Using Python Itertools for Efficient Looping


 Written by:
Written by:Nathan Rosidi
Maximize Your Data Science Workflow with Python Itertools: A Guide to Efficient Looping.
There is no doubt that, in data science, efficient looping is like a magic wand. It can transform tedious tasks into quick and painless processes. Sounds like something straight out of Harry Potter, doesn't it? But in our case, the spellbook is Python's itertools library!
You see, looping is often the bread and butter of data science algorithms. Get it right, and you'll make your computer—and your boss—very happy. It's like cooking: the right ingredients can make or break the dish. But instead of spices and herbs, we're dealing with iterators that can massively improve your code efficiency.
So, what's on the menu today? Well, we'll explore infinite iterators that just keep on giving, finite iterators that know their limits, and combinatoric iterators that love to mix and match. Each of these is a special tool in Python's itertools toolbox, so let’s get started!
Python Itertools for Efficient Looping
Now let’s explore the power of Python's itertools library, which offers a wide range of tools for efficient looping. We'll look divide iterators into three categories: Infinite iterators, Finite iterators, and Combinatoric iterators.

Infinite iterators
Let's start with infinite iterators, the generators that never say "stop." They just keep going and going! In this section, we'll focus on three basic but powerful infinite iterators: count, cycle, and repeat. Each has its own unique utility and can make your data science tasks more efficient. Let's dive in!

count()
The count() function creates an infinite iterator that generates consecutive numbers. In data science, this function can be used for adding indexes or time-stamps to a data set.
Here is the code.
from itertools import count
# Start counting from 1
counter = count(start=1)
# Simulated data points for weight measurements
weight_data = [70, 71, 69, 68, 70]
# Create a dictionary with indexes for each weight
indexed_data = {}
for index, weight in zip(counter, weight_data):
indexed_data[index] = weight
print(indexed_data)
Here is the output.

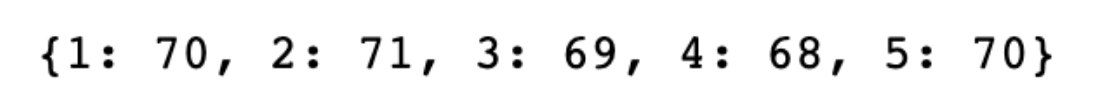
The count() function starts an infinite counter from 1. We pair each value from this counter with a weight measurement from our data set. This attaches a unique index to each weight measurement. The result is a dictionary where each weight is associated with a unique number. This helps in identifying or referring to specific data points for analysis.
cycle()
The cycle() function creates an infinite iterator that loops over an input sequence indefinitely. In data science, this can be useful for tasks that require periodic or cyclical patterns. For instance, let’s say you have weather data for seven days and next week’s temperature will be predicted to be similar to this week's you could use cycle() to repeat the pattern.
Here is the code.
from itertools import cycle, islice
# Create a cycle of days of the week
days_of_week = cycle(['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'])
# Simulated temperature data for 7 days
temperatures = [23, 25, 22, 21, 20, 19, 24]
# Pair each temperature with a day of the week for the next two weeks
next_two_weeks_temp = list(zip(islice(days_of_week, 14), temperatures * 2))
print(next_two_weeks_temp)
Here is the output.


Here, cycle() takes the list of days of the week and keeps repeating it. We use islice() to take 14 values from this infinite loop, which gives us the days for the next two weeks. We then pair each day with temperature data, effectively extending the 7-day temperature data into a 14-day forecast.
repeat()
The repeat() function from Python's itertools library creates an iterator that produces a specified value indefinitely or for a given number of times. In data science, repeat() can be useful when you need to fill or extend data with a constant value. Imagine you're tracking monthly sales data and you want to project the same revenue for the next few months as a placeholder.
from itertools import repeat
# Use repeat to generate the same revenue for the next 3 months
revenue_projection = list(repeat(5000, 3))
# Existing revenue data for past months
past_revenue = [4000, 4200, 4500]
# Combine past revenue and future projections
total_revenue = past_revenue + revenue_projection
print(total_revenue)
Here is the output.

