How to Drop Duplicates in PySpark?


Categories:
 Written by:
Written by:Nathan Rosidi
Learn how to ensure accurate analysis by identifying and removing duplicates in PySpark, using practical examples and best practices for handling large datasets.
Duplicate entries could distort the results of your research and, hence, lead to false inferences.
Cleaning and De-Duplicating are not just good practices; they are the foundation step of pre-processing to ensure clean and unique data.
In this article, we will use it to guide you through cleaning your data by identifying and removing duplicates in PySpark.
What is a PySpark DataFrame and Why is it Important?
In this section, we'll explain what a PySpark DataFrame is, discuss why it's essential for handling big data, and introduce some basic operations you can do with it.
The PySpark DataFrame is a distributed collection of data organized into named columns, like a table in a relational database. It is the high-level API that provides an optimized way to use RDDs.
Let's create a simple PySpark DataFrame to illustrate its usage.
from pyspark.sql import SparkSession
# Create a Spark session
spark = SparkSession.builder.appName("UnderstandingDataFrame").getOrCreate()
# Sample data
data = [("Alice", 34), ("Bob", 45), ("Charlie", 29), ("David", 34)]
# Create a DataFrame
df = spark.createDataFrame(data, ["Name", "Age"])
# Show the DataFrame
df.show()
Here is the output.


Here we did:
- Initiate the Session: Spark session with the name "UnderstandingDataFrame."
- Sample Data: The list of tuples defining the sample data.
- Displaying the data in PySpark DataFrame Form: Sample data is converted to a PySpark DataFrame.
- Show DataFrame: The DataFrame's content would be visible to see the data.
This PySpark DataFrame makes working with data very comfortable because it offers a variety of data operations, which we can perform, especially with the help of optimized dataframes. Also, it is very easy to process a massive array of data.
Also, check out our post “What is PySpark?”. It’s a deep dive into PySpark's powerful features, practical applications, and expert tips for optimization.
Hands-on Practice: Customer Feedback Analysis
Now, let’s drop duplicates with an interview question from our platform. In this question, Capital One wants us to analyze customer feedback. The feedback was already sorted into three categories. They want us to find comments that are not short, and that come from social media.
Last Updated: January 2024
Capital One's marketing team is working on a project to analyze customer feedback from their feedback surveys.
The team sorted the words from the feedback into three different categories;
• short_comments • mid_length_comments • long_comments
The team wants to find comments that are not short and that come from social media. The output should include 'feedback_id,' 'feedback_text,' 'source_channel,' and a 'comment_category', which is already calculated in the data.
Link to this question: https://platform.stratascratch.com/coding/10366-customer-feedback-analysis
Now, let’s see this question. Here is our dataset.
Let’s turn this answer into codable steps and corresponding codes in PySpark.
1. Filtering Comments
Here, col refers to a column in the dataframe. The code filters the rows to include only those where the comment_category is not short_comments and the source_channel is social_media.
filtered_comments = customer_feedback.filter(
(col('comment_category') != 'short_comments') &
(col('source_channel') == 'social_media'))
2. Selecting Columns
This step narrows down the dataframe to include only the columns we're interested in.
filtered_comments = filtered_comments.select(['feedback_id', 'feedback_text', 'source_channel', 'comment_category'])3. Removing Duplicates
The dropDuplicates() function ensures that the final dataframe does not contain any duplicate rows, making our data clean and reliable for analysis.
filtered_comments = filtered_comments.dropDuplicates()4. Conversion to Pandas
Finally, converting the PySpark dataframe to a Pandas dataframe facilitates easier data handling and visualization in many cases. However, it is better suited for datasets that fit into the memory of a single machine.
customer_feedback = filtered_comments.toPandas()Here is the entire solution.
from pyspark.sql.functions import col
# Filter comments that are not 'short_comments' and come from 'social_media'
filtered_comments = customer_feedback.filter(
(col('comment_category') != 'short_comments') &
(col('source_channel') == 'social_media')
)
# Select only the required columns
filtered_comments = filtered_comments.select(
['feedback_id', 'feedback_text', 'source_channel', 'comment_category']
)
# Remove duplicates
filtered_comments = filtered_comments.dropDuplicates()
# Update the dataframe variable as required
customer_feedback = filtered_comments
# Return the cleaned and filtered dataframe
customer_feedback.toPandas()
Here are the expected output’s first rows.
