Indispensable Data Mining Tools You Need as a Data Scientist


Mastering data mining tools: A comprehensive guide to data analysis, machine learning, and predictive analytics for effective business intelligence.
There is no doubt that, in today's decision-making landscape, data holds a crucial position.
Data mining tools exactly help you with this – decision-making.
From Python to Oracle BI, these tools are fundamental pillars, not only enhancing data analysis and machine learning but also bolstering predictive analytics and data visualization.
So, whether it's to boost business intelligence or augment data warehousing initiatives, it's time we explore these indispensable data mining tools every data scientist needs in their toolkit.
You might want to avoid the data mining tools as you think they must involve knowing a programming language. But you’d be wrong! There are many data mining tools where a programming language is not always mandatory.
Ready to cross the threshold into the world of data mining?
We’ll start with fundamentals. And speaking of fundamentals, we plowed the net in search of data science resources. We included 314 of them (yes, that much!) in the Resources For Data Science Fundamentals article.
What is Data Mining?


Finding patterns in large data sets is a process known as data mining, which includes techniques from the fields of statistics, machine learning, and database systems.
This process consists of several stages.

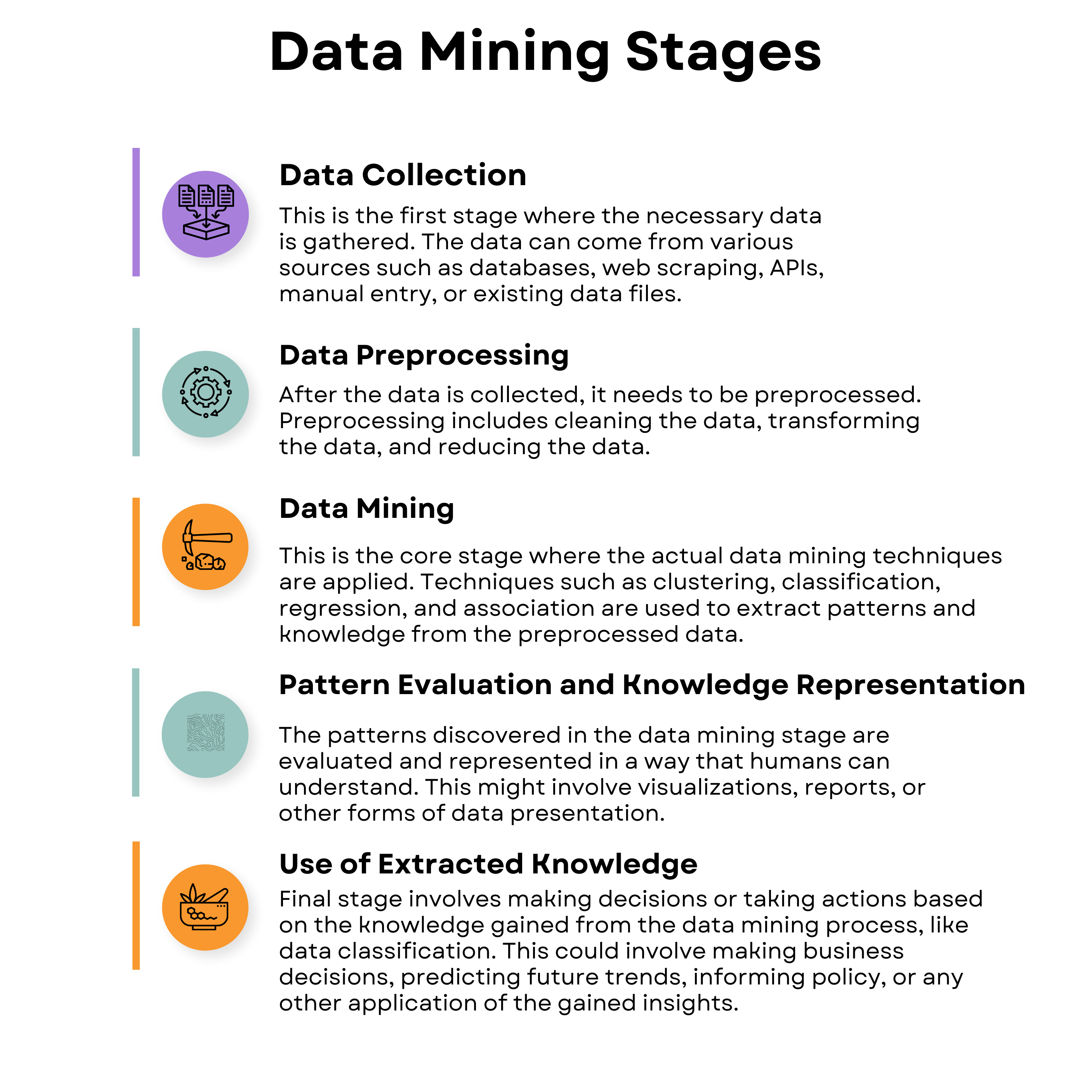
Data Extraction or Collection refers to gathering data from different sources, which can be structured, unstructured, or semi-structured, for processing or storage. This extracted data is used in subsequent stages.
Data Preprocessing is a technique in data mining that transforms raw, often incomplete, and inconsistent data into an understandable format. It consists of several sub-processes, including data cleaning, integration, transformation, reduction, and discretization, all aimed at resolving issues in the raw data. The critical sub-process here is data cleaning. It is the process of detecting and eliminating noise and inconsistent data from the collected dataset. This phase is critical as the quality of data significantly impacts the extraction of useful information, and it involves handling missing data, noisy data, and inconsistent data.
Data Mining is the main stage where different mathematical and computational algorithms are applied to extract patterns from the data. Techniques such as clustering, classification, regression, and association can be used.
