Data Science Python Interview Question Walkthrough


 Written by:
Written by:Nathan Rosidi
In this article, we show how to approach and solve a challenging data science question from an interview at the City of San Francisco.
If you want to excel in extracting information from address strings, you will find this useful.
The City and County of San Francisco employs, according to various sources, between 35 and 45 thousand people. These positions are spread across many of its departments such as finances, health, transportation, law enforcement, museums or even the San Francisco International Airport. This includes data scientists who are employed either within the Department of Technology or as a supporting role in another division.
Generally, to become a data scientist at the City of San Francisco one is expected to have experience in performing data mining, data processing, and exploratory data analysis using SQL, Python libraries (e.g., NumPy and pandas), and big data tools (e.g., Hadoop MapReduce and Spark). Particularly knowledge in programming and developing algorithms in Python is a major requirement. Data scientists can expect to perform hypothesis testing, regression, classification, clustering, time series analysis, natural language processing, feature engineering, and predictive modeling as part of their job.
Technical Concepts Tested in Interview Questions
In this article, we discuss and solve one of the data science interview questions that require string manipulation and information extraction from an address. This example represents a large portion of data science questions at the City of San Francisco because in many cases candidates are asked to extract information from or summarise data that somehow relate to the city governance - business registries, census data, statistics, payrolls etc.
In many of these questions the task involves extracting information from text, such as business type from its name, zip codes or street names from address, or department from a position name. The assignments like this require the knowledge in manipulating strings, constructing conditional statements and applying the methods to large datasets. Additionally, they test skills that are not specific for any specific programming language, for instance, identifying and solving edge cases.
Data Science Interview Question: Health Inspections Per Street
This question has been asked to those interviewing to get a job at the City of San Francisco and is titled ‘Health Inspections Per Street’. It’s a hard-level question because dealing with all the edge cases when working with addresses is always tricky.

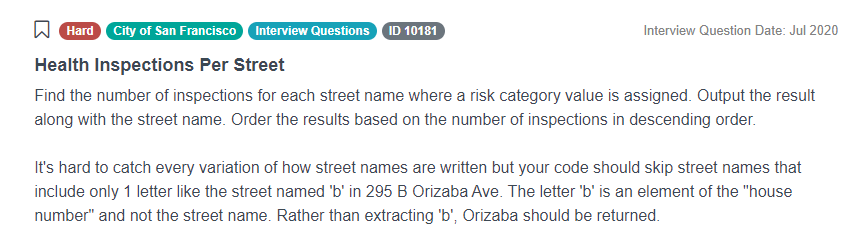
Link to the question: https://platform.stratascratch.com/coding/10181-health-inspections-per-street
We’re being asked to find the number of inspections for each street name where a risk category value is assigned. We’ll see the data and find out what the risk category value is in a moment. It also says that we should output the result along with the street name and order the results based on the number of inspections in descending order.
This already tells us that we’ll need to extract a street name from an address and the second paragraph gives us further instructions on how to do it. It correctly realizes that it's hard to catch every variation of how street names are written. There’s an example given here: your code should skip street names that include only 1 letter like the street named 'b' in 295 B Orizaba Ave. The letter 'b' is an element of the "house number" and not the street name. Rather than extracting 'b', Orizaba should be returned.
What the question is warning us about is not to simply assume that we can just find the first space in the address string and assume that everything before the space is a house number and everything after in a street name. There are edge cases, like this one with the house number 295B that we need to account for in our solution.
Framework to Solve the Problem
Before we start devising the solution, let me share with you the 3-steps general framework to solve any data science problem. It’s especially useful for solving interview tasks as given the stress, it’s lifesaving to have a systematic way to approach any question, but it also comes useful in general e.g. in your data science career.
- Understand your data:
- List your assumptions about the data columns so you know which columns to use
- If you still don’t feel confident you understand your data enough, view the first couple of rows of your data (single or multiple tables). Or if in an interview, ask for some example values so you understand the actual data, not just the columns. It’ll help you identify edge cases and limit your solution to the bounds of your assumption.
- Formulate your approach:
- Write down the logical steps you are supposed to program/code.