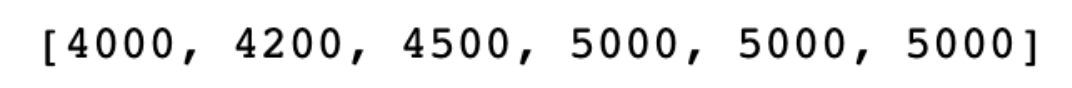
In this example, the repeat() function is set to produce the value 5000 for 3 times. These repeated values are then combined with the existing revenue data to give a full list of total revenue, including projections. The use of repeat() here simplifies the task of filling in or extending a data series with a constant value, making it easier to create placeholders for future analysis.
Finite iterators
Let's shift our focus to finite iterators. These are tools that deal with tasks having a definite endpoint. In this section, we'll explore Chain(), Compress(), and DropWhile(). Each comes with its own set of capabilities, tailor-made for specific situations in data science.

chain()
The chain() function from Python's itertools library creates an iterator that links multiple sequences together. In data science, this can be useful for combining disparate data sets into a single sequence for easier analysis. Suppose you have quarterly sales data stored in different lists, and you want to analyze the sales data for the entire year.
Here is the code.
from itertools import chain
# Quarterly sales data for a year
Q1_sales = [1000, 1100, 1050]
Q2_sales = [1200, 1300, 1250]
Q3_sales = [1100, 1000, 1150]
Q4_sales = [1050, 1100, 1200]
# Use chain to combine all the sales data
annual_sales = list(chain(Q1_sales, Q2_sales, Q3_sales, Q4_sales))
print(annual_sales)
Here is the output.


The chain() function takes in the sales data from each quarter and links them into a single list. This unified list, annual_sales, is easier to analyze than four separate lists. Combining data this way allows for more holistic insights and facilitates various types of analysis, from trend identification to statistical modeling.
compress()
The compress() function from Python's itertools library produces an iterator that filters elements from an input sequence based on another iterable containing Boolean values.
Let’s say you have a list of product reviews and a corresponding list that marks each review as either relevant or not relevant.
Here is the code.
from itertools import compress
# Product reviews
reviews = ["Great!", "Bad!", "Average.", "Excellent!", "Poor!"]
# Relevance flags: 1 for relevant, 0 for irrelevant
relevance_flags = [1, 0, 0, 1, 0]
# Use compress to keep only relevant reviews
relevant_reviews = list(compress(reviews, relevance_flags))
print(relevant_reviews)
Here is the output.


In the example, compress() takes two lists: reviews and relevance_flags. It goes through both lists together and keeps the reviews where the corresponding flag is 1 (relevant). The result is a list containing only the relevant reviews.
This is useful in data science for quickly filtering large datasets based on a set of conditions, which helps in focusing the analysis on only the data that matters.
dropwhile()
The dropwhile() function in Python's itertools library creates an iterator that drops elements from an input sequence as long as a given condition is true.
In data science, this function is useful for ignoring a segment of data that doesn't meet certain criteria.
For instance, if you're analyzing website traffic and want to focus only on periods of high activity, dropwhile() can help you ignore low-traffic intervals.
Here is the code.
from itertools import dropwhile
# Hourly website traffic counts
traffic_data = [10, 12, 8, 15, 20, 25, 30]
# Function to check for low traffic
def is_low_traffic(x):
return x < 15
# Use dropwhile to ignore low-traffic hours
high_traffic_data = list(dropwhile(is_low_traffic, traffic_data))
print(high_traffic_data)
Here is the output.

