Solving LeetCode Word Break Problem for Data Science Interviews


Categories:
 Written by:
Written by:Irakli Tchigladze
Solve this LeetCode Python challenge called “Word Break” to sharpen your skills
Having a successful career in tech comes down to your willingness and motivation to learn, even after you get a job. Data science is no exception. Data scientists who don’t get complacent and spend time on improving their skills are always in high demand.
As a data scientist, if your primary focus is to get a data science job, platforms like StrataScratch and LeetCode are ideal places to start. They contain hundreds of data science questions asked during actual data science interviews. Python developers can use LeetCode to practice writing algorithms to work with data.
Using Platforms like LeetCode and StrataScratch is especially important if you are a fresh graduate with little to no coding experience. In this article, we will walk you through the answers of a difficult question called “Word Break” on LeetCode platform. By the end, you should have an insight into writing efficient algorithms during an interview.
Solving the LeetCode Word Break Problem
To solve this question, candidates have to compare and match two values. The first one is a string - a collection of symbols, usually letters. The second value is a list of words, which are also string values. Simply put, we have to check if words from the list can be put together to match the string.
This LeetCode word break question may seem simple at first, but it is more difficult than you might expect.


Link: https://leetcode.com/problems/word-break/
When approaching difficult questions like this one, it helps to understand the full picture: what the question asks, available data and expected output. Your approach to this problem will speak volumes about your ability to write simple, but precise algorithms to handle any edge cases in the data.
Framework to Solve this LeetCode Word Break Problem

To find an answer to questions like this one, first consider all of its components: the available data, limits of data, expected output, and any other condition there might be. Once you connect all the dots, you can start thinking about your approach to the question.
When trying to wrap your head around a Python challenge, always follow these three steps:
1. Understand your data
- Pay attention to the structure and type of data you have to work with.
- When you compare two pieces of data, consider how they could be related.
- Pay attention to what type of value the question asks you to return. Sometimes candidates successfully get the answer, only to return the wrong value.
- Consider constraints and limitations of available data. For this particular question, constraints give you information about important factors that you need to consider when writing an algorithm.
2. Formulate your approach
- Create a list of logical steps necessary to find the answer.
- You can start with a simple and obvious approach. This process can help you wrap your head around the question.
- Write down any ideas for improving the algorithm. When solving difficult problems like this one, taking notes of your thought process can go a long way
- Pay close attention to the question description. Sometimes it contains important details and conditions.
- Don’t be afraid to think out loud when coming up with an approach. It’s an opportunity to show your analytical thinking skills. Talking about your approach might also give you ideas to further refine your algorithm.
3. Code execution
- Think of Python features you’re going to use. For this LeetCode word break question, we have to repeatedly compare two string values. It’s a good use case for recursive functions.
- Think of ways to avoid doing unnecessary computations. For example, memoization can help you reduce the recursion tree.
- Think of a problem as a combination of many subproblems.
- Understand how you’re going to implement the separate steps of the solution. Then find a way to tie it all together to arrive at the answer.
Learn Algorithmic Techniques
There can be many different ways to approach this LeetCode word break problem. Python developers often write solutions based on specific techniques, which are algorithm design patterns for solving certain types of questions. For example, the first solution on the LeetCode platform uses the ‘backtracking’ technique.
If you spend enough time on StrataScratch and LeetCode platforms, you’ll start to understand how and when to apply these techniques to find answers. This will dramatically reduce the time you spend on writing an algorithm. It will also improve your value as a Python developer and Data Scientist in general.
Understand Your Data
In some cases, looking at data can help you understand the question better than a verbal description of the problem. Data samples put all important components in one place which helps you understand the context of how they’re related.
This question asks us to check if words in the list can be matched with a string. Data samples include both values, output, and sometimes even an explanation of the logic behind the answer.

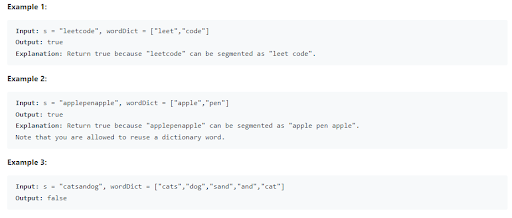
The third example is especially interesting. At first glance, it looks like ‘catsandog’ string should be matched with words in the dictionary. Despite how it looks, upon closer inspection, we’ll see that these words can’t fit together to match the provided string.
Constraints:
Constraints can give you a fuller picture of data. For this particular question, it describes the limitations of data and can give you the following information: maximum length of a string, the maximum number of words in the list, the maximum length of each word, their formatting, and information about the uniqueness of words.