One example goal of data mining is data classification, achieved using a variety of methodologies, including clustering algorithms, association rules, decision trees, and neural networks. Data classification is the process, either manual or automated through machine learning, of categorizing data into distinct classes, a critical step in data analysis that enhances data organization and understanding.
Pattern Recognition involves identifying patterns, trends, or relationships in the cleaned and transformed data, which can help in making predictions or understanding underlying relationships. For instance, supermarkets can use pattern recognition to determine products that are frequently purchased together to optimize product placement or deals.
This final stage of the data mining process is crucial as it is where the insights and knowledge extracted from the analysis are put into action. This stage can be broken down into several aspects:
- Interpreting Results: Before taking any action, it's essential to interpret and understand the results obtained from data mining. This involves analyzing patterns, trends, and relationships that have been identified in the data.
- Validation and Verification: It's important to validate the results to ensure that the insights are reliable and based on sound data. This might involve cross-validating with other data sources or using statistical methods to verify the significance of the findings.
- Decision Making: With validated insights, decision-makers can make informed choices. In a business context, this could involve adjusting pricing strategies, targeting specific customer segments, or optimizing supply chains. In healthcare, it could mean adopting new treatment protocols.
- Predictive Modeling: The insights gained can also be used to build predictive models that forecast future trends or outcomes. For instance, a retailer might use data mining to predict future sales trends and stock inventory accordingly.
- Informing Policy: In the public sector, data mining can inform policy decisions. For example, insights from data mining can be used to shape educational policies, public health initiatives, or urban planning.
Data Mining Tools

This section will explore some of the most widely-used data mining tools, each with unique features tailored to different needs and use cases.

Let’s start with Python.
Python


Python is a popular programming language in various areas of data science, including data mining. Here’s an overview of this data mining tool.

