How to Nail a Data Science Interview at Google - Real Interview Scenario


Do you have a data science job interview coming up? Get well prepared by looking at this real interview scenario from Google! Are you able to answer this set of data science interview questions?
At a typical technical interview at Google, the interviewer would welcome you and explain the structure of the questions that they will be following. Normally, they will first ask a question relating to statistics or probability, before moving on to the coding task - the candidate will need to use Python or SQL to manipulate a dataset and produce the expected output. In this data science interview scenario, the coding task will be in Python. In the end, they will ask a more open-ended question concerning the products at Google.
Before starting the interview, the interviewer will always ask if you understood the structure and if you perhaps already have any questions. Don’t hesitate to ask if you find anything unclear or confusing - it’s better to pose a question than pretend everything is clear and get lost eventually.
Data Science Probability Interview Questions at Google

The technical interview then starts with the first question. It is about probability and the question is as follows: there are four people in an elevator that is about to make four stops on four different floors of the building. What is the probability that each person gets off on a different floor?

Link to the question: https://platform.stratascratch.com/technical/2358-four-people-in-an-elevator
Clarifications
It’s a good practice to repeat the question or slightly rephrase it to make sure that you have understood it. “So there are four people and four stops and we're interested in the outcomes where each person gets off on a different floor.”
This is also a perfect time, right after hearing the full question, to ask for clarifications and make assumptions. In this case, a candidate may ask if there is no assumption that at least one person needs to get off at each floor? The answer would be no - it is a possibility but it’s also possible that multiple people, even all four of them get off on a single floor.
Another question that you may ask is whether we know anything about these people? Or about the environment, for example, how many people live on each floor? In this case, no, we don’t know anything like that so we can assume that all possible events are independent and have the same probability of occurring.
Solution
When you clear all the ambiguities, it’s time to present a solution. Feel free to take some time to think about it and make some notes before you start speaking - it is totally fine to stay silent for a while. When presenting the answer, don’t only mention the final result. Instead, guide the interviewer through your thought process and show all the intermediate steps. Here is how you can structure the answer to this Google data science interview question:
First, we can count the number of all possible options or events. Since there are four floors and assuming that everyone needs to leave the elevator eventually on one of the floors, nobody will stay in the elevator, each person can get off on either floor 1, floor 2, floor 3 or floor 4. Hence, one person has the possibility to generate 4 distinct events but since we have 4 people in the elevator, the total number of combinations will be 4 times 4 times 4 times 4, so 256.
And next, we need to count the number of favourable outcomes that for us are events where each person gets off on a different floor. In other words, on each floor, someone needs to get off but these people can get off on different floors in a different order. And to find a number of all possible orderings of 4 people, we can use a factorial and so the number of favorable outcomes will be 4! That is equal to 24.
And we are being asked for the probability so the number of favorable outcomes divided by the total number of possible outcomes, so we have four factorial divided by four to the power of four which gives:
which we can simplify to:

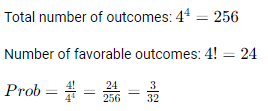
Follow-up Question
After you present the solution, the interviewer will typically validate if it is correct and will certainly ask you some follow-up questions. In this case, it could be the following:
“If we have n floors and k people, how would you generalize this formula to still find the probability of everyone getting off on different floors?”
Again, it’s fine to ask for clarifications or present the assumptions but in this case, these probably wouldn’t change from the original question. It’s also good to take a short while and think about the answer especially given that follow-up questions may be tricky. Such as in this case, where there is no one simple answer. The solution could be as follows:
It depends on the values of n and k. After all, if we have more people than floors then the probability is always 0 because it’s impossible for everyone to get off on a different floor if we still assume that everyone needs to eventually leave the elevator.
Then, the number of people is probably higher than 1 but we can also add that if k is equal to 1, then the probability is 1 because it’s impossible for multiple people to get off on a single floor since there’s only 1 person.
But if the number of floors is larger than or equal to the number of people, then the solution will be similar to my solution for the original problem. We need to divide the number of favorable outcomes by the total number of outcomes. To ensure that everyone gets off on another floor, we need to select k floors out of our n floors so that we can assign them to the k people. Hence the number of favorable outcomes is the total number of ways in which we can make this selection is in fact equal to the n permutations of k.
If n and k are the same, then this becomes simply n factorial, such as we saw in the original question. And then the total number of outcomes is the number of floors, or the number of possibilities each passenger has as to where to get off, to the power of the number of passengers to count all possible combinations of these choices. Therefore, the probability is the n permutations of k divided by n to the power of k.

