we have a list of new videos to insert into the database table, let’s call the append_from_df_to_db() function to insert those videos into the database table.
append_from_df_to_db(curr, new_vid_df)
conn.commit()If you take a look at the database table, the data is there. Now try updating the data in the database using this code with a new pandas dataframe that is an updated pull from your API.
Conclusion
Between this article and the last article on extracting data from an API, we’ve basically built a data pipeline. All that’s needed is to add a scheduler to automatically pull new data from the API and refresh your database table. If you’re able to build a data pipeline, you’ve managed to create the first steps in your one and only data analytics project you need.
This solution is scalable in the sense that it can handle millions and billions of rows. And the code is written with good software development fundamentals.
Share