It is known for its easy syntax and readability. It has a rich ecosystem of libraries tailored for different data mining tasks, making it one of the go-to languages in data science.
Python can interact with almost every type of database, which makes it handy for data extraction and cleaning.
Some of the most commonly used libraries are:
- pandas
- NumPy
- scikit-learn
- TensorFlow
- PyTorch
Libraries like pandas and NumPy are useful in preprocessing and cleaning data, handling tasks like null value replacement, outlier handling, and feature scaling.
Null Value Replacement: This technique involves substituting missing or null values in the dataset with other values.
This is done to avoid errors or biases during data analysis.
Common statistical methods used for replacing null values include using the mean, median, or mode of the existing data.
Outlier Handling: Outliers are data points that are significantly different from other observations.
They can distort statistical measures and affect the performance of data models.
Outlier handling involves identifying these unusual data points and taking appropriate actions, such as removing them or adjusting them to more reasonable values.
Feature Scaling: In datasets with features that have different ranges or units, feature scaling is used to standardize the range of these features.
This ensures that no feature disproportionately influences the model due to its scale.
Common methods of feature scaling include normalization (scaling features to a range of 0 to 1) and standardization (scaling features to have a mean of 0 and a standard deviation of 1).
Another popular library is scikit-learn, which offers many supervised and unsupervised learning methods for the application of machine learning techniques.
Deep learning tasks rely on TensorFlow and PyTorch.
Companies such as Google, Amazon, and Facebook use Python for its simplicity, powerful data analysis, and predictive capabilities it provides, aiding in decision-making and strategic planning.
Advantages
- Simplicity: Python's syntax is straightforward and intuitive, making it great for beginners.
- Strong library ecosystem: Python has a comprehensive set of libraries for data mining and machine learning tasks.
- integration: Python can easily integrate with web services and database systems, making it ideal for data extraction.
Disadvantages
- Performance: Compared to compiled languages like C or Java, Python is slower. This could be a constraint when dealing with large datasets.
- Memory consumption: Python's ease of use comes with the cost of higher memory consumption.
Python can be installed from its official website: Python.org
R

R is a programming language for statistical computation and creating visuals.
Here’s the overview of its use, pros and cons.

One reason for its popularity is a variety of tools available for manipulating data, doing calculations, and displaying visuals.
It is an effective language used to create statistical applications and carry out data analysis.
Also, it's open-source, meaning it's free to use, and has a rich ecosystem of packages making it highly extensible.
R provides excellent tools for understanding data and producing high-quality graphics. Companies such as Pfizer, Bank of America, and Shell use R for data analysis.
R can be used in every stage of the data mining process. It offers several packages for data extraction, cleaning, visualization, and implementing complex statistical models.
Libraries like dplyr are used for data cleaning and manipulation, ggplot2 for data visualization, and caret for implementing machine learning models.
Advantages
- The richness of packages: R has a vast number of packages for statistical analysis, data visualization, and machine learning.
- Quality of plots: R creates high-quality, highly customizable plots, making them ideal for data visualization and reporting.
Disadvantages
- Memory management: R loads all data into RAM, which can slow down computation when dealing with large datasets.
- Complexity: R has a steeper learning curve compared to Python, especially for beginners.
R can be installed from its official website: R-project.org
IBM SPSS Modeler

IBM SPSS Modeler is a data science and predictive analytics tool, that allows users of all skill levels to build and deploy analytics at scale. It supports the complete data science cycle from data understanding to deployment.
Here’s this data mining tool overview.
Due to its visual interface, you can work with data and manage the process directly.
It is used by companies that need to develop models to drive decision-making immediately and will benefit from this software.
You don’t need programming language knowledge, so its user-friendly visual interface might make this data mining tool your favorite.
Advantages
- Ease of use: Its visual user interface makes creating and deploying predictive models simple for non-programmers.
- Advanced algorithms: It offers a wide range of machine learning algorithms, statistical models, and data preparation tools.
Disadvantages
- Expensive: IBM SPSS Modeler is a premium product with a high price tag, which may not be suitable for small businesses or individual users.
- Less flexible: Despite being a bonus for the non-coders, the tool's user-friendly interface limits its flexibility when compared to computer languages like R and Python.
IBM SPSS Modeler features include automated data preparation, integrated data transformation, advanced algorithms for machine learning, text analytics, and easy deployment of models.
IBM SPSS Modeler can be found on IBM's official website: IBM SPSS Modeler
RapidMiner

