Illustrated Guide About Self Join in SQL

Categories:
 Written by:
Written by:Nathan Rosidi
Mastering SQL Self Joins: how they work, why they multiply rows, and when to use them for comparisons, retention, and deduplication.
A self join is a regular join where both sides of the join reference the same table. You give that table two different aliases, and SQL treats them as if they were two separate tables. This lets you compare rows within the same dataset: the same way you would compare two tables, but the data source is one.
This comes up more often than people expect: comparing each passenger's fare to others in the same class, checking whether a user's first signup event matches a later session, or scanning a dataset for records that appear more than once.
In this article, we walk through what a self join actually does, why it multiplies rows in ways that can cause real problems, and three practical patterns from real business data. We also cover when to skip the self join entirely and use a window function or a CTE instead.
How Does a Self Join Work in SQL?
As mentioned, self join occurs when one table is joined with itself. In the standard depiction of SQL joins, it could be represented this way.

Let’s see what that means in practice. Here we have an organizational structure of the famous e-learning company AcrobataScratch.

This is a hierarchical data structure, as we learned. How can this structure be translated into a table? With the help of a primary (PK) and a foreign key (PK).
Remember, PK and FK are usually used for joining one table with another. Well, this time, we’re joining the table with itself, so both keys are in one table.
One hierarchical data characteristic is that a primary key (PK) and a foreign key (FK) are referencing the same table.
Again, it’s not necessary to compare two columns of one table for it to be a self join in SQL. As you will see in the examples from our platform, SQL self join can equally successfully be used on non-hierarchical data for comparing the same column of the same table.
Now, let’s get back to our AcrobataScratch example. The above organizational structure translates into this table.
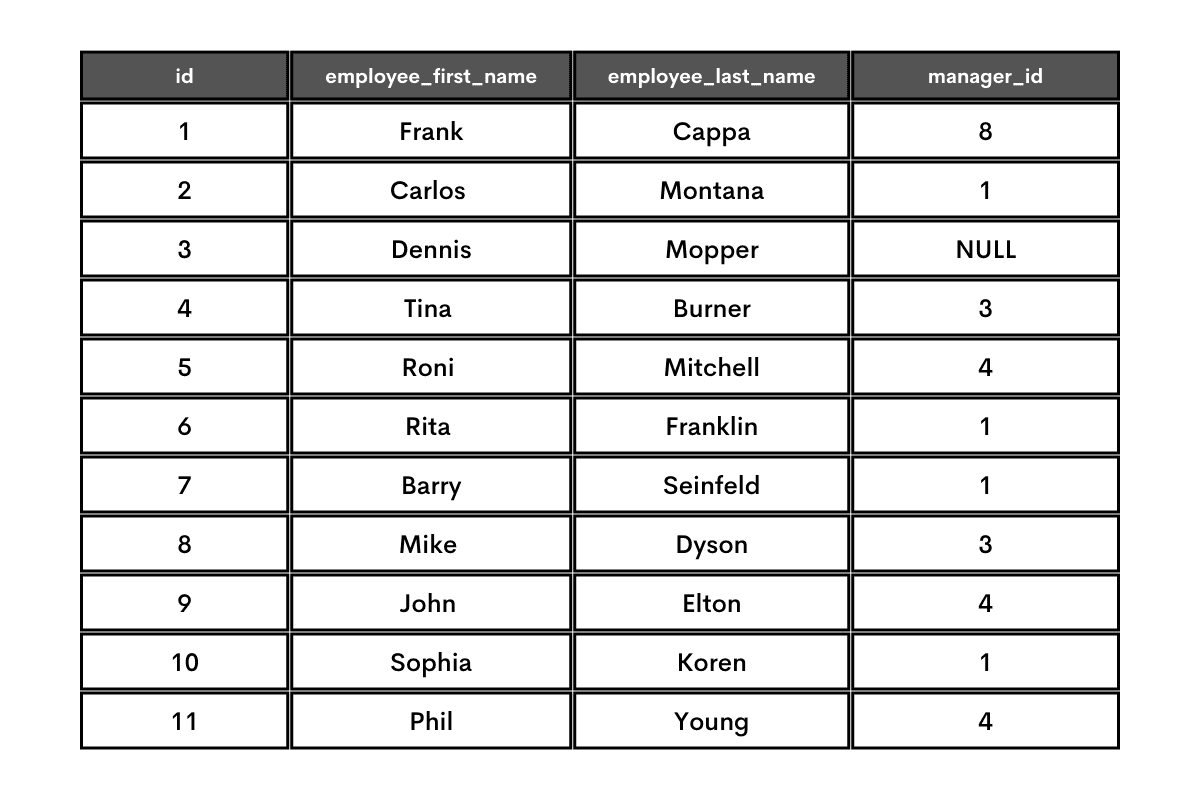
This table is typical for wanting to find the direct boss of each employee. The manager_id shows the ID of the employee that is a boss to a current row’s employee. If there are NULL values, it means this employee has no boss, i.e., he’s the boss of the bosses, the ultimate boss, the Shao Kahn of the company.