Why is Dropping Duplicates Important for Accurate Analysis?
With accurate analysis, you can provide consistent results even having duplicate records in your data. You must drop duplicates to ensure your data is correct and accurate. In this section, we will cover the importance of removing duplicates.
Let's see how to identify and drop duplicates using PySpark.
# Sample data with duplicates
data = [("Alice", 34), ("Bob", 45), ("Alice", 34), ("David", 29), ("Bob", 45)]
# Create a DataFrame
df = spark.createDataFrame(data, ["Name", "Age"])
# Show the original DataFrame
print("Original DataFrame:")
df.show()
# Drop duplicates
df_dedup = df.dropDuplicates()
# Show the DataFrame after dropping duplicates
print("DataFrame after dropping duplicates:")
df_dedup.show()
Here is the output.


Let’s see what we did here.
- Duplicate Data sample: Creates a list of tuples with duplicate entries.
- Create DataFrame: This step will convert the posted sample data in PySpark DataFrame.
- Original DataFrame: It is used to View the dataframe first to see the duplicates.
- Drop duplicates: It will drop the duplicate rows using the dropDuplicates() function.
- Show DataFrame after dropping duplicates: Display the DataFrame after dropping duplicates by providing only the pertinent information while maintaining the integrity of the data.
Duplicate removal increases your data analysis's accuracy, leading to more trustful insights and intelligent decisions.
How to Identify Duplicate Records in PySpark?
The first step before we delete anything is identifying duplicate records. This makes it very easy to clean your dataset since PySpark provides various methods to detect duplicates.
Let's look at some code examples to identify duplicates.
# Sample data with duplicates
data = [("Alice", 34) , ("Bob", 45), ("Alice", 34), ("David", 29), ("Bob", 45)]
# Create a DataFrame
df = spark.createDataFrame(data, ["Name", "Age"])
# Show the original DataFrame
print("Original DataFrame:")
df.show()
# Method 1: Using dropDuplicates() function
df_dedup = df.dropDuplicates()
print("DataFrame after dropping duplicates using dropDuplicates():")
df_dedup.show()
