PayPal Data Scientist Interview Questions


Categories:
 Written by:
Written by:Nathan Rosidi
In this post we'll take a close look at one of the PayPal data scientist interview questions and discuss two different ways of solving this question using SQL.
PayPal is a major American company combining the expertise in technology and finance into an elaborate payment solution used by hundreds of millions of users worldwide. Founded in 1999 by, among others, Elon Musk, the corporation now has a yearly revenue of over 20 billion dollars and employs more than 26 thousand people. While the main product of the company is the service for storing and exchanging money between users, PayPal acquired a number of other companies and services within the last decade. It also leads extensive research into topics such as transaction security or fraud detection.
In this article, we will take a close look at one of the interesting PayPal data scientist interview questions and discuss two different ways of solving this question using SQL. Even though both solutions are fully correct, one of them is more likely to land you a data science job at PayPal.
Also, check out our post "data science interview questions" to find more questions from other top companies.
Data Scientist Position at PayPal
PayPal is always on the lookout for data scientists and data analysts with the possibilities to work at their offices in various US states, India, Ireland, the UK and other countries. It offers employment both within the different departments of the main company and in a number of acquired companies and products. A PayPal data scientist may contribute to new features development, aiding the sales efforts or perfecting techniques of fraud detection to name a few.
To fill their data science positions, PayPal looks for those who can leverage data and analytics to drive strategy and initiatives end to end. They should have experience with data modeling, machine learning algorithms, and data science techniques as well as with explaining technical concepts and analysis implications to varied audiences or translating business objectives into analyses. PayPal expects from the candidates fluency in SQL, Python or R while the knowledge of visualization tools such as Tableau, Salesforce Einstein or Qlikview comes as a big advantage.
PayPal Data Scientist Interview Question: Super Managers
This is one of the real PayPal data scientist interview questions. It is titled ‘Super Managers’ and it is a medium level question with a difficulty coming from the way in which the data are stored as compared to what this question is asking about.


Link to the question: https://platform.stratascratch.com/coding/9901-super-managers
We are being asked to find managers with at least 7 direct reporting employees. The question also specifies that we should output the first names of managers.
Framework to solve this PayPal data scientist interview question
Before devising the solution, let us share the 3-step general framework that you can use to solve any data science problem. It’s especially useful for solving interview tasks as, given the stress, it’s lifesaving to have a systematic way to approach any question but it also comes useful in general e.g. in your data science career.

- Understand your data:
- The first step is to list your assumptions about the data columns so that you know which columns you'll need to use
- And view the first couple of rows of the data you have (single or multiple tables) if you still don’t feel confident you understand your data enough. Or if you're in an interview, you may ask for some example values to understand the actual data, not just the columns. It’ll help you to identify the edge cases and limit your solution to the bounds of your assumption.
- Formulate your approach:
- Write down the logical steps you are going to program or code.
- Identify the main functions you need to use or implement to perform the logic.
- Remember that the interviewers will always be watching you; they can intervene when needed, so make sure that you ask them to clarify any ambiguity, they will also specify if you can use ready-made functions, or you should write code from scratch.
- Code Execution:
- While building up your code, do not oversimplify, or overcomplicate it.
- You can build it in steps based on the steps you’ve outlined with the interviewer. That means that the code will probably not be efficient. That’s fine. You can talk about optimization at the end with the interviewer.
- The most important point is not to overcomplicate your code with multiple logical statements and rules in each code block. A block of code can be defined as a CTE
or a subquery because it’s self-contained and separate from the rest of the code. - The interviewer will be evaluating your problem-solving skills so speak up and talk as you’re laying down code
Understand your data
Let’s start by looking at the data we have available to solve this PayPal data scientist interview question. Usually, at an interview you won’t be given any actual records, instead, you’ll see what tables or data frames are there and what are the columns and data types in these tables.
In the case of this PayPal data scientist interview question, we are given only one table called ‘employee’. It has quite a few columns such as ‘id’, ‘first_name’, ‘last_name’ and so on. Just looking at the column names, we can deduce that each row in this dataset represents one employee of a certain company. Each employee has several details such as ‘age’ or salary’.
employee
| id | int |
| first_name | varchar |
| last_name | varchar |
| age | int |
| sex | varchar |
| employee_title | varchar |
| department | varchar |
| salary | int |
| target | int |
| bonus | int |
| varchar | |
| city | varchar |
| address | varchar |
| manager_id | int |
The good news is that to answer this question, we won’t need to use all the columns from the dataset. We are being asked to find managers with a certain number of corresponding employees so the columns that will come in handy are ‘employee_title’ or ‘manager_id’. We will also use the ‘first_name’ column because this is what we need to output in the final result.
Solution #1
Formulate Approach
The next step, according to the framework for solving data science interviews, is to formulate the approach. In this article, we will cover two ways of solving this PayPal data scientist interview question and that’s why we will go through the steps of formulating approach and the code execution twice.
This first solution will probably be an easier and clearer one, we will define three quite logical steps for solving this problem, each step will virtually be addressed by a separate query and we will only use basic SQL clauses and functions.