To find each employee’s boss's name, you have to self join the table on the condition that PK = FK.
This is illustrated below.

This shows that, for example, Frank Cappa is the boss to four employees, marked in blue. His boss is an employee with the ID = 8, i.e., Mike Dyson.
Dennis Mopper is a boss to two employees marked in yellow. He doesn’t have a boss, as there is a NULL in the manager_id column.
You can interpret the rest of the table following the same logic.
When such a table is self-joined where PK = FK, it results in this.
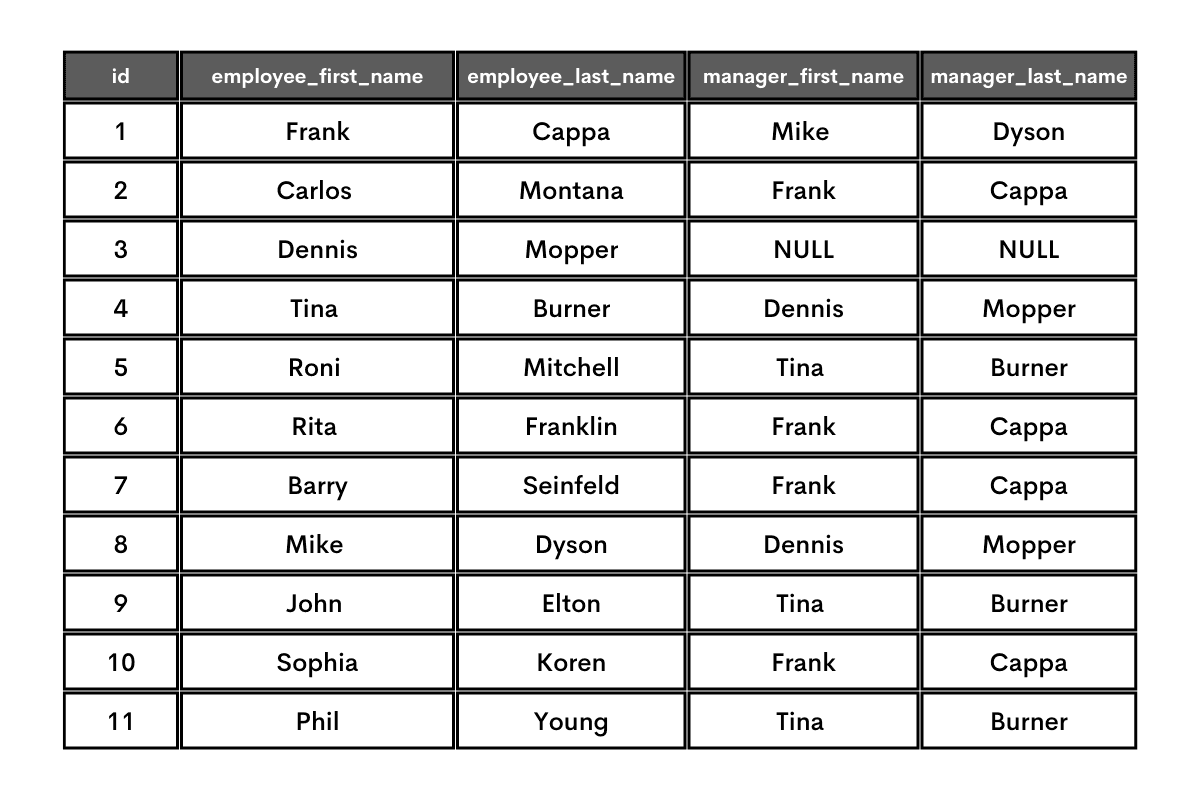
There you have it; the list of all employees and their bosses.
