How to Use STRING_AGG to Solve SQL Questions in Data Science Interviews


STRING_AGG is a rather rarely used SQL aggregation function but it sometimes comes useful when solving data science interview tasks. An example of this is the recent and very tasty interview question from Amazon that deals with some cookbook titles.
To start with, the string_agg() function, as the part of its name suggests, is an aggregation function. Just for a reminder, the aggregation is used to reduce the number of rows in the table such that there is only one row per a distinct value from the key or from the column that we’re aggregating the dataset by. We can then use a number of functions on top of the aggregation to see statistics concerning each value from the key.
For example, take a look at this dataset of Oscar nominees throughout the years. There are many variables in this table, but we’re only interested in the name of the nominee and the movie they were nominated for.

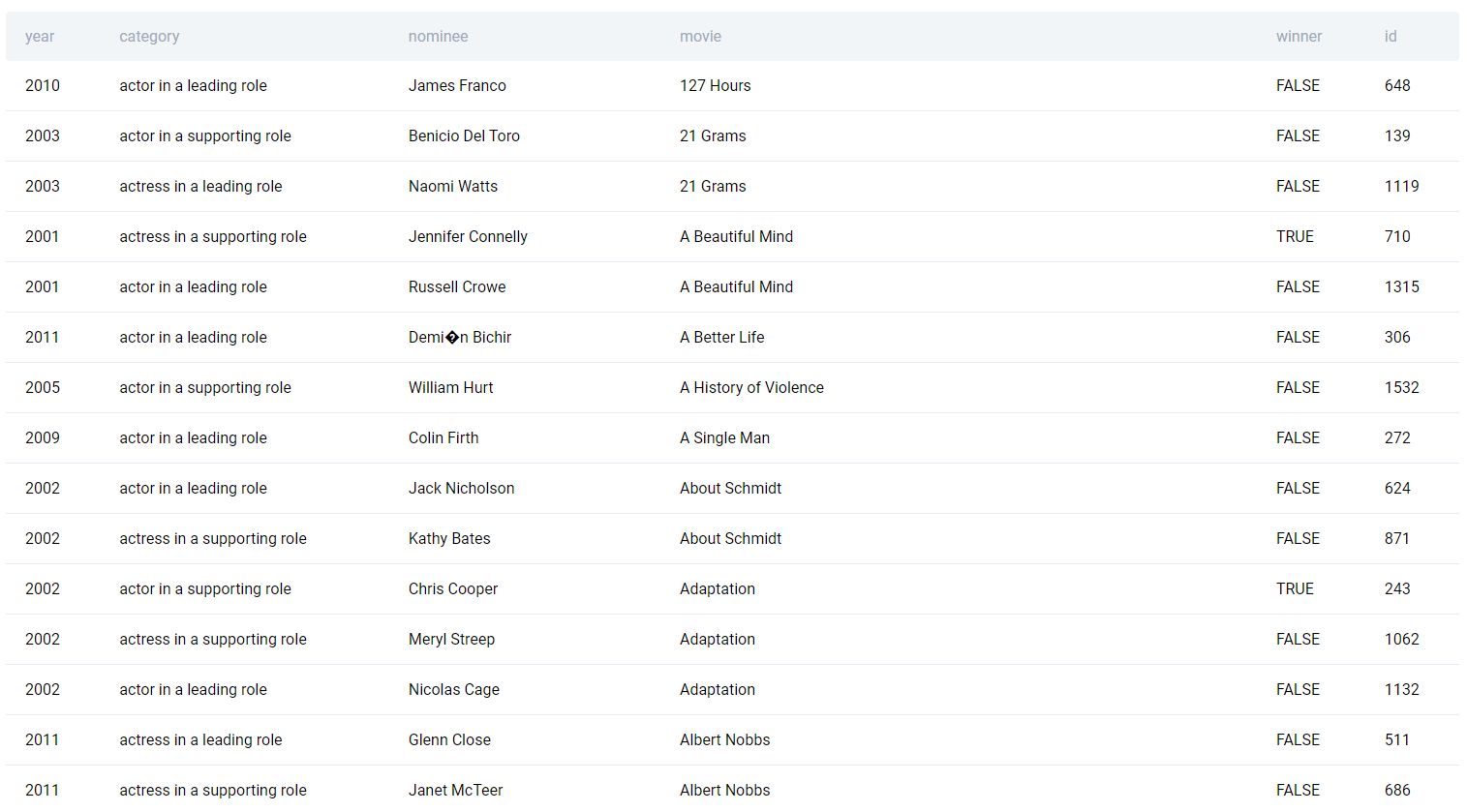
Now, let’s assume we want to count the number of nominees that each movie had. We can generate such an output using probably the most popular aggregation function - COUNT().