- Firstly, let’s consider the column ‘manager_id’. This column tells us, for each employee, who is their manager. It contains IDs that correspond to IDs of some employees who also happen to be managers. Since we’re only interested in managers who have at least 7 employees reporting to them, the logical first step will be to count how many reporting employees each manager has. This can be done with the help of this column ‘manager_id’ by simply counting how many times each ID appears in this column.
- Once we have these numbers, the second step will be to filter the results only leaving these IDs that appear in the column ‘manager_id’ at least 7 times - this is equivalent to saying that an employee with this ID is a manager and has at least 7 other employees reporting to them.
- The final step will be to adjust the output to what’s required by the question. It says ‘output first names of managers’ so that’s exactly what we will do. We can use this of IDs from the previous step and retrieve from the dataset the first names corresponding to these IDs.
Code Execution
Having defined our general approach, it is time to write the code. The first step is to count how many times each ID appears in the ‘manager_id’ column. This can be achieved with a simple query and with the use of the COUNT() function. We can select the ‘manager_id’ and count the number of all rows - that’s what the asterisk means. We can call this second column ‘emp_cnt’ so that it can be reused later. Don’t forget to group by ‘manager_id’ and this query will give us the number of times each ID appears in the column ‘manager_id’.
SELECT manager_id,
count(*) AS emp_cnt
FROM employee
GROUP BY manager_id
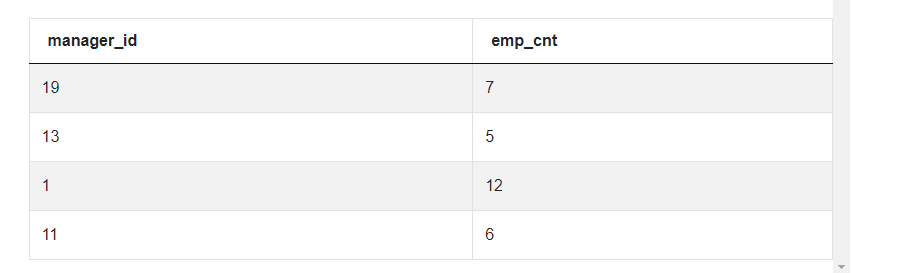
As you can see, there are only 4 managers with IDs 19, 13, 1 and 11, and these are the number of employees who report to them. We can already see that two of them have at least 7 employees, now we just need to make our code understand it. The next step is to filter the results to leave only IDs that appear at least 7 times. We can do it in another query in which we will select the column ‘manager_id’ from the previous query and restrict the ‘emp_cnt’ to be equal to or greater than 7.
SELECT manager_id
FROM
(SELECT manager_id,
count(DISTINCT id) AS emp_cnt
FROM employee
GROUP BY 1) a
WHERE emp_cnt >= 7
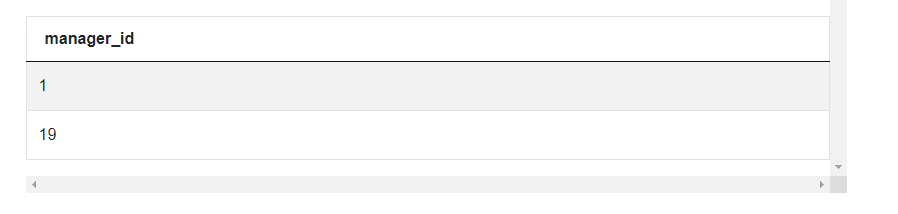
As expected, only two IDs, 1 and 19, are left on the list. These are IDs of employees who are managers and have 7 or more direct reporting employees. Now, the only thing we’re missing is the first names. So let’s add one more outer query in which we will select the first_name column from our original table. And then let’s add a WHERE clause saying that the ID of the employees must be in the list we created before
SELECT first_name
FROM employee
WHERE id in
(SELECT manager_id
FROM
(SELECT manager_id,
count(DISTINCT id) AS emp_cnt
FROM employee
GROUP BY 1) a
WHERE emp_cnt >= 7)
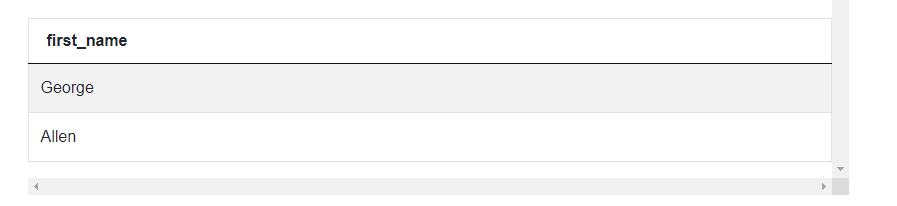
Turns out George and Alan are the two managers with at least 7 employees who report to them. These are exactly the names of employees with IDs 1 and 19. What’s worth mentioning here is that this construction ‘WHERE column IN subquery’ works only when the subquery returns a single column. That’s why in the subquery, we only select the column ‘manager_id’. If we selected anything else, for example, ‘emp_cnt’, this solution would no longer work.