# Method 2: Using SQL queries
# Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people")
# Identify duplicates using SQL query
duplicates = spark.sql("""
SELECT Name, Age, COUNT(*) as count
FROM people
GROUP BY Name, Age
HAVING count > 1
""")
print("Identified duplicates using SQL query:")
duplicates.show()
Here is the output.

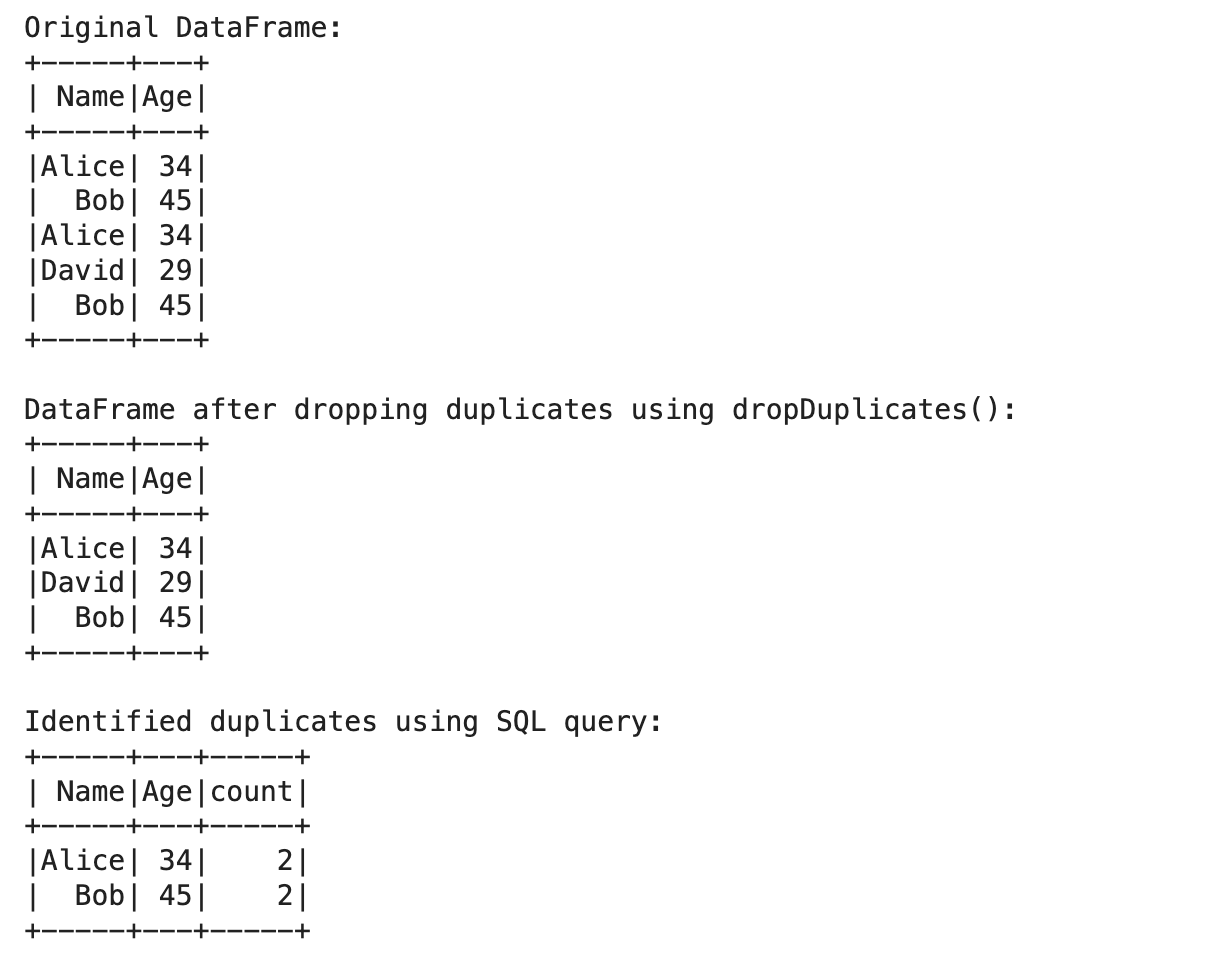
Let’s see what we did here.
- Example Data with Duplicates: This describes a list of tuples that repeatedly contain the same elements.
- Make DataFrame: It converts the sample data to PySpark DataFrame.
- Original DataFrame: This function will let you see the duplicate on your initial or first DataFrame.
- Way 1: follows the dropDuplicates() function to remove the duplicate records and display the Data frame afterward.
- Way 2: Register the DataFrame as a temporary SQL view and execute an SQL query that groups by each record and counts the occurrences of each.
Implementing these methods for duplicate detection will guarantee that your data are clean and prepared for legitimate analytical purposes.
How to Drop Duplicates in PySpark?
Thanks to the dropDuplicates () function, dropping duplicates is very easy in PySpark. This method allows you to specify the columns on which the duplicates must be checked and what to do with them.
Here's how to use the dropDuplicates() function to drop duplicates from a DataFrame.
# Sample data with duplicates
data = [("Alice", 34), ("Bob", 45), ("Alice", 34), ("David", 29), ("Bob", 45)]
# Create a DataFrame
df = spark.createDataFrame(data, ["Name", "Age"])
# Show the original DataFrame
print("Original DataFrame:")
df.show()
# Method 1: Using dropDuplicates() function
df_dedup = df.dropDuplicates()
print("DataFrame after dropping duplicates using dropDuplicates():")
df_dedup.show()
# Method 2: Using SQL queries
# Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people")
# Identify duplicates using SQL query
duplicates = spark.sql("""
SELECT Name, Age, COUNT(*) as count
FROM people
GROUP BY Name, Age
HAVING count > 1
""")
print("Identified duplicates using SQL query:")
duplicates.show()
Here is the output.

