What Does a Data Engineer Do (And What They Don’t Do)?


What does a data engineer do? How does this role differ from data scientists? What’s the salary and how to get a job? The answers await you in the article.
We imagined this article as a general overview of a data engineering role. To give you that, we’ll explain who a data engineer is and what a data engineer does and what skills you need to become one. We’ll show you what your day-to-day work encompasses and how much you could be paid.
Sometimes, understanding what something is, is best done by understanding what it isn’t. Comparing data engineers to data scientists might do the trick.
In the end, we’ll tie everything together by showing you several typical questions you might get at the job interview.
What is a Data Engineer?
A data engineer is a job in the family of data science jobs. For a quick overview of the different data science roles and what they are, go to our What Does a Data Scientist Do article.
In short, data engineers are data professionals who prepare data for other people to use. We like to consider them part of the data-provider type of data science job.
How do they provide data to others?
What Does a Data Engineer Do?
When making data available for other users, data engineers:
- Build a pipeline
- Maintain a pipeline
- Wrangle data
A data pipeline is what it sounds like – a pipeline for moving data from one place to another.

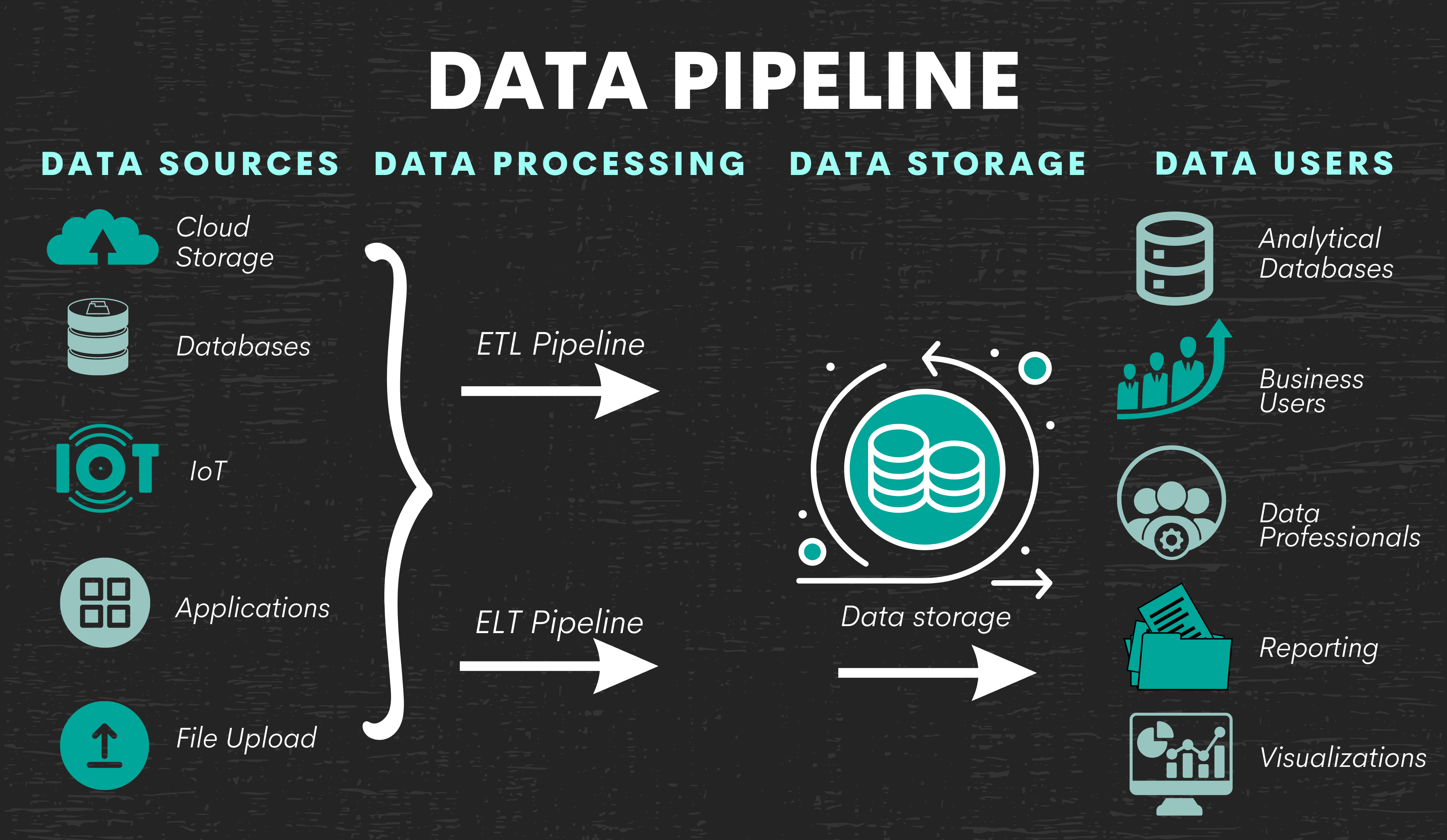
The three main building blocks of a data pipeline are:
- Data sources
- Data processing (ETL/ELT)
- Data storage
Data sources are where the data is coming from. It can be anything, from databases, cloud storage, Internet of things to applications and file upload.