We want to achieve this in SQL, so we need to know the SQL syntax for self join.
SQL Self Join Syntax
A self join uses two aliases for the same table. SQL treats each alias as a separate table, which lets you compare rows against each other.
SELECT t1.column, t2.column
FROM table_name t1
JOIN table_name t2
ON t1.join_column = t2.join_column
WHERE t1.id <> t2.id; exclude self-pairing
t1 and t2 are arbitrary names: what matters is that both point to the same underlying table. The WHERE clause controls which row pairs survive. We cover exactly how that filtering affects row counts in the next section.
Where Self Joins Show Up in Practice
Self joins are a natural fit for four categories of problems that come up repeatedly in real data work.
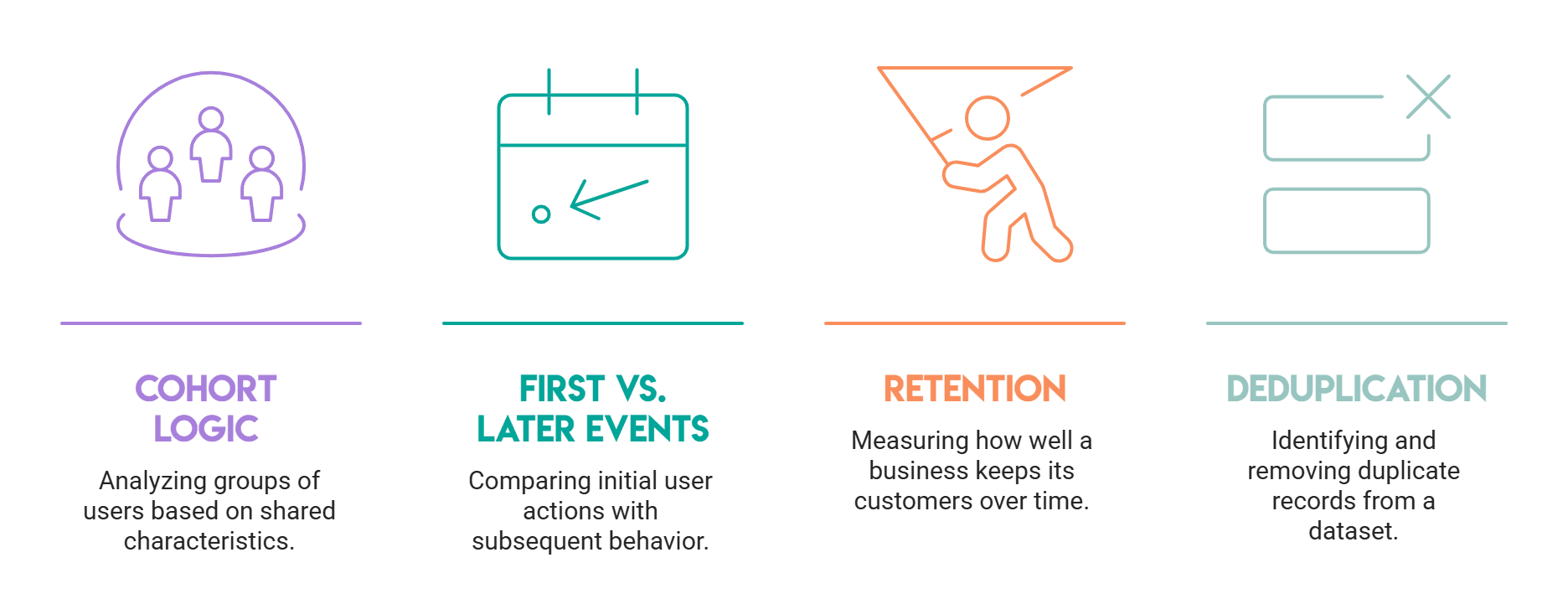
Cohort logic
When you need to compare members of the same group to each other: passengers in the same ticket class, users who signed up in the same month. A self join lets you generate all within-group pairs in a single query. You control the pairing logic entirely through the WHERE clause.