RapidMiner is a data science platform that offers a wide range of techniques, from data preparation to machine learning and model validation.
Here’s the overview.
It supports steps of the data mining process like data loading, transformation, model building, validation, and deployment.
Moreover, RapidMiner offers a range of operators for data preprocessing, machine learning, and modeling
No specific programming knowledge is required to use RapidMiner, thanks to its visual environment for designing analytical workflows. It does, however, support scripting in several languages, including Python, Groovy, and others, for added flexibility and functionality.
Advantages
- User-friendly: RapidMiner offers a simple, drag-and-drop interface that makes complex analytics accessible to non-programmers.
- Comprehensive: Its wide range of features makes it a comprehensive solution for data science projects.
Disadvantages
- Limited customizability: While its user-friendly interface is a benefit, it can limit the level of customization available to users.
- Expensive: The full version of RapidMiner can be expensive, making it less accessible for small businesses or individual users.
RapidMiner can be found on its official website: RapidMiner
KNIME

KNIME, short for Konstanz Information Miner, is a data analytics platform that supports data mining, machine learning, and other data-driven tasks. It allows users to create visual workflows with a wide range of integrated tools.
Here’s the overview.
KNIME supports all phases of the data mining process. It has nodes for data preprocessing, such as data cleaning, transformation, and integration. It also has numerous nodes supporting a variety of machine learning algorithms like decision trees, clustering, neural networks, and association rules.
Its flexibility, extensive features, and visual workflow make it suitable for both beginners and advanced users to create and deploy data-driven strategies effectively.
KNIME does not require programming knowledge as it's a visual data analytics tool. Nevertheless, it supports integration with numerous programming and scripting languages like Python, R, and JavaScript, which can be used to extend its capabilities.
Advantages
- Flexibility: KNIME is highly flexible, with more than 1000 modules and hundreds of plugins from its vast community.
- Visual Workflow: Its drag-and-drop interface allows for easy creation and understanding of data workflows.
Disadvantages
- Learning Curve: Even though KNIME reduces the barrier of coding, it still requires a solid understanding of its workflow concept, individual nodes, advanced features, and underlying data science principles, which together contribute to its steep learning curve.
- Performance: Handling very large datasets can be challenging as it may require significant computational resources.
KNIME can be found on its official website: KNIME
Orange Data Mining

Orange Data Mining is an open-source software package for machine learning and data visualization. It is renowned for its user-friendly Python scripting features and visual programming interface.
Here’s the overview.
It allows users to design their data analysis process visually and promotes open and reproducible research.
Orange Data Mining supports the entire data mining process. It comes with a set of components called widgets that range from data preprocessing to machine learning algorithms.
It allows you to build complex workflows for analyzing and visualizing data.
Orange Data Mining is widely used in academia for teaching purposes and in industries where quick and effective data analysis is needed.
It is primarily a visual programming tool and does not require explicit programming skills. However, it can be extended using Python scripting.
Advantages
- Ease of use: Its widget-based interface allows users to design data analysis workflows visually.
- Interactive visualization: It comes with numerous widgets for interactive data visualization, promoting a better understanding of the data.
Disadvantages
- Limited Algorithms: While it covers many basic machine learning algorithms, it may not have all the latest or more complex methods.
- Performance: Orange might struggle with very large datasets due to computational limitations.
Orange Data Mining can be installed from its official website: Orange Data Mining
Apache Spark