Data processing is what happens when raw data is extracted from its sources, transformed, and loaded into data storage.
That’s why this is called ETL or Extract, Transform, Load. After it’s pulled from the sources, the data is made usable by organizing, cleaning, changing, and validating it. In short, data is wrangled. Once this step is finished, the data is stored.
There’s also a similar process called ELT, which stands for Extract, Load, Transform. After extracting data, it’s saved into data storage, and only after that, the data transformation is performed.
Data storage is where the data is saved after it’s been processed. Usually, it’s a data warehouse or data lake. From there, data is made available to business users and other data professionals.
Types of Data Engineering Jobs
What a data engineer will focus on depends on the company size. No matter what, it will for sure revolve around data wrangling, building, and maintaining pipelines.
Based on that, there are three distinct types of data engineering jobs:
- general practitioner
- pipeline specialist
- database specialist
The general practitioner data engineer works in a small company where they or their team are responsible for everything concerning data. Their work involves handling data sources, building and maintaining data pipelines and storage, and analyzing data. In this situation, they are several data professionals in one person.
The pipeline specialist works in a midsize company. Their concern is data pipelines. It means they ensure data availability to other data users by overlooking and tuning data pipelines and integration tools, ensuring data flow between data sources and data storage. They are usually part of a data science team, working with them to ensure data fits their project’s needs.
Database specialists are traditionally to be found in larger companies. They are responsible for analytics databases, and that involves setting them up, loading them with data, and maintaining them. It’s because, in large companies, a large number of analytics databases with different requirements make this type of data engineer required.
What Skills Does a Data Engineer Need?
Building data pipelines, maintaining them, and wrangling data require data engineers to have the skills of a:
- software engineer
- DevOps engineer
- data analyst
Here’s a more specific list of these skills.
Data Engineer vs. Data Scientist
Data engineer is not a data scientist, which is like defining a dog by saying it’s not a cat – telling the truth and saying nothing.
In the binary categorization of data providers and data users, the data scientist is a data user. They are focused on building ML models, while the data engineers deal with raw data and data architecture.Their education is somewhat similar. The skills and tools they use overlap to a certain degree, too.
Data engineering is a tad bit heavier on the programming side. Also, data engineers don’t use ML platforms, while data scientists don’t work with ETL/ELT tools. The exception can be small companies that sometimes expect one employee to be both a data engineer and a data scientist.
You can find more details about similarities and differences in our Data Engineer vs. Data Scientist article.
Data Engineer Salary
According to the latest information from Glassdoor, the median total salary for data engineers in the US is $111,486 a year.