In this code, dropwhile() uses the is_low_traffic function to skip over the first elements that are below 15. Once it encounters an element that is 15 or higher, it includes all elements after that. The result is a new list that starts from the first high-traffic hour. This is handy in data science to focus on segments of data that are relevant to the analysis, allowing for more targeted insights.
Combinatoric iterators
After mastering infinite and finite iterators, let's dive into the fascinating domain of combinatoric iterators. These are special tools designed to perform combinations, permutations, and cross-products. They are extremely useful when we need to explore all possible scenarios or arrangements in data science tasks.

product()
The product() function in Python's itertools library creates an iterator that produces the Cartesian product of input iterables.In data science, this function is particularly useful for generating all possible combinations of different sets of parameters for model tuning.
Imagine you want to try out various combinations of learning rates and batch sizes to optimize a machine-learning model.
Here is the code.
from itertools import product
# Possible learning rates and batch sizes
learning_rates = [0.01, 0.1, 0.5]
batch_sizes = [32, 64, 128]
# Generate all combinations using product
parameter_combinations = list(product(learning_rates, batch_sizes))
print(parameter_combinations)
Here is the output.


The product() function takes two lists: learning_rates and batch_sizes. It then creates an iterator that gives you all possible pairs between these two lists. The result, parameter_combinations, includes all possible combinations of learning rates and batch sizes.
This helps in running experiments to fine-tune machine learning models, allowing you to test each combination systematically.
permutations()
The permutations() creates an iterator that produces all possible arrangements of an input iterable. In data science, this is useful for tasks like feature selection where you might want to test different combinations of input variables to improve a model's performance.
For example, if you have a dataset with three features—'Age', 'Income', and 'Education Level'—you could use permutations() to see how different combinations of these features impact the model.
Here is the code.
from itertools import permutations
# Features in a dataset
features = ['Age', 'Income', 'Education Level']
# Generate all permutations of features
feature_permutations = list(permutations(features, 2))
print(feature_permutations)
Here is the output.

The permutations() function takes the list features and the integer 2, which specifies the length of the permutations we want to generate. The output, feature_permutations, gives you all 2-element arrangements of the given features.
This list can be used to experiment with different feature combinations in a machine-learning model. By testing each of these permutations, you can identify which set of features gives you the best model performance.
combinations()
The combinations() function creates an iterator over unique combinations of elements from an input iterable. In data science, you often face problems where you need to select a subset of features to feed into a model.
Imagine you have a dataset with columns like 'Age', 'Salary', and 'Years of Experience'. Using combinations(), you could generate all possible pairs or triplets of these columns to find the most predictive set.
Here is the code.
from itertools import combinations
# List of features in a dataset
features = ['Age', 'Salary', 'Years of Experience']
# Generate all 2-element combinations of features
feature_combinations = list(combinations(features, 2))
print(feature_combinations)
Here is the output.


This code takes the list of features and generates all unique 2-element combinations. The output is stored in feature_combinations. You could then use this output to train your model with different feature sets.
The idea is to find out which group of features makes your model the most accurate. This can help you improve model performance without adding extra complexity.
Conclusion
We dived into Python's itertools, explored how to loop more efficiently, and even checked out some practical data science applications. From infinite iterators to the nitty-gritty of finite iterators and combinatoric iterators.
Reading is a great start, but practice makes perfect. The more you code, the more you get those "aha!" moments that make everything click. So, I encourage you to roll up those sleeves and start coding. Tinker with these iterators and implement them in your projects. It's the best way to become proficient and elevate your data science game.
If you're keen on taking your skills to the next level, our platform is the place to be. We offer hands-on data projects and challenging Python interview questions that mirror what you'll face in the real world. So why wait? Dive in, get your hands dirty, and prepare to shine in your data science career. See you there!
FAQ’s
Why use iterator instead of for loop Python?
Iterators can be more memory-efficient than for loops, especially with large data sets. They only generate the next value when you ask for it, so they don't load everything into memory at once.
What should you keep in mind when using the repeat () function of the Itertools module?
Be cautious with repeat() because it generates an infinite loop of repeated values. Always pair it with another function to limit the repetitions, or you'll get stuck in an endless loop!
How do you loop through an iterator in Python?
You can use a for loop or the next() function to go through an iterator. For example, for items in the iterator: will loop through each item until it reaches the end.
Which modules contain functions that create iterators for efficient looping in Python?
The itertools module is the go-to for efficient looping iterators. There are also the functools and operator modules which offer some utility functions that can be used with iterators.
Share