SELECT movie,
count(nominee)
FROM oscar_nominees
GROUP BY movie
In SQL, the aggregation is performed using the GROUP BY statement. Here, we say that the dataset should be grouped by the movie column, in other words, the movie column is our key for the aggregation operation. We can then use the aggregation function count(nominee) that counts for each distinct value in our key, in this case for each movie title, in how many rows does it appear. When you run this code, you can see that now each movie title appears only once in the output because we aggregated the data by the movie. This is the simplest type of aggregation in SQL - you’ve probably seen it before.
But now let’s say that we want, instead of just getting the number of nominees per movie, to get a list of nominees for each movie. We need to aggregate the data again because the goal is to see one row per each distinct movie but the aggregation function to use this time is the string_agg() function. This function allows us to concatenate all strings from the rows that have the same key value, in our case, the same movie title. Go ahead and change the ‘count(nominee)’ in the code above to string_agg(nominee, ''). When you run this code, you have a list of nominees for each movie from our dataset, it should look like the one below.

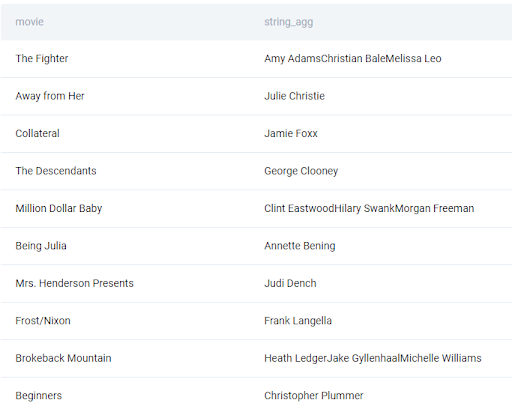
Some movies only have one name listed because there was only one nominee, but in some cases, we have multiple names. The only problem that you may already see is that in the case of multiple names, there is no separation between the names. We can kind of see where each name starts because of the capital letters but it’s not very easily readable. That’s why the string_agg function gives us one more cool functionality, namely, we can decide on our custom separator.
And this is exactly what this second parameter of this function is for, for now, we only put there 2 apostrophes - this simply means no separator. But we can also select anything to be a separator, for example, a comma, or a semicolon, we can also have a symbol and a space, or just a space, or even space symbol and space. Pretty much any string can be a separator. Feel free to change what is between the apostrophes in the string_agg function and observe how the output changes.
This was a brief introduction to this rather rarely seen aggregation function and now let’s see how we can use it to solve one of the real-life SQL interview questions.
Interview Question

This question was asked by Amazon and its title is Cookbook Recipes. We are given the table with titles of recipes from a cookbook and their page numbers. The task is to represent how the recipes will be distributed in the book.


Link: https://platform.stratascratch.com/coding/2089-cookbook-recipes
It then specifies that we should produce a table consisting of three columns: left_page_number, left_title and right_title. The k-th row (counting from 0), should contain the number and the title of the page with the number 2*k in the first and second columns respectively, and the title of the page with the number 2*k+1 in the second column.
It could be a bit hard to understand the idea just from reading this description but we were told, in fact, that in an interview with this question you would be shown the sample of what the data may look like and what the corresponding output should be look like, so let’s take a look at the sample dataset.

