Zillow Data Scientist Interview Question Walkthrough


Categories:
 Written by:
Written by:Nathan Rosidi
We’ll closely examine one of the interesting Zillow data scientist interview questions and find a simple and flexible approach for solving this question.
This Zillow data scientist interview question can be solved in several ways, but we’ll cover one of the most simple and flexible solutions. Keep reading to discover an approach which can handle a variety of different datasets without accidentally leaving out important records!
As the most-visited real estate website in the United States, Zillow and its affiliates offer customers an on-demand experience for buying, selling, renting and financing with transparency and nearly seamless end-to-end service. Zillow Offers buys and sells homes directly in dozens of markets across the country, allowing sellers control over their timeline. Zillow Home Loans, our affiliate lender, provides our customers with an easy option to get pre-approved and secure financing for their next home purchase. Zillow recently launched Zillow Homes, Inc., a licensed brokerage entity, to streamline Zillow Offers transactions.
Data Scientist Position at Zillow
Data Scientist Positions at Zillow typically work for the Data Science & Analytics team. As a member of the Analytics team at Zillow, you will partner closely with stakeholders to model, analyze, and visualize business relevant metrics which inform both short and long term decision-making. This role will be responsible for advancing Zillow’s reporting practice to develop source-of-truth datasets and maintaining their Looker instance.

This team collaborates with Data Engineering to turn data into information – and information into insight. It works with datasets as small as an Excel spreadsheet and as large as raw clickstream data. It’s responsible for production reporting, analysis, causal inference, and forecasting. This team works closely with Product Managers, Marketing, and Engineering to deliver critical information and insights that drive decision making.
For additional information on the Data Science team at Zillow, here’s an official article from a few years back highlighting their tools, technology, and data. Beyond this, StrataScratch offers several other articles like this one and this one providing more context about data science roles.
Concepts Tested in Zillow Data Scientist Interview Questions
The main SQL concepts tested in the Zillow data scientist interview questions include
- Use of avg() function to aggregate records
- When to use WHERE() versus HAVING() for filtering data
- Using subqueries to compare computational results
Zillow Data Scientist Interview Question
Cities With The Most Expensive Homes
The question we are going to examine in detail in this article has been asked during an interview at Zillow. It’s titled “Cities With The Most Expensive Homes”, and the key challenge is finding the national average and city averages for home prices then comparing the two to filter for the most expensive cities.


Link to Problem: https://platform.stratascratch.com/coding/10315-cities-with-the-most-expensive-homes
Ultimately, we’re being asked to find the cities with higher average home prices than the national average all while using one table of data.
This Zillow data scientist interview question may seem like a short and simple question, but, as we will see, the answer requires thinking thoroughly about which function to use for data comparison. While there exists multiple ways to solve this question, we’re going to look at one of the simplest, most flexible solutions.
Framework to Solve the Problem
To make the process of solving this interview question easier, we will follow a framework we could use for any data science problem. It consists of three steps and creates a logical pipeline for approaching problems concerning writing code for manipulating data. Here are the three steps:
- Understand your data:
- Take a look at the columns and make an assumption about them. Take note which columns will be relevant for your calculations and which you can discard.
- If you don’t have a complete understanding of the schema, take a look at the first couple of rows of data and explain how the values stem from the column. Ask for example values if none are present. Understanding what values might look like for columns will help you figure out if you can limit your solution to specific columns or if you must broaden it for edge cases.
- Formulate your approach:
- Now, begin writing down the logical steps that you have to program/code. Don’t worry if it seems out of order at first. Code can be changed, so you might perform a calculation in advance and set it aside for later or place it elsewhere to write a separate part of the solution.
- You also have to identify the main functions that you have to implement to perform the logic. Envision the operation a function might have in advance to avoid miscalculations.
- Don't forget that interviewers will be watching you. They can intervene whenever needed, so make sure that you ask them to clarify any ambiguity. Your interviewers will also specify if you can use some ready-made functions or if you should write the code from scratch.
- Code Execution:
- Build up your code in such a way that it doesn't look oversimplified or overcomplicated either. Remember you can always set part of the solution aside for later use if you need to work through a separate step of the problem.
- Build it in steps based on the outline shared with the interviewer. It doesn’t have to be the most efficient solution, but it will help to present a generic solution which covers a variety of data.
- Here's the most important point. Think carefully about how your functions operate. This will let you achieve a simpler solution with fewer logical statements and rules cluttering the code.
- Don't be quiet while laying down your code. Talk about your code as the interviewer will evaluate your problem-solving skills.
Understand Your Data
Let’s start by examining the data. At most company interviews, you won’t have access to the data and won’t have the ability to execute code. Instead, you’ll be responsible for understanding the data and making assumptions solely based on the table schema and by communicating with the interviewer.
In the case of this Zillow data scientist interview question, there is only one table with five columns of data representing an id, state, city, street address, and market price. Each row corresponds to a single home.
zillow_transactions
| id | int |
| state | varchar |
| city | varchar |
| street_address | varchar |
| mkt_price | int |