Apache Spark is for big data processing, and has built-in modules for SQL, machine learning, and graph processing.
Here’s the overview.
Apache Spark supports data mining through its machine learning library (MLlib) which includes several commonly used machine learning algorithms like clustering, regression, classification, and collaborative filtering. It also supports model evaluation, and feature extraction, transformation, and selection.
You’ll need coding skills to use Apache Spark.
Apache Spark is popular among data engineers and data scientists in industries that require processing large-scale data, like telecommunications, finance, and e-commerce. Companies like Netflix, Yahoo, and eBay use Spark for its speed, ease of use, and versatility in processing and analyzing big data.
Advantages
- Speed: Spark can run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
- Ease of Use: More than 80 high-level operators are provided by Spark to simply create parallel applications.
Disadvantages
- Memory Consumption: Spark uses more storage space as it caches intermediate data in memory rather than storing it in disk which can be a challenge for small-scale projects.
- Complexity: Spark’s high-level APIs and programming model can be complex to understand and apply.
Apache Spark can be found on its official website: Apache Spark
Kaggle

Kaggle is a Google-owned online community for data scientists and machine learning enthusiasts.
Here’s the overview.
You can explore various datasets on Kaggle, develop data mining and machine learning models, and take part in tournaments.
It provides a collaborative and competitive environment to learn and apply data mining concepts.
You can execute scripts in the browser using Kaggle Kernels, which makes it simple to share and discuss code with the community.
It's popular in academia and industry for its rich resource of datasets, kernels (code), and community discussions.
Advantages
- Rich resources: Kaggle provides an abundance of datasets, kernels, and competitions to learn from and participate in.
- Community: Kaggle's large community of data scientists provides a great platform for collaboration and learning.
Disadvantages
- Overfitting to the leaderboard: In Kaggle competitions, there's a risk of overfitting models to the leaderboard, which might not generalize well to real-world data.
- Competitive pressure: The competitive nature of Kaggle can be overwhelming for beginners.
Kaggle can be accessed on its official website: Kaggle
Zoho Analytics

Zoho Analytics is a data analytics software. It will allow you to create impressive data visuals and dashboards quickly.
Here’s the overview.
Moreover, Zoho Analytics has built-in connectors to pull data from diverse sources to create correlational reports. These reports may be used to identify trends and correlations among different variables.
Additionally, it allows predictive analytics, which enables firms to predict future patterns and outcomes using historical data.
You can use Zoho Analytics to analyze business data, discover hidden insights, track key business indicators, and get business intelligence reports wherever they are.
Zoho Analytics primarily operates as a BI tool with a user-friendly, drag-and-drop interface and doesn't require programming knowledge for its basic functionality. However, familiarity with SQL would be beneficial to perform more complex data manipulations and customizations.
Advantages
- Ease of use: Zoho Analytics has a user-friendly interface that allows even non-technical users to create reports and dashboards.
- Integrations: It can integrate with a variety of other Zoho apps and other external applications.
Disadvantages
- Limited customization: There are few choices for customization.
- Performance: Some consumers may have concerns about how quickly data is processed.
Zoho Analytics can be accessed on its official website: Zoho Analytics
SAS Data mining

The SAS Institute creates SAS Data Mining for advanced analytics.
Here’s the overview.

Its features provide machine learning techniques, including clustering, decision trees, and regression, which will be useful for data scientists.
SAS Data Mining is a good choice for data mining projects because it provides powerful data preparation features, including data cleansing, transformation, and variable selection.
You can use this data mining tool via a graphical point-and-click interface or learning the SAS language.
Advantages
- Comprehensive analytics: SAS provides a wide range of statistical and machine learning techniques.
- Data management: It has strong data management and preprocessing capabilities.
Disadvantages
- Cost: SAS products, including their data mining software, tend to be more expensive than other alternatives.
- Complexity: Despite its strength, SAS may be difficult to master, especially for people who are new to data analysis.
For more, here is its official website: SAS Data Mining.
Oracle BI

