Understanding Python Try Except Blocks


 Written by:
Written by:Nathan Rosidi
From basics to advanced: Navigating Python try except blocks with real-world data science applications using the world happiness report dataset.
Have you ever faced an error in your Python script, scratching your head wondering what just happened? Well, you are not alone! Python, like any other programming language, can encounter errors.
To handle these errors, Python try-except blocks are essential. Understanding it can sometimes feel like learning a new language, but fortunately, it is a simple concept. The "try" block lets you test a block of code for errors, while the "except" block lets you handle the error.
In this article, we will explore the nitty-gritty details of Python's try-except blocks. From the basic syntax to handling specific errors, and diving deep into advanced concepts, we have it all covered for you. Let’s buckle up and get started!
Basic of Try-Except Blocks in Python
In Python, creating a try-except block is quite straightforward. First, you use the code that might raise an error in a "try" block. Then, you define the "except" block where you specify how to handle potential errors. Let's break down a simple example to give you a better understanding:
try:
result = 10 / 0
except ZeroDivisionError:
result = "Sorry, you cannot divide by zero"
In this code, we have a try block where we try dividing 10 by 0, an operation that will certainly cause a ZeroDivisionError.
Fortunately, we have guessed this error and have set up an except block to catch it, preventing the program from crashing and assigning an error message to the result variable.
But what happens when this variable runs?
result

Of course, the message we define will output.
Common Errors Caught by Try-Except in Python


These errors, from SyntaxError to ZeroDivisionError, can all be handled, ensuring that your program doesn't crash unexpectedly.
Later in this article, we will cover some common errors and learn how to catch them in your try-except blocks.
To understand this, let’s use a dataset, from Kaggle.
World Happiness Report


The World Happiness Report is a notable study, here. It was first released in 2012, with new editions coming out almost every year since then.
It is a big survey that asks people from 156 different countries about how happy they feel. The happiness score comes from things like how much money people make and how supported they feel by friends, family, and the government.
This study isn't just famous; it's becoming a vital tool for groups and governments worldwide in shaping their policies. Top professionals from various fields, such as health, public policy, and more, contribute to the report.
In this article, we will use the 2019 world happiness report Report collected from Kaggle.
Here is the link: https://www.kaggle.com/datasets/unsdsn/world-happiness, where you can download World Happiness Reports from 2015 to 2019.
Here are the first few rows of our dataset.


