How to Answer Data Science Interview Questions – Organizing Your Solutions

Categories:
 Written by:
Written by:Nathan Rosidi
Learn how to answer data science interview questions. This article aims to provide an approach to organizing your solution before writing a line of code.
Tip on How to Answer Data Science Interview Questions
When you are in a coding interview, do not start coding as soon as you hear the question!
The tip is to organize the entire approach, organize your solution in your head or maybe on a piece of paper or the whiteboard before even writing a line of code down. The purpose of this tip is just to slow things down and for you to gather your thoughts to answer a lot of the unknowns and clear that up with the interviewer before you start to write code.
Because the worst thing that you could do even after preparing for a data science interview is immediately start coding and realize that you're down the wrong path. The interviewer tells you that ‘oh you can't really assume this’ or ‘you can't really assume that’ or ‘what about this edge case’ or ‘what about that use case’.
By the time you're able to understand everything about this problem and the data, your solution that you've coded up is completely wrong and you're going to have to start from scratch.
So, instead of doing that my advice is to clarify everything you need to know about the solution before even writing a line of code.
This again has several benefits. Here are some of the benefits:
1. To be able to slow things down in an interview
I think this is really important for those who may not be experienced enough to just get the solution right away or maybe nervous and not thinking straight. This will make you able to slow things down to talk to the interviewer to write things out on the editor or a whiteboard. It helps you just clear your mind and think straight.
2. To be able to clear up all of your assumptions
Get clarity on all of the unknowns, understanding what the underlying question could be, understanding the table structure, understanding the data set structure and then understanding just the data itself and how it's stored. Those are all very important when you start to decode up the solution.
3. To be able to have an idea of what the outline of the solution should look like
If you did number one and number two correctly, you should have a good idea of what the outline of the solution should look like. What are all of the logical statements that you have to put into, for example, the WHERE clause? What are all the aggregate functions that you're going to need to use in the SELECT clause? If you're using SQL, that should make sense to you. So, to be able to clarify a lot of the unknowns and to be able to think clearly, will allow you to have a better picture in your head of what the structure of that solution is going to look like.
4. It allows the interviewer to better understand your thought process
It allows the interviewer to better understand:
- How you're thinking through solving the problem
- How you're thinking through the edge cases
- How you're thinking through the use cases
- Do you understand the data correctly
- Do you understand how to manipulate it in the right way
All of that is a conversation to have before even starting to write a line of code.
So, my tip on how to answer data science interview questions is really to organize all of that in your head or on a whiteboard or the editor or a piece of paper with the interviewer before even starting to write code.
Let’s take a practice question to learn how to answer data science interview questions
What I want to do next is show you my computer screen and implement this tip on a real practice data science interview question.
Let's test out this tip on the practice question
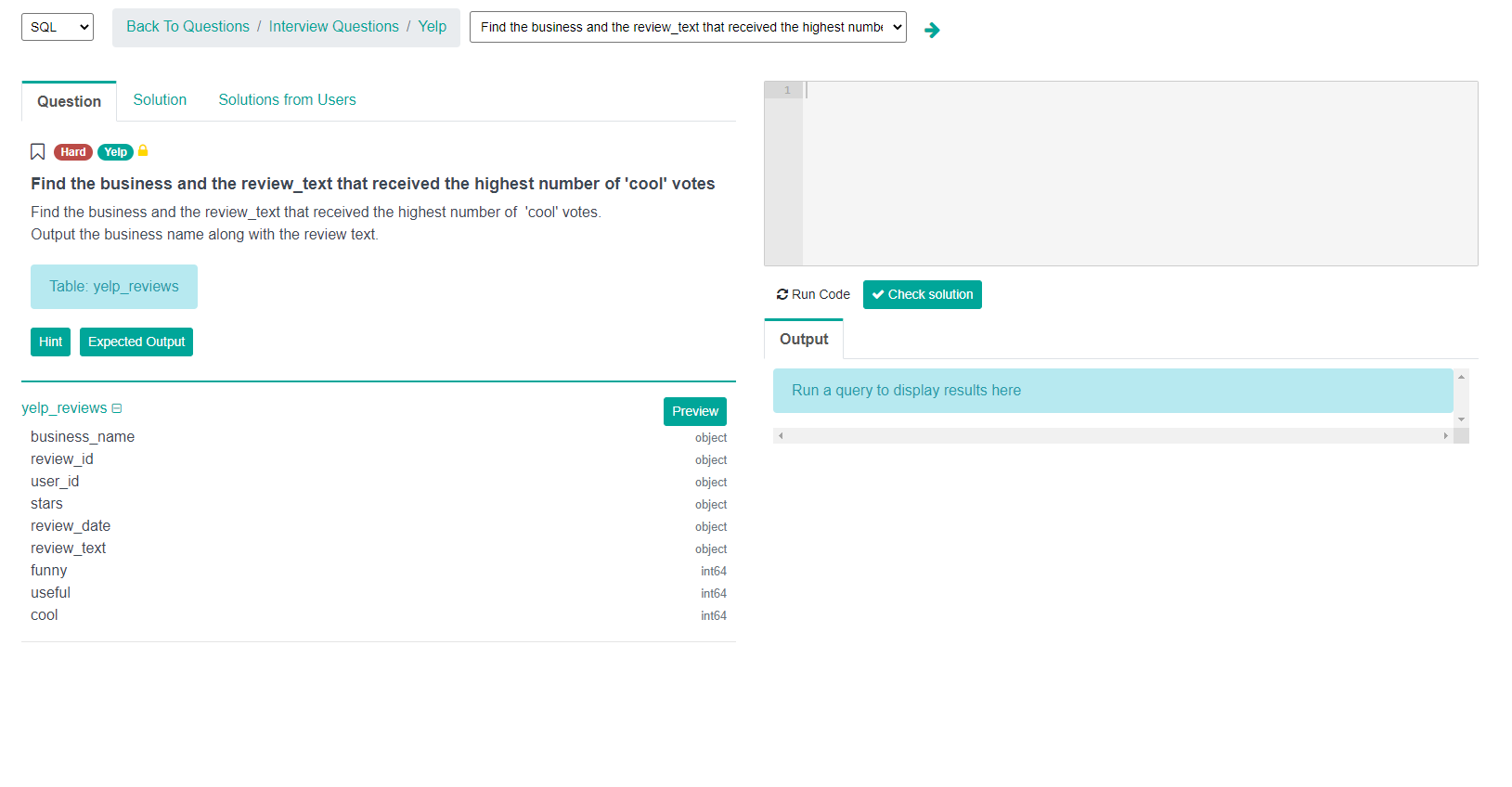
I have opened StrataScratch and went to this interview question.