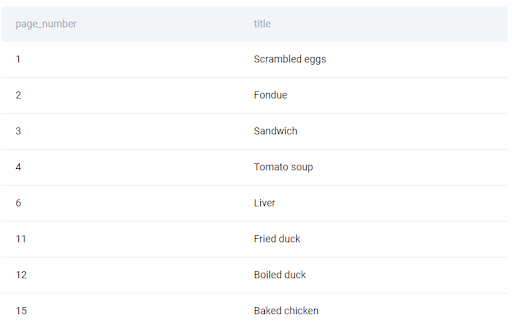
We only have the page numbers and the recipe titles. And what we’re supposed to do with it, is to transform it into a kind of a book. If we open a book, we always see a left page and a right page. And the task is exactly to simulate how these recipe titles would align in a book. The additional task is to also produce this first column with the numbers of the left page in each row.
Formulate Approach
- To solve this data science interview question, we can start by generating an empty series with numbers corresponding to all pages in our book. In other words, this will be a single column of consecutive numbers, starting with 0 and ending with the maximum page number from our original dataset.
- Next, we can merge the original dataset with our series of numbers. This way, if there is a recipe title on one of the pages, we will see the title next to a corresponding page number, otherwise, the cell next to the row number will be empty.
- Then, we can use CASE statements, and split the recipe titles into two columns in such a way that titles with even page numbers will be in one column and titles with odd page numbers will be in another column. At the same time, we can divide the numbers from our series by 2 so that each two recipe titles that in an open book would be next to each other, will have the same number in their rows.
- Next, we can aggregate the data by the page number divided by two, or in other words, the values in the first column, and use the string_agg() function to return the recipe titles that need to be on each pair of pages in the book.
- The final step will be to add a column with numbers of the left page, out of the two pages represented by each row, as specified in the question text. We can actually reuse the numbers from the series that we created earlier and multiply them by 2. You will see once I do it that it will work out nicely.
Code execution
Having defined these general steps for solving this data science interview problem, we can start writing the SQL code. The first step is to generate a series with numbers corresponding to all pages in the book. In SQL, a new series of numbers can be generated using a generate_series function. This is what the syntax looks like. We say that we want to select a column generate_series, let’s call it page number, from this function generate_series. The parameters of the function are the lowest and the highest number that we want to include in our series.
SELECT generate_series AS page_number
FROM generate_series(0, last_page_number)
So if we change last_page_number to let’s say 5, then we will get the series of consecutive numbers from 0 to 5. Go ahead and try it out with different numbers.
But what is the last_page_number in our case? We need to get it from our original dataset but be careful because it’s not equal to the number of rows in the original table - that’s because only the pages with recipe titles are listed there. So, the number of the last page in our book will be, in fact, the maximum number from the page_number column from the original table cookbook_titles. We can get this number using the max() function like that:
SELECT max(page_number)
FROM cookbook_titles
Now, coming back to the series expression from earlier, we can do a little trick and paste this whole query in the generate_series function, instead of the last_page_number placeholder and put this inner query in the parentheses. This gives us exactly as many numbers in the series as we need to create the entire book. Go ahead and paste this code in the right place in the code editor above.
To make things more readable, we can also declare this series query as a common table expression,calling it, for example ‘series’. This way, we will be able to access the table generated by this query by simply using the keyword series. The complete code for generating the series will therefore looks like this:
WITH series AS
(SELECT generate_series AS page_number
FROM generate_series(0,
(SELECT max(page_number)
FROM cookbook_titles)))
SELECT *
FROM series
The next step is to merge our original dataset with this series. To merge the two tables, we can use the JOIN keyword in the FROM statement of our current main query. Let’s give an alias to the table series, e.g. s and we say that we want to join it with the original table, cookbook_titles, such that the values in the two page_number columns match.
WITH series AS
(SELECT generate_series AS page_number
FROM generate_series(0,
(SELECT max(page_number)
FROM cookbook_titles)))
SELECT *
FROM series s
JOIN cookbook_titles c on s.page_number = c.page_number
But this is not exactly what we wanted, because we’re back to not having all the pages listed but only the ones that have recipe titles on them. That’s because we wrote JOIN - this implies an inner JOIN which returns such rows where page_number value exists in both tables. What we need, however, is in this case a LEFT JOIN such that it’ll preserve all the page numbers from the series table even if they don’t exist in our original table. Go ahead and change ‘JOIN’ in the last line to ‘LEFT JOIN’ to see the difference.