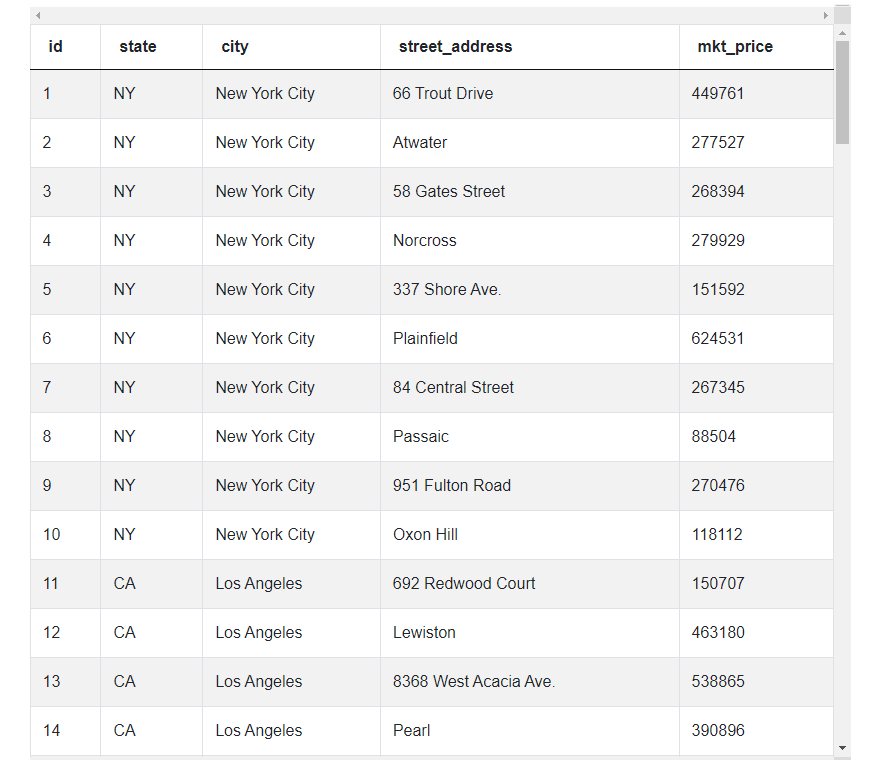
What’s important to realize is to solve this Zillow data scientist interview question, we don’t need all the columns of data. Reviewing the data shows us we can discard the id, street_address, and state columns for our calculations. As a result, our solution will only rely on market prices and cities. We also know we’ll have to use these two columns to calculate a national average and compare a city average to this value all within the same block of code.
Solution:
Formulate Approach
The next step, according to the general framework for solving data science questions, is to outline a few general steps we’ll need to perform to answer this question. These are very high-level but writing them down, in the beginning, will make the writing process much easier for us.
Here are the general steps to follow:
- Start with a query to get the national average market price using the avg() function.
- Put your initial query for the national average market price to the side while querying for the average market price for each city. This will require us to again use the avg() function and GROUP BY city since there are multiple records for each city.
- Move your average market price by city calculation and your original national average query (in the form of a subquery) into a HAVING() function to filter for only the cities where the average market price is higher than the national average.
Find the National Average Market Price
To write the SQL code for this question, let’s follow the general steps that we’ve just defined and translate them into code. The key part of this approach is we leverage a subquery for national average and the HAVING() function to perform a proper price comparison. You can think about it as first obtaining the national average, then obtaining a city average, then comparing the two averages to only list cities with a higher average price.
Looking at the first step, we can start by writing the code for obtaining the national average. This is a relatively simple query which takes advantage of the avg() function, so we can start like this:
SELECT avg(mkt_price)
FROM zillow_transactions