- Identify the main functions you would use/implement to perform the logic.
- Interviewers will be watching you; they will intervene when needed, make sure you ask them to clarify any ambiguity, they will also specify if you can use ready- made functions, or you should write code from scratch.
- Code Execution:
- Build up your code, do not oversimplify, do not overcomplicate it either.
- Build it in steps based on the steps outlined with the interviewer. That means that the code is probably not going to be efficient but that’s fine. You can talk about optimization at the end with the interviewer.
- The most important point is not to over complicate your code with multiple logical statements and rules in each code block. A block of code can be defined as a CTE or a subquery because it’s self-contained and separate from the rest of the code.
- Speak up and talk as you’re laying down code as the interviewer will be evaluating your problem-solving skills.
Understand your Data
Let’s start by looking at the data we have available to solve this question. Usually, at an interview we won’t be given any actual records, instead we’ll see what tables or data frames are there and what are the columns and data types in these tables.
In the case of this question, we can see we only have 1 data frame, ‘sf_restaurant_health_violations’ but it has quite a lot of columns. It seems like each row in this data set corresponds to one violation. Each violation is described by the last 3 columns. It was identified during a certain inspection where an inspection has some ID, date, score and type. Finally, each violation is identified at a certain business that is identified by these first 10 columns. Since we just made some assumptions about the data, it’s always a good idea to share all of this with an interviewer and confirm with them if your assumptions are correct.

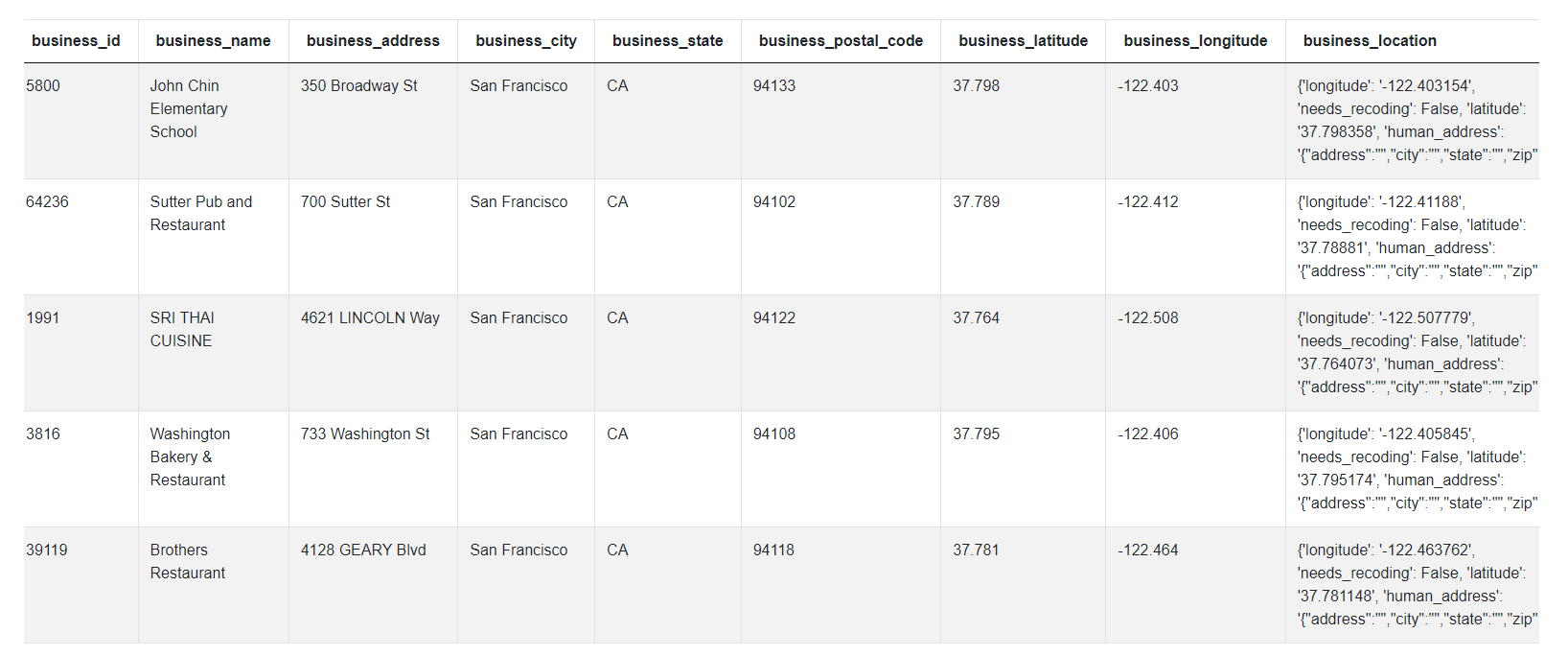

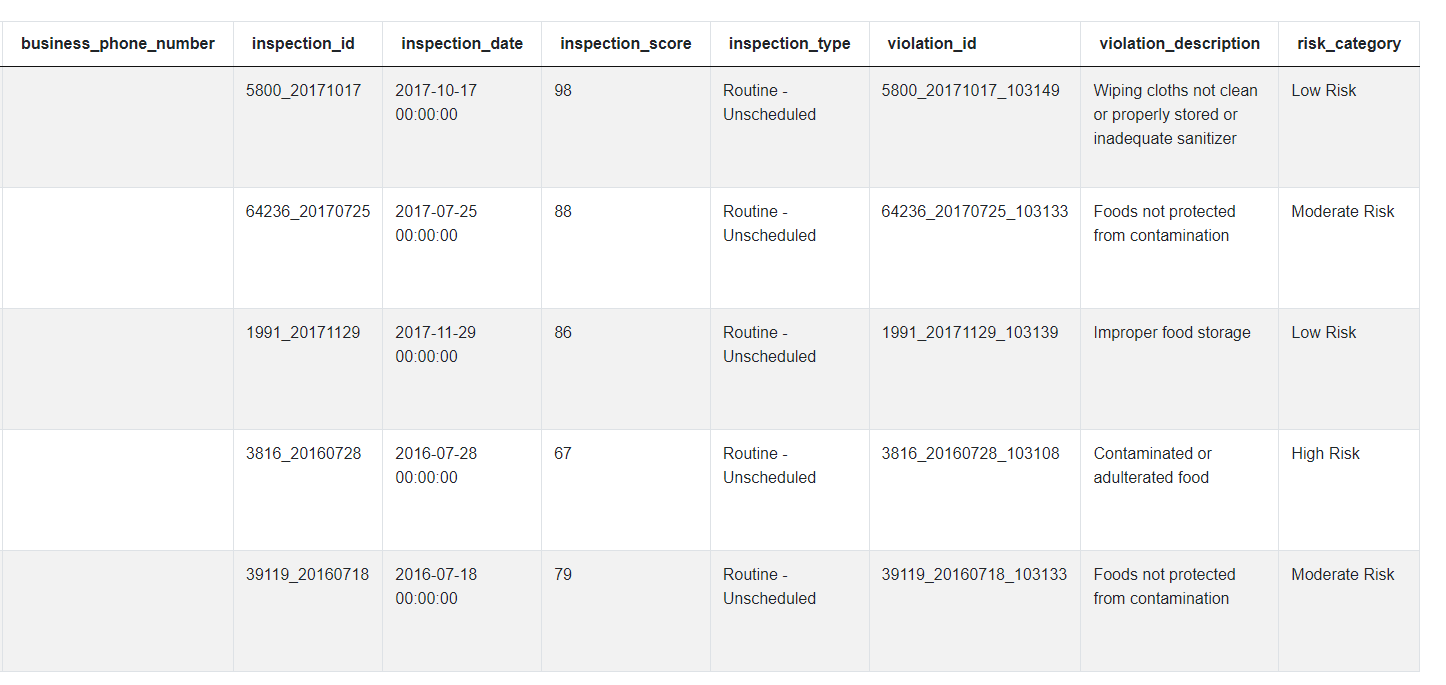
Luckily, we won’t actually need to worry about all of these columns to solve the problem. It’s a good practice to come back to the question and think which columns may be useful. We need to find the number of inspections so we’ll need to count the ‘inspection_id’ column. Then the ‘where a risk category value is assigned’ suggests that we’ll need to filter the data using the ‘risk_category’ column. Finally, ‘Output the result along with the street name.’ tells us to focus on the column ‘business_address’ where the street name should be included.
