Spotify Data Science Interview Question Walkthrough


Earning the rank of number 10 in Fortune’s Future 50 in 2020, Spotify offers a diverse array of job options for the ambitious data scientist.
A quick search on Spotify’s website shows tempting options for data scientists looking to explore different areas of data science: marketing, user research, product insights, etc. In today’s article, we will explore the following interview question sourced from recent Spotify data science interviews.
Spotify Data Science Interview Question
Find the number of times an artist has been on the billboard top 100 in the past 20 years. Output the result alongside the artist's name and order records based on the founded count in descending order.
Link to the Question: https://platform.stratascratch.com/coding/9744-artist-of-the-decade
Follow along with us at StrataScratch as we walk through how to first approach and then solve this Spotify data science interview question along with Frederik Müller. Please note that this interview question has been modified since the date of this recording. The approach is still the same, but the output accounts for the last 20 years of history instead of 10.
Skills Used in this Spotify Data Science Interview Question
The following skills will be used in the approach to solving this problem:
- Arithmetic operations
- COUNT() / GROUP BY
- Built-in date functions
Approach
The first approach to any interview data science interview question involves a few initial steps:
- Gathering and reviewing all data provided
- Noting the expected output, and
- Clarifying whether there are any uniquities or challenges that must be addressed in the solution
The data for this problem is all present in one table: billboard_top_100_year_end. This table provides a list of all songs that have hit the billboard top 100 along with the year, the artist name, the group name, and the song’s ranking.
| year | year_rank | group_name | artist | song_name | id |
|---|---|---|---|---|---|
| 1956 | 1 | Elvis Presley | Elvis Presley | Heartbreak Hotel | 1 |
| 1956 | 2 | Elvis Presley | Elvis Presley | Don't Be Cruel | 2 |
| 1956 | 3 | Nelson Riddle | Nelson Riddle | Lisbon Antigua | 3 |
| 1956 | 4 | Platters | Platters | My Prayer | 4 |
| 1956 | 5 | Gogi Grant | Gogi Grant | The Wayward Wind | 5 |
Our expected output is a list of artist names along with the total number of times they showed up in the billboard top 100 chart within the last 20 years. The list should be ordered by the number of appearances, highest to lowest. In the data set provided, there is already a column of artist names present, which we will use as our first returned column. Because it’s possible that an artist may be part of multiple groups in addition to a solo career, this is the reason for choosing the artist column for our query instead of the group_name column. The second column returned by the query will be the number of times each artist has appeared in the list. This will require use of the COUNT() function. Here is the base knowledge we will use to build up our query.
Building the Query
As the query is built below, follow along with each step by running the code provided to see how the query evolves.
We first find all artists in the table and return the total number of times that each artist is present. The brief also tells us to order the results by frequency of appearance, so let’s order by column 2, which is the result of COUNT(*) :
SELECT artist,
COUNT(*) as count_20yrs
FROM billboard_top_100_year_end
GROUP BY artist
ORDER BY 2 DESCSince this Spotify data science interview question asks only for the results from the last 20 years*, a WHERE clause is added to filter the results. At this point the goal is to test for accuracy–the query will be refined later.
SELECT artist,
COUNT(*) AS count_20yrs
FROM billboard_top_100_year_end
WHERE YEAR >= 2002
GROUP BY artist
ORDER BY 2 DESC*Please note the year in the example is reliant upon the release date of this article.
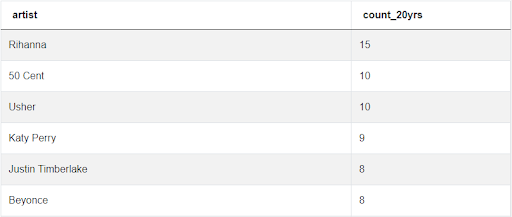
Here are the results of the query as it currently exists:

Refining the Query
Now that the query has an accurate solution, it is time to refine the WHERE clause for better applicability. The goal of writing an effective query is to ensure that the code is “future-proof”, i.e. the query should work as expected as time moves forward. Our output should only include data from the last 20 years of billboard history, so we’ll isolate the current year in the query using DATE_PART() and CURRENT_DATE:
DATE_PART(‘YEAR’, CURRENT_DATE)To find results from the last 20 years, we subtract the value in the year column from the current year using the - operator and only display the row if the result is <= 20. Finally, best practices include specifying the column name instead of the asterisk(*) [all columns] wherever possible. Though COUNT(*) works in this instance because all rows in the table are unique, specifying the artist column helps with readability and processing time:
SELECT artist,
COUNT(artist) AS count_20yrs
FROM billboard_top_100_year_end
WHERE DATE_PART('year', CURRENT_DATE) - YEAR <= 20
GROUP BY artist
ORDER BY COUNT(artist) DESCAs we can see below, the output here is the same as the previous, unrefined code, though this modification ensures the results will remain accurate as time passes.

Conclusion
Through the course of this article and the affiliated video, we’ve walked through the steps taken to evaluate this Spotify data science interview question, the data provided, assumptions about those data, and worked through the resolution. Once the question was solved, we walked back through the solution and refined the query for future readability. We used COUNT() to find a count of all of the artists, DATE_PART() to isolate the year value from CURRENT_DATE, and the subtraction (-) and comparison (<=) operators to produce the final result. Check out our post "Data Science Interview Questions From Top Companies" to practice more such questions from other top companies.
Latest Posts:



Share