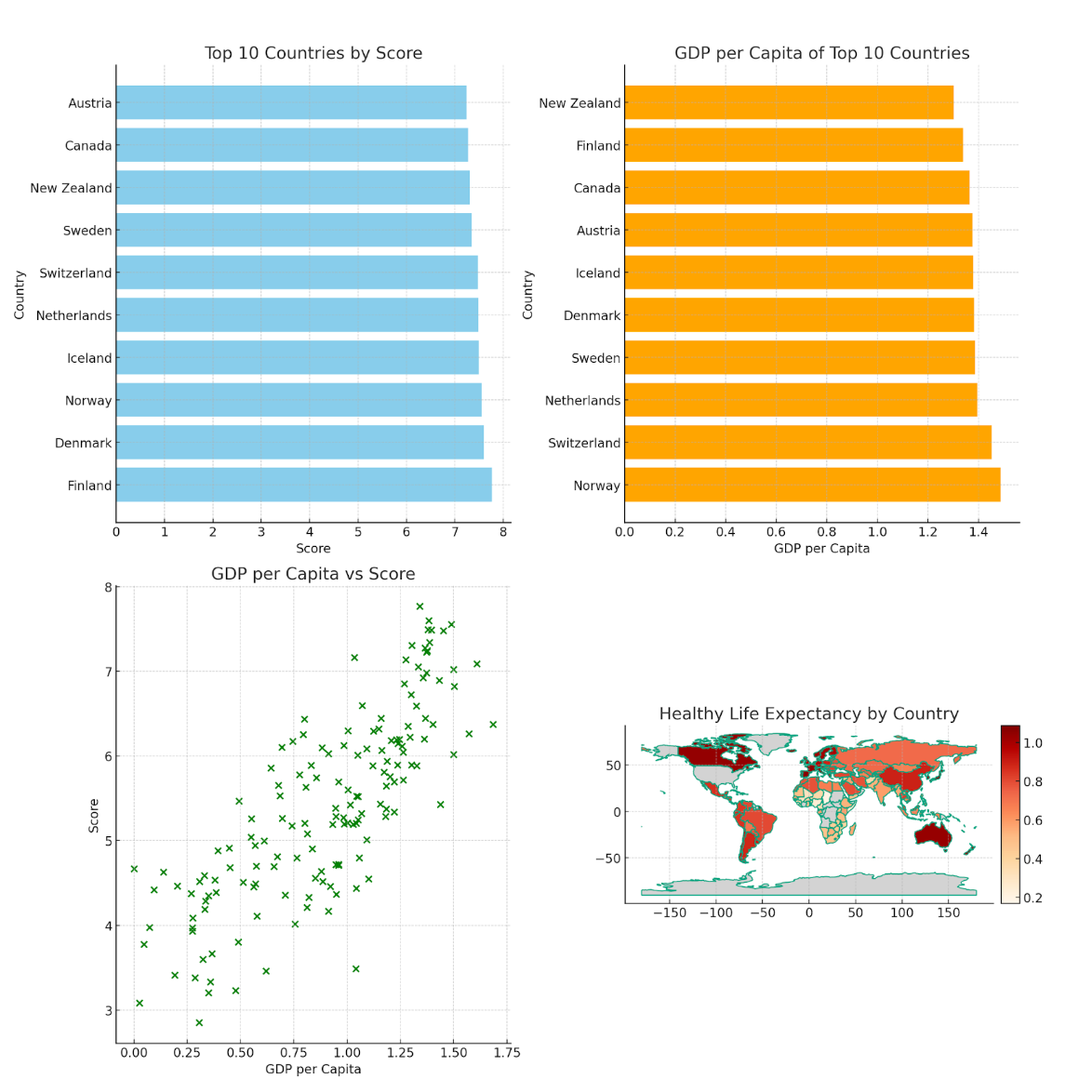
Here 4 graphs, that explain our dataset a little bit better.
Here is the code.
# Sort the top 10 countries by GDP per capita in descending order
top_10_countries_gdp = top_10_countries.sort_values(by='GDP per capita', ascending=False)
# Set up the subplot grid
fig, axarr = plt.subplots(2, 2, figsize=(14, 14))
# Plot 1: Horizontal bar graph showing the top 10 countries based on the overall score
axarr[0, 0].barh(top_10_countries['Country or region'], top_10_countries['Score'], color='skyblue')
axarr[0, 0].set_title('Top 10 Countries by Score')
axarr[0, 0].set_xlabel('Score')
axarr[0, 0].set_ylabel('Country')
# Plot 2: Horizontal bar graph showing the GDP per capita of the top 10 countries in descending order
axarr[0, 1].barh(top_10_countries_gdp['Country or region'], top_10_countries_gdp['GDP per capita'], color='orange')
axarr[0, 1].set_title('GDP per Capita of Top 10 Countries')
axarr[0, 1].set_xlabel('GDP per Capita')
axarr[0, 1].set_ylabel('Country')
# Plot 3: Line graph depicting the relationship between GDP per capita and score
axarr[1, 0].scatter(data['GDP per capita'], data['Score'], color='green')
axarr[1, 0].set_title('GDP per Capita vs Score')
axarr[1, 0].set_ylabel('Score')
axarr[1, 0].set_xlabel('GDP per Capita')
# Plot 4: Geographical map highlighting the healthy life expectancy in different countries
divider = make_axes_locatable(axarr[1, 1])
cax = divider.append_axes("right", size="5%", pad=0.1)
world.boundary.plot(ax=axarr[1, 1], linewidth=1)
world.plot(column='Healthy life expectancy', ax=axarr[1, 1], legend=True, cax=cax, cmap='OrRd', missing_kwds={'color': 'lightgrey'})
axarr[1, 1].set_title('Healthy Life Expectancy by Country')
# Adjust the layout
plt.tight_layout()
plt.show()
Here is the output.

Now, since we are familiar with this dataset, let’s start applying Python try-except blocks.
Feature Engineering - ZeroDivisionError
While creating new features by manipulating existing columns, data scientists often encounter errors.
In this scenario, we will create a new column by dividing two existing columns, where one contains zero values.
This can lead to a ZeroDivisionError. We will handle this by replacing instances of division by zero with NaN, and then remove these NaN values.
import numpy as np
# Creating a new column by dividing "Score" by "GDP per capita", and handling ZeroDivisionError by replacing it with NaN
def safe_division(score, gdp):
try:
return score / gdp
except ZeroDivisionError:
return np.nan
data['Score_per_GDP'] = data.apply(lambda row: safe_division(row['Score'], row['GDP per capita']), axis=1)
# Display the first few rows of the dataframe to observe the new column created and the NaN value at index 5
data.head(6)
Here is the output.