Here's the link if you want to follow along with me: https://platform.stratascratch.com/coding/10060-top-cool-votes?python=
So, we have the question and some hints if we want the expected output. This is essentially what the solution should display. In the screenshot, you can see the table, the underlying columns, the editor as well as how you can run code.
Let's look at the question below taken from Yelp:
"Find the business and the review_text that received the highest number of ‘cool’ votes.
Output the business name along with the review text."
So, we have a question and the data set. The table is called yelp reviews and we have the columns right below the yelp_review.
Seems like a pretty easy question – syntactically easy to code up in SQL or Python or whatever language that you would be interviewing in.
Some people would immediately start to write code and then ask questions along the way. The problem I have with this is that depending on how you interpret the question and depending on how the data is stored and formatted in the table that completely dictates the approach and the structure to the query to the solution that you would be writing.
The first thing I want clarity on is “what columns do I want to use in this question”.
I know I want the business_name column, review_text column and probably going to want the ‘cool’ column. The problem is I don't necessarily have access to the underlying data and how the data stored in the table dictates how I'm going to write my logic and dictates how I'm going to approach the solution.
The first thing I want to tell the interviewer is what I want to do is identify the most cool votes. That's the first step of this problem before you get to identify the business as well as the review text. You need a way to identify which business or which record in the table has the most amount of cool votes.
The problem I'm seeing is that this table could be formatted in one of two ways. The first way I'm seeing is that the table itself is transactional.

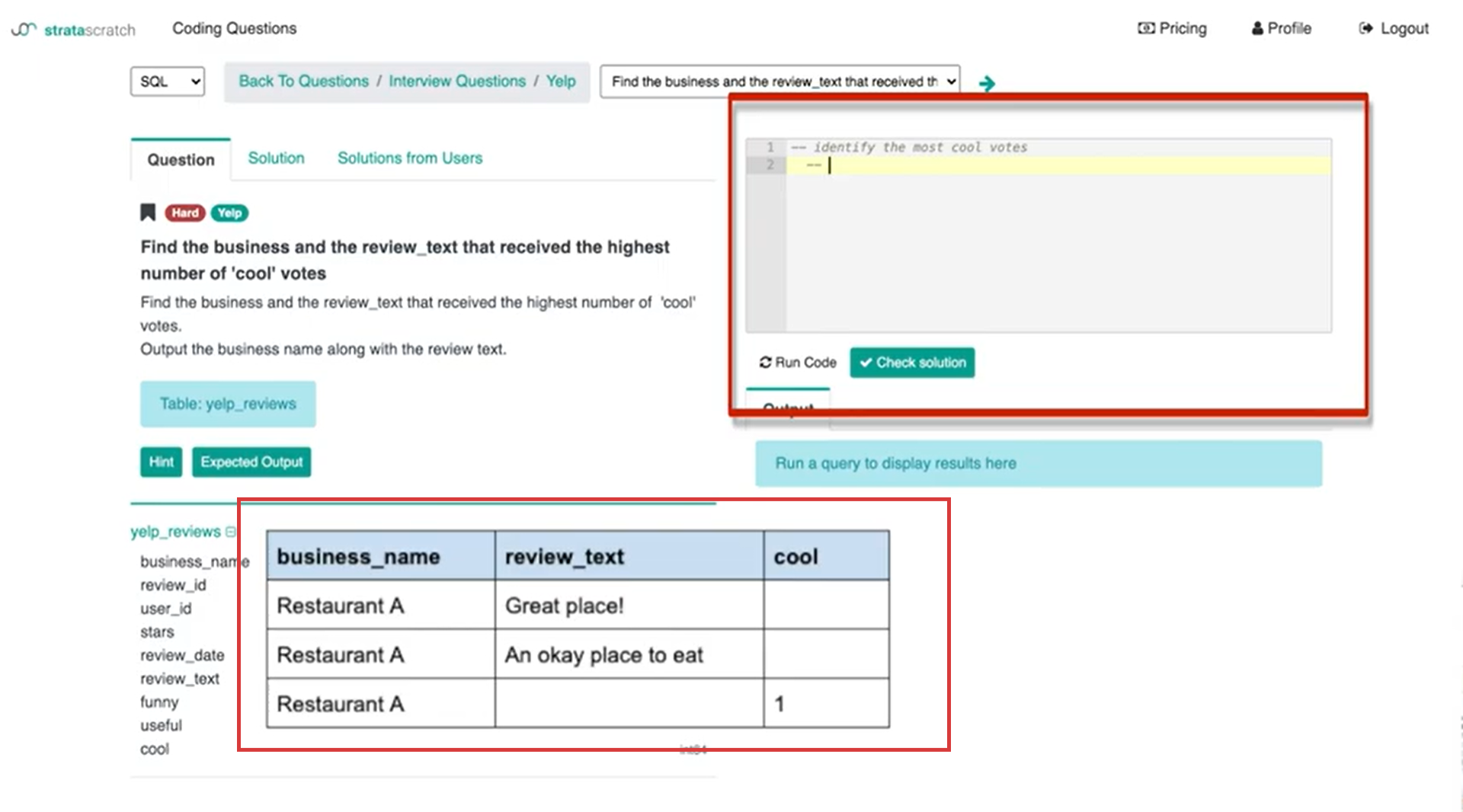
It's one record for every action. That could mean that a user writes a review and then the review is one record and then another user writes the review and a second record is then added to that table. That means that in order to calculate the business with the most cool votes or to identify the most cool votes, I would need to either sum or count the records.