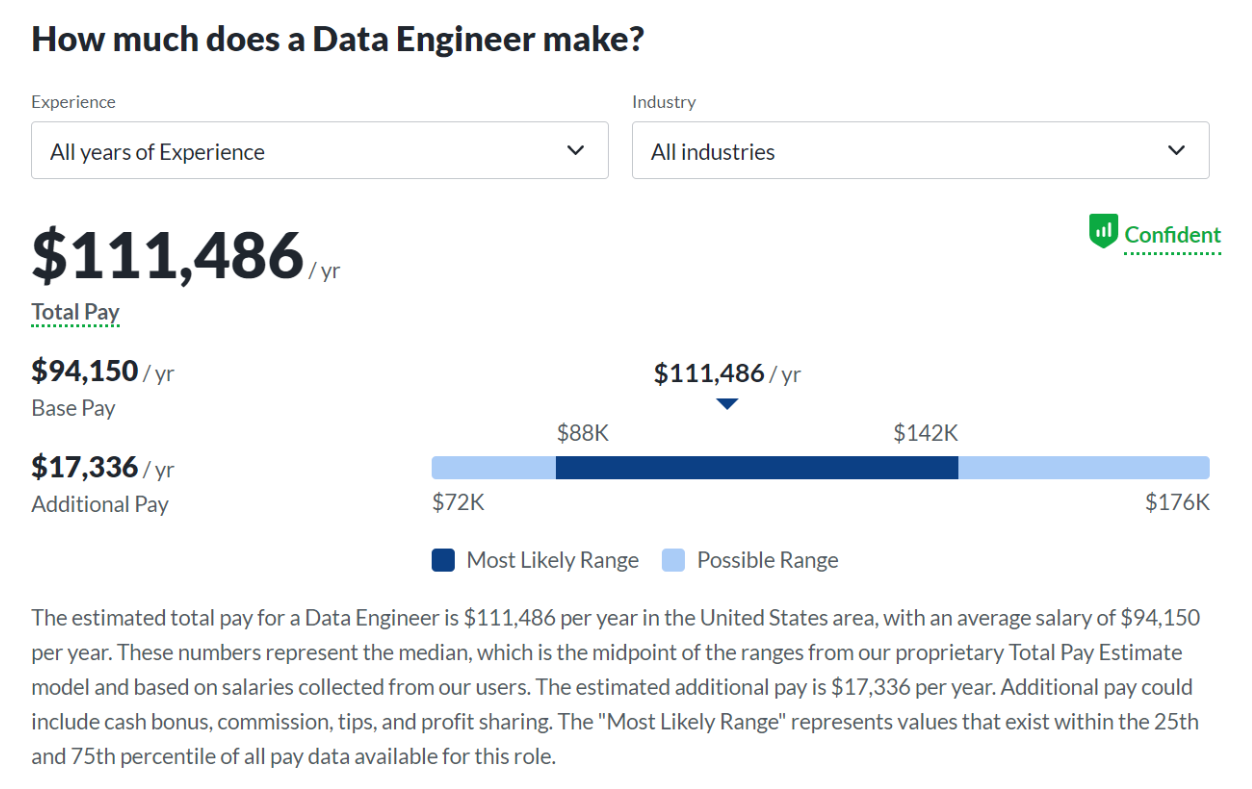
This salary includes the base pay of $94,150 and additional pay of $17,336.
The most likely salary range is between $88k and $142k. This is something we already covered to a great extent in our article “data engineer salary”, so there’s no need to repeat it here.
How to Ace a Data Engineering Interview?
The answer is easy: go to the interview and show you have the required skills.
Easier said than done. There are different approaches, but it always boils down to two aspects of preparation:
- Research the company
- Practice your technical skills
Researching the company involves knowing its history, products, organization, and competitors. Aside from these generalities, you should also get to know their interview process. In other words, how technical it gets, which skills they’re most interested in, how many rounds there’ll be, and with whom. One of the clues to the skills you should focus on lies in the job description. But also, in this article, we outlined in detail what a data engineer does. So you’ve already completed one of the crucial steps simply by reading the article.
Next is to practice your technical skills. It’s much easier once you know what skills the company will test, wouldn’t you say? And it’s even better if the company you’re interviewing is on our interview questions list.
The questions at the interviews are mostly coding questions. They can also be technical questions requiring coding knowledge or other technical skills.
Coding questions
Depending on the job description, you could be asked to solve a number of questions using SQL, Python, or any other programming language popular in data engineering.
Example #1: SQL Coding Question
For example, you could get this easy SQL question at an Amazon interview.
Interview Question Date: May 2022
Write a query to return all Customers (cust_id) who are violating primary key constraints in the Customer Dimension (dim_customer) i.e. those Customers who are present more than once in the Customer Dimension. For example if cust_id 'C123' is present thrice then the query should return 'C123' | '3' as output.
Link to the question: https://platform.stratascratch.com/coding/2107-primary-key-violation
Data
There’s one table at your disposal: dim_customer. Take a look at the data itself.
| cust_id | cust_name | cust_city | cust_dob | cust_pin_code |
|---|---|---|---|---|
| C273 | Stephen V. Cooke | New York | 1996-11-28 | 8235 |
| C274 | Peter P. Mankin | Mount Upton | 1984-06-25 | 6050 |
| C274 | Juan C. Parker | Mertzon | 1989-07-07 | 6867 |
| C274 | Eve E. McClure | Southfield | 1995-05-18 | 7791 |
| C275 | Charles J. Stevens | Oakland | 1975-12-02 | 5930 |
Solution
You could solve the question the following way.