Formulate your Approach
After getting familiar with the data, it’s important to come up with a few general steps that we will follow when crafting the solution for this interview question. In our case, we can follow these steps:
- Write a method for extracting a street name from the strings in the ‘business_address’ column. We need to assume that the address starts either with the street name, in which case we need to extract the first word from the string, or with a number that may be followed by a letter, in which case we should extract either the second or third word of the string.
- Having this method, we can use it to add a new column to our data set - the street name
- In the third step, we will filter the data to leave only these rows where the risk category is assigned, in other words only the records for which the ‘risk_category’ column is not empty
- Next, we can make the formatting of the street names consistent by making them start with a lowercase letter in all cases. This step ensures that each street name will only appear once in the final output.
- The final step is to prepare the final output as instructed in the interview question:
- We’ll only have two columns: a street name and the number of inspections. We’ll therefore need to group the results by street name in such a way that we count the number of times each street name appears in the data set.
- The last thing to do will be to order these results so that street names with most inspections are in the top and with the least inspections in the bottom.
Code Execution
Having formulated the approach, we can now actually write the code that will produce the expected output. We will use the Python programming language and so we can assume that the data is stored as a Pandas dataframe called ‘sf_restaurant_health_violations’. Pandas is the popular Python library for querying and manipulating data sets. We can start by importing it so that we can use it later.
import pandas as pd
Now let’s follow the approach that we have formulated before. The first step is the method for extracting the street name from the address, so we can start by writing this method. For now, we don’t care about the data set or any specific addresses, we’ll just write a Python function that, given some address x, will return the street name. We can start by typing:
def street(x):
We want to extract the street name from x where x is a string containing the address. We can start by checking if the first character of the first part of the string is a digit or a letter. If the first part starts with a letter, we can assume that it’s a street name and return this first word. We can use the split() function that, when applied to a string, will divide the string into pieces based on the separator character that we can select.
if str(x.split(' ')[0][0]).isdigit() == True:
# first part is a number
else:
return x.split(' ')[0]
Let’s examine this code. We use x.split(' ') to divide our address string into pieces with the space bar being a separator. So if x is, for example, ‘295 B Orizaba Ave’, then using x.split(' ') will turn it into a list where the first element is 295, the second is B, the third one is Orizaba and the fourth is Ave. We’re interested only in the first part of the string for now, so we wrote x.split(' ')[0] which corresponds to the first element in the list, everything that is in the string before the first spacebar. Remember that in Python the first element has index 0. In our example, it’d just be a number 295. However, we’re not only interested in the first part, but specifically in the first character of the first part, that’s why we add another [0] to achieve x.split(' ')[0][0]. We can now use a function .isdigit(), which, when applied to a character, returns a Boolean value True if the character is a digit and a value False otherwise. However, we need to be careful because .isdigit() can only be applied to a character data type. But if our first character is indeed a digit, we risk that Python will automatically convert it to a numerical data type, for example integer. In this case, the .isdigit() would result in an error because it can’t be applied to an integer. To avoid it, we can ensure that the character is considered as a string and not a number by casting it as a string. That’s why we have the str() function there.
So this piece of code str(x.split(' ')[0][0]).isdigit() returns True if the first character of the string is a digit and False if it’s a letter. If the latter is the case, so when the first character in the address is a letter, then we can assume that the first word is indeed a street name and return it using return x.split(' ')[0] - in this way we output everything that’s before the first spacebar in the address string.