First vs. later events
If you want to find a user's first login and then measure what they did next, you can join the events table to itself: one alias anchored to the earliest event per user, the other ranging over everything that came after. This is the pattern behind funnel analysis and activation metrics.
Retention
Retention queries often need to know whether a user who was active in period A was also active in period B. Joining a users-or-events table to itself on user_id with different date filters on each alias is one way to express that relationship directly.
Deduplication
Before aggregating any dataset, it is worth checking for exact duplicate rows. A self join on the columns that define uniqueness, with a WHERE id1 <> id2 condition, surfaces every pair of rows that share the same key values. As we will see in Question 3 below, GROUP BY with HAVING usually handles this more cleanly, but understanding the self-join version clarifies why duplicates cause problems for counts and averages.
Real Business Tables Often Used
The examples in this article use three tables drawn from StrataScratch interview questions. Each one represents a category of table you encounter constantly in real data pipelines: the specific table is just one concrete instance of that pattern.

Users table
A users table tracks the people or entities in a system: who they are, when they joined, and any attributes that describe them. In our examples, linkedin_users is a users table scoped to employment history: it records each job a user held, the employer, the role, and the start and end dates of that position.
Events table
An events table records actions or interactions over time, with a timestamp and some description of what happened. In our examples, playbook_events is an events table for a product analytics context: it captures individual user actions (logins, page views, sign-up steps) along with the event type, location, and device.
Orders table
An orders table holds transactional records: each row is a purchase or sale event tied to a customer, a product, and a date. In our examples, online_orders is an orders table for an e-commerce context: it records per-product sales linked to a promotion, including the sale date, cost, and units sold.
How a Self Join Multiplies Rows
This is the part that trips most people up.
With no join condition, a self join produces every possible combination: for a table with 100 rows, you get 10,000 output rows. Even with conditions, the output grows fast.
Take linkedin_users. User 3 has three jobs (Microsoft, Amazon, Google). A self join on user_id with no further conditions pairs each row with every other row for that user (including itself), producing nine pairs before any filtering:
SELECT t1.user_id,
t1.employer AS employer_1,
t2.employer AS employer_2
FROM linkedin_users t1
JOIN linkedin_users t2
ON t1.user_id = t2.user_id
WHERE t1.user_id = 3;
Which one to use depends on whether the calculation you are computing should be symmetric or directional. We will see a concrete example of this in the first question below.
Self Join in SQL: Common Patterns
Pattern #1: Pairwise Row Comparison
Use this pattern when each row needs to be compared against a set of other rows in the same table: same group, same category, within a certain distance.
The self join generates all qualifying pairs; you then filter and aggregate across them. The key decisions are: what defines "comparable" rows (the equality conditions), what defines the distance threshold (the range condition), and whether you need <> or < to control pair direction.
This pattern comes up in fare comparisons, price benchmarking, proximity matching, and any question that asks "how does this row compare to similar rows?"

Let’s see an example of this pattern.
Find fare differences on the Titanic using a self join
Find the average absolute fare difference between a specific passenger and all passengers that belong to the same pclass, both are non-survivors and age difference between two of them is 5 or less years. Do that for each passenger (that satisfy above mentioned coniditions). Output the result along with the passenger name.
Data View
The titanic table holds one row per passenger with fare, passenger class, age, and survival status. For this question, we compare each non-surviving passenger's fare with that of all other non-survivors in the same class who are within five years of age.
Grain (what one output row means): one qualifying passenger, with the average absolute fare difference to all comparable passengers in the same class and age band.
Common Mistakes
The most common error is forgetting to exclude self-pairing. Without titanic1.passengerid <> titanic2.passengerid, each passenger pairs with themselves. That pair has a fare difference of zero, which pulls the average down and makes the result wrong.