This is much better, let’s only leave the first and the third columns of this table and let’s also declare it a common table expression for the sake of readability. Since the output is still rather similar to the original table, we can call it ‘cookbook_titles_v2’.
WITH series AS
(SELECT generate_series AS page_number
FROM generate_series(0,
(SELECT max(page_number)
FROM cookbook_titles))),
cookbook_titles_v2 AS
(SELECT s.page_number,
c.title
FROM series s
LEFT JOIN cookbook_titles c ON s.page_number = c.page_number)
SELECT *
FROM cookbook_titles_v2
Next is when things get a bit more difficult. Right now, we have all the recipe titles in a single column eventually we want them in two different columns depending on their page number. To get closer to this goal, let’s use the CASE statements. The first one will say that if a page number is even, in other words, if page number modulo 2 is equal to 0 - the percentage symbol denotes modulo - we return the recipe title. This will create a column with only these titles which are on even pages. Let’s call this column left_title.
WITH series AS
(SELECT generate_series AS page_number
FROM generate_series(0,
(SELECT max(page_number)
FROM cookbook_titles))),
cookbook_titles_v2 AS
(SELECT s.page_number,
c.title
FROM series s
LEFT JOIN cookbook_titles c ON s.page_number = c.page_number)
SELECT *,
CASE
WHEN page_number % 2 = 0 THEN title
END AS left_title
FROM cookbook_titles_v2
And then, go ahead and add pretty much the same case statement under the first one, this time saying that if a page number is odd, or if page number modulo 2 is equal to 1, we return the recipe title. This will create a column with all the titles from odd pages, we’ll call it the right title. When adding the second CASE statement, don’t forget about the comma after ‘left_title’. The second statement should look like this:
CASE
WHEN page_number % 2 = 1 THEN title
END AS right_title
We can also remove the column ‘title’ because we already have all the titles nicely split into two columns as we wanted them. And we can divide the page_number column by 2. To do this, replace the asterisk after the SELECT keyword with ‘page_number / 2’.
When you run this code, what these numbers mean is that when we open our book, first we will see a blank page on the left and a page with the title Scrambled Eggs on the right. Next, we turn the page and so we see the title Fondue on the left side and Sandwich on the right - that’s why both have the same value in the first column.

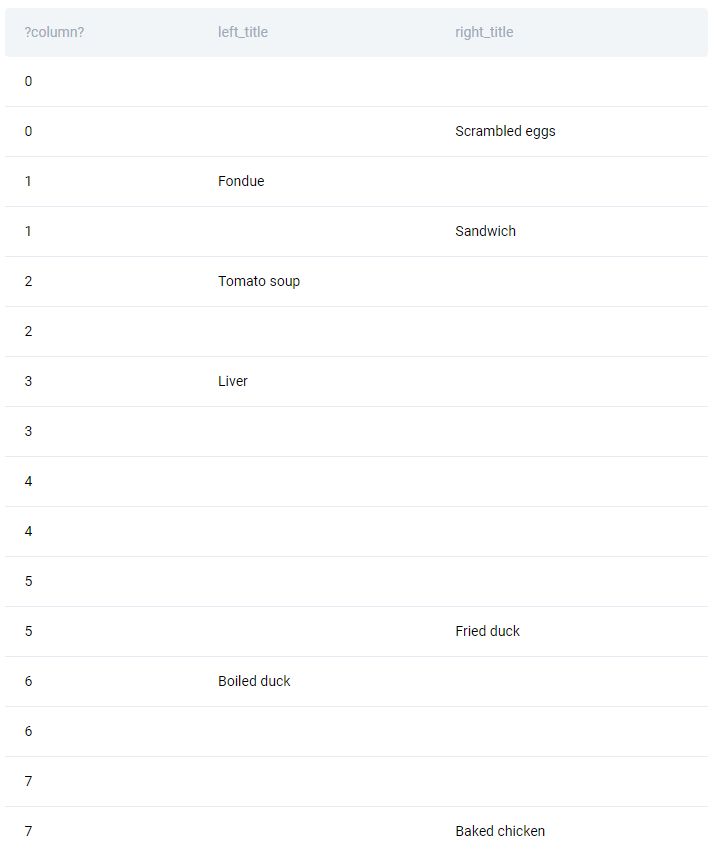
So to reduce the dataset such that all the rows with the same value become a single row, we need to aggregate the data by this first column, again, using the group by statement.