In the other case, when the first character is a digit, we know that the first part of an address is a house number and not a street name. We’ll ignore it and return either the second or third word. Which one? It depends if the second word has only one letter or more. If it’s longer than one letter, then we can assume it’s a street name and return this second word. Otherwise, if it only has one letter, then it’s a part of the number and we’ll need to return the third word.
if len(x.split(' ')[1]) > 1:
return x.split(' ')[1]
else:
return x.split(' ')[2]
In this code, we use the len() function which returns the length of an object, in this case a number of characters in a string. We also apply it only to the second part of the address string (which in Python has index 1), so we count the characters between the first and second space bar. If the length is larger than 1, then we can return this second word as the street name. Otherwise, we return the third word, so the one with index 2. Now, the entire function for extracting street name from the address string x looks as follows:
def street(x):
if str(x.split(' ')[0][0]).isdigit() == True:
if len(x.split(' ')[1]) > 1:
return x.split(' ')[1]
else:
return x.split(' ')[2]
else:
return x.split(' ')[0]
We can verify that the function works by using a few examples. If the address is ‘295 B Orizaba Ave’, then the first if statement returns true because the first character is a digit, the second if statement returns false because B does not have more than 1 character, and so we return the third part, Orizaba, which indeed is the street name. If the address is ‘700 Sutter St’, then the first if statement returns true again because the first character is a digit. But now also the second if statement returns true because Sutter has more than 1 letter and so we return Sutter as the street name. Finally, if we only input ‘Broadway St’ as the address, then the first if statement returns false because the first character is not a digit and so we return the first word, in this case ‘Broadway’ right away.
Now, we can apply this method that we have just written to our data frame:
sf_restaurant_health_violations['street_name'] =
sf_restaurant_health_violations['business_address'].apply(street)
This code will create a new column ‘street_name’ such that in every row, the content of ‘street’ column will be equal to the content from ‘business_address’ column after applying the method street() to it. We execute it by using the Pandas .apply() function on the ‘business_address’ column and with the name of our function, so ‘street’ as the parameter.
We have covered the first two steps from our approach. We have the method for extracting the street name from the address and we have added the column to the data frame with the street name extracted from the address. It’s the column ‘street_name’. The next step is to filter the data by only leaving rows with the risk category assigned. We can do it with the following line of code:
assigned_risk = sf_restaurant_health_violations[]
This will create a new data frame ‘assigned_risk’ that will only include some values from the original data frame based on a condition. We will now add the condition inside the squared brackets. The condition is that the risk category needs to be assigned, in other words, the column ‘risk_category’ can’t say ‘null’. Luckly, there is a Pandas function notnull() that does just that. So the condition will look as follows:
sf_restaurant_health_violations['risk_category'].notnull()
Column ‘risk_category’ from data frame ‘sf_restaurant_health_violations’ and it can’t say ‘null’. Then, we can add this condition to the previous code:
assigned_risk =
sf_restaurant_health_violations[sf_restaurant_health_
violations['risk_category'].notnull()]
This construction with repeating the name ‘sf_restaurant_health_violations’ may look weird at first, but it’s a completely normal way to filter in Pandas.
Having filtered the results, the next step is to ensure the consistency in formatting. In particular, we want to ensure that all street names start with a lowercase. For that, we need to update the column ‘street_name’ that we have recently created.
assigned_risk['street_name] = assigned_risk['street_name'].str.lower()
Basically, the function lower() can be applied to a string and forces the first letter to be lowercase. We need to use this construction .str.lower() though to specify that we want to apply the lower() specifically to the strings in the ‘street’ column.
We’re almost there. The final step is to prepare the output according to the instructions in the interview questions. We’ll need to group the results by street name, count the number of occurrences for each street name and then sort the results in descending order. Rather amazingly, using Pandas we can do all of it with just one line of code. Let’s start by creating a new variable ‘result’ and for now, let’s set it equal to our filtered data frame ‘assigned_risk’.
result = assigned_risk
To group the results by street name, we can use the Pandas groupby() function. We need to specify by which column it should group the results, in our case we’ll say ‘street_name’. We then need to tell it in what way to group the results. We want to count the number of rows in which each street name appears, which can be achieved using a Pandas groupby().size() function.