What I can say to the interviewer – is this table transactional? businesses are not unique across the business column and so there are duplicates. If so I would want to either use the ‘count’ or ‘sum’ function.

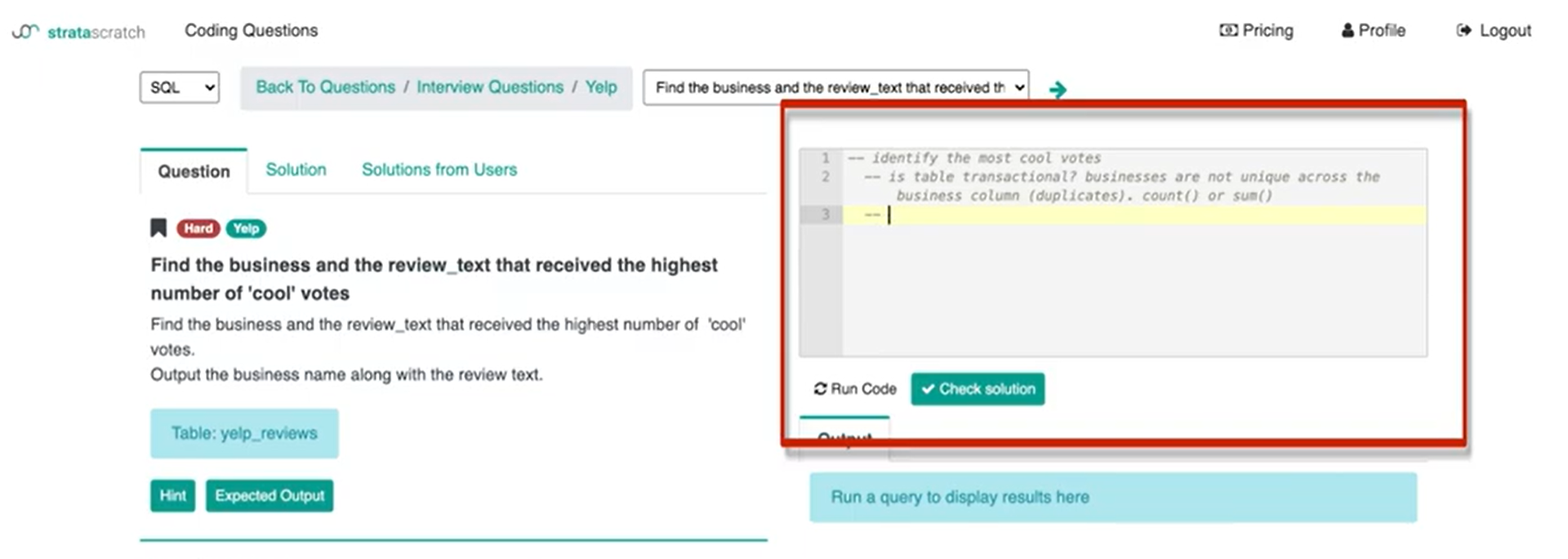
Or
Does it store all of the businesses uniquely? Meaning that each row has a unique business and all we're doing is we're aggregating the cool, useful and funny votes all in one record. I can then write ‘table stores unique business names and cool votes are aggregated’.