Oracle BI delivers a full range of analysis and reporting capabilities. Its purpose is to assist enterprises in obtaining a greater understanding, spanning a wider range of data, and achieving improved results in all facets of their operations.
Here’s the overview.
Oracle BI incorporates Oracle Data Mining, an advanced data mining tool integrated into the Oracle database. This tool empowers users to construct, assess, and implement data mining models directly within the Oracle Database environment.
It offers support for diverse data mining techniques, including clustering, classification, association, and regression.
Organizations opt for Oracle BI due to its comprehensive data analysis capabilities, extensive reporting features, and seamless integration with Oracle's suite of enterprise solutions.
While not primarily a programming tool, it integrates with Oracle's SQL and PL/SQL. Knowledge of these database languages can be beneficial but is not strictly necessary, as Oracle BI provides a range of graphical interfaces and tools.
Advantages
- Integration: Oracle BI communicates with other Oracle applications, offering seamless data analysis and reporting.
- Comprehensive capabilities: It offers robust data mining, visualization, and reporting capabilities.
Disadvantages
- Complexity: Oracle BI can be complex to set up and require specialized knowledge to use effectively.
- Cost: As with other Oracle products, Oracle BI can be expensive, particularly for small businesses.
More information about Oracle BI can be found on its official website: Oracle BI
Civis

Civis Analytics is a data science platform that helps you to cover the data and make smart decisions accordingly.
Here’s this data mining tool overview.
By using Civis Analytics, data scientists can work together on data science projects, which is helpful for companies.
With Civis, you can easily analyze their data and make informed choices with predictions accordingly.
Civis allows users to leverage their existing scripts or take advantage of CivisML, a machine-learning service that streamlines the process of model creation, validation, and deployment.
Businesses choose Civis for its advanced capabilities in predictive analytics, efficient data management, and intuitive data visualization features.
No explicit programming knowledge is needed to use the Civis platform's core features, as it offers a user-friendly interface for managing data science projects. However, it does allow for the use of Python and R for more advanced data analysis.
Advantages
- Usability: Civis platform is designed to be user-friendly for both data scientists and business users.
- Scalability: The platform is designed to handle large data and complex analytics tasks.
Disadvantages
- Pricing: The cost of Civis Analytics can be a barrier for smaller organizations or individual users.
- Learning curve: While the platform is designed for ease of use, it can take time to become proficient with all its capabilities.
More information about Civis Analytics can be found on its official website: Civis Analytics
WEKA

WEKA is a popular machine learning software written in Java, developed at the University of Waikato, New Zealand.
Here’s WEKA’s overview.
WEKA is easy to use, even if you're new to data mining, and free. It has many machine-learning algorithms which might help you.
It's popular for teaching, research, and different industries because it helps you understand your data better, especially in the Java Script community.
It is a GUI-based tool, so programming is not strictly necessary to use it. However, it is implemented in Java, and understanding Java can be beneficial if you want to extend its capabilities or embed WEKA's functionalities into your own Java code.
Advantages
- Ease of Use: WEKA has a user-friendly graphical user interface that makes it easy to load data, run algorithms, and interpret output.
- Open-source: WEKA is free and open-source, making it accessible for everyone.
Disadvantages
- Java Dependency: WEKA is implemented in Java, so you must have Java installed to run it.
- Handling of Big Data: WEKA may struggle with very large datasets, due to Java's memory constraints.
More information about WEKA can be found on its official website: WEKA
Conclusion
In essence, we've journeyed through a spectrum of indispensable data mining tools integral to any data scientist's toolkit.
From Python and R for scripting, to powerful platforms like IBM SPSS Modeler and RapidMiner, each data mining tool provides unique features catering to different aspects of data mining, opening avenues to gain insights from data.
Remember, choosing the right data mining tool requires understanding your goals, data, and personal preference. The realm of data mining is vast and ever-evolving; continue exploring, and you'll surely harness its full potential. Interested in learning more?
As data mining is a part of data science, which we specialize in, you’ll find many useful articles on this topic on our platform. And we’re also here if you want to learn popular data mining languages like Python and R. Just go to our coding questions section to find a great source of coding interview questions from all the best data science companies.
See you there!
Latest Posts:



Share