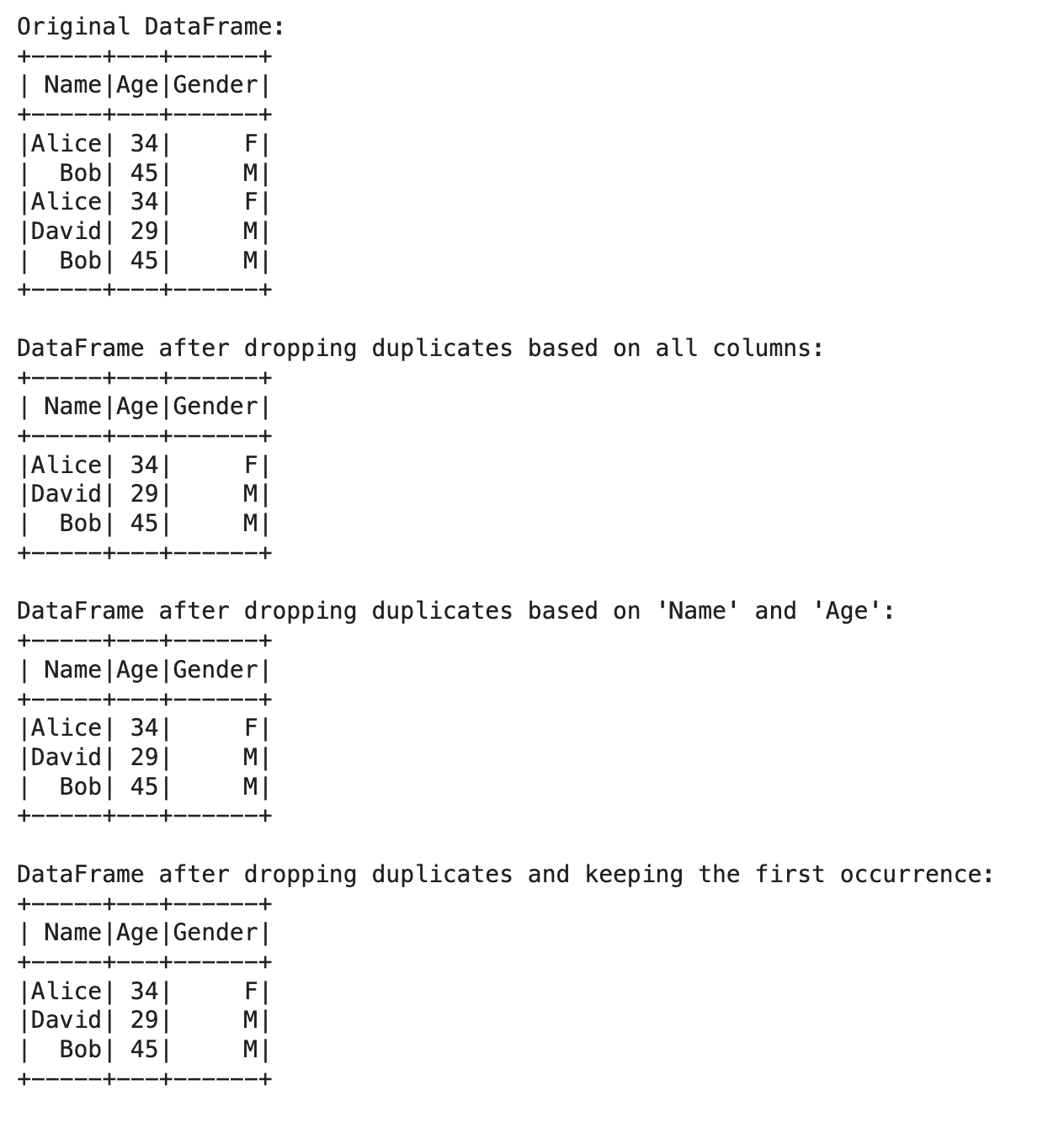
Let’s see what we did here.
- Sample data with duplicates: Describes a list of tuples(which contains duplicates)
- Create DataFrame: Transforms the sample data to a PySpark DataFrame.
- Print Original DataFrame: It will print the first data frame to allow you to see all the duplicates.
- Dropping duplicates based on all columns: dropDuplicates() function is called without parameters to remove duplicates based on all columns.