GROUP BY page_number / 2But this is not enough because we still need to apply some kind of aggregation functions to the two other columns - left_title and right_title. And yes, you guessed it, the function that will do perfectly, in this case, is the string_agg and we will use it to wrap the CASE statements.
WITH series AS
(SELECT generate_series AS page_number
FROM generate_series(0,
(SELECT max(page_number)
FROM cookbook_titles))),
cookbook_titles_v2 AS
(SELECT s.page_number,
c.title
FROM series s
LEFT JOIN cookbook_titles c ON s.page_number = c.page_number)
SELECT page_number / 2,
string_agg(CASE
WHEN page_number % 2 = 0 THEN title
END, '') AS left_title,
string_agg(CASE
WHEN page_number % 2 = 1 THEN title
END, '') AS right_title
FROM cookbook_titles_v2
GROUP BY page_number / 2
As you can see when you run the code, this also changed the order of the values in the first column, so you can sort the data by this column by adding ORDER BY 1 after the GROUP BY statement - this is not a necessary step but it will make it easier for you to see what happened here.
What’s interesting is that while we’re using the string_agg(), we’re not actually concatenating any strings together. That’s because each double page in our book has at most one title on the left and at most one title on the right - this is the simplification made in this interview question. But if it was possible to have multiple titles on the same page, we could use the same method and the string_agg function would concatenate these titles for us.
So the reason why we’re using this specific aggregation function is simply that we need to use some kind of a function and this one allows us to preserve the original strings. Also, for this reason, it doesn’t matter what we choose to be our separator - as you can see right now there is none - that’s because we’re actually not concatenating any strings so no separator is necessary. Though it still needs to be included as a parameter of the string_agg function.
The final step is to add the column with the number of the left page in each row. So it would be 0, 2, 4, 6, and so on, all the even numbers. We already have the numbers in the first column that go from zero but then they are consecutive. So we should be able to simply multiply the values from this column by 2. Let’s rename this first column left_page_number for clarity.
Go ahead and replace the ‘page_number / 2’ after the SELECT keyword with ‘(page_number / 2) * 2 AS left_page_number’ and you can now click the ‘Check Solution’ button to confirm that this is the correct answer to this data science interview question.
WITH series AS
(SELECT generate_series AS page_number
FROM generate_series(0,
(SELECT max(page_number)
FROM cookbook_titles))),
cookbook_titles_v2 AS
(SELECT s.page_number,
c.title
FROM series s
LEFT JOIN cookbook_titles c ON s.page_number = c.page_number)
SELECT (page_number/2)*2 AS left_page_number,
string_agg(CASE
WHEN page_number % 2 = 0 THEN title
END, ',') AS left_title,
string_agg(CASE
WHEN page_number % 2 = 1 THEN title
END, ',') AS right_title
FROM cookbook_titles_v2
GROUP BY page_number / 2
It’s true it may look silly that we first divide the number by 2 and then multiply it by 2 but the reason for this is that we aggregate the data by the expression page_number divided by 2. So in the SELECT statement, we need to leave exactly the same expression page_number divided by two before we can apply more operations to this column. Otherwise, SQL would return an error or we would need to modify the aggregation key, which, however, would change the results to something incorrect.
Conclusion
In this article, you could learn how to use the string_aggr() function and use it during technical data science interviews. This is only one possible solution to this problem, but as mentioned, there are also other approaches and solutions. Our advice is to practice answering the data science interview questions by constructing solutions to them but always try to think of other ways to solve them, maybe you’ll come up with a more efficient or more elaborate approach.
Latest Posts:



Share