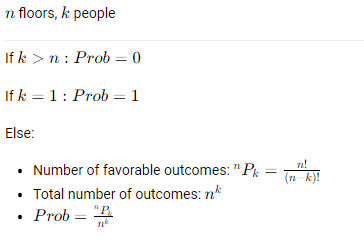
Unless you did something wrong, there is usually no follow-up question to a follow-up question. After you present the answer, the interviewer may validate it or comment on it briefly, before moving on to the next stage of the interview.
To practice more such questions, check these 30 Probability and Statistics Interview Questions for Data Scientists.
Data Science Coding Interview Questions at Google

The next part of the Google data scientist interview is the coding challenge. The task here is to find the email activity rank for each user. I can tell you that the email activity rank is defined by the total number of emails sent. The user with the highest number of emails sent will have a rank of 1, and so on. Your code should output the user, total emails, and their activity rank. Order records by the total emails in descending order and for the users with the same number of emails, please sort them in alphabetical order.

Link to the question: https://platform.stratascratch.com/coding/10351-activity-rank
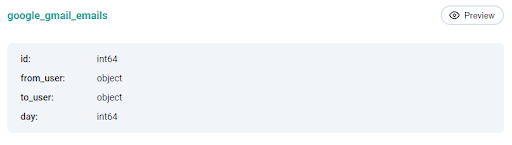
You will typically not be shown any actual data, but the interviewer should show you at least the schema of the dataset that you should use as the input. In this case, it’s one table google_gmail_emails, with the numerical field ID, a string from_user, a string to_user and the numerical field day.