A second mistake is using < instead of <>. That removes half the comparisons: each pair (A, B) appears only once, rather than both (A, B) and (B, A). When the output is grouped by a specific passenger (GROUP BY name1), we want all comparisons from that passenger's side. Using <> is correct here because direction matters for the average.
Edge case: the condition ABS(titanic1.age - titanic2.age) <= 5 silently excludes passengers where age is NULL. If your dataset has missing ages and you need to handle those passengers, you would need to add an explicit OR age IS NULL branch or decide upfront that they are excluded.
Solution
1) Set up the self-join and filter to comparable passengers
We alias titanic as titanic1 and titanic2, then pair rows that share the same pclass, are both non-survivors, and are within five years of age. We exclude self-pairing with <>.
SELECT titanic1.name AS name1,
titanic1.fare,
titanic2.fare AS fare_comparison
FROM titanic titanic1,
titanic titanic2
WHERE titanic1.passengerid <> titanic2.passengerid
AND titanic1.pclass = titanic2.pclass
AND ABS(titanic1.age - titanic2.age) <= 5
AND titanic1.survived = 0
AND titanic2.survived = 0;
2) Aggregate to get the average absolute fare difference per passenger (final solution)
We wrap the fare columns in ABS() and pass the result to AVG(), then group by passenger name to get one row per qualifying passenger.
Run the code above to see the output.
Pattern #2: Consecutive Period Matching
Use this pattern when you need to check whether the same entity appears in two consecutive time periods: month over month, week over week, or any fixed interval.
The self join pairs the same entity at two points in time. One alias anchors to period A; the other matches against period A + 1. The join condition uses date arithmetic to express "next month" or "next week" rather than an exact date offset, which makes it flexible across calendar boundaries.
This pattern comes up in retention analysis, streak detection, subscription continuity, and any question that asks "which users were active in both this period and the next?"

Let's see an example of this pattern.
Trips in Consecutive Months
Last Updated: November 2021
Find the IDs of the drivers who completed at least one trip a month for at least two months in a row.
Data View
The uber_trips table holds one row per trip with a trip_date, driver_id, fare, and is_completed flag. A single driver can have multiple trips across multiple months. The question asks for drivers who completed at least one trip a month for at least two consecutive months.
Grain (what one output row means): one driver who had a completed trip in some month and another completed trip in the immediately following month.
Common Mistakes
The most common error is comparing exact dates instead of months. If you write b.trip_date - a.trip_date = 30, you miss months with 28 or 31 days. The correct approach is to compare at the year-month level by using TO_CHAR with the 'YYYY-MM' format after adding a one-month interval to the first alias's date.
A second mistake is forgetting to filter is_completed = TRUE on both sides of the join. If you filter only one alias, you get pairs where a driver started a trip in month A but never finished it, paired with a completed trip in month B, which does not satisfy "completed at least one trip a month."
Edge case: a driver could have multiple trips in both months. The self join will produce multiple matching pairs for that driver, but DISTINCT in the SELECT collapses them to a single row per driver, which is what the question asks for.
Solution
1) Set up the self-join to pair trips in consecutive months
We alias uber_trips as a and b, then join on driver_id with the condition that a's trip month + 1 equals b's trip month. This pairs every trip in month A with every trip by the same driver in month A+1.
SELECT a.driver_id,
TO_CHAR(a.trip_date, 'YYYY-MM') AS month_a,
TO_CHAR(b.trip_date, 'YYYY-MM') AS month_b,
a.is_completed AS completed_a,
b.is_completed AS completed_b
FROM uber_trips a
JOIN uber_trips b ON a.driver_id = b.driver_id
AND TO_CHAR(a.trip_date + interval '1 month', 'YYYY-MM') = TO_CHAR(b.trip_date, 'YYYY-MM')
ORDER BY a.driver_id;
2) Filter to completed trips and deduplicate (final solution)
We add a WHERE clause requiring both trips to be completed, and wrap the SELECT in DISTINCT to return one row per qualifying driver.
Pattern #3: Duplicate Detection
Use this pattern when you need to find rows that share the same value across one or more columns: employees with matching salaries, orders with identical amounts, or users with the same signup date.