- Drop duplicates based on the subset of columns: Remove duplicate records based on a few columns using: dropDuplicates(subset=["Name","Age"])
- Customization: By default, dropDuplicates() retains only the first occurrence of duplication. However, we can customize the criteria to keep the desired records.
By setting the parameters for dropping duplicates, you can adjust the process based on your dataset and create a more efficient analysis by keeping only the correct and important data.
How do you handle large datasets efficiently in PySpark?
Dropping duplicates in PySpark can be very inefficient with large datasets. Performance can be much improved using repartitioning, caching, and employing distributed computing capabilities.
Let us look at some ways to deal with Big Data in PySpark.
Here's how you can use partitioning and caching to handle large datasets.
# Sample large data
large_data = [("Alice", i % 100, "F") for i in range(1000000)] + [("Bob", i % 100, "M") for i in range(1000000)]
# Create a large DataFrame
large_df = spark.createDataFrame(large_data, ["Name", "Age", "Gender"])
# Show the number of partitions
print("Number of partitions before repartitioning:")
print(large_df.rdd.getNumPartitions())
# Repartition the DataFrame
large_df = large_df.repartition(100)
print("Number of partitions after repartitioning:")
print(large_df.rdd.getNumPartitions())
# Cache the DataFrame
large_df.cache()
# Drop duplicates
large_df_dedup = large_df.dropDuplicates()
# Show the DataFrame after dropping duplicates
print("DataFrame after dropping duplicates:")
large_df_dedup.show()
Here is the output.

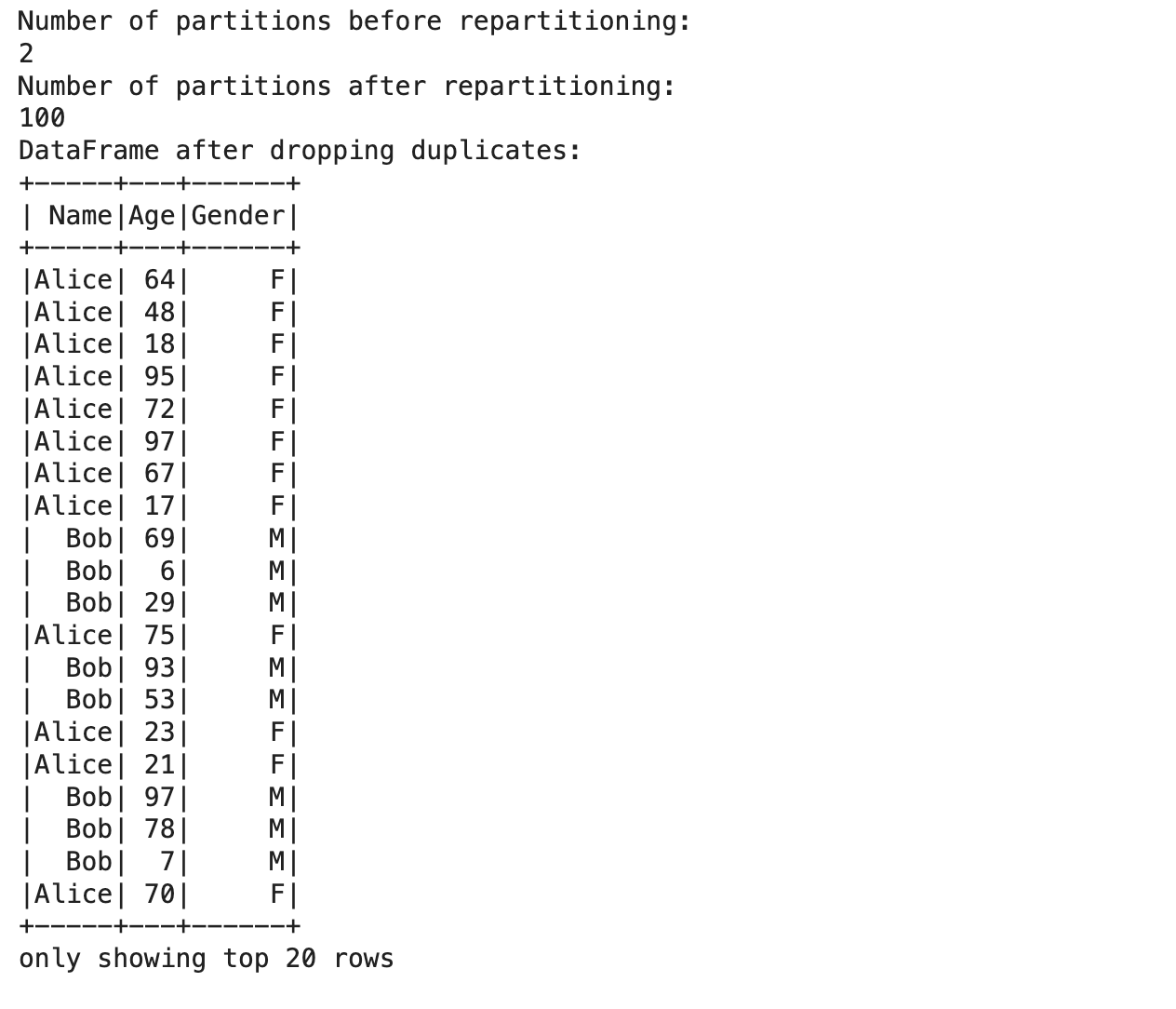
What we did above explained
- Sample Large Data: Randomly selects a large number of duplicate records.
