A Resource Guide to Jump-Start Your Own Data Science Projects

 Written by:
Written by:Abhishek Ramesh
A very into-detail guide on the data science project components and the resources for jump starting your very own project.
This is a resource guide to start your data science projects. This guide will go over what are the various components to successful data science projects and websites and online datasets to help jump start your project!
First off, you need to understand what and why specific components are required in a full stack data science project (such as time-series analysis and APIs). We have created a detailed breakdown and what interviewers look for in this article → “Data Analytics Project Ideas That Will Get You The Job” and the video below:
Components of Data Science project:
- Promising dataset
- Real data
- Timestamps
- Qualitative data
- Quantitative data
- Modern Technologies
- APIs
- Cloud Databases (Relational + Non-Relational data)
- AWS → S3 buckets
- Building model
- Metrics
- Modifying dataset
- Diagnostics tests
- Transformation
- Test/Control
- Model Selection
- Optimizing
- Math
- Making impact/validation
Promising Dataset
Real Data
Any great data science project uses constantly updated data.
There are 2 important reasons for using updating real data.
1) The dataset is never truly complete
A real world dataset needs manipulation of values to derive a new metric or needs to be filtered. Data wrangling is one of the most important parts of data science, since a model is only as good as the dataset it analyzes.
2) The dataset is updated in real time
Most companies use datasets that are updated frequently. These types of datasets are important especially for businesses that need to take a specific action if a certain metric falls below a certain threshold. For example, if the supply of an ice cream company falls below the predicted demand, the company needs to make a plan on how to match the supply and demand curve. Using real time datasets is a great way to show recruiters, you have experience with variable datasets.
Timestamp
Datetime values are as the word states values that include date or time. These values are commonly found in datasets that are constantly updated, since most of the records will include a timestamp. Even if the record doesn’t have a timestamp, it’s useful for analysis to have a datetime column. Commonly companies want to see the distribution across the year (or possibly decades), so finding datasets with datetime and finding the distribution of a specific metric over a year is important.
Qualitative / Quantitative
Qualitative and quantitative data represents non-numerical and numerical values accordingly.
Examples:
- Qualitative → Gender, types of jobs, color of house
- Quantitative → Conversion rate, sales, employees laid off
Both types of data provide their own importance.
Quantitative data is one of the fundamentals of regression models. You are using numbers and variables to predict a numeric value.
Qualitative data can help with classification of models such as through decision trees. Qualitative data can also be converted into quantitative data, such as converting safety levels [none, low, medium, high] to [0, 1, 2, 3], which is called ordinal encoding.
Geo-locations, such as countries or longitude/latitude, are nice to have in datasets. Similarly to datetime values, with geo-locations, you could find the distribution of metrics across various states/countries. Especially when working with multinational corporations, they have datasets from various countries that need to be analyzed.
Resources
Now you have a better understanding of what to search for in your potential dataset, here are some websites to search for datasets.
- Google Dataset Search
- Registry Of Research Data Repositories
- U.S. Government Open Data
- Open Government Data Platform India
These links contain datasets in csv format, but also have access to APIs. APIs are important to have in your repertoire, since data especially when working for companies is usually obtained through APIs.
Another place to retrieve datasets beyond these websites are from famous tech companies that are consumer based, such as Twitter, Facebook, and YouTube. These companies provide APIs for developers through their websites directly. This is an easy area to find intriguing ideas for your projects!
Modern Technologies

Modern technologies are key factors on what differentiates a good and great data science project. Modern technologies refers to commonly used softwares and services used by companies. APIs and cloud databases are examples of modern technologies.
API
APIs are one of the most important modern technologies to use when creating a data science project. APIs (Application programming interface) is what makes your application work. Imagine you are booking an Uber ride. Through your phone, you will first input your pickup and dropoff location. Uber will give you an approximate cost. How does the Uber application calculate this cost, it uses APIs. An API is an interface between 2 software.
Example: The Uber app requires an input of pickup and dropoff locations. A separate software, which can be hosted on the web, will calculate the cost based on distance between locations, approximate time taken, surge pricing (when there is high demand for rides), and much more. The calling and communication between these 2 softwares is an API.
1.) Understanding APIs and how to setup in code
Knowledge of APIs is essential for a great data scientist. While you can watch the short videos about what is an API, you definitely need a better understanding of where APIs are used and the different types. Building your own API is a great way to get a better understanding and how to test APIs.
Resources
2. Libraries for APIs (Request/Flask in Python)
To request data from APIs or even create your own API there are specific libraries to use.
Resources
- To learn more about Requests in APIs → Creating project with API Working with APIs in Python [For Your Data Science Project]
- To learn more about building a REST API with Flask Python REST API Tutorial - Building a Flask REST API
3. Understand json objects
Plenty of APIs use JSON objects as an input and output, so it is crucial to understand what json objects are.
Resources
- Using json library in Python - Python Tutorial: Working with JSON Data using the json Module
Cloud Database
Recruiters want data scientists with experience with cloud databases, since databases are hosted in clouds more often these days.
Before going into the 3 major cloud platforms, you want to plan your structure of input and output data. There are 2 different types of databases: relational and nonrelational data.