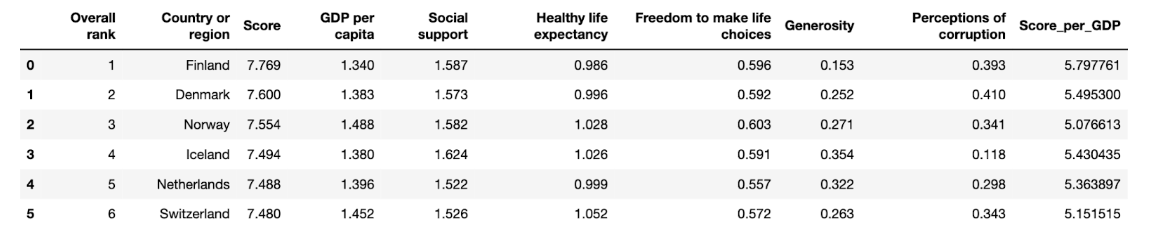
As you can see, here now we create Score_per_GDP column. But one thing to be careful about is there might be a nan because we make divison. Let’s check whether our new column contains nan or not.
print(df['Score_per_GDP'].isna().any())Here is the output.


Now as you can see our try and except block successfully works, and assigns nan instead of ZeroDivisionError. Let’s remove nan’s. Here is the code.
print(data_cleaned['Score_per_GDP'].isna().any())Here is the output.

Let’s check, whether our new column has nan or not. Here is the code.
print(data_cleaned['Score_per_GDP'].isna().any())Here is the output.


Now, we successfully removed nan as you can see.
Data Cleaning- Custom Errors
Our dataset does not contain any missing values, however, let’s put missing rows inside our dataset by using the following code.
import random
data_cleaned['Score_per_GDP'] = data_cleaned.apply(lambda row: safe_division(row['Score'], row['GDP per capita']), axis=1)
# Introducing NaN values in random rows in the "Score_per_GDP" column
random.seed(42) # Setting seed to get reproducible results
nan_rows = random.sample(range(len(data_cleaned)), 5) # Generating 5 random row indices
data_cleaned.loc[nan_rows, 'Score_per_GDP'] = np.nan # Setting the values in the randomly chosen rows to NaN
# Display the rows with NaN values
row_with_nan = data_cleaned.loc[nan_rows]
Here we added nan rows, but we also don't know which column is nan, to check afterward, we assigned numbers to row_with_nan. Now let’s define try except blocks to check, if there are nan values that exist in the column, it will fill with the mean of the column and print the row names afterward. Let’s check, here is the code.
try:
# Check if there are NaN values in the column
if data_cleaned['Score_per_GDP'].isna().any():
# Get the mean of the column
mean_value = data_cleaned['Score_per_GDP'].mean()
# Get the indices of the rows with NaN values
nan_indices = data_cleaned[data_cleaned['Score_per_GDP'].isna()].index.tolist()
# Replace NaN values with the mean of the column
data_cleaned['Score_per_GDP'].fillna(mean_value, inplace=True)
# Display a message with the indices of the rows where NaN values were replaced
print(f"[{', '.join(map(str, nan_indices))}] rows NaN values have been filled with the mean.")
else:
print("There are no NaN values in the column.")
except Exception as e:
print(f"An error occurred: {e}")
Here is the output.


Let’s check the variable that we created at first, to see if we did it correctly.
row_with_nanLet’s see the output.


As you can see from the two outputs, we can fill gdp’s with the mean successfully.
Data Manipulation - Index Error
In data science, it is common to remove rows from a dataset during the data cleaning process. However, this can sometimes lead to attempts to access rows that have been deleted, resulting in an IndexError.
To prevent our script from crashing when this happens, we can use a python try-except block, inside our script, to catch the IndexError and handle it. Let’s check.
# Removing rows with NaN values in the "Score_per_GDP" column
length_data = len(data)
data_cleaned = data.dropna(subset=['Score_per_GDP'])
try:
# Trying to access a row using an index that no longer exists in the data_cleaned dataframe
print(data_cleaned.loc[length_data])
except KeyError:
print(f"KeyError: Attempted to access index {length_data}, but the dataset only contains {len(data_cleaned)} rows.")
Here first, we assign data frame's length to the length_data variable. Then we cleaned our dataset, We will try to reach our datasets last row, but if we have an issue, we will raise an error that prints our datasets last length.
Python Try Except Advanced Concepts