Solution #2
Formulate Approach
We have seen one way to solve this PayPal data scientist interview question but as mentioned, there are multiple possible approaches so let’s see one more. This solution is a bit more advanced than the previous one but it’s also more elegant and shorter. Again, let’s start by outlining the general approach to solving this problem. The steps will be similar but not exactly the same as previously.
- First, let’s again create a list of IDs that appear in the ‘manager_id’ column at least 7 times. In the previous solution, we needed two steps and two queries to do it but this time let’s use a HAVING clause that will allow us to achieve the same result in a single query.
- From here we could proceed the same as last time using the ‘WHERE column IN query’ construction but let’s do it differently this time. The second step will be to add employees details to the list of IDs from the previous step by merging the list with the original table using a JOIN.
- At this point, we will have rows from the original dataset corresponding to employees who are managers and have at least 7 reporting employees. The final step then will be to only output their first names instead of all the possible data.
Code Execution
Let’s get on to writing the code for this solution. The first step is to use the HAVING clause to output IDs that appear in the ‘manager_id’ column at least 7 times. The HAVING clause is useful here because it allows using the COUNT() function for defining the condition. This means that we no longer need to select a COUNT() function and add an outer query to filter the results.
SELECT manager_id
FROM employee
GROUP BY manager_id
HAVING COUNT (*) >= 7
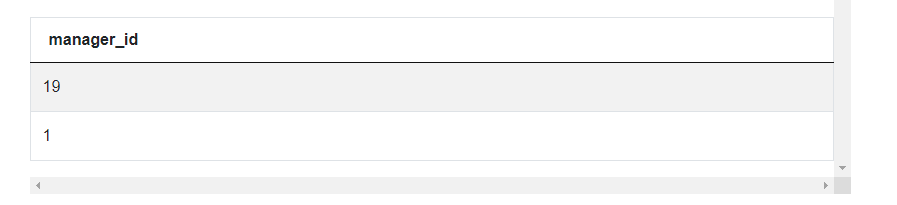
Note that even though there is no aggregation function in the SELECT clause, we still need to add the GROUP BY clause. That’s because we still use an aggregation function, COUNT(), but this time in the HAVING clause. This function still needs to know that the results need to be aggregated by ‘manager_id’. And why use HAVING instead of WHERE? That’s because it’s not allowed to use an aggregation function inside the WHERE clause. The only way is to use the function in a subquery and then the WHERE clause in the outer query like in the previous solution. Using the HAVING clause allows us to do this in a single query. As you can see the result from this query is the correct list of IDs: 19 and 1.
The second step is to add employee details to the list of IDs by joining the list with the whole dataset. Let’s start with a generic query selecting all the columns from the employee table and then let’s join the table with the query from the previous step.
SELECT *
FROM employee AS t1
JOIN
(SELECT manager_id
FROM employee
GROUP BY manager_id
HAVING COUNT (*) >= 7) AS t2
ON t1.id = t2.manager_id;See that in the JOIN condition, so in everything after the ON keyword, we defined that the column ID from the original dataset should correspond to the column ‘manager_id’ from the list of IDs. That’s because IDs that we got in the previous query are the managers whose names we need. If we matched them with the column ‘manager_id’ in the original table, then we’d again get data of employees who report to managers 1 and 19, not the managers themselves.


As you can see, now we still have two rows but we also added all the columns from the employee table so for both the managers we have all the possible data. We only need to output the first names though and that’s why we have this last step. This can be achieved very simply by replacing the asterisk in the SELECT clause with the name of the column.
SELECT first_name
FROM employee AS t1
JOIN
(SELECT manager_id
FROM employee
GROUP BY manager_id
HAVING COUNT (*) >= 7) AS t2
ON t1.id = t2.manager_id;The result is the same as before, we can see that George and Alan are the managers with at least 7 reporting employees, and so this solution is also correct.
Comparison of Approaches
We have covered two different approaches to solving this PayPal data scientist interview question but can it be that one of the approaches is better than the other? Speaking about performance and efficiency, the first solution had 3 queries compared to only two in the second solution. But at the same time, the second solution used the HAVING clause which is generally less efficient and slower than a WHERE clause. But then the first solution had two different WHERE clauses. So when it comes to efficiency, computing time and the memory needed, the two solutions are very similar to each other and should have very similar performance on large datasets.
However, if you’re at a job interview, you will probably want to use the second approach. That’s mostly because it’s a bit more advanced - it implements the not so common HAVING clause and we merge the two datasets using JOIN. On the other hand, the first solution uses only the most basic SQL and so it can hardly be used to show off your skills at an interview. The second solution is also a bit more elegant since we only have 2 queries instead of 3 nested ones.
Conclusion
In this article, we have discovered two different ways for solving only one interview question. But even though we have seen only these two approaches, it doesn’t mean that you won’t be able to find any more. Our advice is to practice answering the interview questions on the StrataScratch platform by constructing solutions to them but always try to think of other ways to solve them, maybe you’ll come up with a more efficient or more elaborate approach.
And lastly, don’t forget to stick to the framework for solving any data science problems that we discussed in the beginning, it will make your interviews and your life much easier. Once again, you start by examining and understanding the data, you then formulate your approach - the few general steps required to solve the problem. Finally and based on these two, you can write your code step by step.
Share