- Create large DataFrame : Converts the big dataset into a PySpark DataFrame.
- Show the number of partitions before re-partitioning: tell you how many partitions your DF had first on which it ran from the last operation.
- Repartition the DataFrame: It uses the repartition() function to add some partitions and for efficient parallel processing.
- Cache (): As the name suggests, it caches the DataFrame in memory to speed up operations on the same data used repeatedly.
- Drop duplicates: Drop duplicates use the function dropDuplicates() to remove duplicates from the large DataFrame.
- Show DataFrame After Dropping Duplicates: Prints the DataFrame after removing those duplicates.
By partitioning and caching, you can process large datasets more quickly, making operations turning the instinct behavior of dropping duplicates fast and efficient.
How do you handle null values before dropping duplicates in PySpark?
Before dropping duplicates, the handling of null should be correct. Only then you will get the proper result. The na functions in PySpark drop() to manage null values.
We'll demonstrate how to handle null values in your dataset before dropping duplicates.
Here's how to use PySpark to handle null values and then drop duplicates.
# Sample large data
large_data = [("Alice", i % 100, "F") for i in range(1000000)] + [("Bob", i % 100, "M") for i in range(1000000)]
# Create a large DataFrame
large_df = spark.createDataFrame(large_data, ["Name", "Age", "Gender"])
# Show the number of partitions
print("Number of partitions before repartitioning:")
print(large_df.rdd.getNumPartitions())
# Repartition the DataFrame
large_df = large_df.repartition(100)
print("Number of partitions after repartitioning:")
print(large_df.rdd.getNumPartitions())
# Cache the DataFrame
large_df.cache()
# Drop duplicates
large_df_dedup = large_df.dropDuplicates()
# Show the DataFrame after dropping duplicates
print("DataFrame after dropping dupl
Here is the output.


Explanation of what we did above:
- Sample Data with Nulls: We created a sample data that includes nulls.
- Creating DataFrame: It makes the sample data converted to PySpark DataFrame.
- Original DataFrame with Missing values: It prints the original DataFrame to detect Missing values.
- Drop rows with missing values: It removes the rows where at least one value is missing – NA/NULL data in a column naïve method. Remove rows having any null values by the drop() function.
- Displaying blank value available rows: This will show you all the rows that contain the row by deleting all the blank values from the DF.
- Take unique rows after treating null values: It has the check of dropDuplicates() function, which removes duplicates from the cleaned DataFrame.
- Displays the Final DataFrame: After duplicates(token) and null values are somewhat handled.
Suppose you handle the nulls before dropping duplicates. In that case, you can provide accurate data results and ensure the information is correct and reliable, which means more accurate metrics or insights.
Performance Considerations for Efficient Duplicate Removal in PySpark
When working with large datasets, performance considerations are a concern for efficient duplicate removal. Date skewness, cluster specification, and resource allocation can make a huge difference to the performance.
Let’s see the code.