Understanding and using advanced concepts such as nested try-except blocks and else-finally clauses can enhance error handling in Python, particularly in data science tasks. Let's go into these concepts with practical examples, focusing on data manipulation and cleanliness.
Nested Try-Except Blocks
In more complex scripts, you might encounter situations where you need to handle different errors that can occur at different points in a process. In such cases, nested try-except blocks can be very useful.
Let's illustrate this with an example where we will try to access a specific row in our dataset and then try to access a specific column in that row:
def get_cell_value(dataframe, row_idx, col_name):
try:
# First try block to catch index related errors
row_data = dataframe.loc[row_idx]
try:
# Second try block to catch column related errors
cell_value = row_data[col_name]
print(f"The value at row {row_idx}, column '{col_name}' is: {cell_value}")
except KeyError:
print(f"KeyError: The column '{col_name}' does not exist in the dataset.")
except KeyError:
print(f"KeyError: The row with index {row_idx} does not exist in the dataset.")
# Usage example
get_cell_value(data_cleaned, 65, 'Country or region')
Now, in the final part of the code above, we try to see 65th row’s country of our dataframe. Here is the output.

Else-Finally
In Python, the else and finally clauses in a try-except block allow you to manage the flow of your script effectively, especially when working with data science tasks involving data manipulation and cleaning.
Here, we walk you through a structured approach to handling errors and maintaining data cleanliness using a try-except-else-finally block:
try:
# Create a new column by dividing "Score" by "GDP per capita"
data['Score_per_GDP'] = data['Score'] / data['GDP per capita']
except ZeroDivisionError:
print("ZeroDivisionError: Attempted to divide by zero. Assigning NaN to the column.")
data['Score_per_GDP'] = np.nan
except KeyError as e:
print(f"KeyError: The column '{e}' does not exist in the dataset. Assigning NaN to the new column.")
data['Score_per_GDP'] = np.nan
else:
# Check if any NaN values were created and report them
nan_rows = data['Score_per_GDP'].isna().any()
if nan_rows:
print(f"NaN values were created. Handling them appropriately.")
finally:
# Remove rows with NaN values in the 'Score_per_GDP' column
data.dropna(subset=['Score_per_GDP'], inplace=True)
print("End of data processing script. Any NaN values have been removed.")
Let’s breakdown this code above.
First, we try to make a new column called 'Score_per_GDP' by dividing the scores by the GDP per capita values. This is what we are hoping will work smoothly.
But, things can go wrong, so we have plans in place:
- If we end up dividing by zero (which isn't allowed), we catch this mistake, let the user know with a message, and fill the new column with "NaN" (not a number) to indicate missing values.
- If the column names we used don't actually exist in our data (maybe there was a typo or the column was deleted earlier in the script), we catch this mistake too, alert the user, and also use "NaN" for the whole new column.
Next, if everything in our first step worked nicely without any issues, we checked to see if we had any "NaN" values in our new column. If we find any, we let the user know with a message.
Lastly, no matter what happened before, we have a cleanup step at the end.
Here, we remove any rows with "NaN" values in our new column to keep our data tidy. We also print a message to let the user know that we've reached the end of our script and have removed any "NaN" values.
Conclusion
In this article, we discovered Python's try-except blocks, by using real-life examples drawn from data science scenarios with Kaggle's World Happiness Report dataset. We covered everything from basic implementations to advanced concepts like nested blocks and the role of "else" and "finally" clauses and ensuring data cleanliness.
If you want to discover more Python, by cracking interview questions, here are the top 30 Python interview questions.
FAQ’s
What is the try except block in Python?
In Python, a "try-except" block is used to catch errors and handle them instead of letting the program crash. You put the code you want to "try" to run inside the "try" block, and if an error occurs, the program jumps to the "except" block to handle the error.
How do you skip a try block in Python?
To "skip" a try block means not to run the code in it. While we don't usually skip a "try" block, we can use "if-else" conditions to control whether or not to enter the "try" block based on certain conditions. So, if you don't want to run the "try" block, you can set up a condition that prevents entering it.
How many except block can a try have in Python?
A "try" block can have multiple "except" blocks to catch different types of errors. This means if you have many different errors that could happen, you can set up several "except" blocks, each handling a different type of error, helping you respond to each error in the most appropriate way.
How to handle an exception using try except block in Python?
To handle an exception with a "try-except" block, you place the code that might cause an error in the "try" block. If an error occurs, the code in the "except" block is run, allowing you to handle the error in a way that you decide, like displaying a friendly error message to the user.
Share