Clarifications
As in the previous question, before jumping straight to the solution, you should first think about whether the question is clear, if there are any parts that are ambiguous and if there are any assumptions you will need to make to solve it. Generally, it is fine to make your own assumptions as long as you communicate them clearly to the interviewer.
In this case, a candidate may have questions about the data. Since was mentioned that the ‘day’ column is numeric, why are these values integers and not have the date or datetime type? The answer may be that this is a simplification because this Google data scientist interview question does not relate to handling dates. You can assume that the dataset contains emails from several days and all emails from the first day have the value 1 in the day column, all emails from the second day have the value 2 and so on.
Another question may be about how are the users represented in this dataset. Do we have their IDs or email addresses or names stored? The interviewer may reply that the solution should work regardless of what the strings in the from_user and to_user columns are, only given that these strings uniquely identify each user. We can assume, for example, that these are some kinds of user IDs composed of random numbers and letters.
A follow-up question may be that if several users have the same number of emails, we should order these IDs alphabetically and based on that apply the ranking values? In this case, yes, if several users have the same number of emails, they should still be given different ranking values and since only this ID of theirs is given in the dataset, it makes sense to use it for the alphabetical ordering.
Solution
Once everything is clear, it’s time to provide the solution. But before you start coding, a good tactic is to write down a few general steps. In this case, the first step may be to aggregate the data by the IDs in the from_user while counting the number of rows - this will give us the number of emails sent by each user. Next, we can use the rank() function to add the ranking values based on the number of emails. And the final step will be to prepare the final output by sorting the results by the number of emails and alphabetically by the user IDs.
- Aggregate the data by from_user while counting the number of rows
- Use rank() function to add ranking values based on the number of emails
- Sort the values by number of emails and user ID
Before we show you how this interview question may be solved, go on and give it a try in the code editor below. When you are done, you can click the ‘check solution’ button to see if you have obtained the expected output. Then scroll down to continue reading and check out the suggested solution to this question in Python.
For the first step, we will start by applying a groupby function to the original dataset, google_gmail_emails. We want to aggregate by from_user so this will be the parameter of the groupby function. Let’s give this aggregated DataFrame the name ‘result’.
result = google_gmail_emails.groupby('from_user')But aside from the aggregation, we should also count the number of rows. So let’s add the size() function to do exactly that. We can reset the index so that the from_user column doesn’t become an index and we can still see it.
result = google_gmail_emails.groupby('from_user').size().reset_index()
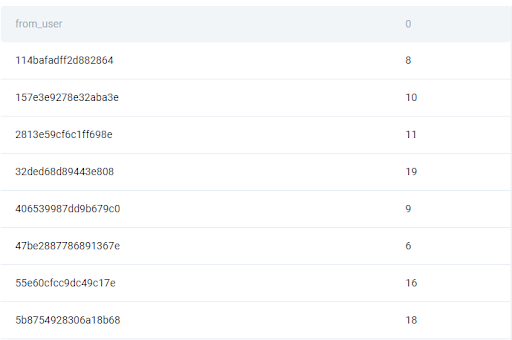
It may be problematic that this new column that basically represents the number of emails sent by each user, has an automatically generated name - zero. Remember that in an interview the readability and solution format are equally important as the correctness of the code. Let’s add a rename() function for readability.
result = google_gmail_emails.groupby('from_user').size().rename('total_emails').reset_index()
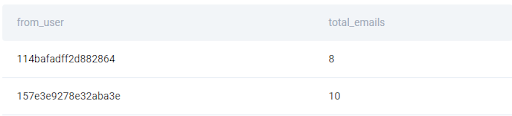
This is the first step. In the second step, let’s start by declaring a new column in the DataFrame ‘result’ - we can store the ranking values in this column.
result['rank'] =Then, the ranking will be based on the column total_emails, the one that we have created by aggregating the data in the first step. So let’s apply the rank() function to this column.
result['rank'] = result['total_emails'].rank()
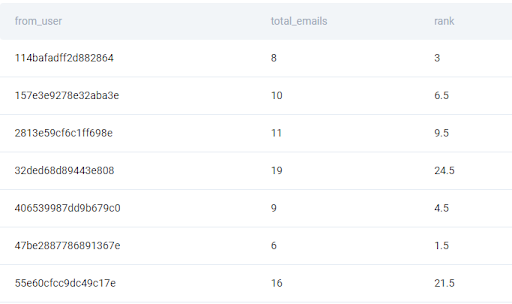
But right now, this is the default ranking function in Pandas that assigns the same values to users with the same number of emails. The ranking method we’re interested in, however, is called ‘first’ in Pandas so let’s add it as the parameter of the rank function.
result['rank'] = result['total_emails'].rank(method='first')
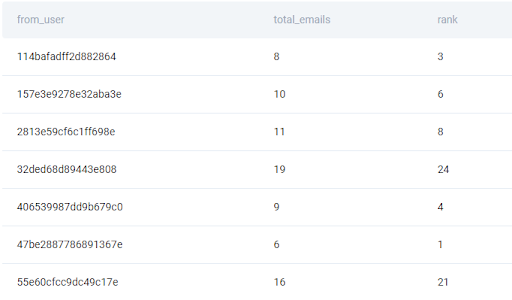