# Sample data
large_data = [("Alice", i % 100, "F") for i in range(1000000)] + [("Bob", i % 100, "M") for i in range(1000000)]
# Create a big DataFrame
large_df = spark.createDataFrame(large_data, ["Name", "Age", "Gender"])
# Show partitions
print("Number of partitions before repartitioning:")
print(large_df.rdd.getNumPartitions())
# Repartition DataFrame
large_df = large_df.repartition(100)
print("Number of partitions after repartitioning:")
print(large_df.rdd.getNumPartitions())
# Cache DataFrame
large_df.cache()
# Drop duplicates
large_df_dedup = large_df.dropDuplicates()
# Show the DataFrame after
print("DataFrame after dropping duplicates:")
large_df_dedup.show()
Here is the output.

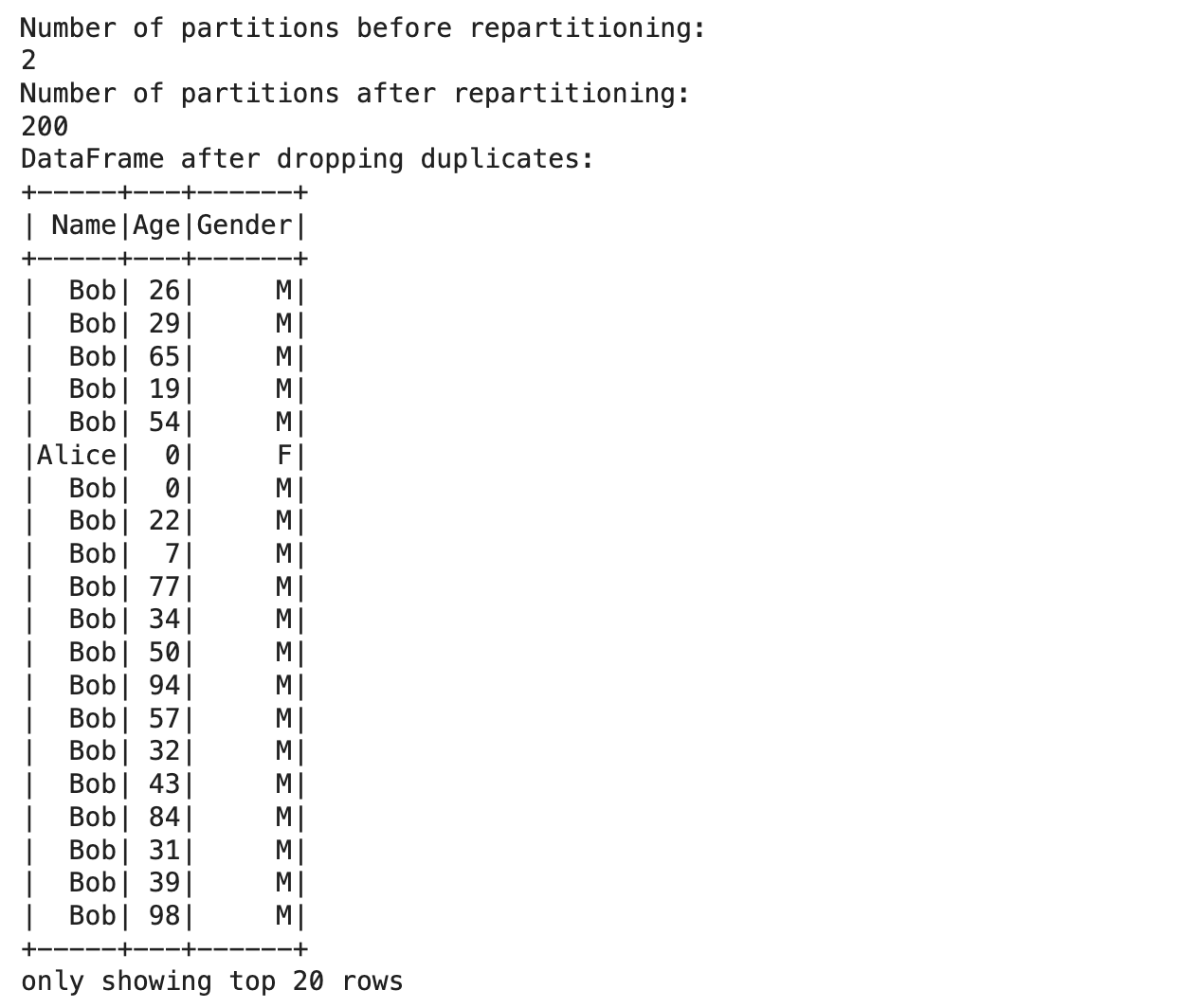
Here is a breakdown of what we did above:
- Sample large skew data: Create a large row of skewed data.