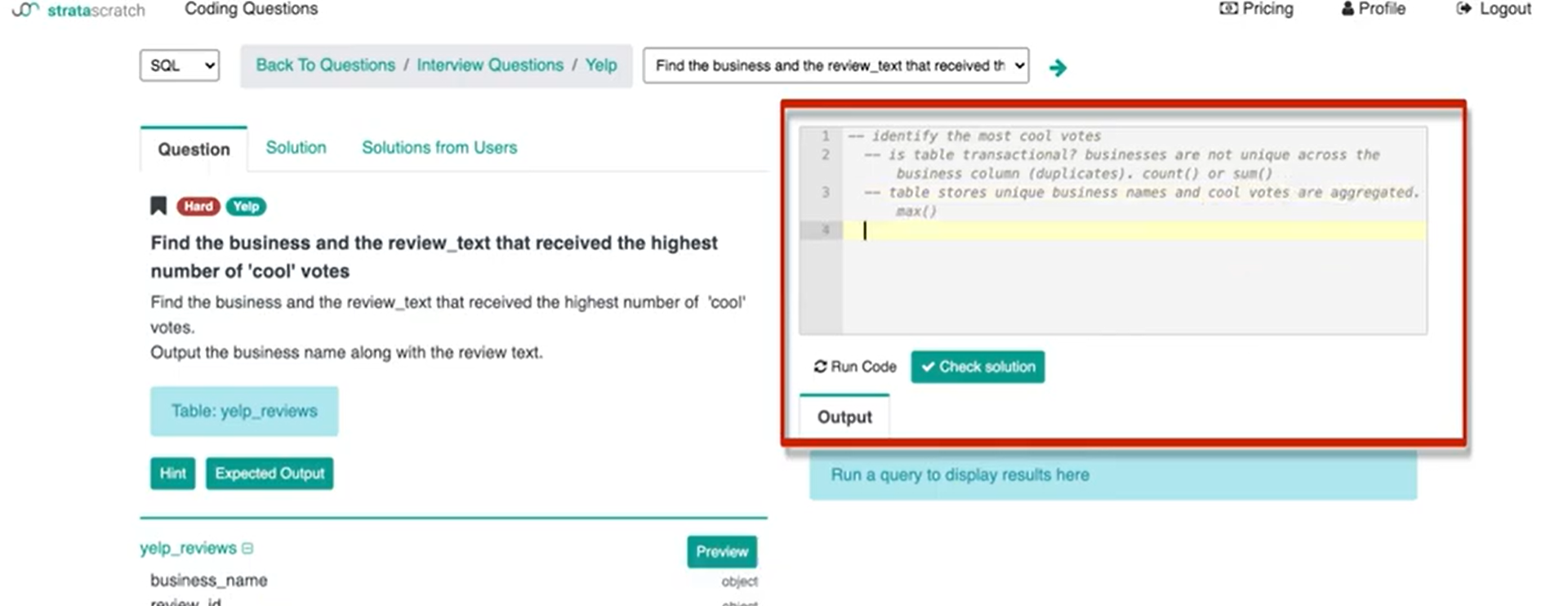
Once I identify the way the data is stored in the table I can start thinking about how I want to write the code and how I'm going to approach the solution.
In this case, let's just say that the table itself here stores unique business names. The number of cool votes is already aggregated on a record level. But you can see with this tip, this conversation is definitely required before you start writing any code because if you guessed wrong, you would have written like 10 lines of code and it would be complete trash. It would not at all answer this question and you would have wasted a lot of time before being able to rewrite your solution and by then the interview might be over. So, this is not the way you’re going to answer data science interview questions.
The next thing I want to talk about is then the ability to identify the business name once you have identified the most cool votes.
So, here I'm seeing two ways I can identify the business name once I've identified the most cool votes.
One is I can get the most cool votes and then I can just do order by. What that’ll do is it will order by companies and businesses with the most cool votes at the top and then with the least amount of cool votes at the bottom. It's basically the table reorganized. Then I can limit that by one if I want to find one company with the most cool votes. I can say – maybe I want to do an order by the cool column and then limit one to get the top result.

The problem here is that if there are three or multiple companies with the same amount of maximum cool votes, say that they all have 20 cool votes and if I limit by one I'm only displaying one company out of the multiple companies that have basically the most cool votes.

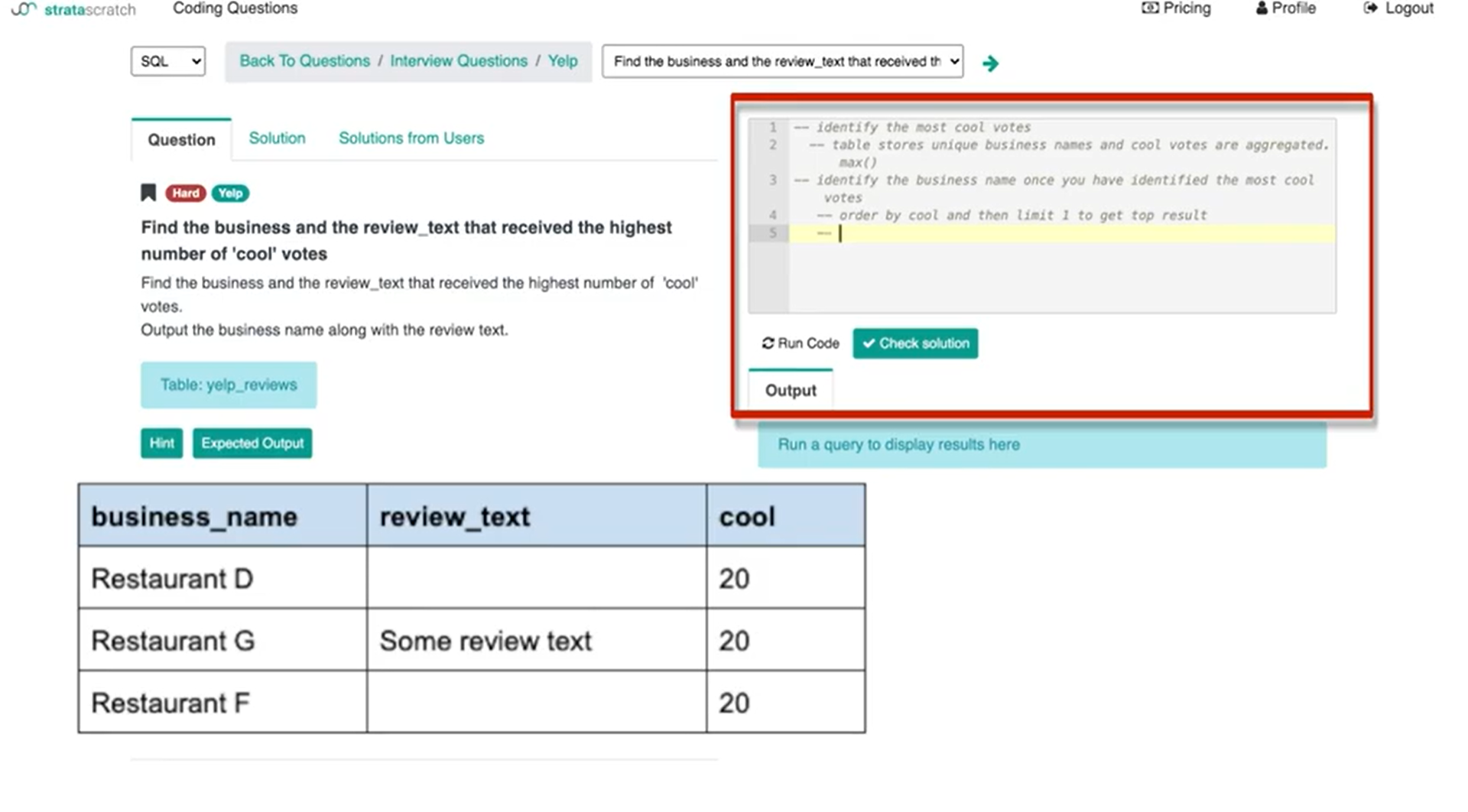
That definitely is not how I want to write the solution but it's very important to tell the interviewer that I understand how SQL works. I understand that this is what the trade-off is going to be if I write the code like this.