A self join on the matching column with a <> condition on the primary key produces all pairs of rows that share that value. The output is one row per pair, which means the result grows fast: two employees at the same salary produce 2 pairs, three produce 6, four produce 12. When the question asks for a list of individual matching records (not pairs), the self-join approach works directly.
This pattern comes up in data quality checks, fraud detection, compensation audits, and any question that asks "find records that share the same value."

Let's see an example of this pattern.
Employees With the Same Salary
Find employees who earn the same salary.
Output the worker id along with the first name and the salary in descending order.
Data View
The worker table holds one row per employee with their ID, name, salary, joining date, and department. The question asks you to find employees who earn the same salary as at least one other employee and to output their worker ID, first name, and salary in descending order.
Grain (what one output row means): one employee who has at least one salary match elsewhere in the table.
Common Mistakes
The most common error is forgetting the w.worker_id != w1.worker_id condition. Without it, every employee matches themselves, and the query returns the entire table; every employee "shares" a salary with themselves.
A second mistake is using < instead of <>. Using < gives you each pair only once: the pair where worker 4 matches worker 5, but not the pair where worker 5 matches worker 4. That is useful for listing unique pairs, but this question asks for a list of individual employees; each matching employee needs their own output row, so <> is correct.
Edge case: if three employees share the same salary, the self join produces 6 pairs (3 × 2). But when you SELECT only from the left alias (w), each of the three employees appears twice (once per match partner). The output still shows the right set of employees because no DISTINCT is needed: the question asks for all matching employees, and each employee appears in the result as many times as they have match partners. If you needed a deduplicated list, you would add DISTINCT.
Solution
1) Self-join to expose all salary-matching pairs
We alias worker as w and w1, then join on salary with the condition that the two rows have different worker_id values. This shows each employee alongside every other employee who earns the same amount.
SELECT w.worker_id,
w.first_name,
w.salary,
w1.worker_id AS matched_worker_id,
w1.first_name AS matched_name
FROM worker w
INNER JOIN worker w1 ON w.salary = w1.salary
AND w.worker_id != w1.worker_id
ORDER BY w.salary DESC,
w.worker_id;
2) Select only the requested columns and sort (final solution)
