Top Data Warehouse Interview Questions with Answers


Categories:
 Written by:
Written by:Nathan Rosidi
Your ultimate guide to acing data warehouse interviews with in-depth answers to the interview questions and insider tips for every level.
Picture this: You've landed an interview for your dream job in data warehousing, and the countdown is on. What now? How do you prepare for those curveball questions?
Today, we’ll go into the data warehouse interview questions. We'll kick off with some basic questions, the ones that set the stage, like "What is a data warehouse?" and "Why is it important?"
Next, we'll ramp up to the more complex queries that even the pros might stumble on. Finally, you'll get insider tips to nail your answers like a pro. All roads in this guide lead to one destination: making you interview-ready for any data warehouse position. Are you in?
Data Warehouse Interview Questions
What is Data Warehousing?


Data warehousing is the process of collecting, storing, and managing data from varied sources to provide meaningful business insights.
Explain the ETL process in data warehousing.
ETL stands for Extract, Transform, Load. It's the pipeline that takes raw data from source systems, transforms it into a format that can be analyzed, and loads it into a data warehouse.

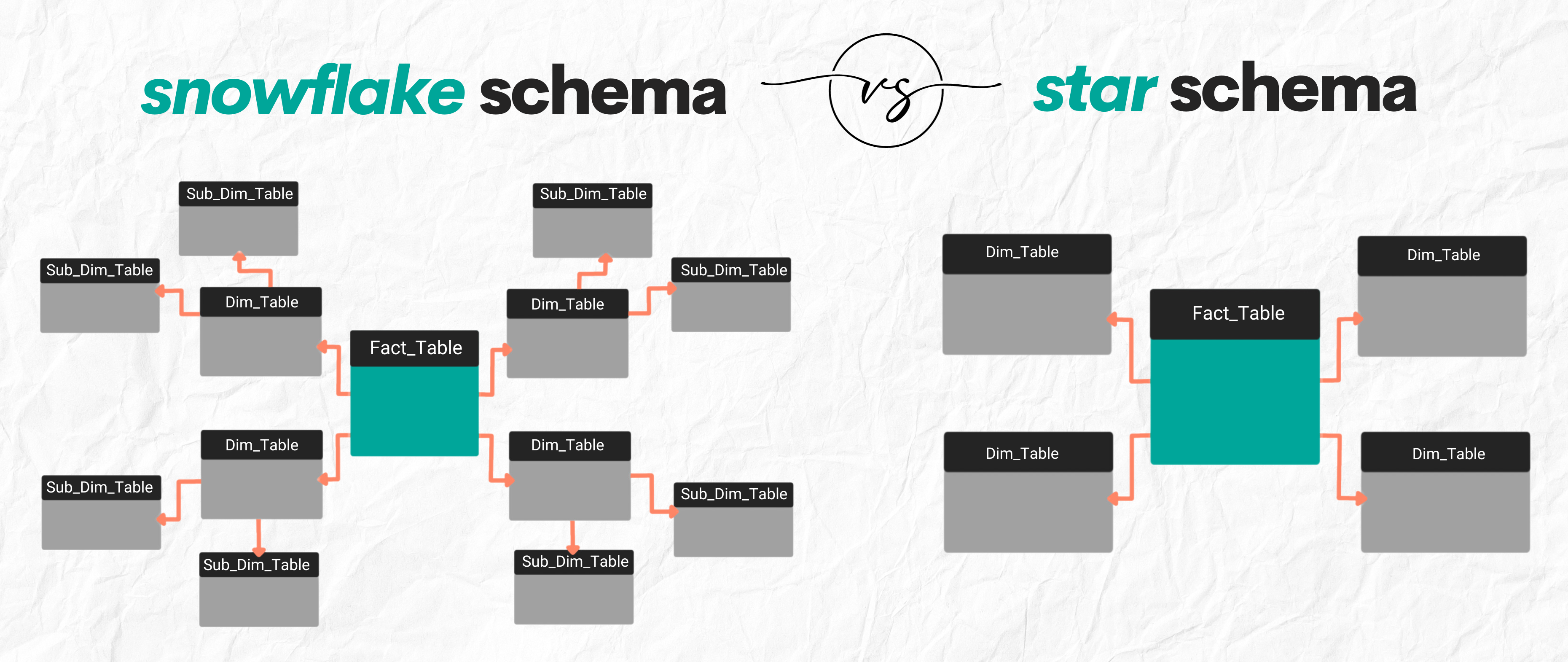
What is Star Schema?
Star Schema is a type of database schema where a central fact table is connected to one or more dimension tables, resembling a star shape. It's commonly used in data warehousing for its simplicity and speed in query performance.
What is Snowflake Schema?
Snowflake Schema is a more complex version of star schema. It normalizes dimension tables, breaking them into additional tables to minimize data redundancy.