All of this information will come in handy when you’re writing an algorithm. For instance, information about formatting can tell you whether you need to transform letters in the string.
Solution 1:
In this algorithm, we create a recursive function to continuously match the string with words in the array.
Formulate Your Approach
Once we’ve wrapped our heads around the question, it seems obvious to use recursive functions to find the answer. We are also going to follow the backtracking technique to check every possible combination of letters from the string. Our recursive function should take three arguments: a string, a word dictionary, and a numerical index.
We will design the function to check letters starting from the specific index in the string. The first call to the recursive function will start from the very beginning, index 0. First, the function will check just the first letter, then the first two letters, and so on, until we find a match.
Once we’ve matched the first few letters with one of the words in the dictionary, the recursive function will call itself again, but this time it will start checking from the letter that comes after the matched part of the string.
The function will follow this principle and try to match every letter of the string. If we can match the entire string including the last letter, the function should return true. If not, false.
Writing basic algorithms like this one can be a good way to wrap your head around the question. However, there is room for improvement, so this algorithm shouldn’t be your final answer.
Code Execution
First we create the main function wordBreak(), which accepts three arguments: self, the string value, and a list of words. It outputs a boolean.
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
def wordBreakRecur(s: str, word_dict: Set[str], start: int):
if start == len(s):
return True
for end in range(start + 1, len(s) + 1):
if s[start:end] in word_dict and wordBreakRecur(s, word_dict, end):
return True
return False
return wordBreakRecur(s, set(wordDict), 0)Then we define a recursive function, which also accepts three arguments: a string value, a list of words, and a number, representing the index, a starting point to continue checking the string.
For the initial call, the index will be 0. In the subsequent recursive calls to the function, it will update the index to start checking from the letter after the matched part of the string.
If we have a five-letter word matched with the first five letters in the string, during the next call, the function will start checking the string from the sixth letter. It will follow this pattern until it checks the last unmatched portion of the string.
If the string is matched, the function will return true boolean value. If it's not, it will return false. Running this algorithm on LeetCode will give us the following output


Algorithm returns the right answer, so it is accepted. Importantly, LeetCode output also shows the runtime of the algorithm. In this case, it’s 59 milliseconds. This number alone doesn’t give us a lot of information. We need to compare it to other algorithms.
We also need to consider its runtime complexity - in other words, the pace at which the execution time grows when the algorithm has to process more data. For now, we only have a string with 8 symbols and two words in the array. In this case, this algorithm works fine, but we can make it more efficient to handle larger volumes of data.
Solution 2:
This solution is similar to the first, but it uses the memoization technique to reduce execution time.
Formulate Your Approach
In this function, we will do everything exactly as we did in the first one. One major difference will be the use of memoization to significantly reduce the execution time of the algorithm.
The previous algorithm is inefficient because in some cases it checks the same combination of letters multiple times. We can prevent this by using the caching feature of the functools module.
After we make this addition to the code, our algorithm will have a ‘memory’ of previous checks and it will automatically dismiss attempts to check the same string multiple times.
Code Execution
This algorithm looks a lot like the brute force approach from the first solution. The main difference is the use of the Python functools module.
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
@lru_cache
def wordBreakMemo(s: str, word_dict: FrozenSet[str], start: int):
if start == len(s):
return True
for end in range(start + 1, len(s) + 1):
if s[start:end] in word_dict and wordBreakMemo(s, word_dict, end):
return True
return False
return wordBreakMemo(s, frozenset(wordDict), 0)Under the hood, @lru_cache decorator creates a memo array, to make sure that the algorithm only checks unique pieces of string. This is necessary to trim the number of calculations for getting the answer.
The output of this algorithm shows that it is indeed faster than the first one.