This code produces a single table with a single record corresponding to the national average. One thing to note is we can’t continue to manipulate this table to reach our solution. We’ll need this data for later, so the next step involves putting this query to the side (either cutting and pasting it or commenting it out)
Find the Average Market Price for Each City
Since we need to know the average market price by city, the next step involves using the avg() function again on the market_price column. Since each city has multiple records, we’ll GROUP BY city to get an average by city:
SELECT city, avg(mkt_price)
FROM zillow_transactions
GROUP BY city
--SELECT avg(mkt_price)
--FROM zillow_transactions
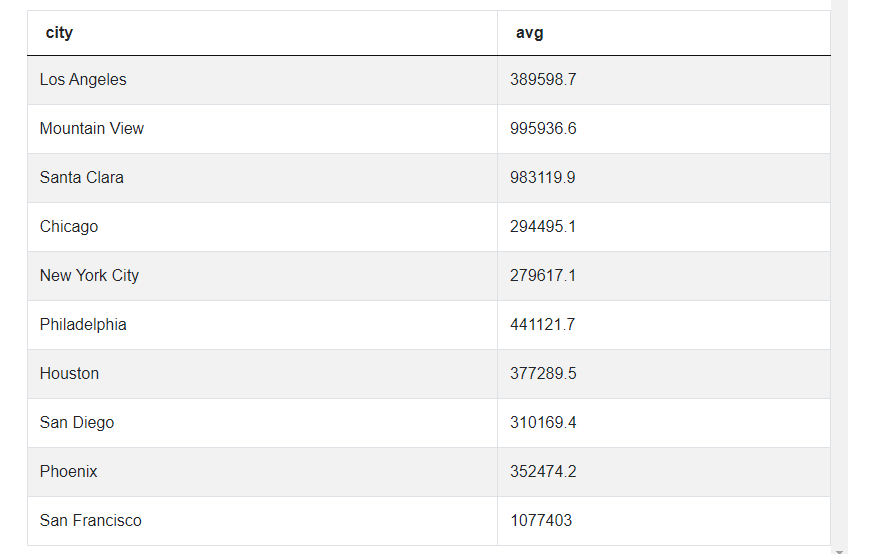
As you can see, we now have an average by city. What we need now is to compare these averages to our original national average and only present cities which have a higher price.
Filter for Cities Where the Market Price is Greater Than the National Average
Here’s where this Zillow data scientist interview question becomes tricky: your first impression might be to use WHERE to filter. This issue here is WHERE applies before the calculation of the city averages, so it’s going to remove relevant data and present the wrong results. Instead, we’ll use HAVING() as our filtering function for the average comparison, so we aren’t discarding relevant pricing data.
For the third step, we’ll compare the city average price calculation to a subquery featuring our original national average calculation inside the HAVING() function to filter for the correct cities:
SELECT city
FROM zillow_transactions
GROUP BY city
HAVING(avg(mkt_price) > (SELECT avg(mkt_price) FROM zillow_transactions))
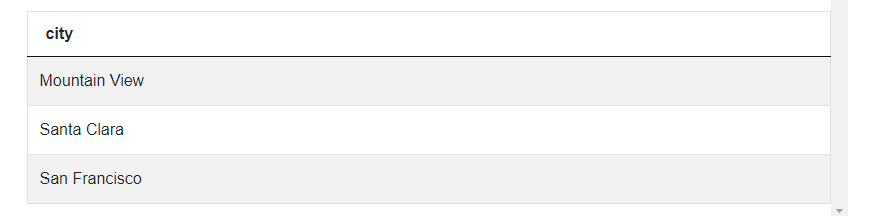
Originally we were asked to present only the cities, and here we get only one column with cities having higher average home prices than the national average. While you could have used an ORDER BY to rank the home prices, it wouldn’t contribute at all towards reaching the correct answer in this solution.
Now, we have the entire solution, and, although it’s simple, it’s also flexible enough to accommodate any additional price data appended to the dataset.
Conclusion
In this article, we have discovered a simple and flexible way for solving one of the Zillow Data Scientist Interview questions. Remember the method mentioned here is not the only possibility, and there exists countless other ways, be they more or less efficient, for answering this interview question!
On StrataScratch, you can practice answering more data science interview questions by constructing solutions to them but always try to think of other ways to solve them, you may come up with a more efficient or elaborate approach. Make sure to post all your ideas to benefit from the feedback of other users, and you can also browse all their solutions for inspiration!
Share