What I can do instead is I can use a self inner join.

When you get to an interview and you need to answer a question like this or really any coding interview for data science if you are only given one table the first thing that should go off in your head is – do I need to do a self join? Because joins are very common to test for and if you are not given multiple tables you're most likely going to do some sort of self join or some sort of sub query to actually be able to solve this question.
So, bells were already ringing in my head when I read this question and I saw that there was only one table that we could work with. Immediately I think we're going to use a self inner join.
The second table is going to be utilizing max function:

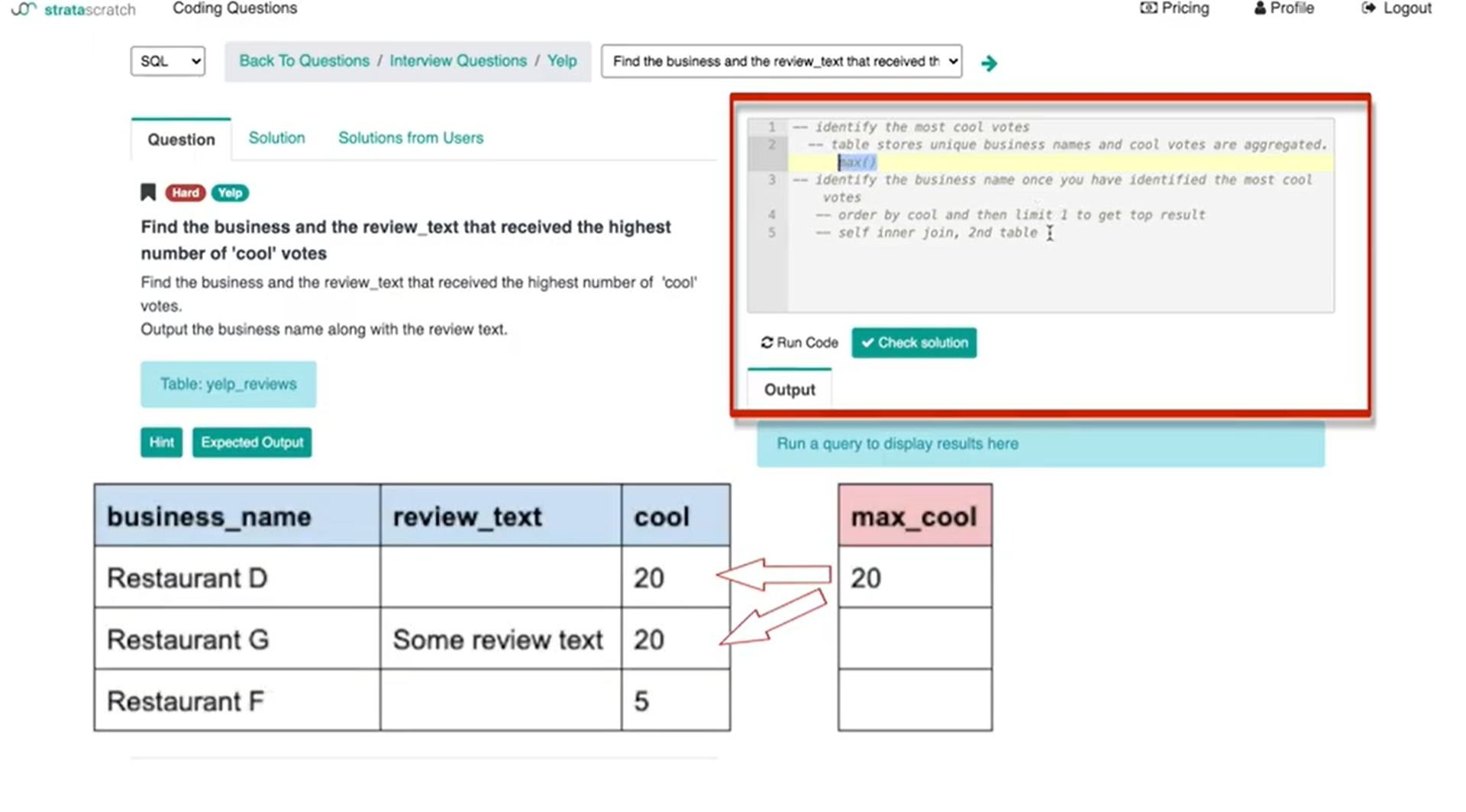
The second table is going to essentially be to identify the most cool votes and then link it back to the original table to get business name and review text.