What are Fact Tables and Dimension Tables?
Fact tables contain measurable, quantitative data. Dimension tables include descriptive, textual, or categorical information, which is typically the entry points to data.
What are Aggregates in a Data Warehouse?
Aggregates refer to the summarization of data, often precomputed and stored in a separate table. They help in reducing the volume of data to be scanned for query processing, thus improving performance. Think of it like a summary section at the end of each chapter in a book.
Can you explain Data Mining and its relationship with Data Warehousing?
Data Mining is the practice of discovering patterns and knowledge from large sets of data. Data warehousing and data mining are closely related because a data warehouse provides the clean, organized data needed for data mining. Imagine data warehousing as laying down the tiles for a mosaic, and data mining as the art of creating a picture with those tiles.
Explain the concept of Materialized Views.
Materialized Views are query results that have been stored in a table for quicker retrieval. Instead of running complex queries each time, you can pull data from a materialized view, effectively speeding up query performance. It's like freezing a portion of a flowing river for quick access later on.
What are Slowly Changing Dimensions (SCD)?
Dimensions that change gradually over time are called Slowly Changing Dimensions. Managing them is crucial to maintaining historical accuracy. There are different methods to handle SCDs—such as overwriting, adding new rows, or adding new attributes. It's akin to keeping track of the changes in a character as a movie series progresses.
How do you optimize Data Warehouse queries?
Query optimization can be done by using indexing, partitioning, or through the use of materialized views. Efficient SQL queries, avoiding nested subqueries, and removing unnecessary joins also play a part. Think of it as rearranging the furniture in a room for the quickest path to exit.
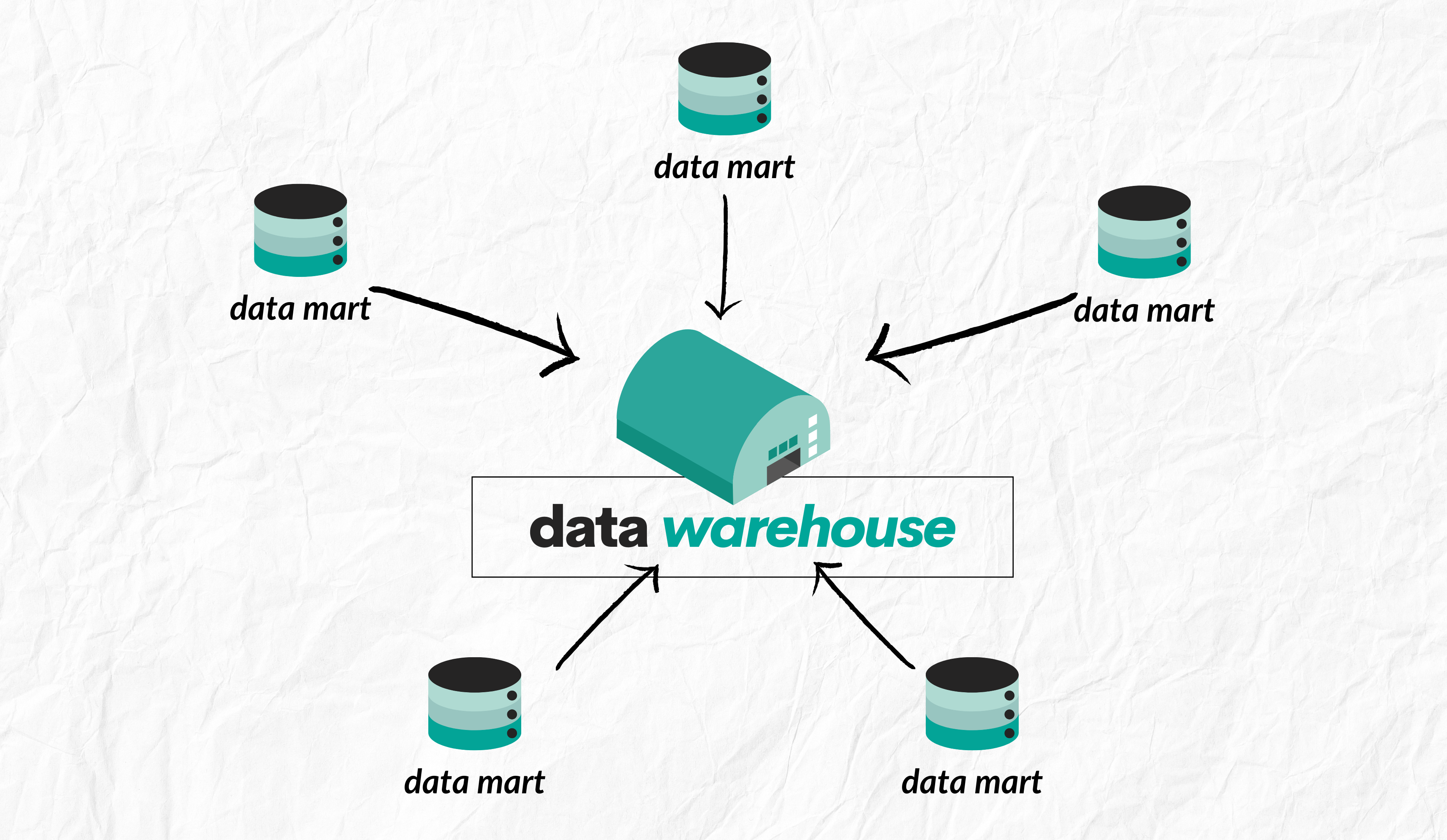
What is a Data Mart?
A Data Mart is a subset of a data warehouse that focuses on a specific area, like sales or marketing. It's similar to having a small convenience store in a neighborhood, derived from a larger supermarket for localized needs.
How does OLAP differ from OLTP, and what do they stand for?