This is an improvement because it assigns a unique value to each user. But still, the user with 8 emails has a lower rank than the user with 10 emails and the question asks for the ranking to work in the other direction. By default, this function applies ranking based on the values in the total_emails column in ascending order. Since we’re interested in the descending order, so for the ranking to be from the highest number of emails to the lowest, let’s change the ascending parameter to false.
result['rank'] = result['total_emails'].rank(method='first', ascending=False)
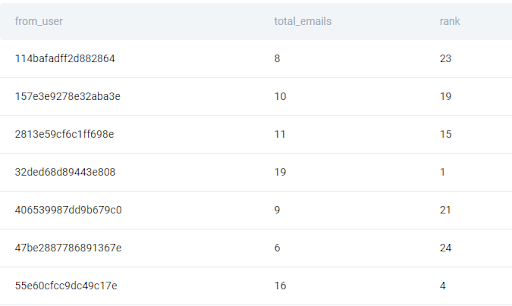
This ranking seems correct so the only thing left to do is to sort the values by the number of emails and user ID. We can use the sort_values function and declare that we should sort both by the total_emails and from_user columns.
result = result.sort_values(by=['total_emails', 'from_user'])
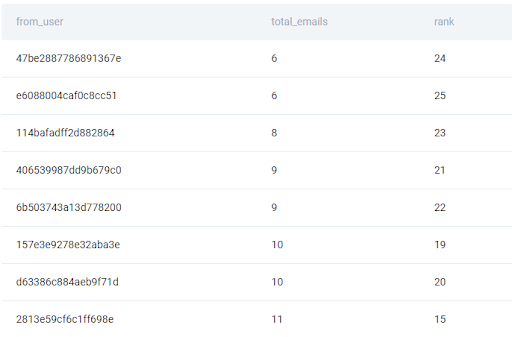
But now, while the user IDs are ordered alphabetically, the total_emails values are ordered in the ascending order while we’re interested in the descending order so let’s add a parameter ascending, this time with two values. This means that the first condition, the total_emails value, should be considered in descending order, hence ascending is set to False. And the second condition, so the from_user string, should be considered in ascending or alphabetical order.
result = result.sort_values(by=['total_emails', 'from_user'], ascending=[False, True])The final solution will therefore look as follows:
# 1. Aggregate the data by from_user while counting the number of rows
result = google_gmail_emails.groupby('from_user').size().rename('total_emails').reset_index()
# 2. Use rank() function to add ranking values based on the number of emails
result['rank'] = result['total_emails'].rank(method='first', ascending=False)
# 3. Sort the values by number of emails and user ID
result = result.sort_values(by=['total_emails', 'from_user'], ascending=[False, True])
Follow-up Questions
After you confirm that you finished writing the code, the interviewer will ask a follow-up question. In this case, it may be the following:
“You applied the rank function only to the total_emails column. How did you ensure that the ranking takes into account the alphabetical sorting of user IDs?”
This is a theoretical question that you should answer quite quickly without changing the code. This is just to see if you have a deep understanding of the functions that you used in the code. The response will be that this is, in fact, a technicality related to the groupby function in Pandas - when the data are aggregated by a column, Pandas automatically sorts the resulting data by this column in the ascending, or in this case alphabetic, order. Therefore, we could simply apply the rank function to the total_emails because it also considered the pre-existing alphabetical sorting which existed from the previous step.
The interviewer may then ask another, tricky question, trying to make you doubt in your previous responses. For example:
“But then the data were sorted alphabetically in the first step and then the rank function sorted them by total_emails in descending order. Then, is the last line even necessary?”
It’s important to remember that this may be a trick and your solution is probably fine, you should simply defend it. In this case, it is because while the rank function was applied given the specified sorting rule, Pandas doesn’t actually change the order of the rows in the DataFrame. So if we want the data in the final output to be ordered by total_emails or the rank, we need to use the sort_values function. And since when sorting by total_emails, Pandas may actually disregard the alphabetical ordering of user IDs from earlier, we also need to include this as the second step in the sort_values function. To stress your point in this case, you can even comment on the final line of code and show the interviewer how the output would change.
Before moving on, the interviewer may ask another follow-up question that may require you to change the code slightly.
“They may assume, for instance, that we actually want all users who have the same number of emails to have the same ranking value, how would you modify the code to achieve this?”
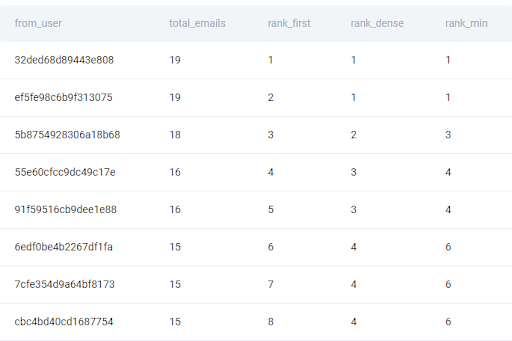
This change can be achieved by changing the method of the rank function. Here, we have chosen the ‘first’ method. But if we allow for the duplicate ranking values, we can change the method to, for example, ‘dense’. Or, if we allow for gaps between the ranking values, then we can use a min method.
result['rank_first'] = result['total_emails'].rank(method='first', ascending=False)
result['rank_dense'] = result['total_emails'].rank(method='dense', ascending=False)
result['rank_min'] = result['total_emails'].rank(method='min', ascending=False)