If I run this whole thought process with the interviewer, they would know what the downsides of using an order by limit one are. Instead, if I say like – hey I'm going to use a self inner join or I'm going to write a subquery, my second table is going to have the most cool votes, so that way I can filter out all of the other companies that don't match that vote count. I can get all of the companies that have the most cool votes. So, if I run that entire thought process with the interviewer they understand that that's what I'm going for and they understand that I'm thinking about the query and the structure so that all of the trade-offs and all of the edge cases they're all addressed.
If I just start coding, what I'm going to do first is write this the subquery where the “2nd table that identifies the most cool votes”.
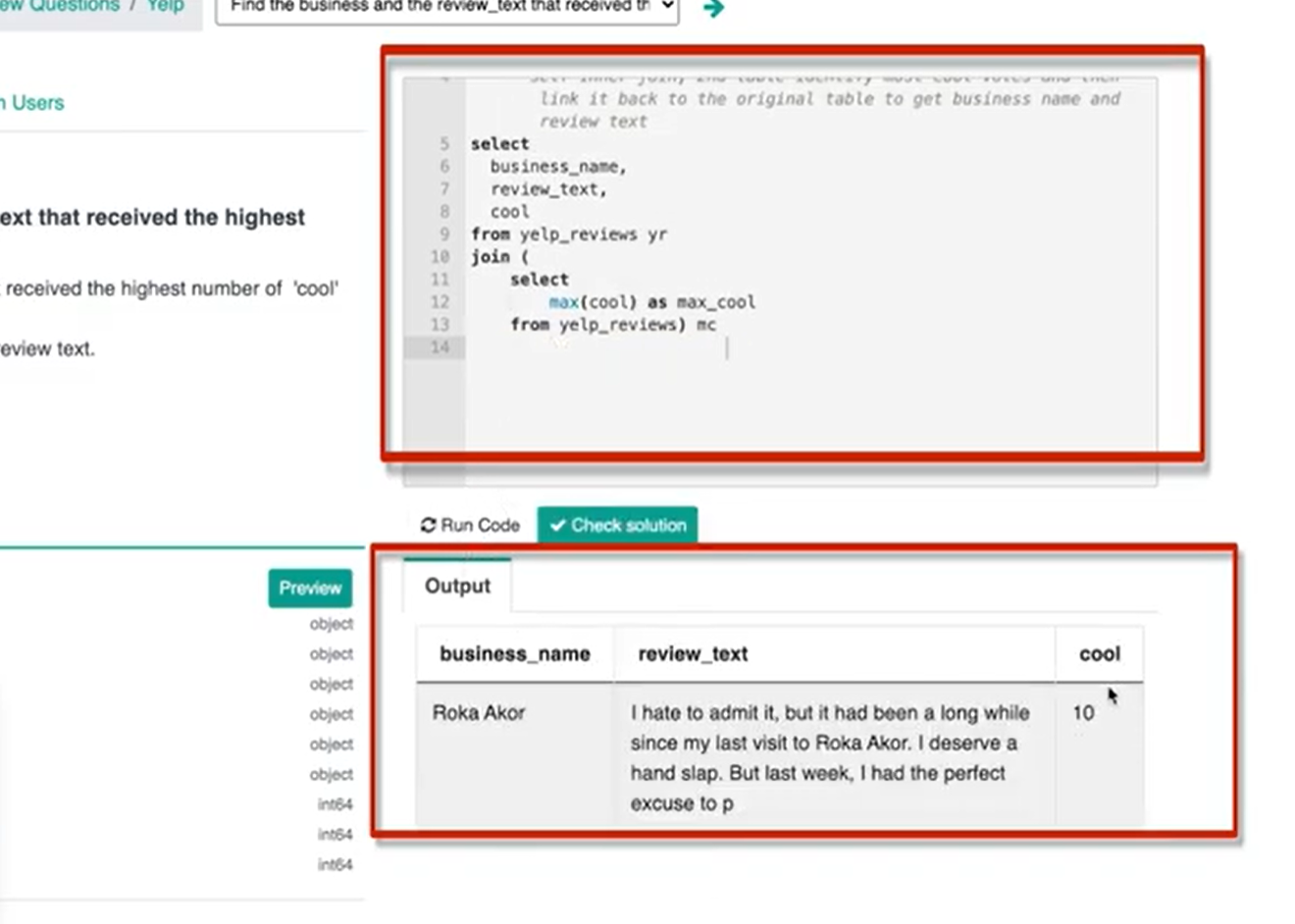
What that's going to look like is essentially it's going to be a max cool as I'm going to name the column ‘max_cool’ for max cool votes from yelp reviews.

If I actually run this query, I get 10. The business or businesses with the most amount of cool votes are going to be businesses with 10 cool votes.
So, this is the subquery and I'm just going to package it into the outer query which is going to be basically outputting business name as well as review text from yelp reviews, and alias it with ‘yr’. Now, I’ll join that subquery and call it max cool (mc). Then I need to now have the ‘on’ the keys. So, on mc.max_cool.