SELECT cust_id,
COUNT(*) AS n_occurences
FROM dim_customer
GROUP BY cust_id
HAVING COUNT(*) > 1;
The query lists IDs and uses the COUNT() function to find the number of their occurrences. The output is grouped by ID and filtered to show only IDs that appear more than once.
Output
| cust_id | n_occurences |
|---|---|
| C276 | 2 |
| C281 | 2 |
| C274 | 3 |
Look for some more questions in our Data Engineer Interview Questions article.
Example #2: Python Coding Question
One of the Python coding question examples is the question by Meta/Facebook.
Interview Question Date: November 2020
Meta/Facebook sends SMS texts when users attempt to 2FA (2-factor authenticate) into the platform to log in. In order to successfully 2FA they must confirm they received the SMS text message. Confirmation texts are only valid on the date they were sent.
Unfortunately, there was an ETL problem with the database where friend requests and invalid confirmation records were inserted into the logs, which are stored in the 'fb_sms_sends' table. These message types should not be in the table.
Fortunately, the 'fb_confirmers' table contains valid confirmation records so you can use this table to identify SMS text messages that were confirmed by the user.
Calculate the percentage of confirmed SMS texts for August 4, 2020. Be aware that there are multiple message types, the ones you're interested in are messages with type equal to 'message'.
Link to the question: https://platform.stratascratch.com/coding/10291-sms-confirmations-from-users
Data
Here, you’ll be working with two tables: fb_sms_sends and fb_confirmers. The data in the table looks like this.
| ds | country | carrier | phone_number | type |
|---|---|---|---|---|
| 2020-08-07 | ES | at&t | 9812768911 | confirmation |
| 2020-08-02 | AD | sprint | 9812768912 | confirmation |
| 2020-08-04 | SA | at&t | 9812768913 | message |
| 2020-08-02 | AU | sprint | 9812768914 | message |
| 2020-08-07 | GW | rogers | 9812768915 | message |
The table fb_confirmers consists of the following data.
| date | phone_number |
|---|---|
| 2020-08-06 | 9812768960 |
| 2020-08-03 | 9812768961 |
| 2020-08-05 | 9812768962 |
| 2020-08-02 | 9812768963 |
| 2020-08-06 | 9812768964 |
Solution
Here’s the code that solves this problem.
import pandas as pd
import numpy as np
df = fb_sms_sends[["ds","type","phone_number"]]
df1 = df[df["type"] == 'message']
df1_grouped = df1.groupby('ds')['phone_number'].count().reset_index(name='count')
df1_grouped_0804 = df1_grouped[df1_grouped['ds']=='08-04-2020']
df2 = fb_confirmers[["date","phone_number"]]
df3 = pd.merge(df1,df2, how ='left',left_on =["phone_number","ds"], right_on = ["phone_number","date"])
df3_grouped = df3.groupby('date')['phone_number'].count().reset_index(name='confirmed_count')
df3_grouped_0804 = df3_grouped[df3_grouped['date']=='08-04-2020']
result = (float(df3_grouped_0804['confirmed_count'])/df1_grouped_0804['count'])*100
The code creates dataframe with three columns from the table fb_sms_sends. It is then filtered to contain only the message type, and the number of sent messages is counted for each date. Later on, the message count for only August 4, 2020, is shown.
After creating the second data frame from the second table, data frames are left joined to get the number of confirmed messages for August 4, 2020.
These two results are divided and multiplied by 100 to get the percentage.
Output
And the percentage of confirmed SMS texts for August 4, 2020, is 20%.
| count |
|---|
| 20 |
Non-coding Questions
While coding is usually the most-tested skill, be prepared for some technical questions, too.
Example #3: Impute Missing Information
One example could be a question by Airbnb asking you to explain how you would impute missing information.


Link to the question: https://platform.stratascratch.com/technical/2158-impute-missing-information
It’s an open-ended question, and how you answer it will show the level of your skills and experience.
Example #4: Data Structures in Python
This question is by Walmart. It asks you to explain data structures in Python, which requires certain knowledge of this programming language.


Link to the question: https://platform.stratascratch.com/technical/2072-data-structures-in-python
Summary
Let this article “what does a data engineer do” serve you as a go-to source for a data engineer’s job, with an emphasis on the job description. We explained what the responsibilities and daily tasks of a data engineer are. Of course, it requires specific skills, and we listed them neatly. Having such skills calls for adequate compensation, which is substantial in the case of data engineers.
How do you get into the position to earn it? We can’t do the work instead of you. But we can give you actual interview questions for practicing coding and other technical skills.
Join our community and ace your coming data engineering interview!
Latest Posts:



Share