Data Science Product Interview Questions at Google

The final question of this data science interview would be concerning the products at Google. We observe that there is an increase in users buying Google One 100GB storage plan by 15%. The question is how would you find the reasoning behind this?

Link to the question: https://platform.stratascratch.com/technical/2303-storage-plan-usage
Clarifications
As you should remember by now, you should start by stating assumptions and clarifying any ambiguities about the question. You may start by showing off your knowledge of Google products by saying that from what you remember, Google One currently has 4 plans, there’s a free 15GB plan that all the Google users are at by default. Then there’s a Basic plan with 100GB, a standard plan with 200GB and a premium plan with 2TB of storage. Ask the interviewer if this is all correct.
Another question might be if there is any change to purchases of other plans? For the sake of this question, we can assume that there is no change - the purchases of other plans are as expected and only the Basic 100GB plan had an unexpected increase of 15%.
Then you may ask what is the time span in which the increase occurred? Is this increase consistent throughout the long term or is there a sudden increase? We can say that this is a sudden increase, for example, for several months the number of users buying this plan was rather stable but in the last month, we observed the increase.
And finally, you can pose a hypothetical question if you access any data when investigating the increase? In this case, yes, you can assume that you have access to all data captured by Google.
Solution
Then, you can outline your solution. Again, it’s fine to take a while and think about what you are going to say. Also, remember that when it comes to product-related questions, there is not just one right answer - these questions are asked more to find out how you approach them and what you know about the company’s products. For more information, see our guide to answering data science product sense interview questions.
To investigate this increase, we can start by investigating possible internal factors and then also external factors. The most obvious internal factor could be some kind of promotion or a discount that was introduced in the recent time. This would be easy to find out because major discounts should be recorded in the database or we could check if the users were recently paying the normal or a lower price for the plan. Another factor could be a change to the website that presents the different plans. Maybe the 100GB plan got marked as a ‘recommended’ one. Since Google should keep the archives of its own websites, this should also be easy to trace. There could also be a promotional campaign, not necessarily a discount but, for example, an email or a pop-up that was sent or shown to many users - this could’ve caused the increase and should also be traceable in Google’s databases. Finally, an internal factor may not be related to marketing but to how the Google One storage is used. Maybe before the storage was only for Gmail and Google Drive but last month it got extended to, for example, Google Photos and now users who had the default 15GB plan found that it’s not enough for them.
The external factor may be a sudden increase in the overall number of users. This could be observed from Google's data on the number of users but it wouldn’t fully explain why the increase occurred only for this single Google One plan. So maybe the increase has occurred within a certain demographic of users or within a specific user group that is more prone to opt for the 100GB plan. This would require further investigation trying to estimate which users are most likely to purchase this specific plan. Finally, the increase could have happened due to the users storing more data. Perhaps the average amount of data that a user stores suddenly increased or hit a critical level so that for an increased number of users, the 15GB in the default plan is not enough.
Follow-up Question
After your answer, the interviewer won’t typically confirm if it’s correct or not, such as they do in other types of questions. That’s because, as mentioned, there is not just one correct solution for product sense questions. But the interviewer can still ask a follow-up question. For instance:
“You mentioned at the end an external factor that users may store more data than before and suddenly the 15GB plan isn’t enough. How would you use Google data to verify this claim?”
Again, there is not just one correct solution. The response could be that to see if this factor is really the one affecting the purchases of the 100GB plan, we could observe how much data users store within their Google One plan and how these volumes of data change in time. We can also perform a more global analysis of how much data users on the internet are storing using Google's search engine trends and the extrapolation of the users’ data volumes from Google services such as Drive or Gmail.
After this, the interview is finished. The interviewer may ask you if you have any questions in the end but other than this, there are usually no further discussions.
Conclusion
We hope you enjoyed discovering what a data science interview may look like at Google. You have hopefully learned what different types of interview questions there are, how to ask for clarifications and state assumptions, as well as how to deal with the follow-up questions which are certain to appear in a technical interview.
Remember that the best way to nail a job interview is to practice both the coding and the non-coding questions. Each time you solve one, try also to think what follow-up questions may be asked by an interviewer. Also, check out the ultimate guide to become a data scientist at Google to understand the interview process and find out what Google is looking for in a data scientist. And if you’re curious to know how much a data scientist earns at Google, check out our post 'Google data scientist salary'.
Latest Posts:



Share