It is only 6 milliseconds faster, which may seem disappointing. However, remember that this is a small sample of data. The difference will be much more significant when working with larger volumes of data.
Solution 3:
In this solution, we perform a breadth-first search to get the answer.
Formulate Your Approach
Instead of relying on recursive functions, in this function we will use while and for loops to find the answer.
We’ll need to store the index to know where to start matching the string. Whenever the function matches one of the words with a string, it will update the index. In the next iteration, it will start from the first after the matched portion of the string.
We will also maintain an array of our past attempts to match the string starting on this index. In the while loop, we can implement a check to skip checks from indexes that led to unsuccessful results.
Code Execution
Here we have a standard definition of wordBreak function, with the same type and number of arguments as before.
In the function body, first, we create a set of words. Then we initialize a deque value and store it in the q variable. This variable will store the index to describe which parts of the string need to be checked.
Initially, we need to check the entire string, so the q value should have an initial value of 0.
The visited variable will store previously checked indexes of the string. In the while loop, we will set a condition, which will skip the index if it was already checked.
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
word_set = set(wordDict)
q = deque()
visited = set()
q.append(0)
while q:
start = q.popleft()
if start in visited:
continue
for end in range(start + 1, len(s) + 1):
if s[start:end] in word_set:
q.append(end)
if end == len(s):
return True
visited.add(start)
return FalseThe deque value in the q variable will store the index of the letter coming after the matched portion of the string.
To make sure we start checking from the first letter, we add a starting index 0 to the q variable. Python follows zero-based indexing, so the first letter will have an index of 0. We also transform the list of words into a set.
If the index stored in the q variable turns out to be the last index of the string, it means that words in the list could be matched with the entire string. If not, the function will return false.
Running this code will confirm that it returns the right answer.

Solution 4:
An algorithm based on principles of dynamic programming.
Formulate Your Approach
In this solution, we rely on dynamic programming principles to design an algorithm that is efficient and easy to read.
To understand this function, we need to think of a problem as a combination of subproblems. In other words, we will break down the string into parts and check if each of these parts can be found in the word dictionary.
With every iteration, we get information and if the match is found, we move forward in the string. This way, with every iteration we need fewer calculations to find the answer.
We’ll maintain an array of boolean values for each letter in the string. When we find a word that matches with letters in the string, we will set the boolean values to true to mark the ‘borders’ of the string. In other words, the indices at which the string was successfully matched with words. This way, we’ll know which string combinations should be checked and which should be skipped to avoid repeated calculations.
In the for loop, we will start from the first letter of the string and attempt to find a match. As we go through the array, we will store the position of the furthest matched letter in i, and update the same position in the array of booleans.
If the boolean value on the i index is true, and it’s the last letter of the string, it means we successfully matched the entire string, and should return true.
Code Execution
In this solution, we create a dp array that contains as many elements as the letters in the string and one more value for the base case. This is the position from which we should start checking the array. We set the first item in the array to true.
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
word_set = set(wordDict)
dp = [False] * (len(s) + 1)
dp[0] = True
for i in range(1, len(s) + 1):
for j in range(i):
if dp[j] and s[j:i] in word_set:
dp[i] = True
break
return dp[len(s)]Our for loop checks how far in the string we can go by matching substrings with words in the list. Every time we match a word with the string, we set the boolean value on the i index to true.
Booleans in the list are going to be an indicator of whether or not we were able to match the string until that index. For this reason, we can simply return the value of the last boolean in the list.
If we run this algorithm, we’ll see that it returns the right answer and executes the fastest.

Comparison of Approaches to Solve this LeetCode Word Break Question
Four approaches described above can be separated into two categories - recursive and iterative. The first two solutions rely on recursive functions to get the answer, whereas the last two use while and for loops.
In the very first approach, we create a recursive function to continuously match the string with words from the list. We call it over and over until we fully match the string or we reach the point from which there is no match for the remainder of the string.
The second approach is mostly the exact same algorithm but relies on memoization to avoid checking the same bits of string multiple times.
In the third approach, we accomplish the same by using deque value to store the index as we go through the string. We also keep the record of already checked indexes, to avoid checking from this position again.
In the last approach, we maintain a cache to store boolean values for each letter in the string. Boolean values will be updated depending on whether the check from a specific position was successful.
Overall, all four approaches have some common elements and differences. One common feature is to store the position of the first unchecked letter in the string. In the first call, this position is always 0, but it is updated as we go through the string.
Every solution except the first implements a cache. For the second algorithm, we use the Python functools module, whereas in the last two we create a variable to store the result of previous checks.
The way we return the final answer is the same for the first two algorithms that rely on recursive functions. In the third approach, we check if the updated index represents the position of the last letter in the string. If it does, we return true.
In the last solution, we have a list of boolean values for each letter in the string. If the string up to a specific letter was successfully matched, the boolean value for the same index is set to true. To get the answer, we simply check if the last boolean in the array is true.
Conclusion
Any data scientist can benefit from a strong knowledge of Python. Mastering this skill comes down to practice. You can use platforms like LeetCode to find challenges and look at other people’s solutions.
Before writing Python algorithms to work with data, work on your foundation. This “Top 30 Python Interview Questions” can help you understand many of the concepts and techniques used in solutions to such problem. Also check out "LeetCode Two Sum Problem" and "LeetCode Single Number Problem" to explore more such questions from LeetCode.
Share


