Using Lambda Filter in Python to Solve Amazon Interview Question


Categories:
 Written by:
Written by:Nathan Rosidi
Introducing the lambda filter function in Python through a medium-level interview question from Amazon.
Analyses typically require identifying and studying particular groups of interest because businesses want to know the best or worst performing markets and customers. This helps them optimize the company strategy by addressing issues or adapting to trends uncovered in the analysis.
As an analyst, this means understanding which groups to focus on by calculating summary metrics (i.e. average monthly transaction, % of new customers, average sales value, etc.) and filtering the dataset for these ‘special groups’ - typically those that exceed or underperform compared to a threshold. For tasks like this, the lambda filter combination is a powerful way to streamline your code.
Let’s see this “Lambda Filter” in action as we solve a medium-level Python interview question from Amazon.
How to Use Lambda Filter in Python

To learn about lambda filter function in python, we’ll dive into an example question from Amazon. This interview question is called ‘Three Purchases’.
Last Updated: March 2022
List the IDs of customers who made at least 3 orders in both 2020 and 2021.
Link to the question: https://platform.stratascratch.com/coding/2095-three-purchases
Video Solution:
We’re given a table listing the order and user ID, order date and totals.
Notice that the order_date column does not only give us the year of the order, but the full date and timestamp as well. So first, we need to extract the ‘year’ information to analyze orders on this basis. We can use the pandas.Series.dt.year function to do this.
# Import your libraries
import pandas as pd
#Extract year of order
amazon_orders['year'] = amazon_orders['order_date'].dt.year
Questions We Need to Answer to Solve This Problem
- How many orders did each user place each year?
- Which customers placed at least 3 orders in 2020?
- Which customers placed at least 3 orders in 2021?
- Which customers placed at least 3 orders in 2020 and 2021?
How Many Orders Did Each User Place Each Year?
Easy. We can group the dataset by user ID and year and calculate the total number of orders for each of these user ID-year combinations. Assuming we have only one row per unique order, the total number of rows is equivalent to the total number of orders.
Yes, you’ll be able to do this using:
amazon_orders.groupby(['user_id', 'year'], as_index=False).size()
But let me demonstrate how you could also do the same using a lambda expression.
Lambda expressions are defined using the following syntax:

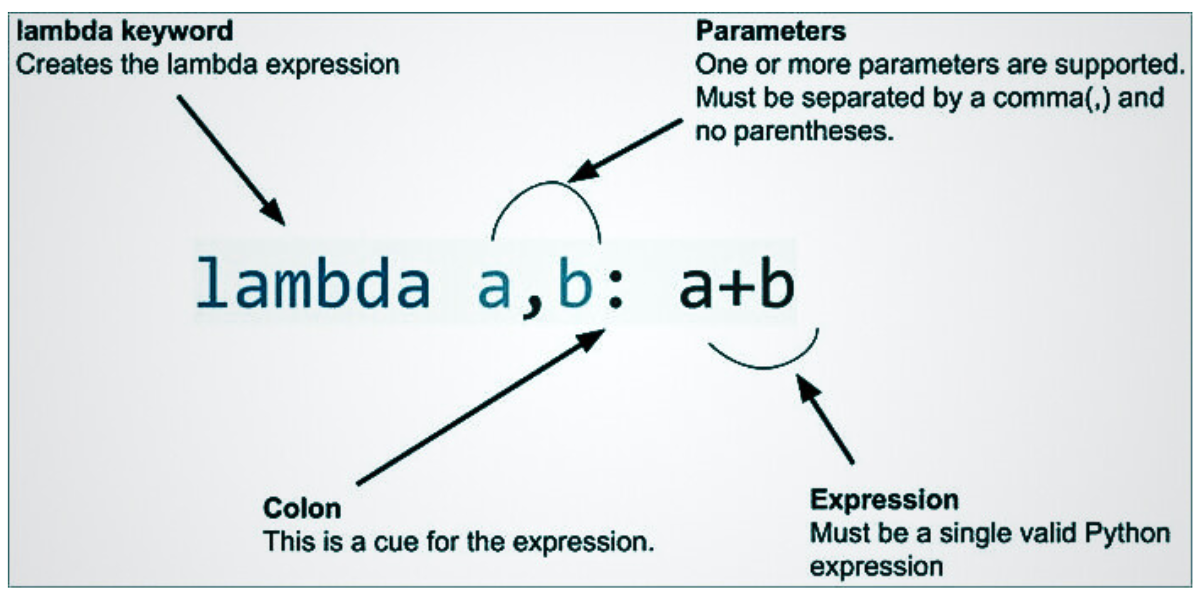
Like the ‘usual’ function, it will take one or more arguments and return a value based on the expression provided. The main advantage to using lambda expressions is that you can create and invoke a lambda function in a single line! Therefore, it is the preferred method for simple and ad-hoc calculations.
After grouping our orders by user_id and year, we can calculate the number of rows by taking the length of each column. This is quite simple but if you ever had to do a more customized calculation, say converting a decimal to percentage terms (i.e. number X 100) or any other operation not currently served by in-built functions, i.e. mean(), size(), min(), max(), sum(), lambda functions will be your savior!
#Group the orders by user ID and year
amazon_orders.groupby(['user_id', 'year'], as_index=False).agg(lambda x: len(x))
Tip: Using lambda expressions will allow you to perform more complex calculations in your grouped dataframes. Why don’t you try creating your own lambda functions with our code editor to become more familiar with lambda expressions?
Which Customers Placed At Least 3 Orders in 2020? In 2021?
To answer the next two questions, let’s first filter for customers ordering at least 3 times in any year. We can do this quickly with a filter function.
Note:
A filter function returns items of the iterable which satisfies the given condition. It will take in two arguments:
- a function which returns True or False; and
- an iterable, such as a list, tuple, string, or any other sequence can be iterated over in a for-loop.
Syntax: filter(function, iterable)
You can use lambda expressions with filter functions. Instead of having our lambda expression return the total number of rows, we can revise it slightly to return True or False instead.
lambda x: len(x)>=3
As you will see in the code below, we have tweaked our solution by using:
- A filter (instead of an aggregation function)
- Lambda expression returning True or False (instead of a calculation)
Tip: groupby() generates an iterable so you can apply a filter function on the resulting groups too!
What our code does is:
- Groups the orders table by user_id and year
- For each of these groups, checks if the length of the columns (total orders) is greater than or equal to 3
- If it is, the group is returned. Otherwise, it is excluded from the result.
This gives us a subset of the orders history table, where the customer ordered at least 3x in that year.
We want 1) information only for 2020 and 2021 and 2) a unique list of customer IDs for these years. We will use a set method to get rid of the duplicated customer IDs. (Notice that the result above shows a filtered orders table, not an aggregated one.)
#customers with >=3 orders in 2020
customers_2020 = set(orders_per_year[orders_per_year['year'] == 2020]['user_id'])
#customers with >=3 orders in 2021
customers_2021 = set(orders_per_year[orders_per_year['year'] == 2021]['user_id'])
Which Customers Placed at Least 3 orders in 2020 And 2021?
Imagining we have two sets of customer IDs (one for 2020 and another for 2021), we need to identify the customers who are in both sets.
#retrieve unique customers who ordered >=3x in 2020 and 2021
customers_2021.intersection(customers_2020)
And label the column appropriately after converting this into a pandas dataframe.
result = pd.DataFrame(customers_2021.intersection(customers_2020), columns=['user_id'])
Let’s submit our final solution!
# Import your libraries
import pandas as pd
#Extract year of order
amazon_orders['year'] = amazon_orders['order_date'].dt.year
#only look at user_id-year combinations where total orders>=3
orders_per_year = amazon_orders.groupby(['user_id', 'year']).filter(lambda x: len(x) >=3)
#customers with >=3 orders in 2020
customers_2020 = set(orders_per_year[orders_per_year['year'] == 2020]['user_id'])
#customers with >=3 orders in 2021
customers_2021 = set(orders_per_year[orders_per_year['year'] == 2021]['user_id'])
#retrieve unique customers who ordered >=3x in 2020 and 2021
result = pd.DataFrame(customers_2021.intersection(customers_2020), columns=['user_id'])
Closing
I hope you enjoyed that introduction to using lambda filters and expressions and realized how powerful it can be when preparing or analyzing data. Can you think of applications in your project or job?
Whether you want to streamline your code or learn new functions, we have more content in our Top 30 Python interview questions article so do check it out. Otherwise, if you like to learn by solving questions instead, check out different questions used in interviews on our coding platform.
Share