The question asks for worker_id, first_name, and salary sorted by salary descending. We drop the columns from the second alias and keep only the left side.
When to Use Window Functions or CTEs Instead
A self join is the right tool when you need to compare a specific row to another specific row in the same table: same user, same class, within some distance. The Titanic fare question is a good example: every row needs to be measured against a filtered set of other rows. Nothing else handles that as directly.
But several patterns that look like self-join problems have cleaner solutions:
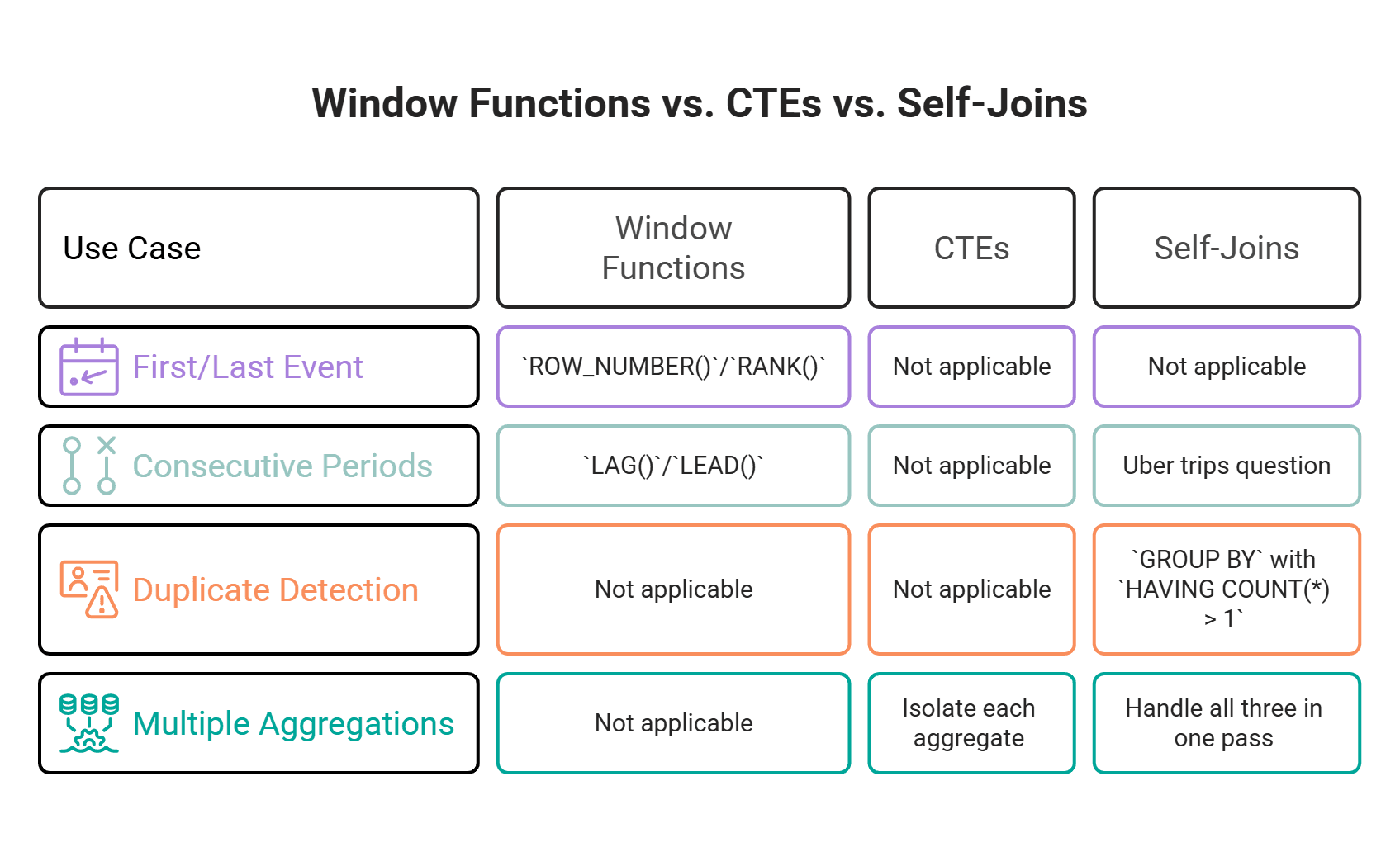
- For the first or last event per user, ROW_NUMBER() or RANK() partitioned by
user_idand ordered by timestamp produces one clean row per user without any join at all. - For consecutive-period checks,
LAG()orLEAD()partitioned bydriver_idand ordered by month can detect whether the previous or next period exists without generating any intermediate pairs. The Uber trips question works well as a self join, but on a large table with millions of trips, the window-function version avoids row multiplication entirely. - For duplicate detection,
GROUP BYwithHAVING COUNT(*) > 1gives one row per duplicate group. A self-join gives one row per pair within each group, which grows fast and is harder to interpret. - For multiple aggregations over a date range (like the promotion question), CTEs that isolate each aggregate are easier to write, test, and extend than a self-join that tries to handle all three in a single pass.
The practical signal: if your self-join condition uses only < or > on a date or sequence column with no equality condition, a window function will almost always produce the same result with fewer rows in memory and simpler code.
Conclusion
A self join is just SQL treating a single table as two tables. That is the whole mechanic. The complexity comes from understanding how many rows the join generates and what condition controls that.
The three patterns in this article cover the core use cases: pairwise row comparison for comparing rows within a group, consecutive period matching for retention and streak logic, and duplicate detection for data quality and fraud checks. Each pattern has a clear signal for when it belongs and a clear alternative for when it does not.
Two things to keep in mind before you write the next one. First, always exclude self-pairing with <> on the primary key unless you have a specific reason not to. Second, watch the row count. A self join on a large table grows fast, and a slow query is often the first sign that a window function would have been cleaner.
When the problem is genuinely about comparing one row to another row in the same table, nothing expresses that more directly than a self join. That is when it earns its place.
Share