result = assigned_risk.groupby(['street']).size()
The code from above will successfully group the results but it will only return the number of occurrences for each street name - only one column of numbers and no street names. Additionally, ‘result’ has become a Series - another data type from Dataframe that only allows to store a single column of data. We want to convert it back to a Pandas Dataframe and show the names of streets. We can do it by first using a Pandas function to_frame() that converts a Series to a Dataframe. By the way, here we can specify a name for the column with the numbers of violations, let’s say ‘number_of_risky_restaurants’ - it’ll look better than leaving the column without a name. Then, we’ll also use a function reset_index(). Before that Pandas considers street names to be the index and doesn’t show them as a separate column in the data frame. Using this function will change back to a numerical index and will show street names as a column.
result = assigned_risk.groupby(['street']).size().to_frame
('number_of_risky_restaurants').reset_index()
Finally, we want to sort the results. The interview question says to order the results based on the number of inspections in descending order. Additionally, we can add a secondary sorting rule such that when several streets have the same number of inspections, they will be sorted in the alphabetic order. We can achieve this result by using a function sort_values().
result = assigned_risk.groupby(['street']).size().to_frame
('number_of_risky_restaurants').reset_index().sort_values
(['number_of_risky_restaurants', 'street'])
However, there’s one problem with this output. By default, the function sort_values() orders everything in the ascending order. This means that it sorts numbers from smallest to largest and text in the alphabetic order. We need it a bit different, the question specifically asks to order numbers in the descending order or from largest to smallest. But then for the secondary sorting, based on street name, we still want the alphabetic order. To code this, we just need to add a Boolean parameter ‘ascending’ to the sort_values() function and set it to False for the primary rule and to True for the secondary rule.
result = assigned_risk.groupby(['street']).size().to_frame
('number_of_risky_restaurants').reset_index().sort_values
(['number_of_risky_restaurants', 'street'], ascending=[False, True])
This very long, single line is enough to produce the required output. Here’s the entire code solving this Python data science interview question:
import pandas as pd
def street(x):
if str(x.split(' ')[0][0]).isdigit() == True:
if len(x.split(' ')[1]) > 1:
return x.split(' ')[1]
else:
return x.split(' ')[2]
else:
return x.split(' ')[0]
sf_restaurant_health_violations['street'] = sf_restaurant_health_violations['business_address'].apply(street)
assigned_risk = sf_restaurant_health_violations[sf_restaurant_health_violations['risk_category'].notnull()]
assigned_risk['street'] = assigned_risk['street'].str.lower()
result = assigned_risk.groupby(['street']).size().to_frame('number_of_risky_restaurants').reset_index().sort_values(['number_of_risky_restaurants', 'street'], ascending=[False, True])
Check out more Python interview questions here that are being asked in Data Science Interviews at top companies like Amazon, Google, Microsoft, etc.
Conclusion
This is it, we have successfully written the solution for this interview question ‘Health Inspections Per Street’ from the City of San Francisco. The use of the Python programming language allowed us to write the entire solution in just a few lines of code but probably the most difficult part was coming up with the general approach. In particular, it was crucial to think of all the possible variations of how the address string can look like. This is frequently a case when extracting information from a string, especially from an address, that we first need to carefully examine the data and try to catch as many edge cases as possible, then also figure out how to cover all of them in our code.
However, remember that in an interview, we’re usually not given the exact data, only the column names, data types and maybe a few examples like in this case. That’s why, to solve the question, we need to rely on some assumptions and while it’s completely fine to assume things, it’s absolutely crucial to communicate clearly with the interviewer and make them aware whenever you make any assumptions. Communication with the interviewer is also a key when writing the code, it’s a good practice to explain the steps while you code them and to talk about the most important functions that you’re using - in this way you’re not only showing the interviewer that you can solve the task, but also and more importantly that you master the programming language in general.
And lastly, don’t forget to stick to the framework for solving any data science problems, it will make your interviews and your life much easier. Once again, you start by examining and understanding the data, you then formulate your approach - the few general steps required to solve the problem. Finally and based on these two, you can write your code step by step.
Also, check out our post on Python Data Science Interview Questions to find questions that are targeted towards beginners or someone who is looking for more challenging tasks.
Share