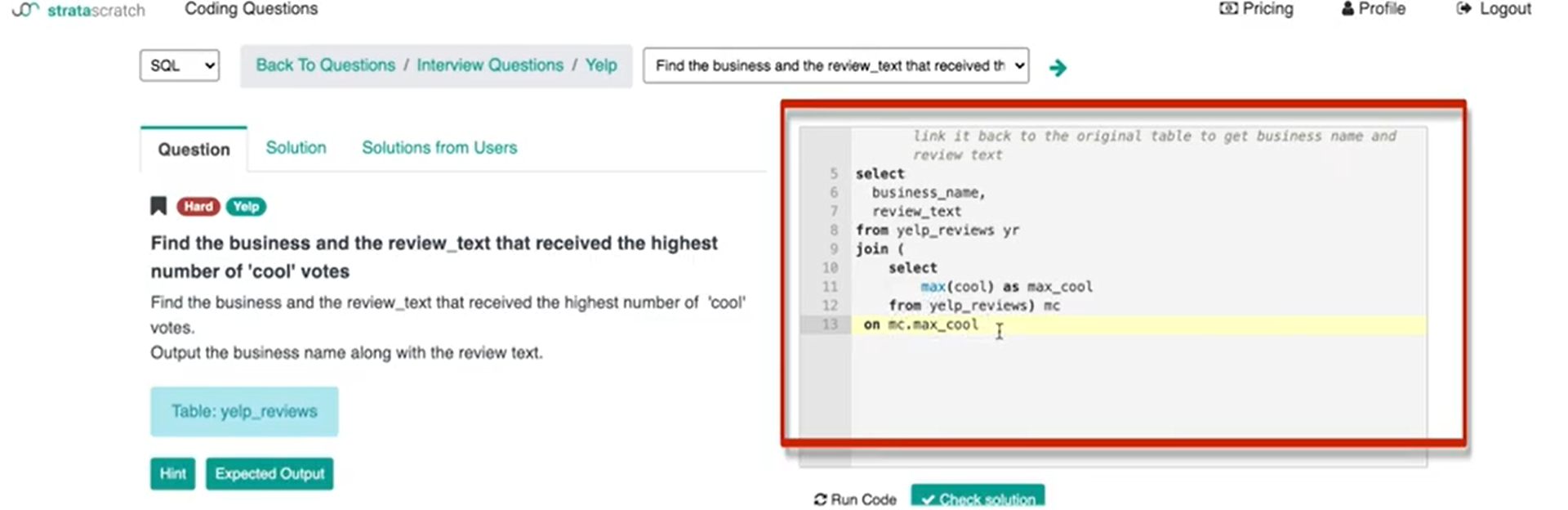
In this little inner join subquery, the only key available is max cool and obviously, I'm going to then make that equal to the cool column from yelp reviews.
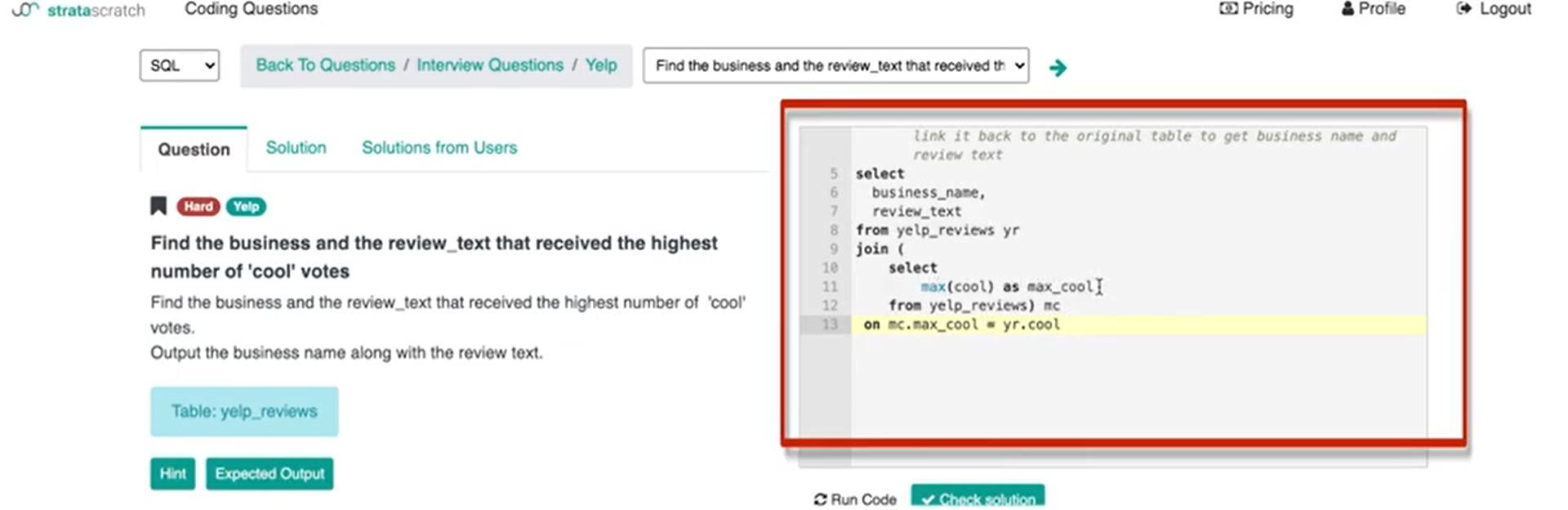
So, we know the value is 10 and then that's going to basically match all records where the cool count is 10.