- Relational databases store data with primary keys to identify the specific data. This type of table is generally seen in table structure.
- Non-Relational databases store data without primary keys, such as graphs.
Common cloud platforms are AWS, Google Cloud, and Microsoft Azure. Each has their own advantages and disadvantages, so BMC gives a detailed analysis between these services.
After personally using these services, I would recommend using AWS especially for a first time project. S3 buckets are extremely common when working with companies. AWS has RDS (Relational database) and DynamoDB (Non-Relational database) along with S3 storage. Using these services is a great way to show you have experience in both cloud storage and S3. AWS has a great variety of free tier services to build your project along with 5gb free of S3 storage.
Resources
Building Models
Let’s discuss what to keep in mind when building a model.
An important part to remember when building a model is why you are using or not using a specific technique in a model. While getting an accurate model is important, during interviews, you want to explain the reasoning behind choosing specific models over others.
Automate your model as much as possible. Assuming your input data has a fixed format, your algorithm should clean, derive new metrics, apply appropriate transformations, and build the model. So even when inputting a dataframe with new data, the algorithm should work and provide the right outputs.
Here are some things to consider when building a model:
Metrics
How do you determine how accurate your model is? What numerical data are used when creating your model? Not all models require a metric, but most use them. Determining what metrics will affect your model and to what extent is imperative to a well thought out model. If your model requires the derivation of a new metric, the what and why that metric was created should be noted.
Modifying dataset
How are you manipulating the values or columns of the input dataset? Remember to clean the dataset. Beyond cleaning the dataset, are there any specific columns you derived that directly affect the output? Also remember to note in your project notes why you made these changes.
Certain columns may contain null values. In those cases you should decide how to deal with the missing value rows. You could impute the average of that column to replace null values or run a regression to predict the values.
There are various ways to clean the dataset ranging from simple removing rows with null values to PCA (Unsupervised ML algorithm to remove correlated values)
Resources
Here are some common techniques to use to optimize your dataset:
- Common Data Cleaning Techniques → 8 Effective Data Cleaning Techniques for Better Data
- Dealing with missing values → 7 Ways to Handle Missing Values in Machine Learning
- Encoding values → Categorical encoding using Label-Encoding and One-Hot-Encoder
- PCA → Principal Component Analysis from Scratch in Python

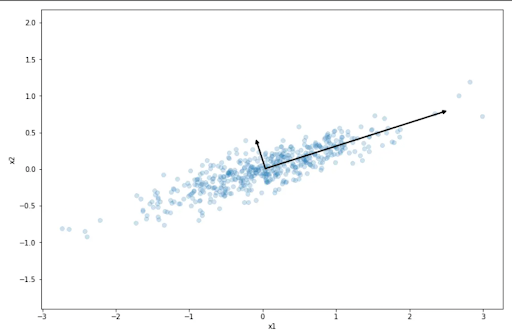
PCA - Overview of Machine Learning Algorithms: Unsupervised Learning
Diagnostic tests
Raw datasets often need to be updated for certain analysis you may run. Suppose you want to check the equal variance in your data, since you want to run a linear regression. To check, you can run a diagnostic test called Homoscedasticity. Depending on the type of model you want to create the dataset needs specific properties.
Resources
Examples of diagnostic tests to run for common problems:
- Outliers
- Box-plot - A simple graph to show the 5 number summary (minimum, first quartile, median, third quartile, maximum) - How To Make Box and Whisker Plots
- Grubbs Test - Test to detect exactly one outlier in the dataset - Grubbs Test (example)
- Homoscedasticity / Heteroskedasticity
- Homoscedasticity - Test to check if variance of the dependent variable is the same throughout the dataset - Bartlett's test
- Heteroskedasticity - Test to check if variance of the dependent variable is NOT the same throughout the dataset - Breusch Pagan test
Transformation
If any diagnostic tests prove transformations are required, run the relevant transformation.
Resources
Common transformations:
- Box-Cox transformation - Transforming a non-normal distribution closer to a normal distribution
- Log transformation - Transforming a skewed distribution closer to a normal distribution
Test/Control
Some models require test/control versions. A common test/control test conducted is A/B testing. Did you implement test/control? What and why did you use the specific difference between test and control versions? What were your results?
Resources
Model Selection
What are your assumptions about this model? What properties does the dataset and model have? Why was this model the best fit for answering your question you are trying to answer?
Resources
- Common Regression Models:
- Ridge - This uses L1 regularization which means ineffective variables’s coefficient can be reduced CLOSE to 0 - Regularization Part 1: Ridge (L2) Regression
- Lasso - This uses L1 regularization which means ineffective variables’s coefficient can be reduced to 0 - Regularization Part 2: Lasso (L1) Regression
- Logistic Regression - This model processes the probability of a given input and returns a binary output- StatQuest: Logistic Regression
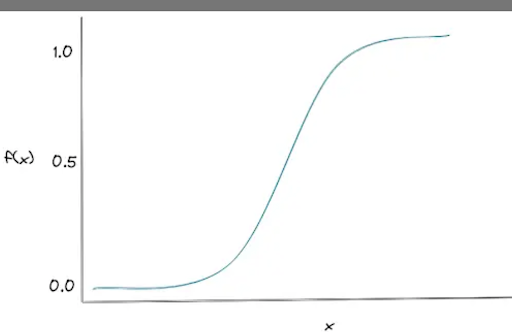
- Logistic regression part - Overview of Machine Learning Algorithms: Classification
- Classification
1. Decision trees - Decision trees are made of decision nodes which further lead to either another decision node or a leaf node - StatQuest: Decision Trees
2.