OLAP (Online Analytical Processing) is geared towards complex querying and reporting, whereas OLTP (Online Transaction Processing) focuses on simple, transactional tasks like inserting, deleting, or updating data. OLAP is like a scientist analyzing data, while OLTP is like a cashier processing transactions.
Can you explain Real-Time Data Warehousing?
Real-Time Data Warehousing involves loading data into the warehouse as it's generated, enabling real-time analysis. It's like watching a live sports game and analyzing the stats as they happen, as opposed to waiting until the game ends.
What is a Staging Area in a Data Warehouse?
The Staging Area is a temporary space used for data processing during the ETL process. Data from different sources is collected here before being loaded into the data warehouse. Think of it as a backstage area where all elements come together before the big performance.
What are Measures in Data Warehousing?
Measures are the numerical metrics based on which analysis is done. They are stored in fact tables and can be aggregated to provide meaningful insights. Imagine them as the scoreboard in a game, showing runs, goals, or points to reflect performance.
What is a Surrogate Key?
A Surrogate Key is an artificial, system-generated unique identifier for each record in a table. Unlike natural keys, which may have a business meaning, surrogate keys are purely for database management. Think of them as arbitrary ID badges for rows in a table.
What are Conformed Dimensions?
Conformed Dimensions are dimensions that have the same meaning and content when being referred from different fact tables. This ensures consistency across the data warehouse. Imagine them as standardized units of measurement that everyone agrees upon, like kilograms or miles.
Can you explain Partitioning in Data Warehousing?
Partitioning involves dividing a large database into smaller, more manageable pieces called partitions. This optimizes query performance by allowing the system to access only the relevant partitions during query execution. It's like organizing a bookshelf by genre so you can find what you're looking for faster.
What is the role of Metadata in a Data Warehouse?
Metadata is data about data. It describes the structure, format, and characteristics of the data, helping users understand what's stored in the data warehouse. It's akin to the table of contents in a book, guiding you on what you can expect to find.