If you run this line of code we get ‘Roka Akor’ as the business with 10 cool votes.

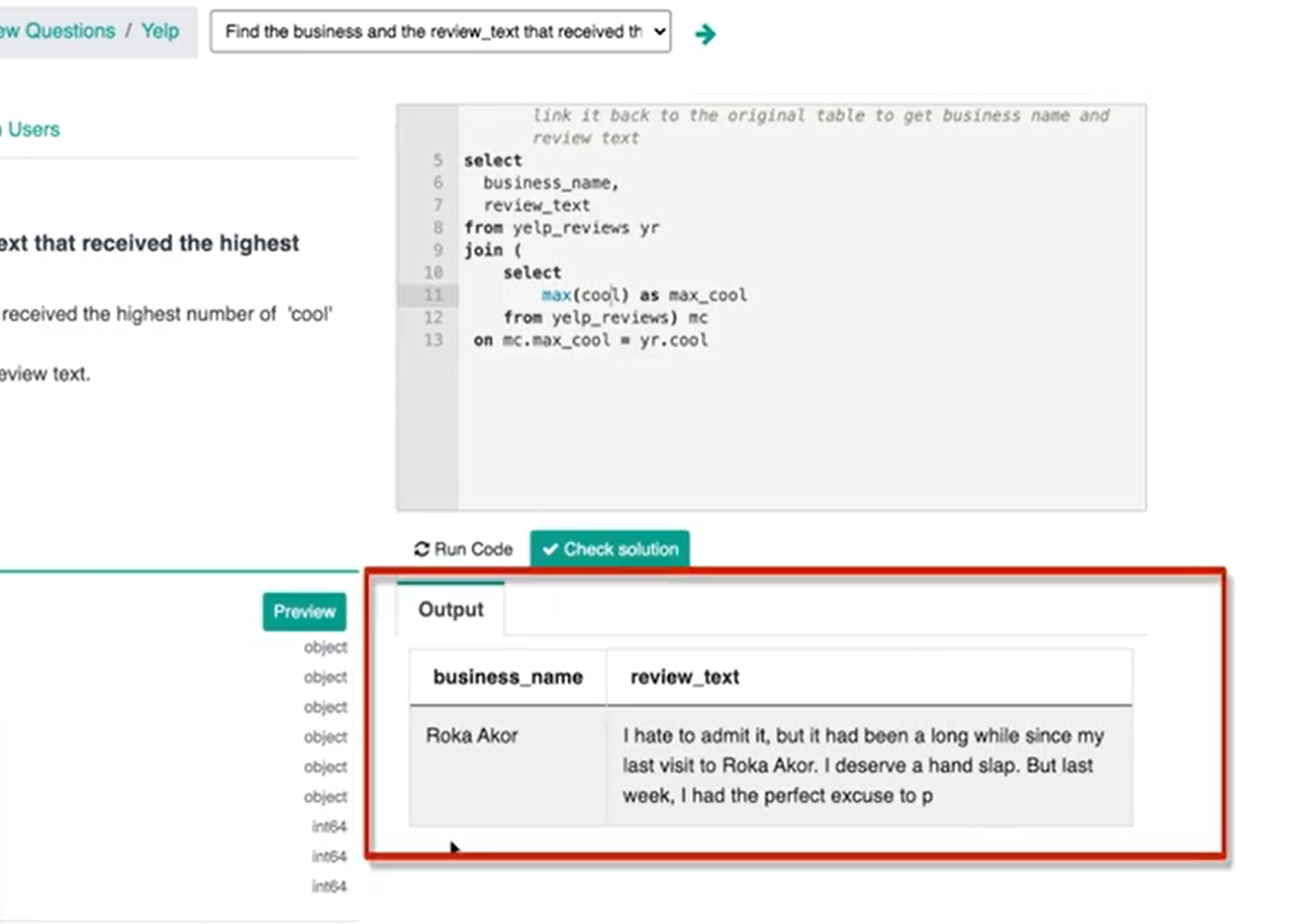
If we wanted to double-check our work, we could also type in the cool column so that what we should get is number 10 and which we do get.

Why Organizing Data Science Interview Solution is Important
My advice on how to answer data science interview questions is not to start coding immediately after you hear or read the interview question. I think what's really important is for you guys to understand what's being asked, understand the tables, the table structure and how all of the data is stored in that. And then to walk through your thought process and walk through what you think your approach would be with the interviewer so that they can get an understanding of how you're thinking. Basically, guide you in the right direction or clarify a few things that might be wrong or unclear.
By doing this you write out your answer in layman's terms and then the only thing you need to do once you get the green light from the interviewer is to write the actual thing out. That should be the easiest part because if you're going to work in data science you should be pretty confident in your coding skills.
But understanding how to get to the solution or how to get to the code is the difficult part. That's what interviewers are trying to filter people out for. What interviewers are trying to look for is people that know how to think and approach solutions in the right way.
So, that's my tip on how to answer any data science question! I hope it makes a lot of sense to you guys. I hope you understood how I implemented that tip onto a practice question so you can see how you might want to do that during your interviews. I know a lot of inexperienced interviewees. What they tend to do is just to jump right in and start coding because it's something that they know how to do it. But in a data science interview or any technical interview, what the interviewer is trying to do is understand how you think and solve problems; is it logical and structured in the right way?
Then after all of that, I am, as an interviewer, going to test whether or not that person knows how to actually write code. But that's later on, I first need to understand how this person thinks through a problem that could be very hard or could be very vague or could have a lot of unknowns; are they able to clarify all of that and then solution something up that works?
Share