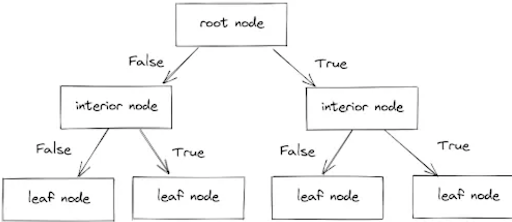
- Decision trees - Overview of Machine Learning Algorithms: Classification
3. Naive bayes - A type of classification algorithm that uses bayes theorem - Naive Bayes, Clearly Explained!!!
- Neural Networks
- CNN model - A neural network model that is used for images recognition - Convolutional Neural Networks (CNNs) explained
- RNN model - A neural network model that is used for sequential data Illustrated Guide to Recurrent Neural Networks: Understanding the Intuition
Optimizing
Your first iteration of your model should not be your final. You must recheck your code and find out how to optimize your code! (Hopefully you made proper comments and well named variables so you don’t forget what a certain function does)
When optimizing your code, you want to determine what is considered a more optimized model? Most commonly with a data science project, a more optimized model is a more accurate model.
Error predictions calculate the difference between the original data and predicted data. Calculating the difference can be done in a couple of ways, such as Mean Squared Error and R². Mean Squared Error is the average of the squares of the errors, where error is the difference between original data and predicted data.
Mean Square Error Formula:
Resources
Common error predictions
- Root Mean Square Error (RMSE) Tutorial + MAE + MSE + MAPE+ MPE
- Adjusted R squared vs. R Squared For Beginners
Math
When creating a statistical model, you definitely need to understand the math. What are the mathematical assumptions of the model? If you have a final equation or specific epochs or other values, include that in your notes.
If you want to create a scientific document for your model, you can use LaTeX documentation. This is specifically made for scientific documents and mathematical formulas. You can use an online LaTeX editor to create the projects.
Making an impact / validation
Now you have finally created your model and project! The final step is to get peer review on your project!
There are multiple ways to get the validation on your project, such as creating a report of your findings or sharing the visualizations.
Creating an article/report
- There are various opinions on how to write a report. No matter how you format your paper, remember to include evidence and logical reasoning behind your analysis. If there are other research papers or models built related to your question, explain the differences and similarities
- Examples of great research papers
Now it is time to share your analysis to the world. The first important place to upload your analysis is to GitHub.
GitHub should be used to upload:
- Code – Make sure it is effectively commented and precise variable names
- Your report
- ReadMe file – For other users to understand how to replicate your analysis
Another social media platform to take advantage of is Reddit. Reddit has plenty of subreddits where you can share your projects.
- r/learnmachinelearning → For simpler project that might tend to be your first few data science projects
- r/machinelearning → For your detailed research papers
- r/dataisbeauitful → This is the go to place to share visualizations with a large community to share visualizations
Towards Data Science (derived from Medium) is the go to place to upload your data science articles. These articles need to be an analysis of your project, why you used specific models over others, your findings, and more.
Some great project analysis
- Future of San Francisco City job market
- Coding an Intelligent Battleship Agent
- Analyzing your Friends’ iMessage Wordle Stats Using Python
- I’ve Tracked My Mood for Over 1000 Days: A Data Analysis
LinkedIn is a great tool to share your projects to people outside of data science. Data science teams in companies have to communicate with coworkers in other departments constantly. Sharing your projects to people beyond your peers gives a great insight in how effectively you can communicate your technical project to a non-technical audience.
Twitter is an important platform to learn about various topics, especially academic research. If you want to be active in the data science community, especially with new technologies or if you are going to publish your own projects, you should join Twitter. Twitter is a great way to share your projects to the academic community and follow reputable people from the field.
Great Twitter pages in ML/AI/DS to follow
Conclusion
Now you have the path for a great data science project!
Try to implement as many of these components as you can. Although, if you include components that are illogical for your project, that is a black mark especially if an interviewer figures this out.
Always try to find how you can improve your model or follow up on your project! For example, if you are creating a prediction model see how accurate your model still is 6 months after you published your model!
TIP: A question you should constantly ask yourself when building your project is why am I using this specific method. For example, if you are building a regression model but choose to use Lasso over Ridge, a reason could be due to wanting to remove certain variables. Again ask yourself, why do I want to remove variables? Maybe certain variables increase the MSPE value. Like this, constantly ask questions throughout your project so you have a more accurate model since you have thought through the various different approaches.
If you’re a beginner and still want more ideas and tutorials to start with, check out our post “19 Data Science Project Ideas for Beginners”.
Share