- Big DataFrame: Converted a skewed dataset into the PySpark DataFrame by creating a large DataFrame
- Number of partitions before repartitioning: Shows the number of partitions that existed before repartitioning to demonstrate some imbalance.
- Repartitioning the Data to balance the data: This function uses the repartition() function to evenly scatter the data across partitions based on the “Age” column. ( )
- Cache the DataFrame: The DataFrame is cached in memory, which makes subsequent operations much faster.
- Remove Duplicates: The dropDuplicate() is called on the Dataframe created after balancing → dropDuplicate() → drop all duplicate rows from the Dataframe.
- Show the DataFrame after Deduplication: Ready for a Permanent Table Analysis after taking care of Skew and Caching.
Considering the above performance considerations, you can make PySpark duplicate removal efficient while handling large and imbalanced data.
Best Practices and Tips for Dropping Duplicates in PySpark
Optimizing your code and choosing deduplication strategies are crucial for successful data preprocessing.
The most effective way to remove duplicates is to invoke the built-in function list. drop_duplicates () on the pandas dataframe itself. Below are a few tips that would help with efficient duplicate removal.
# Sample data with duplicates, making sure to emphasize duplicates
data = [("Alice", 34, "F"), ("Bob", 45, "M"), ("Alice", 34, "F"), ("David", 29, "M"), ("Bob", 45, "M"), ("Eve", 45, "F")]
# Create a DataFrame
df = spark.createDataFrame(data, ["Name", "Age", "Gender"])
# Show the original DataFrame
print("Original DataFrame:")
df.show()
# Repartition based on a column likely to have a balanced distribution
df = df.repartition("Age")
# Cache the DataFrame to speed up operations
df.cache()
# Drop duplicates based on a subset of columns
df_dedup = df.dropDuplicates(subset=["Name", "Age"])
# Show the DataFrame after dropping duplicates
print("DataFrame after dropping duplicates based on 'Name' and 'Age':")
df_dedup.show()
Here is the output.


The above is what we didgement in my explanation here.
- Example data with a common value: All the junior partners have distinct ages listed in tuples.
- Create DataFrame: Takes a sample data and converts it into PySpark DataFrame.
- Display the original DataFrame: It will show you the original DataFrame so you can see duplicates.
- Repartition: Partitioning is the process of mechanically adding divisions to dataframes so that operations on the dataframe can run parallel to process the data already in parallel.
- Cache the DataFrame: Storing the DataFrame in memory to accelerate the operation.
- Remove duplicates based on a subset of columns: It accepts an array of column names to check for duplicates and remove them using the dropDuplicates() function.
- Show DataFrame After Dropping Duplicates: Displays the final output after cloning the DataFrame.
Practical Tips
- Repartition: Try to minimize the skew in your data by spreading it equally across the partitions.
- Caching: Use the cache to maintain the intermediate results, which can then accelerate the subsequent operations.
- Subset: Subset takes a list of column names that must be deduplicated.
- Monitoring: Monitor your jobs from spark UI for the performance and make changes accordingly.
- Set the Configuration: Fine-tune the configuration of the cluster according to your dataset size (for example, executor memory and number of cores).
Conclusion
If you are a data scientist working with large datasets, it is important to have hands-on dropping duplicates in PySpark. Handling duplicates safeguards your data analysis from inaccuracy and unreliability of results.
We started with the basics and covered placing PySpark DataFrame, dropping duplicates, and more. We then experimented with more advanced topics, such as extensive dataset management, to find out what works and gives the best results.
These approaches and best practices will enable you to clean your data and make it available for practical application on PySpark.
Also, check out our article “PySpark Interview Questions” to practice more such questions from basics to advanced.
Share