What is Change Data Capture (CDC) in Data Warehousing?
Change Data Capture tracks changes in source data so that only the altered data gets updated in the data warehouse. This makes the ETL process more efficient. Imagine it like a video editor who only needs to edit a few scenes, not the entire film.

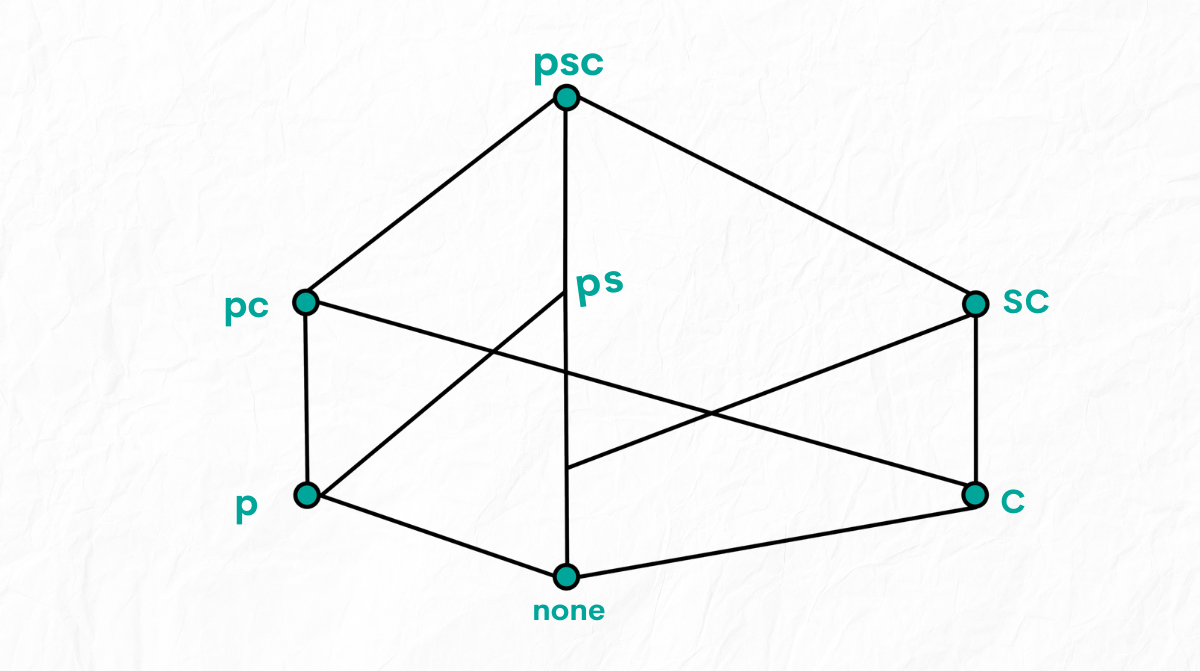
What is a Cube in Data Warehousing?
A Cube is a multi-dimensional data structure that allows fast retrieval of data. It is often used in OLAP databases to simplify complex queries. Think of it as a 3D spreadsheet where you can analyze data across multiple dimensions simultaneously.
Explain the concept of Normalization in Data Warehousing.
Normalization involves organizing the data in the database to reduce redundancy and improve data integrity. While it's beneficial for OLTP systems, it's often avoided in Data Warehouses to speed up query performance. It's like packing a suitcase efficiently; everything has its place, but you might take a performance hit when you need to quickly grab an item.
What are Indexes and how are they used in Data Warehousing?
Indexes are elements within a database designed to accelerate the process of fetching data. They're like the index at the back of a book, directing you to the exact page where you can find what you're looking for.
What steps do you take to protect data within a Data Warehouse?
Data security is often ensured through measures like encryption, access control, and auditing. It's equivalent to having a security system in your home; it's a necessary step to protect valuable assets.
What is Data Purging and why is it important?


Data purging is the process of permanently removing irrelevant or obsolete data from a data warehouse. It's essential for maintaining efficiency and reducing storage costs. Imagine it like spring cleaning your home to remove clutter.
What is a Factless Fact Table?
A Factless Fact Table contains only foreign keys, not facts. It's typically used for capturing many-to-many relationships. Think of it like a guest list for a party; it doesn't tell you much about the party itself, but it shows who's connected to it.
Explain the importance of Data Governance in Data Warehousing.
Data Governance involves the overall management of data availability, usability, and security. It's a set of practices that ensure high data quality and business value. It's akin to the rules and referees in a sports game, ensuring fair play and success.
What are Derived Tables in Data Warehousing?
Derived Tables are tables created in the data warehouse environment to ease the process of querying and reporting. They're not part of the original database schema but are based on queries that run on it. Imagine a summary at the end of a study guide based on the main textbook.
How is Business Intelligence different from Data Warehousing?
While Data Warehousing is more focused on the storage and management of data, Business Intelligence (BI) deals with the analysis and visualization of that data. Data Warehousing provides the data foundation, while BI turns that data into actionable insights. Think of Data Warehousing as the ingredients and BI as the recipe that makes a dish delicious.
What is a Hybrid Data Warehouse?
A Hybrid Data Warehouse combines traditional data warehousing with cloud-based storage. It aims to provide scalability, cost-effectiveness, and flexibility. Imagine a hybrid car that uses both gasoline and electric power; it tries to get the best of both worlds.
Also, you can see 40 Data Science interview questions from top companies.
Final Thoughts
Alright, we've covered a lot of ground! From the basics like "What is a data warehouse?" to tackling some tough, head-scratching questions, we've set you up for a strong game in your next data warehouse interview.
Now, you're armed with knowledge, but remember, practice makes perfect. Fields related to data are areas where learning never stops. The best way to get ahead is to keep practicing. Those questions we tackled?
Check out our platform, to flex those data science muscles. Go into real-world data projects, solve interview questions, and interact with a community just as passionate as you are.See you there!
FAQ’s
What are the 4 key components of a data warehouse?
The 4 key components of a data warehouse are: Data Sources, ETL Process (Extract, Transform, Load), Data Storage, and Presentation Layer.
How do you explain data warehouse project in interview?
In an interview, you could explain a data warehouse project as a centralized repository designed to store and manage large volumes of data, which is then used for reporting and data analysis.
What is a data warehouse answers?
A data warehouse is a centralized storage system that consolidates data from various sources, making it easier to run queries and generate reports for business intelligence.
What are the three major areas in the data warehouse?
The three major areas in the data warehouse are: Data Sourcing and Integration, Data Storage, and Data Access and Presentation.
Share


