How to Remove an Element from a List in Python

Categories:
 Written by:
Written by:Nathan Rosidi
Different Ways to Remove Items from Python Lists with Practical Examples
Removing an element from a list is one of the easiest tasks to perform in Python, but there are different methods, each with a distinct function.
For instance, you may wish to delete all duplicates, skip a particular user, or remove empty strings from a list of names. Although these tasks may appear straightforward, using the appropriate approach results in cleaner code.
In this article, we will explore the most common ways to remove elements and also explore real-life interview questions. If you’d like to expand your knowledge further, you can also check out this guide on python list methods.
Why You Need to Remove Elements from a List in Python
Sometimes your list has items you don’t want. It could be a wrong value, like a zero in a price list. Or a user ID you need to skip. Maybe a repeated entry that breaks your logic.
In these cases, removing the item is the fix. It keeps your list clean and makes your code work better. Python gives you many ways to do this. Each one is useful in a different case. Let’s explore each method individually.

Which Method Should You Use?
Each method for removing elements from a list serves a different use case. Here’s how to decide:
- Use
remove()when you want to delete the first occurrence of a specific value. - Use
pop()when you want to remove an item by index, especially from the end. - Use
delwhen you want to delete items by index or slice ranges. - Use list comprehension when you want to remove all occurrences of a value or apply a condition.
- Use
filter()when working with functions or filtering logic. - Use
set()when you want to remove duplicates (order doesn’t matter).
Sometimes before removing an element, you might need to find out where it is. For that, you can refer to this guide on how to get the index of an item in a list in Python to locate the position.
Remove an Element from a List in Python Using the remove() Method
The remove() method deletes the first matching item. You give it a value, and it takes that value out.
teams = ["Barcelona", "Real Madrid", "Fenerbahçe", "Real Madrid", "Liverpool"]
teams.remove("Real Madrid")
print(teams)
Here is the output.
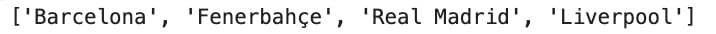
In this case, only the first "Real Madrid" was removed, while the second one is still in the list.
Remove an Element from a List in Python Using the pop() Method
If you want to remove an element by its position, the pop() method would be your choice.
If you don’t give it an index, it removes the last item.
parties = ["Labour", "Democrats", "Republicans", "Conservatives"]
parties.pop(0)
print(parties)
Here is the output.

Here, the item at index 0 ("Labour") was removed. The rest remain in place.
Remove an Element from a List in Python Using the del Statement
The del statement also deletes an item by index, just like pop(). However, it does not return the item; it just removes it.
songs = ["Imagine", "Bohemian Rhapsody", "Hey Jude", "Hotel California"]
del songs[2]
print(songs)
Here is the output.
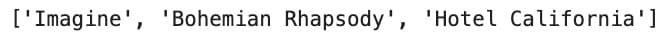
Here, the item at index 2 ("Hey Jude") was removed. Use del when you don’t need to keep the removed value.
Remove an Element from a List in Python with List Comprehension
List comprehension has a whole different approach. It reshapes the entire list based on the condition you give, so as a result, the item you want is deleted. This method is useful when you want to delete items based on a filter.
countries = ["Turkey", "Germany", "France", "Germany", "Italy"]
countries = [c for c in countries if c != "Germany"]
print(countries)
Here is the output.

All "Germany" entries are gone. Unlike remove(), this method eliminates every match in the list. It’s handy when you want to filter out values globally while keeping the rest intact.
Remove an Element from a List in Python Using filter() Function
The filter() function works just like list comprehension. You pass it a function and a list, and it returns the input that passes the test.
names = ["Juan", "Mehmet", "Sofia", "Mehmet", "Luca"]
names = list(filter(lambda x: x != "Mehmet", names))
print(names)
Here is the output.

Just like list comprehension, all "Mehmet" entries are removed. The result is a new, filtered list. Use filter() when you prefer a function-based style instead of writing loops.
Removing Duplicates or All Occurrences of an Element from a List in Python
To remove duplicates in a list, use the set() function. It keeps only one copy of each value.
animals = ["Labrador", "Siamese", "Labrador", "Bulldog", "Siamese", "Bulldog"]
animals = list(set(animals))
print(animals)
Here is the output.

It’s simple and fast.
Practical Application with Real-World Examples
Airbnb Beds Filter Question
3 Bed Minimum
Last Updated: January 2018
Find the average number of beds in each neighborhood that has at least 3 beds in total. Exclude listings where neighbourhood is missing or an empty string.
Output results along with the neighborhood name and sort the results based on the number of average beds in descending order.
In this question, Airbnb asked you to find the average number of beds in each neighborhood, but only for neighborhoods with a total number of beds of at least 3. You should return the results sorted by the average bed count in descending order.
Here is the link to this question. Below is the entire solution.
import pandas as pd
import numpy as np
min_beds = (
airbnb_search_details
.groupby('neighbourhood')
.filter(lambda g: g['beds'].sum() >= 3)
.groupby('neighbourhood')['beds']
.mean()
.reset_index()
.rename(columns={'beds': 'n_beds_avg'})
.sort_values('n_beds_avg', ascending=False))
- The dataset has already been loaded as a pandas.DataFrame.
- print() functions and the last line of code will be displayed in the output.
- In order for your solution to be accepted, your solution should be located on the last line of the editor and match the expected output data type listed in the question.
This solution groups the data by neighborhood, filters out groups with fewer than three beds in total, and then calculates the average. It uses the .filter() method, which effectively removes entries that don’t meet a specific condition: just like conditional list filtering.
Airbnb Guest Ranking Question
Ranking Most Active Guests
Identify the most engaged guests by ranking them according to their overall messaging activity. The most active guest, meaning the one who has exchanged the most messages with hosts, should have the highest rank. If two or more guests have the same number of messages, they should have the same rank. Importantly, the ranking shouldn't skip any numbers, even if many guests share the same rank. Present your results in a clear format, showing the rank, guest identifier, and total number of messages for each guest, ordered from the most to least active.
In this question, Airbnb asked you to rank guests based on how many messages they’ve exchanged with hosts. Guests with the same number of messages should share the same rank, but without skipping numbers in the ranking sequence.
Here is the link to this question. Below is the entire solution.
import pandas as pd
import numpy as np
df= airbnb_contacts.groupby('id_guest')['n_messages'].sum().reset_index().sort_values(['n_messages','id_guest'],ascending=[False,True])
df['ranking'] = df.n_messages.rank(method='dense',ascending=False).astype(int)
df.rename(columns={'n_messages': 'sum_n_messages'}, inplace=True)
my_column = df.pop('ranking')
df.insert(0, my_column.name, my_column)
result=df
- The dataset has already been loaded as a pandas.DataFrame.
- print() functions and the last line of code will be displayed in the output.
- In order for your solution to be accepted, your solution should be located on the last line of the editor and match the expected output data type listed in the question.
This solution first sums the number of messages per guest, then ranks them using the dense method to avoid gaps in rank values. It uses no element removal method, but involves column reordering via .pop() and .insert().
Conclusion
In Python, removing items from a list is a fundamental yet crucial skill. Python provides the tools you need to handle values, indexes, conditions, and duplicates effectively.
As your demands develop, start with simple functions like remove() or pop() and progress to list comprehensions or filter(). Knowing the distinctions makes it simple to select the best approach, and your code becomes cleaner.
Share