Facebook and Microsoft Data Science SQL Interview Questions


Categories:
 Written by:
Written by:Nathan Rosidi
One of the hard data science SQL interview questions from Facebook and Microsoft that test your ability to segment users and join aggregated tables together.
Data science roles at Facebook and Microsoft are highly competitive and difficult to land. Writing SQL on the job will cover 100% of the problems you're going to handle in practice. In this article, we'll walk through solving the data science SQL interview question from Microsoft and Facebook. We'll also give you some tips on how to approach the solution in such data science interviews.
Also, check out our article Microsoft SQL interview questions and Facebook SQL Interview Questions to find more recent questions.
Data Science SQL Interview Question
New And Existing Users
Calculate the share of new and existing users. Output the month, share of new users, and share of existing users as a ratio.
New users are defined as users who started using services in the current month. Existing users are users who started using services in the current month and used services in any previous month.
Assume that the dates are all from the year 2020.
Question Link: https://platform.stratascratch.com/coding-question?id=2028
5-Step Framework to Solve this Interview Question
This framework can be used for any data science interview questions. Here’s a list of steps you should take when solving a question, whether on an interview or on the job.
- Explore Data
- Only when we’re on the job as most of the time you won’t have executable IDEList assumptions
- List Assumptions
- Listing assumptions helps you narrow down the solution space. It’ll help you identify edge cases and limit your solution to the bounds of your assumption.
- Outline Approach
- Outline the approach by writing it out in steps. Each step is one logical statement or business rule.
- Confirm these steps with the interviewer. Often, if the interviewer spots something wrong, they’ll bring it up which is nice because you can fix the problem before even writing a line of code.
- If you want, you can mention the functions you’d implement to solve the problem.
- Code in Increments
- Build the solution in logical parts and communicate each part so the interviewer knows what you’re doing.
- Your code needs to be logical and well structured. The most important point is not to put more than 1 logical statement or business rule for each “block” of code. A block of code can be defined as a CTE or a subquery because it’s self-contained and separate from the rest of the code.
- Optimize Code
- This is usually just a conversation with the interviewer but on the job, you will usually refactor the code to run more efficiently if the code would be used repeatedly.
Data Exploration
Table Schema:
| id | int |
| time_id | datetime |
| user_id | varchar |
| customer_id | varchar |
| client_id | varchar |
| event_type | varchar |
| event_id | int |
Dataset:

As we explore the data, we can see that the 'time_id' is a date in YYYY-MM-DD so we can extract the month from this date field to find the users that used services in that given month.
The 'user_id' is a regular list of users and will be used to count the number of users that have used the service per month.
The 'event_type' is indeed a service type. We can ignore this column because we’re considering all services. It’s important to have stated that in the assumptions with the interviewer. If you were looking for specific events and services, you’d need to use this column in your solution. Luckily we don’t have to as the solution would be much more complicated otherwise.
Assumptions
- Time_id indicates when the user is using a service. All the data is from 2020. This will help us identify new and existing users.
- User_id is all we need to identify users.
- Each time a user uses a service, it’s logged in the table so users are listed multiple times in the table
- Event_type is the service but that isn’t needed for the solution since we’re considering all services or events
Outline Approach
Outlining your approach before you start coding is very important. The major benefit of typing out what your approach is to get a confirmation from the interviewer that these steps are correct. If the interviewer identifies a problem with your approach or with the logic then you can of course correct them before even writing any code.
Now, let's go through our approach for this data science SQL interview question:
- Find the new users which are defined as users that have started using services for the first time. I can use the min() to find the first date a user used a service.
- Calculate all the users that have used services by month. This will give us existing users once we subtract out the new users.
- Join the new users and all users table by month.
- Calculate the shares by dividing the count of new users by the count of all users. Calculating the share of existing users is merely the difference between 1 and the share of new users.
Code in Increments
Now, you should have the following steps in your approach. Code each one of them and build on top of your existing code and then check to see if the query will run each and every time you're adding logic to it. Here are the steps:
- Calculate new users
- Calculate all users
- Join tables
- Calculate user share
Let's go through these steps.
1. Find the new users which are defined as users that have started using services for the first time.
We can find this by finding the minimum date from the 'time_id' column for each user, which gives me the date they started using services.
SELECT user_id,
min(time_id) as new_user_start_date
FROM fact_events
GROUP BY user_id2. Calculate the count of new users by month by extracting the month from the date and counting unique users
SELECT date_part('month', new_user_start_date) AS month,
count(DISTINCT user_id) as new_users
FROM
(SELECT user_id,
min(time_id) as new_user_start_date
FROM fact_events
GROUP BY user_id) sq
GROUP BY monthTo aggregate users by month, we can use the date_part() function and pull out the month from the 'time_id'. Knowing that all the dates are within 2020 helps because I know that the months will all come from 2020. If we had several years in this dataset, we couldn’t use date_part() because the months from different years would be mixed together. We’d have to use a to_char() function and aggregate the data by MM-YYYY.
3. Calculate all users (existing and new) for each month
This will give us existing users once we subtract out the new users.
SELECT date_part('month', time_id) AS month,
count(DISTINCT user_id) as all_users
FROM fact_events
GROUP BY month4. Join the two tables together by month
with all_users as (
SELECT date_part('month', time_id) AS month,
count(DISTINCT user_id) as all_users
FROM fact_events
GROUP BY month),
new_users as (
SELECT date_part('month', new_user_start_date) AS month,
count(DISTINCT user_id) as new_users
FROM
(SELECT user_id,
min(time_id) as new_user_start_date
FROM fact_events
GROUP BY user_id) sq
GROUP BY month
)
SELECT
*
FROM all_users au
JOIN new_users nu ON nu.month = au.month5. Calculate user shares
with all_users as (
SELECT date_part('month', time_id) AS month,
count(DISTINCT user_id) as all_users
FROM fact_events
GROUP BY month),
new_users as (
SELECT date_part('month', new_user_start_date) AS month,
count(DISTINCT user_id) as new_users
FROM
(SELECT user_id,
min(time_id) as new_user_start_date
FROM fact_events
GROUP BY user_id) sq
GROUP BY month
)
SELECT
au.month,
new_users / all_users::decimal as share_new_users,
1- (new_users / all_users::decimal) as share_existing_users
FROM all_users au
JOIN new_users nu ON nu.month = au.month
If we run this query, we now have the share numbers for new and existing users by month.
Output:

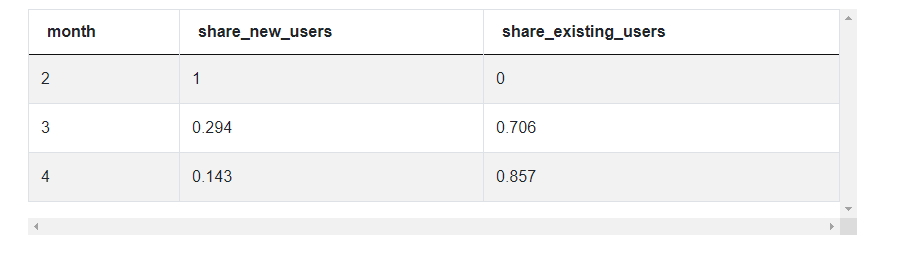
An important note here is that the calculation for existing users can be calculated by subtracting 1 from the share of the new users. Also, remember to convert the share calculation to a decimal or float data type before performing the division.
Optimization
A question that often gets asked is if there’s a way to optimize the code. The interviewer is testing your theory behind SQL so you should say something even if there’s no way to optimize the code.
Taking a look at our solution, there’s no way to optimize this code any further.
Sometimes you can remove a join by using a case statement but it won’t work in our approach because we need to identify the minimum date across the entire dataset and case statements would go row by row. So you need a subquery or CTE to perform that operation.
You also need to perform the same subquery/CTE operation to find all the users by month so we can’t optimize that part of the code or the join of the two subqueries.
Even if there’s no way to optimize the code but you still drop some knowledge on SQL, it would pass the interviewer’s assessment of whether or not you know SQL theory.
Find more SQL interview questions here.
Conclusion
This was one of the hard data science interview questions due to the fact that you’re trying to find the first time a user has used a service. It’s not always obvious to use the min() function as a way to identify new users. You’re also using advanced SQL functions to extract date components like the month from a date field, which make the question more complicated. But it’s necessary to learn how to manipulate dates in data science since most analyses have a date component.
The trick to this data science SQL interview question is using a framework to organize your thoughts as there are multiple steps. Once you lay out your assumptions, like knowing that all the dates are from 2020 and you’re considering all services in your solution, the question becomes much easier to solve. All you need to do is organize your approach in logical and concise steps, and code it up.
Practice the framework and practice organizing your thoughts before coding, and answering complicated questions will become much easier.
Share


